

Removing Duplicate Rows (Based on Values from Multiple Columns) From SQL Table
source link: https://www.geeksforgeeks.org/removing-duplicate-rows-based-on-values-from-multiple-columns-from-sql-table/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Removing Duplicate Rows (Based on Values from Multiple Columns) From SQL Table
In SQL, some rows contain duplicate entries in multiple columns(>1). For deleting such rows, we need to use the DELETE keyword along with self-joining the table with itself. The same is illustrated below. For this article, we will be using the Microsoft SQL Server as our database.
Step 1: Create a Database. For this use the below command to create a database named GeeksForGeeks.
Query:
CREATE DATABASE GeeksForGeeks
Output:

Step 2: Use the GeeksForGeeks database. For this use the below command.
Query:
USE GeeksForGeeks
Output:

Step 3: Create a table RESULT inside the database GeeksForGeeks. This table has 5 columns namely STUDENT_ID, PHYSICS_MARKS, CHEMISTRY_MARKS, MATHS_MARKS, and TOTAL_MARKS containing the id of the student, his/her marks in physics, chemistry, and mathematics, and finally his/her total marks.
Query:
CREATE TABLE RESULT( STUDENT_ID INT, PHYSICS_MARKS INT, CHEMISTRY_MARKS INT, MATHS_MARKS INT, TOTAL_MARKS INT);
Output:

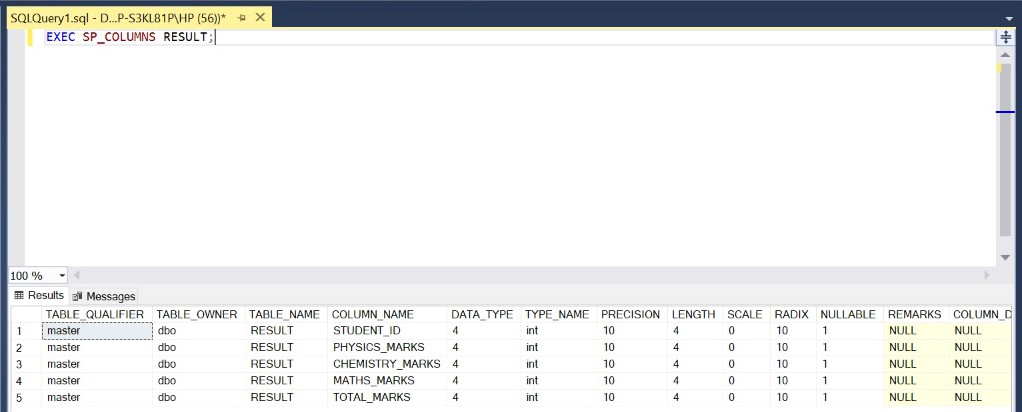
Step 4: Describe the structure of the table RESULT.
Query:
EXEC SP_COLUMNS RESULT;
Output:
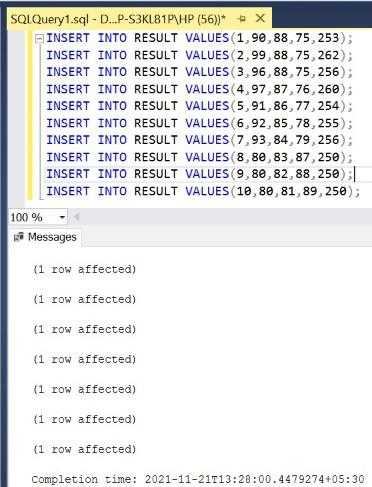
Step 5: Insert 10 rows into the RESULT table.
Query:
INSERT INTO RESULT VALUES(1,90,88,75,253); INSERT INTO RESULT VALUES(2,99,88,75,262); INSERT INTO RESULT VALUES(3,96,88,75,256); INSERT INTO RESULT VALUES(4,97,87,76,260); INSERT INTO RESULT VALUES(5,91,86,77,254); INSERT INTO RESULT VALUES(6,92,85,78,255); INSERT INTO RESULT VALUES(7,93,84,79,256); INSERT INTO RESULT VALUES(8,80,83,87,250); INSERT INTO RESULT VALUES(9,80,82,88,250); INSERT INTO RESULT VALUES(10,80,81,89,250);
Output:
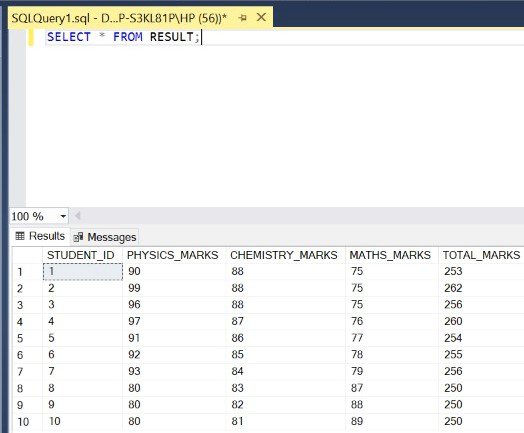
Step 6: Display all the rows of the RESULT table.
Query:
SELECT * FROM RESULT;
Output:
Step 7: Delete rows from the table RESULT which have duplicate entries in the columns CHEMISTRY_MARKS and MATHS_MARKS. To achieve this, we use the DELETE function by self joining(use JOIN function on 2 aliases of the table i.e. R1 and R2) the table with itself and comparing the entries of the columns CHEMISTRY_MARKS and MATHS_MARKS for different entries of the column STUDENT_ID because ID is unique for each student.
Syntax:
DELETE T1 FROM TABLE_NAME T1 JOIN TABLE_NAME T2 ON T1.COLUMN_NAME2 = T2.COLUMN_NAME2 AND T1.COLUMN_NAME3 = T2.COLUMN_NAME3 AND ....... AND T2.COLUMN_NAME1 < T1.COLUMN_NAME1;
Query:
DELETE R1 FROM RESULT R1 JOIN RESULT R2 ON R1.CHEMISTRY_MARKS = R2.CHEMISTRY_MARKS AND R1.MATHS_MARKS = R2.MATHS_MARKS AND R2.STUDENT_ID < R1.STUDENT_ID;
Output:

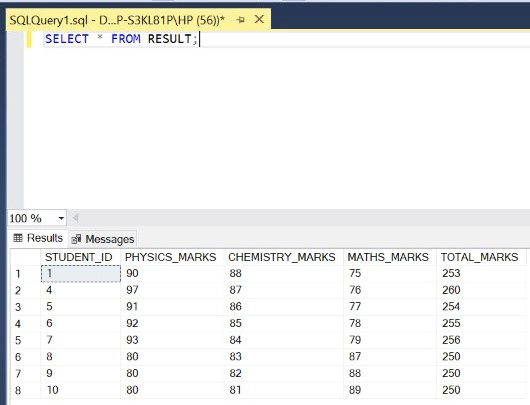
Step 8: Display all the rows of the updated RESULT table.
Query:
SELECT * FROM RESULT;
Note: No row has duplicate entries in the columns CHEMISTRY_MARKS and MATHS_MARKS.
Output:
Step 9: Delete rows from the table RESULT which have duplicate entries in the columns TOTAL_MARKS and PHYSICS_MARKS.
Query:
DELETE R1 FROM RESULT R1 JOIN RESULT R2 ON R1.TOTAL_MARKS = R2.TOTAL_MARKS AND R1.PHYSICS_MARKS = R2.PHYSICS_MARKS AND R2.STUDENT_ID < R1.STUDENT_ID;
Output:

Step 10: Display all the rows of the updated RESULT table.
Query:
SELECT * FROM RESULT;
Note – No row has duplicate entries in the columns TOTAL_MARKS and PHYSICS_MARKS.
Output:

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK