

可观测性数据收集集大成者 Vector 介绍 - SRETalk
source link: https://www.cnblogs.com/ulricqin/p/17762086.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

如果企业提供 IT 在线服务,那么可观测性能力是必不可少的。“可观测性” 这个词近来也越发火爆,不懂 “可观测性” 都不好意思出门了。但是可观测性能力的构建却着实不易,每个企业都会用到一堆技术栈来组装建设。比如数据收集,可能来自某个 exporter,可能来自 telegraf,可能来自 OTEL,可能来自某个日志文件,可能来自 statsd,收集到数据之后还需要做各种过滤、转换、聚合、采样等操作,烦不胜烦,今天我们就给大家介绍一款开源的数据收集+路由器工具:Vector,解除你的上述烦恼。
Vector 简介
Vector 通常用作 logstash 的替代品,logstash 属于 ELK 生态,使用广泛,但是性能不太好。Vector 使用 Rust 编写,声称比同类方案快 10 倍。Vector 来自 Datadog,如果你了解监控、可观测性,大概率知道 Datadog,作为行业老大哥,其他小弟拍马难及。Datadog 在 2021 年左右收购了 Vector,现在 Vector 已经开源,地址是:
Vector 不止是收集、路由日志数据,也可以路由指标数据,甚至可以从日志中提取指标,功能强大。下面是 Vector 的架构图:
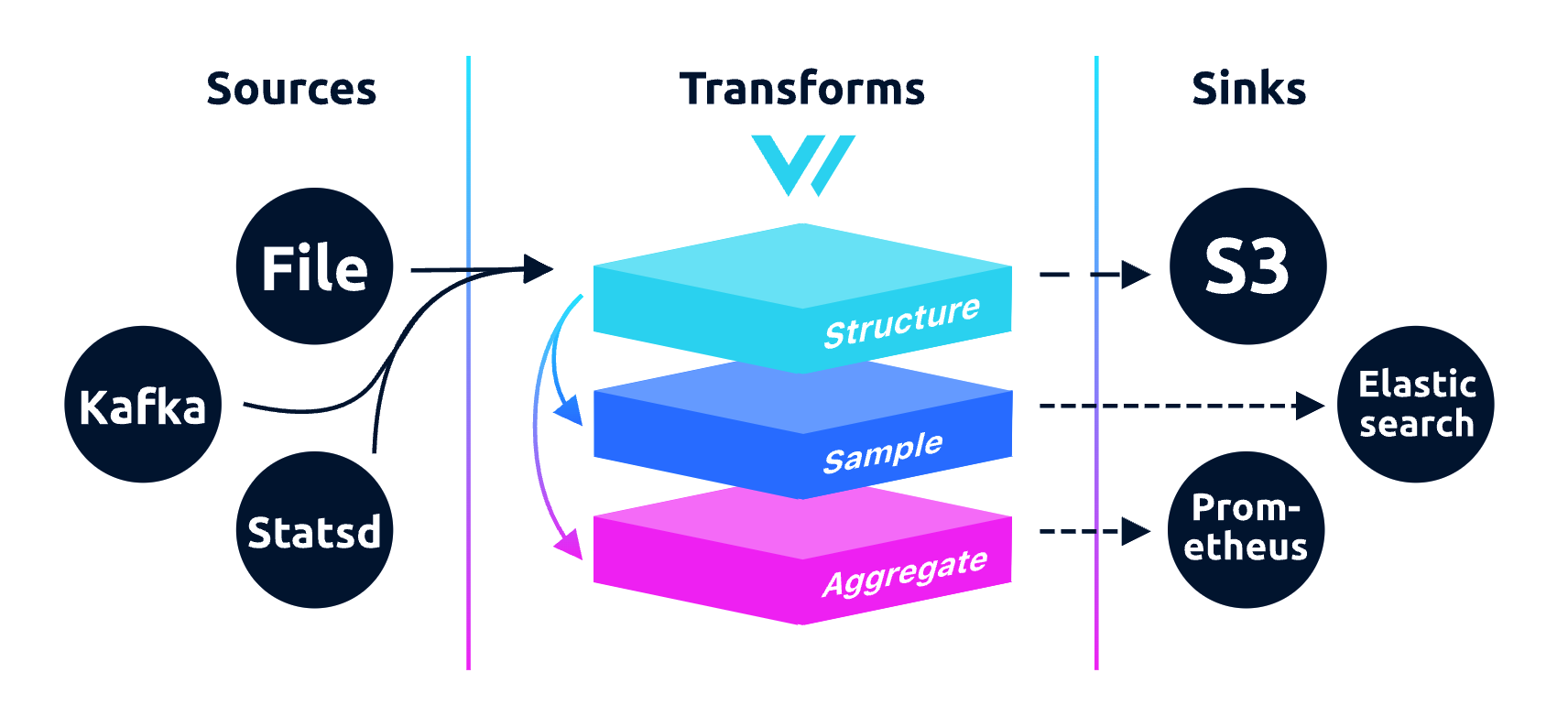
看起来和其他同类产品是类似的,核心就是 pipeline 的处理,有 Source 端做采集,有中间的 Transform 环节做数据加工处理,有 Sink 端做数据转发。魔鬼在细节,Vector 有如下一些特点,让它显得卓尔不群:
- 超级快速可靠:Vector采用Rust构建,速度极快,内存效率高,旨在处理最苛刻的工作负载
- 端到端:Vector 致力于成为从 A 到 B 获取可观测性数据所需的唯一工具,并作为守护程序、边车或聚合器进行部署
- 统一:Vector 支持日志和指标,使您可以轻松收集和处理所有可观测性数据
- 供应商中立:Vector 不偏向任何特定的供应商平台,并以您的最佳利益为出发点,培育公平、开放的生态系统。免锁定且面向未来
- 可编程转换:Vector 的高度可配置转换为您提供可编程运行时的全部功能。无限制地处理复杂的用例
Vector 安装
Vector 的安装比较简单,一条命令即可搞定,其他安装方式可以参考其 官方文档。
curl --proto '=https' --tlsv1.2 -sSf https://sh.vector.dev | bashVector 配置测试
Vector 的配置文件可以是 yaml、json、toml 格式,下面是一个 toml 的例子,其作用是读取 /var/log/system.log 日志文件,然后把 syslog 格式的日志转换成 json 格式,最后输出到标准输出:
[sources.syslog_demo]
type = "file"
include = ["/var/log/system.log"]
data_dir = "/Users/ulric/works/vector-test"
[transforms.remap_syslog]
inputs = [ "syslog_demo"]
type = "remap"
source = '''
structured = parse_syslog!(.message)
. = merge(., structured)
'''
[sinks.emit_syslog]
inputs = ["remap_syslog"]
type = "console"
encoding.codec = "json"首先,[sources.syslog_demo] 定义了一个 source,取名为 syslog_demo,这个 source 的类型是 file,表示从文件中读取数据,文件路径是 /var/log/system.log,data_dir 是存储 checkpoint 数据不用关心,只要给一个可写的目录就行(Vector 自用)。然后定义了一个 transform,名字为 remap_syslog,指定这个 transform 的数据来源(即上游)是 syslog_demo,其类型是 remap,remap 是 Vector 里非常重要的一个 transform,可以做各类数据转换,在 source 字段里定义了一段代码,其工作逻辑是:
- 来自 syslog_demo 这个 source 的日志数据,日志原文在 message 字段里(除了日志原文 message 字段,Vector 还会对采集的数据附加 host、timestamp 等字段),需要先解析成结构化的数据,通过 parse_syslog 这个函数做转换
- 转换之后,相当于把非结构化的日志数据转换成了结构化的数据,赋值给 structured 变量,然后通过 merge 函数把结构化的这个数据和原始就有的 host、timestamp 等字段合并,然后把合并的结果继续往 pipeline 后续环节传递
[sinks.emit_syslog] 定义了一个 sink,名字是 emit_syslog,通过 inputs 指明了上游数据来自 remap_syslog 这个 transform,通过 type 指明要把数据输出给 console,即控制台,然后通过 encoding.codec 指定输出的数据格式是 json。然后通过下面的命令启动 Vector:
vector -c vector.toml然后,你就会看到一堆的日志输出(当然,前提是你的机器上有 system.log 这个文件,我是 macbook,所以用的这个文件测试的),样例如下:
ulric@ulric-flashcat vector-test % vector -c vector.toml
...
{"appname":"syslogd","file":"/var/log/system.log","host":"ulric-flashcat.local","hostname":"ulric-flashcat","message":"ASL Sender Statistics","procid":332,"source_type":"file","timestamp":"2023-09-27T07:31:22Z"}如上,就说明正常采集到了数据,而且转换成了 json 并打印到了控制台,实验成功。当然,打印到控制台只是个测试,Vector 可以把数据推给各类后端,典型的比如 ElasticSearch、S3、ClickHouse、Kafka 等。
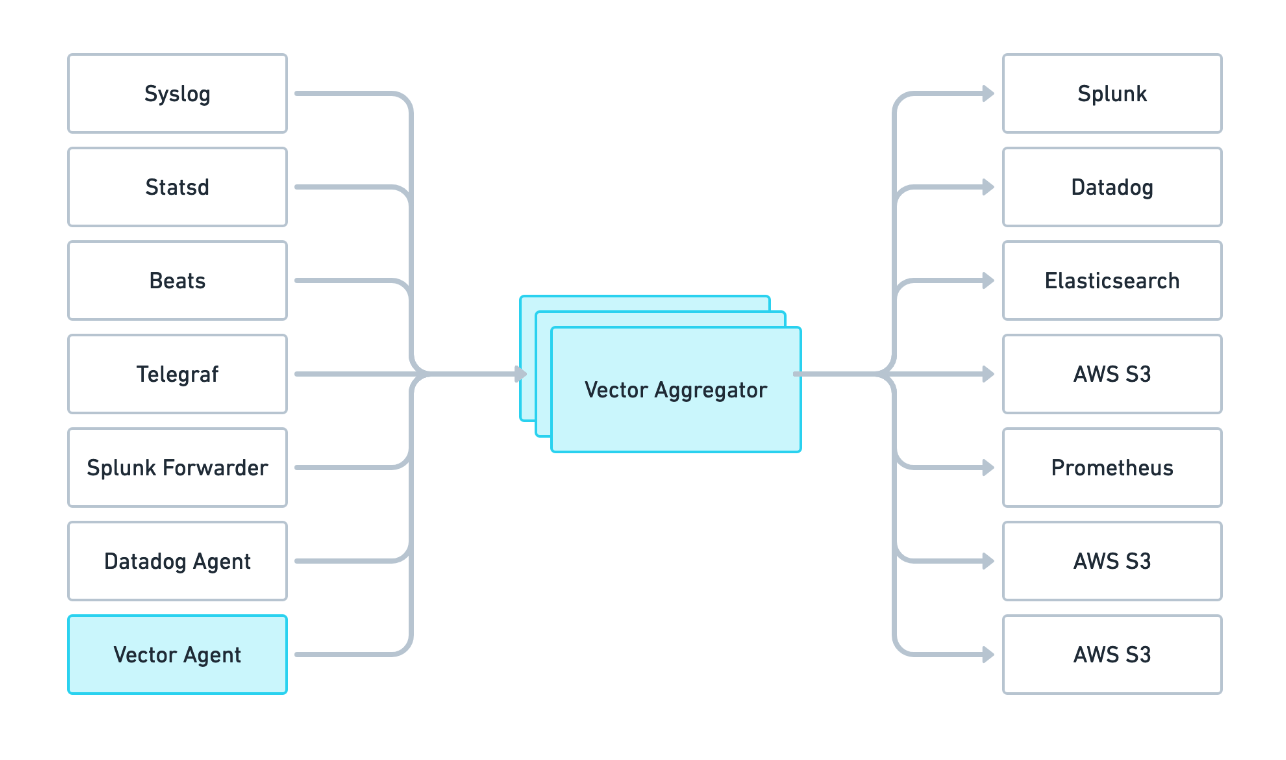
Vector 部署模式
Vector 可以部署为两个角色,既可以作为数据采集的 agent,也可以作为数据聚合、路由的 aggregator,架构示例如下:
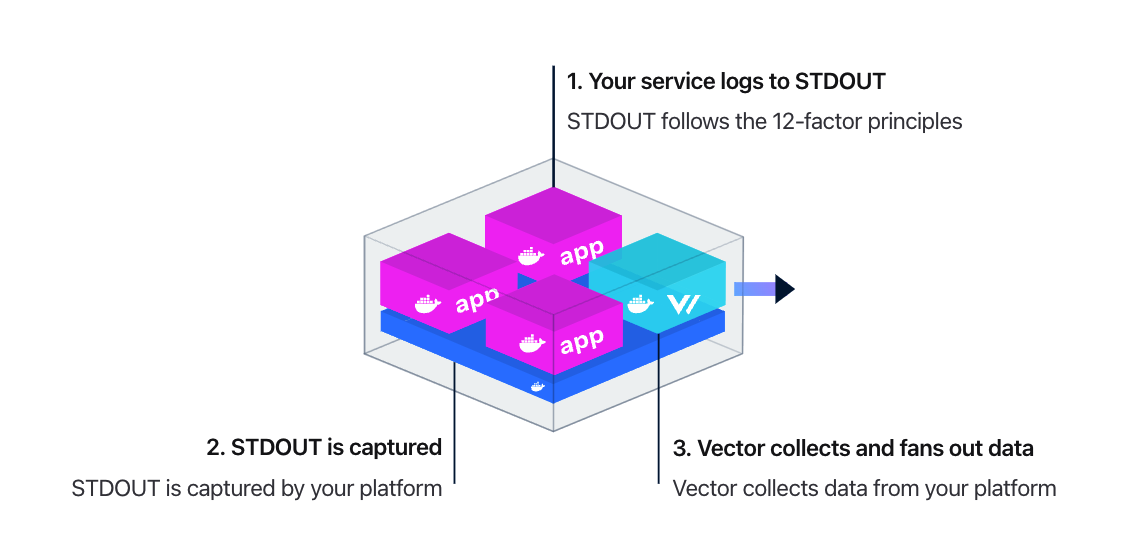
当 Vector 作为 agent 的时候,又有两种使用模式:Daemon 和 Sidecar。Daemon 模式旨在收集单个主机上的所有数据,这是数据收集的推荐方式,因为它最有效地利用主机资源。比如把 Vector 部署为 DaemonSet,收集这个机器上的所有容器中应用的日志,容器中的应用的日志推荐使用 stdout 方式打印,符合云原生 12 条要素。架构图如下:
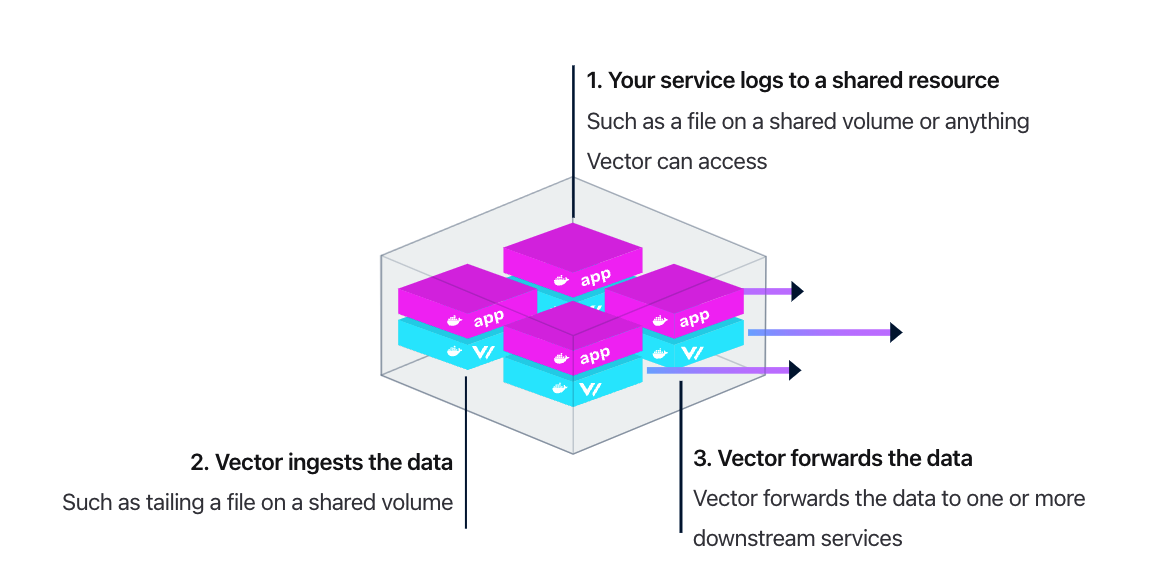
当然,也可以使用 Sidecar 模式部署,这样占用的资源更多(毕竟,每个 Pod 里都要塞一个 Vector 容器),但是更灵活,服务所有者可以随意搞自己的日志收集方案,不用依赖统一的日志收集方案。架构图如下:
Vector 总结
夜莺社区里已经有很多小伙伴从 logstash 迁移到了 Vector,并普遍表示 Vector YYDS,如果你还没听过 Vector,赶紧去试试吧。其他的我也不啰嗦,请各位移步 Vector 官方文档,本文最重要的价值就是让你知道有这么个好东西 :-)
扩展阅读:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK