

如何计算向量数据的相似度?
source link: https://jw1.dev/2023/10/18/a01.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

最近在开发「只言」的衍生产品,名字暂时还没想好,但是功能已经出来了:基于向量化数据对长文本进行检索并整理,text-to-text 系列模型可以以此为上下文并回答用户的问题。
什么是向量化?
文本向量化最直观的表现就是,输入一段文字,返回一串数字,是把信息从直观转为抽象的过程。文本向量化的传统做法一般分为四步:
- 分词:这一步的目的是把文本拆分为独立的单位
- 建立词汇表:用上一步生成的词建立一个词汇表
- 词汇表编码:针对每个独特的词进行编码,这里可能会包括词频、词义、词权重等等属性
- 标准化:在编码后可以针对词的特征进行一定程度的标准化,比如去除权重较低或词频较低的数据等
凭心而论,以上任何一步放在以前都会让我想死,但是今时不同往日,我们有现成的向量化大模型,而我们需要做的只是调用一下 API 而已。
向量化数据长啥样?
如果说要在 js 里表现的话,就是这样:
// 这是一条向量化数据
const vectorizedData = [
-0.006929283495992422,
-0.005336422007530928,
// ...
-4.547132266452536e-05,
-0.024047505110502243
]
如果是 OpenAI text-embedding-ada-002 模型输出的向量数据,那么这个数组将会有 1536 条数据,或者说,维度。维度是啥?维度就是之前我们在编码中提到过的词属性,但是实际应用中,大模型生成的向量数据还包含很多其他维度的属性。
向量化可以做什么?
根据 OpenAI 的描述,向量化之后的数据大概可以做:
- 多样性测量
以下是我简化后的版本:
个人认为向量化的数据其实只有这两个功能,什么聚类、推荐、异常检测等等,都是数据分类后的自然而然得到的能力,而我们要做的就是计算向量数据的相似度。那我们应该要怎么计算相似度呢?
余弦相似度算法(Cosine Similarity)
最常见的方式应该就是计算余弦相似度了,计算步骤为:
- 计算两个向量的点积 (Dot Product)
- 分别计算两个向量的模长(Magnitude)
- 点积除以模长乘积得到相似度
用代码来写的话就是这样:
// 点积
function dotProduct(vec1, vec2) {
let product = 0;
for (let i = 0; i < vec1.length; i++) {
product += vec1[i] * vec2[i];
}
return product;
}
// 模长
function magnitude(vec) {
let sumOfSquares = 0;
for (let i = 0; i < vec.length; i++) {
sumOfSquares += vec[i] * vec[i];
}
return Math.sqrt(sumOfSquares);
}
// 余弦相似度
function cosineSimilarity(vec1, vec2) {
const dotProd = dotProduct(vec1, vec2);
const mag1 = magnitude(vec1);
const mag2 = magnitude(vec2);
if (mag1 === 0 || mag2 === 0) {
return 0;
}
return dotProd / (mag1 * mag2);
}
假设我们现在向量化三个句子:
今天天气怎么样
今天天气如何
这苹果真好吃
套用余弦相似度方法来检查第一句和第二句的相似度,我们会得到值 0.9717939245504936,这表示第一句和第二句相似度为 97%,再来看看第一句和第三句的相似度,我们会得到 0.7795850235231011,可以看到,这个算法基本上算是成立的。
今天天气怎么样,对比,今天天气如何 0.9717939245504936
今天天气怎么样,对比,这苹果真好吃 0.7795850235231011
余弦相似度算法的特点在于,两个向量数据的高维数据,也就是说文本,长度不一定需要相近也能得到很高的相似度。打个比方,“苹果好吃” 和 “隔壁又开了一家苹果店,我早上起床去买了一斤,还挺甜的” 可能会得到一个相对于其他算法更高的相似度,因为两者在语义上描述的主体一致。
欧氏距离算法(Euclidean Distance)
欧式距离也可以叫欧几里德距离,计算步骤为:
- 计算两向量各维度的平方差之和
- 计算平方差之和的平方根
代码这样写:
function euclideanDistance(vec1, vec2) {
var sum = 0;
for (var i = 0; i < vec1.length; i++) {
sum += Math.pow(vec1[i] - vec2[i], 2);
}
return Math.sqrt(sum);
}
还是代入之前的数据我们来看一下结果:
今天天气怎么样,对比,今天天气如何 0.23751243483566573
今天天气怎么样,对比,这苹果真好吃 0.6639503107502986
情况好像有些不对?为什么第一个对比得到的相似度会比第二个对比要少?
因为这里我们计算的是欧几里德距离,距离越近越相似,所以这个算法依旧成立。我们可以用 1 / (1 + distance) 来获取一个 0 - 1 之间的数值,这个数值就是相似度了。
function euclideanDistance(vec1, vec2) {
var sum = 0;
for (var i = 0; i < vec1.length; i++) {
sum += Math.pow(vec1[i] - vec2[i], 2);
}
let distance = Math.sqrt(sum)
return 1 / (1 + distance);
}
使用经过修改的代码再次代入数据进行计算会输出:
今天天气怎么样,对比,今天天气如何 0.8080726882819518
今天天气怎么样,对比,这苹果真好吃 0.6009794845070139
可以看到,文本长度和语义对结果的影响更大了,欧几里德距离算法的特点就是如此,如果原始文本长度差异较大,就可能导致计算出来的相似度越小。在应用方面,这种算法可以用来计算图片的相似度,两张图片通过一定的预处理可以得到相同维度的像素信息,通过对比各像素点在欧几里德空间上的距离就可以计算出图片的相似度,也可以用在推荐系统中充当某一权重,计算用户针对某一项产品的兴趣程度等等。
t-分布邻域嵌入算法(t-Distributed Stochastic Neighbor Embedding)
得,越来越离谱了,这是个啥玩意儿?
我为啥会知道这个东西?因为 OpenAI 关于 Embeddings 的官方文档里有写,它是一种分类算法,可以将向量数据转换成 2 维或者 3 维的点,个人理解,这也是一种相似度算法,计算结果趋于把数据集结成簇(cluster),但是计算步骤对比前面两个算法会稍微有那么亿点点复杂,因为涉及到很多我也不是很懂的专业词汇,在这里就不放了,但是我们有现成的 npm 库:https://www.npmjs.com/package/tsne-js 🤝,t-SNE 可以将向量数据在 2 维平面或 3 维空间可视化,能够让我们更好的理解机器是怎么样看数据的。
那么具体表现是什么呢?
好了,科学时间到!
一开始我用 9 个句子生成了 9 条不同的向量数据,每 3 个句子中分别包含一个统一话题(天气,水果,手机),然而计算后的数据表现却不尽人意:
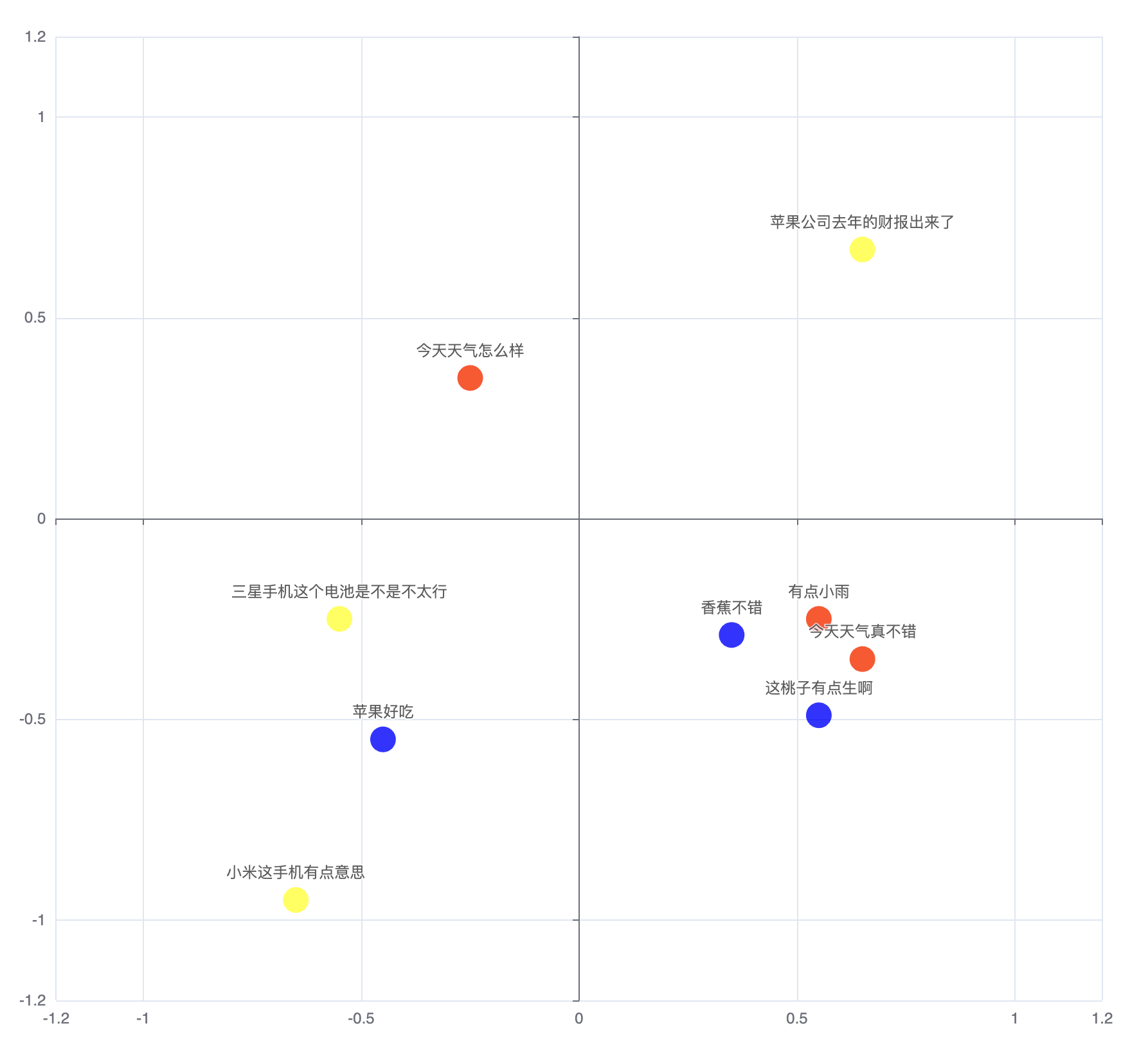
是不是样本太少了?但是上哪找那么多提前分好类的数据呢?直到我看到了这个:https://github.com/ultralytics/mnist

虽然他的数据格式我不能直接拿来用,但是对我启发很大,直接自己造了一个小工具,一点一点手动收集手绘的数字信息。
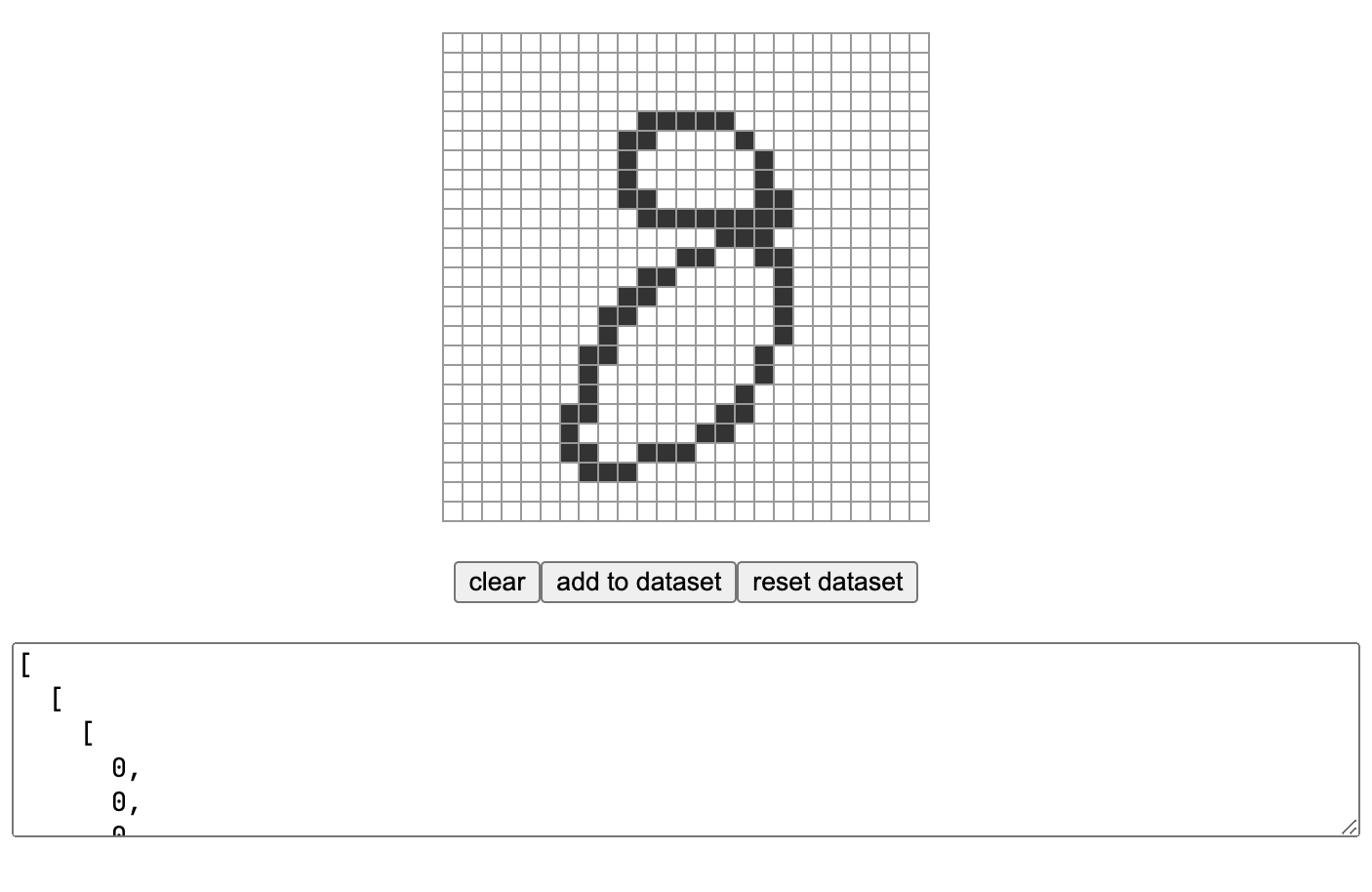
最后做出来的样本长这样:

由于我们的手绘数据都是由 0 和 1 组成,可以看作是一系列布尔向量,t-SNE 算法使用的参数如下:
{
dim: 2,
perplexity: 5,
earlyExaggeration: 4.0,
learningRate: 100.0,
nIter: 500,
metric: 'dice'
}
生成的图表如下:
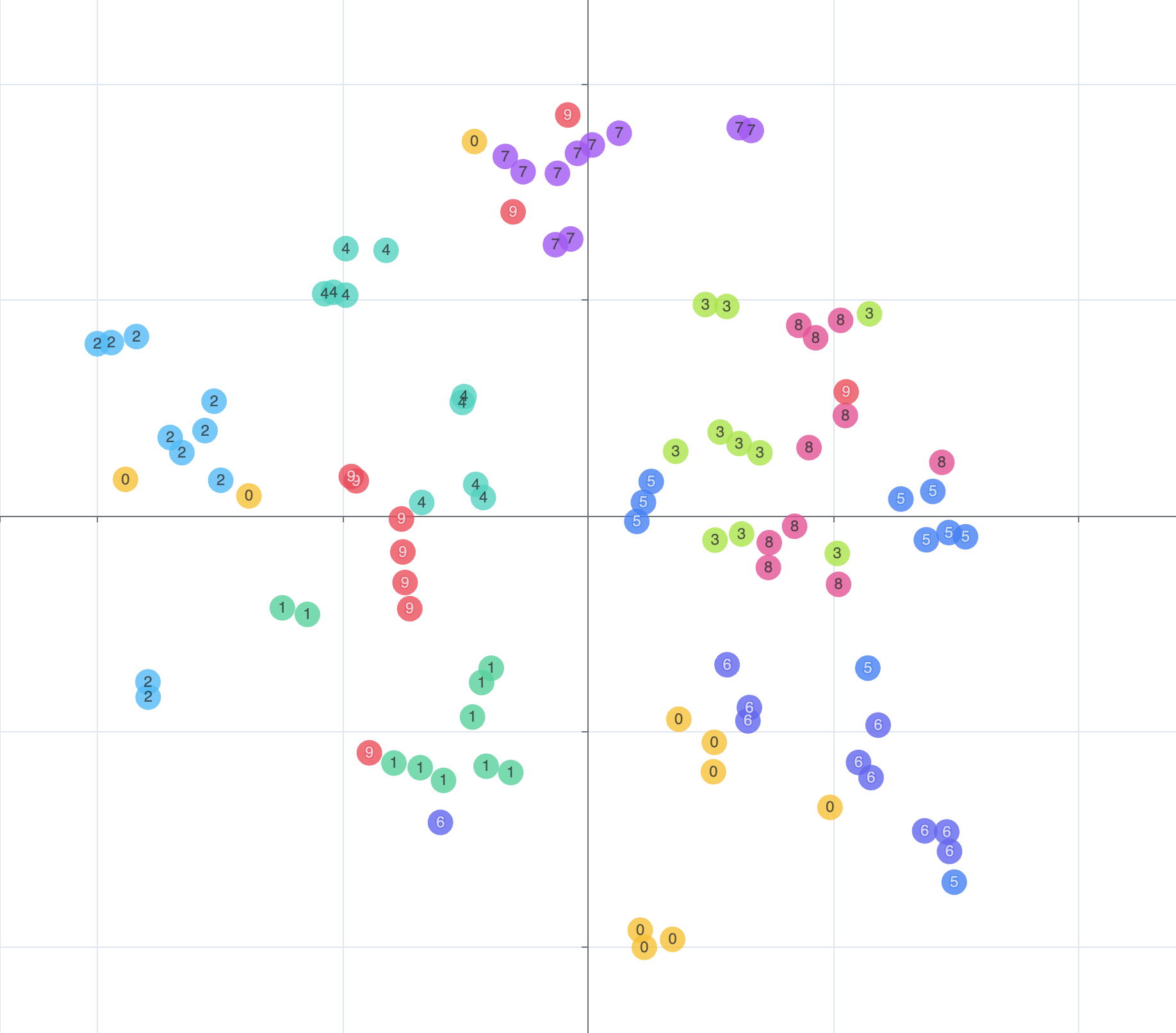
我们大概可以看出,大部分相同的数字都能集结成簇,但是需要注意的是,这里每个节点的颜色都是我们手动预分配的而不是计算出来的,如果需要聚类计算我们还需要 k-means 算法,经过 k-means 算法聚类后重新分配颜色可以得出下图:
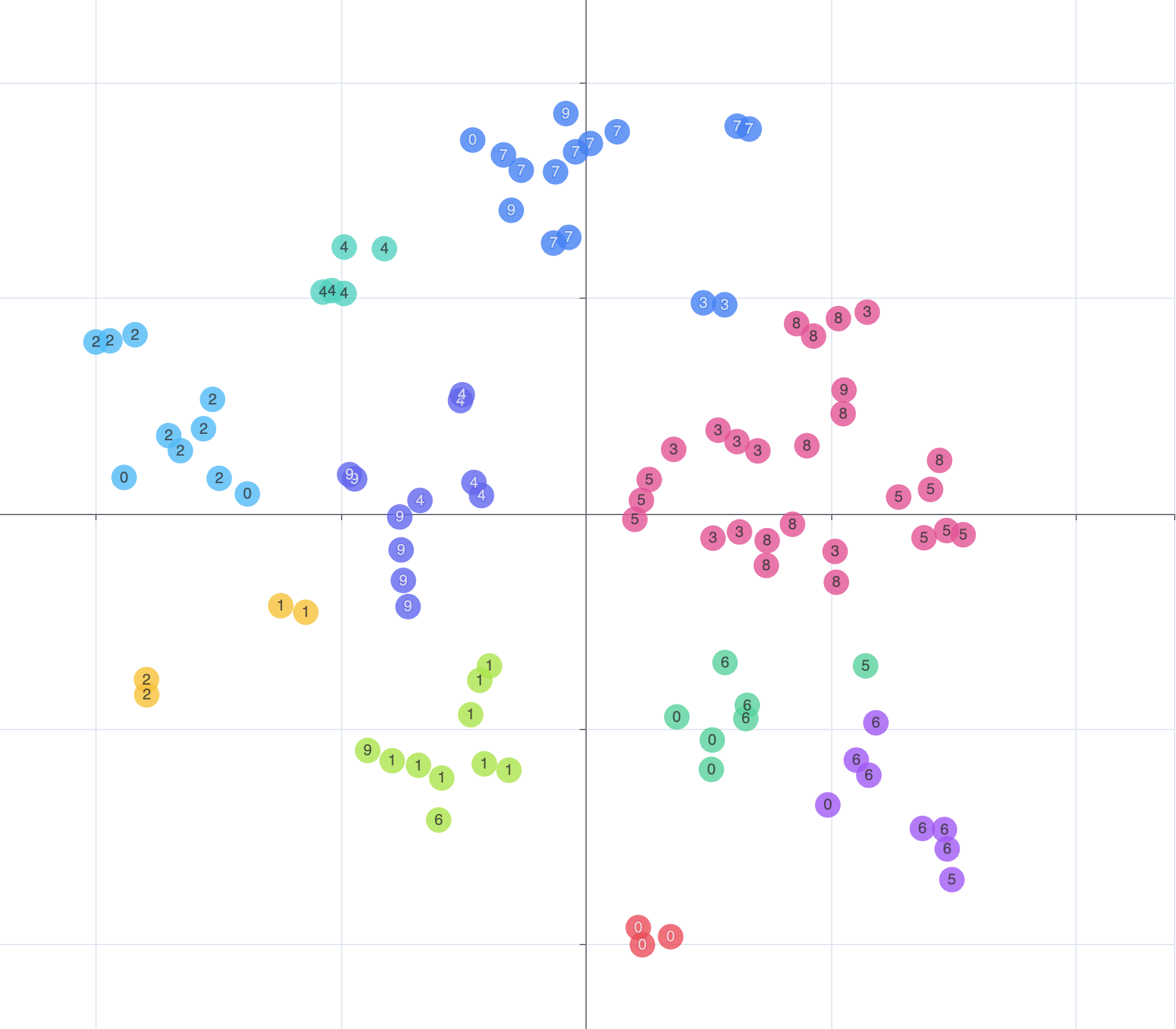
现在我们看到的分类才是算法认为的分类,可以看到第二第三象限中粉色的一簇多由 3、5、8 组成,这表示 t-SNE 算法认为,这些数字在一定程序上有很大的相似度,我知道这对一些朋友来讲可能会觉得荒谬,因为对于人类来说,辨别阿拉伯数字的技能早已刻进大脑,但是对于机器而言,他们可能只学了几百毫秒就要给出结果,如果能够给予足够的迭代次数和庞大的样本数量,机器可以比人更精准,事实上,这就是机器学习的核心。
好了,扯远了,现在讲讲怎么应用在相似度检测上,假设你现在拥有一堆向量数据,如果我们要进行搜索,则必然会先提供搜索词,我们可以将搜索词也向量化,然后一起进行 t-SNE 运算,最后我们找到关键词所在的簇,这个时候我们可以认为,这个簇除了关键词本身的所有项就是与关键词最相似的向量数据,但是缺点也是有的,k-means 生成的簇的长度不可控,可能会有一个簇中只有关键词一个向量数据的情况。
以上这些只是向量数据相似度计算中一些比较常见的算法,在不同的应用场景中会有各种各样的相似度算法,机器学习的世界真的会让人感受到什么是学海无涯,哪怕只是其中一小片的概念就有这么多门道。作为一个普通的前端开发者,我只能说,非常荣幸能够生活在这样一个时代。
好了,今天就说到这里,拜拜👋
Recommend
-
32
NLP基础系列
-
16
在NLP中,我们经常要去比较两个句子的相似度,其标准方法是想办法将句子编码为固定大小的向量,然后用某种几何距离(欧氏距离、$\cos$距离等)作为相似度。这种方案相对来说比较简单,而且检索起来比较快速,一定程度上能满足工程需求。
-
5
numpy 的一维向量如何参与计算 作者: 张志强 ,...
-
5
如何计算两个文档的相似度(一) 浏览:4150次 出处信息 前几天,我发布了一个和...
-
5
相似度计算之马氏距离 浏览:814次 出处信息 马氏距离(Mahalanobis Distance)是由印度统计学家马哈拉诺比斯(...
-
3
常见相似度计算方法回顾 浏览:850次 出处信息 最近学习了常见的一些相似度计算的方法,在寻找资料的过程...
-
8
如果你的网站网页重复或者相似页面过多将会影响你网站的排名,那么如何计算网站内网页的相似度分布? 本文教你通过开发Python脚本使用TF-IDF算法计算网站全站页面相似度分布并可视化展示出来。 0. TF-IDF TF-IDF(英语:term frequenc...
-
6
若无云,岂有风——词语语义相似度计算简介 浏览:2105次 出处信息 诸多事物都要受到其周边事物的影响,进而改变自身...
-
11
相似词查询:玩转腾讯 AI Lab 中文词向量 Original 52nlp...
-
10
向量之间的距离(相似度)及用 Python 进行计算 2022-09-20 | 阅读(18) | 计算距离的目的也是为了确定两个向量的相似度,这里的向量可以是纯数学的数组,或者是一系列带有某些可量化特征值的物...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK