

英伟达25年路线图惊爆流出!老黄豪赌B100暴打AMD,秘密武器X100曝光
source link: https://www.51cto.com/article/769442.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

英伟达25年路线图惊爆流出!老黄豪赌B100暴打AMD,秘密武器X100曝光
英伟达的AI硬件霸主,当得太久了!
现在,各大科技公司都在虎视眈眈,等着一举颠覆它的霸主之位。
当然,英伟达也不会坐以待毙。
最近,外媒SemiAnalysis曝出了一份英伟达未来几年的硬件路线图,包括万众瞩目的H200、B100和「X100」GPU。

随之一同流出的,还有一些硬核信息,包括英伟达的工艺技术计划、HBM3E的速度/容量、PCIe 6.0、PCIe 7.0、NVLink、1.6T 224G SerDes计划。
如果这些计划如愿成功,英伟达将继续成功碾压对手。
当然,霸主之位也没这么好当——AMD的MI300、MI400,亚马逊的Trainium2,微软的Athena,英特尔的Gaudi 3,都不会让英伟达好过。
准备好,前方高能来袭!
英伟达,不止想做硬件霸主
谷歌早已开始布局自己的AI基础设施,他们构建的TPUv5和TPUv5e,既可以用于内部的训练和推理,也可以给苹果、Anthropic、CharacterAI、MidJourney等外部客户使用。
谷歌不是英伟达唯一的威胁。
在软件方面,Meta的PyTorch2.0和OpenAI的Triton也在迅猛发展,使其他硬件供应商得以实现兼容。
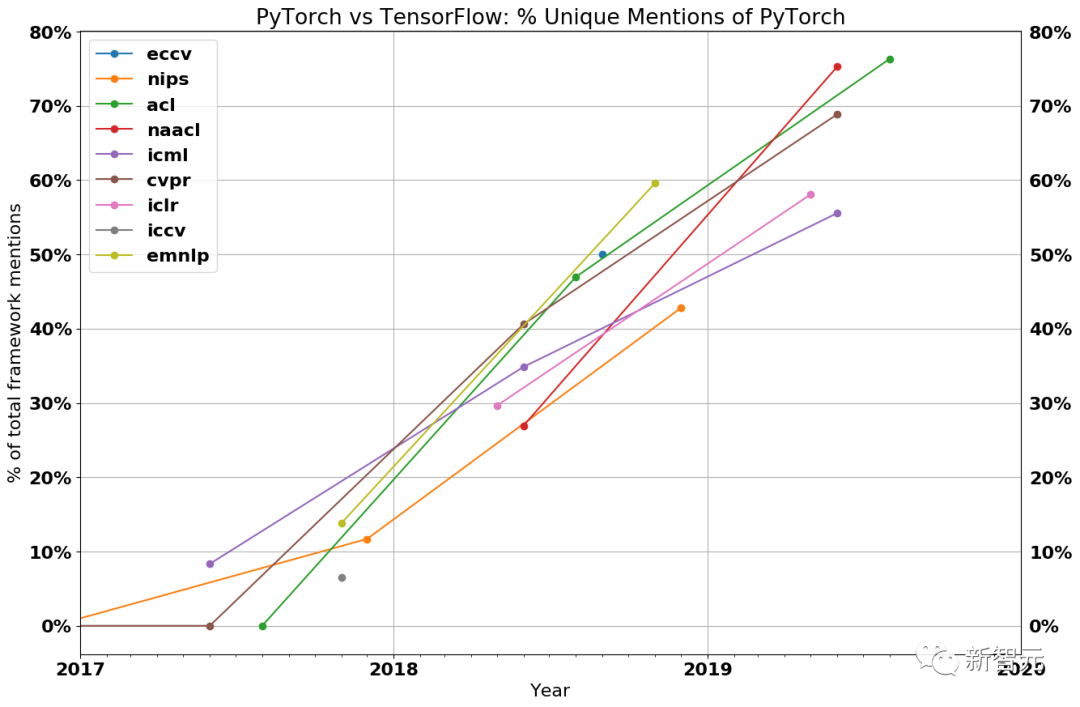
现在,软件上的差距仍然存在,但远不及从前那么巨大了。
在软件堆栈上,AMD的GPU、英特尔的Gaudi、Meta的MTIA和微软的Athena都取得了一定程度的发展。
尽管英伟达仍然保持着硬件领先地位,但差距的缩小,会越来越快。
英伟达H100,也不会独领风骚太久。
在接下来的几个月内,无论是AMD的MI300,还是英特尔的Gaudi 3,都将推出技术上优于H100的硬件产品。

而除了谷歌、AMD、英特尔这些难缠的对手,还有一些公司,也给了英伟达不小的压力。
这些公司虽然在硬件设计上暂时落后,但能得到背后巨头的补贴——天下苦英伟达久矣,这些公司都希望打破英伟达在HBM上的巨额利润垄断。
亚马逊即将推出的Trainium2和Inferentia3, 微软即将推出的Athena,都是已布局多年的投资。
竞争对手来势汹汹,英伟达当然也不会坐以待毙。
在外媒SemiAnalysis看来,无论管理风格还是路线决策,英伟达都是「行业中最多疑的公司之一」。
而黄仁勋身上,体现了一股安迪·格鲁夫的精神。
成功导致自满。自满导致失败。只有偏执狂才能生存。
为了稳坐第一把交椅,英伟达野心勃勃,采取了多管齐下的冒险策略。
他们已经不屑于再和英特尔、AMD在传统的市场上竞争,而是想成为谷歌、微软、亚马逊、Meta、苹果这样的科技巨头。

而英伟达的DGX Cloud、软件,以及针对非半导体领域的收购策略,背后都是一盘大棋。
路线图最新细节曝光!
英伟达最新路线图的重要细节,已经被曝光。
内容包括所采用的网络、内存、封装和工艺节点,各种GPU、SerDes选择、PCIe6.0、协同封装光学器件和光路交换机等细节。
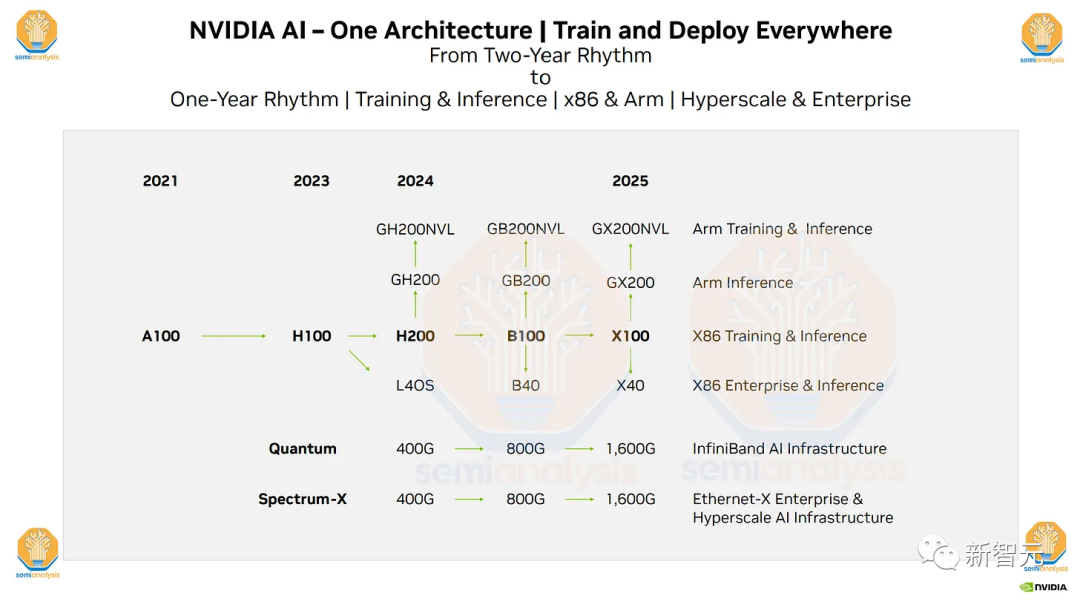
显然,慑于谷歌、亚马逊、微软、AMD和英特尔的竞争压力,英伟达连夜加快了B100和「X100」的研发。
B100:上市时间高于一切
根据内部消息,英伟达的B100将于2024年第三季度量产,部分早期样品将于2024年第二季度出货。
从性能和TCO看,无论是亚马逊的Trainium2、谷歌的TPUv5、AMD的MI300X,还是英特尔的Gaudi 3或微软的Athena,跟它相比都弱爆了。

即使考虑到从设计合作方、AMD或台积电获得的补贴,它们也统统打不过。
为了尽快将B100推向市场,英伟达做了不少妥协。
比如,英伟达本想把功耗定在更高的水平(1000W),但最终,他们还是选择了继续使用H100的700W。
这样,B100推出时,就能继续使用风冷技术。

此外,在B100早期系列,英伟达也会坚持使用PCIe5.0。
5.0和700W的组合意味着,它可以直接插入现有的H100 HGX服务器中,从而大大提高供应链能力,更早地量产和出货。
之所以决定坚持使用5.0,还有部分原因是,AMD和英特尔在PCIe6.0集成上还远远落后。而即使英伟达自己的内部团队,也没有准备好使用PCIe6.0CPU。
此外,他们还将使用速度更快的C2C式链接。

在以后,ConnectX-8会配备一款集成的PCIe6.0交换机,但目前还没人准备好。
据悉,博通和AsteraLabs要到年底才能准备好量产的PCIe6.0重定时器,而考虑到这些基板的尺寸,所需的重定时器只会更多。
这也意味着,最初的B100将被限制在3.2T,使用ConnectX-7时的速度也仅仅是400G,而非英伟达在PPT上所宣称的每个GPU 800G。
如果保持空气冷却,电源、PCIe和网络速度不变,那无论是制造还是部署,都会很容易。

稍后,英伟达会推出一个需要水冷的1,000W+版本B100。
这一版B100将通过ConnectX-8,为每个GPU提供完整的800G网络连接。
对于以太网/InfiniBand,这些SerDes仍然是8x100G。
虽然每个GPU的网络速度提高了一倍,但基数却减半了,因为它们仍需通过相同的51.2T交换机。而102.4T交换机,在B100一代中将不再使用。
有趣的是,有爆料称B100上的NVLink组件将采用224G SerDes,如果英伟达真能做到这一点,无疑是巨大的进步。
大多数人业内人士都认为,224G并不可靠,2024年不可能实现,但英伟达的人除外。
要知道,无论是谷歌、Meta,还是亚马逊,他们的224G AI加速器量产目标都定在2026/2027年。
如果英伟达在2024/2025年就实现了这一点,铁定会把对手们打得落花流水。

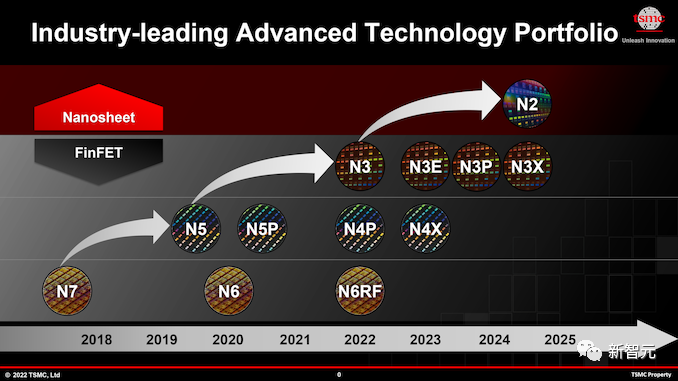
据悉,B100仍然是台积电的N4P,而不是基于3nm工艺的技术。
显然,对于如此大的芯片尺寸,台积电的3nm工艺尚未成熟。
根据英伟达基板供应商Ibiden透露的基板尺寸,英伟达似乎已经转而采用由2个单片大芯片MCM组成的设计,包含8或12个HBM堆叠。
SambaNova和英特尔明年的芯片,都采用了类似的宏观设计。
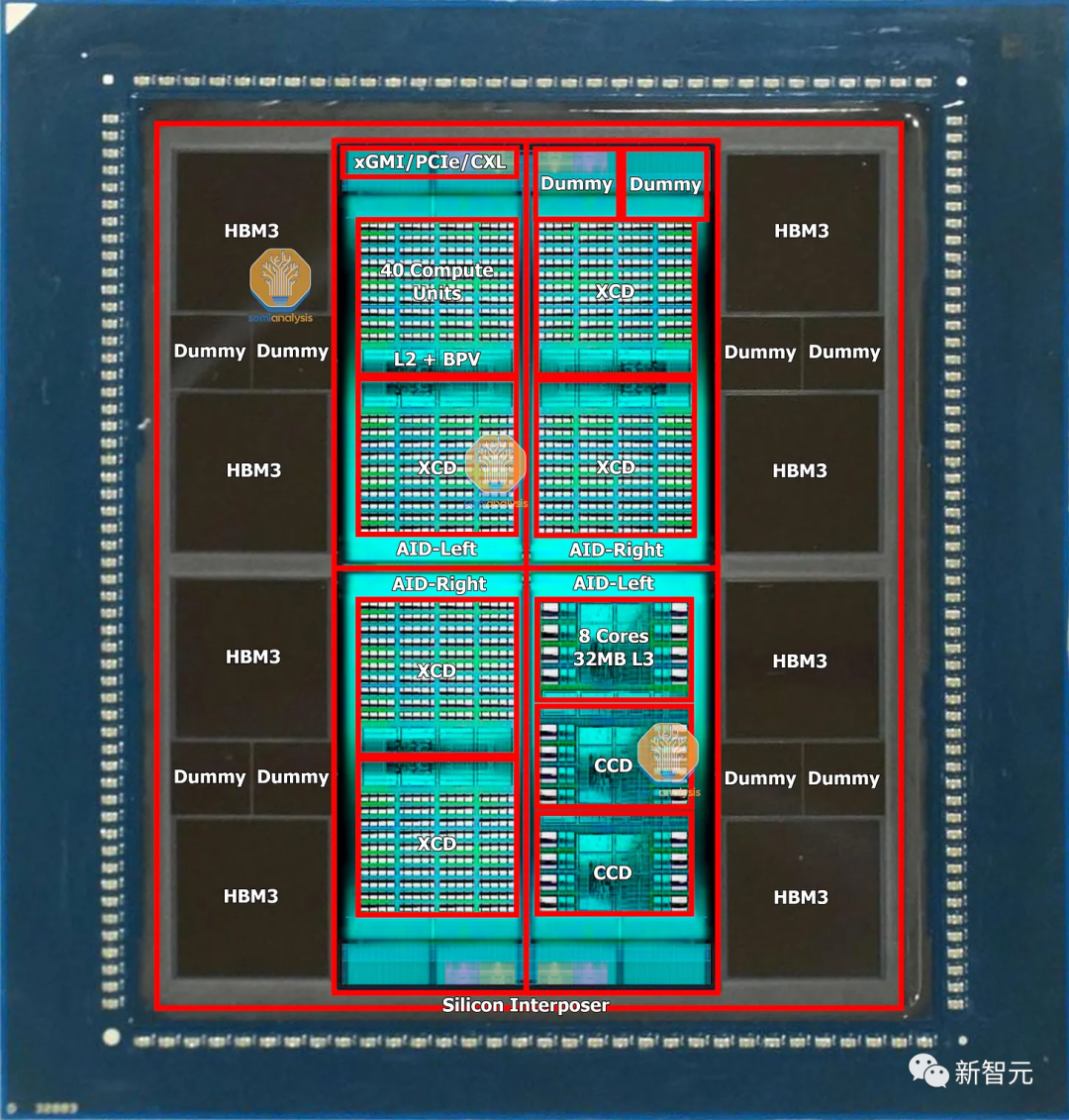
英伟达之所以没有像AMD那样使用混合键合技术,是因为他们需要量产,而成本就是他们的一大顾虑。
据SemiAnalysis估测,这两款B100芯片的内存容量将与AMD的MI300X相近或更高,达到24GB堆叠。
风冷版B100的速度可达6.4Gbps,而液冷版可能高达9.2Gbps。
另外,英伟达还在路线图中展示了GB200和B40。
GB200和GX200都使用了G,显然这是一个占位符,因为英伟达将推出基于Arm架构的新CPU。并不会长期使用Grace。
B40很可能只是B100的一半,只有一个单片N4P芯片,和最多4或6层的HBM。与L40S不同,这对于小模型的推理是很有意义的。
「X100」:致命一击
曝出的路线图中最惹人注意的,就是英伟达的「X100」时间表了。
有趣的是,它与AMD目前的MI400时间表完全吻合。就在H100推出一年后,AMD发布了MI300X战略。
AMD给MI300X的封装令人印象深刻,他们大量塞入了更多的计算和内存,希望能超越一年前的H100,从而在纯硬件上超越英伟达。
英伟达也发现了,他们两年一次发布新GPU的节奏,给了竞争对手大好的机会抢夺市场。
被逼急了的英伟达,正在把产品周期加快到每年一次,不给对手任何机会。比如,他们计划于2025年推出「X100」,仅仅比B100晚一年。
当然,「X100」目前还并未量产(不像B100),所以一切还悬而未决。
要知道,在过去,英伟达可从来不会讨论下一代产品之后的产品,这次已经是史无前例了。
而且,名字大概率也不叫「X100」。
英伟达一直以来的传统,都是以Ada Lovelace、Grace Hopper和Elizabeth Blackwell等杰出女科学家的名字来命名GPU的。
至于「X」,唯一符合逻辑的就是研究半导体和金属带结构的Xie Xide,但考虑到她的身份,概率应该不大。

供应链大师:老黄的豪赌
自英伟达成立之初,黄仁勋就一直在积极推动着对供应链的掌握,从而支持庞大的增长目标。
他们不仅愿意承担不可取消的订单——高达111.5亿美元的采购、产能和库存承诺,并且还有38.1亿美元的预付款协议。
可以说,没有一家供应商能与之相提并论。
而英伟达的事迹也不止一次表明,他们可以在供应短缺时创造性地增加供应量。

2007年黄仁勋与张忠谋的对话
1997年,张忠谋和我相遇时,只有100人的英伟达在那一年完成了2700万美元的收入。
你们可能不相信,但张忠谋以前经常打电话推销,并且还会上门拜访。而我则会向张忠谋解释英伟达是做什么的,以及我们的芯片尺寸需要多大,而且每年都会越来越大。
后来,英伟达总共做了1.27亿个晶圆。从那时起,英伟达每年增长近100%,直到现在。也就是在过去10年中,复合年增长率达到了70%左右。
当时,张忠谋无法相信英伟达需要如此多的晶圆,但黄仁勋坚持了下来。
英伟达通过在供应方面的大胆尝试,取得了巨大成功。虽然时不时要减记价值数十亿美元的库存,但他们仍然从过度的订购中获得了正收益。
这次,英伟达直接抢占了GPU上游组件的大部分供应——
他们向SK海力士、三星和美光这3家HBM供应商下了非常大的订单,挤占了除博通和Google之外其他所有人的供应。同时,还买下了台积电CoWoS的大部分供应,以及Amkor的产能。
此外,英伟达还充分利用了HGX板卡和服务器所需的下游组件,如重定时器、DSP、光学器件等。
如果供应商对英伟达要求置若罔闻,那么就会面对老黄的「萝卜加大棒」——
一方面,他们会从英伟达获得难以想象的订单;另一方面,他们可能会被英伟达从现有的供应链中剔除。
当然,英伟达也只有在供应商至关重要且无法被淘汰或多元化供应的情况下,才会使用承诺和不可取消的订单。

每个供应商似乎都认为自己是AI的赢家,部分原因是因为英伟达向所有供应商都下了大量的订单,而他们也都认为自己赢得了大部分业务。但实际上,只是因为英伟达的增长速度太快了。
回到市场动态上,虽然英伟达的目标是在明年实现超过700亿美元的数据中心销售额,但只有谷歌在上游有足够的产能——拥有超过100万台的设备。AMD在AI领域的总产能仍然非常有限,最高也不过几十万台。
商业策略:潜在的反竞争
众所周知,英伟达正在利用对GPU的巨大需求,来向客户推销和交叉销售产品。
供应链中有大量信息透露,英伟达会根据一系列因素向某些公司提供优先分配。包括但不限于:多元化采购计划、自主研发AI芯片计划、购买英伟达的DGX、NIC、交换机和/或光学设备等。
事实上,英伟达的捆绑销售非常成功。尽管之前只是一家规模很小的光纤收发器供应商,但他们的业务量在一个季度内增长了两倍,预计明年的出货量将超过10亿美元——远远超过了自家GPU或网络芯片业务的增长速度。
这些策略,可以说是相当周密。
比如,想要在英伟达的系统上实现3.2T网络和可靠的RDMA/RoCE,唯一方法就是使用英伟达的NIC。当然,一方面也是因为英特尔、AMD和博通的产品实在是缺乏竞争力——仍然停留在200G的水平上。
而通过对供应链的管理,英伟达还促使400G InfiniBand NIC的交付周期,能够比400G以太网NIC明显缩短。而这两种NIC(ConnectX-7)在芯片和电路板设计上,其实是完全相同的。
其原因在于英伟达的SKU配置,而非实际的供应链瓶颈——迫使企业不得不购买成本更高的InfiniBand交换机,而不是标准的以太网交换机。
这还不止,看看供应链对L40和L40S GPU有多么着迷,就知道英伟达又在分配上做手脚了——为了赢得更多H100的分配,OEM厂商就需要购买更多的L40S。
这与英伟达在PC领域的操作,也是如出一辙——笔记本制造商和AIB合作伙伴必须购买更大量的G106/G107(中/低端GPU)才能获得更稀缺、更高利润的G102/G104(高端和旗舰GPU)。
作为配合,供应链中的人也被灌输了这样的说法——L40S比A100更好,因为它具有更高的FLOPS。
但实际上,这些GPU并不适合LLM推理,因为它们的显存带宽还不到A100的一半,而且也没有NVLink。
这意味着在L40S上运行LLM并实现良好的TCO几乎是不可能的,除非是非常小的模型。而大批量的处理也会导致分配到每个用户上的token/s几乎是不可用的,从而使理论上的FLOPS在实际应用中变得毫无用处。

此外,英伟达的MGX模块化平台,虽然省去了服务器设计的艰苦工作,但也同时降低了OEM的利润率。
戴尔、惠普和联想等公司显然对MGX持抵制态度,但诸如超微、广达、华硕、技嘉等公司则争相填补这一空白,将低成本的「企业人工智能」商品化。
而这些参与L40S和MGX炒作的OEM/ODM,也可以从英伟达那里获得更好的主线GPU产品分配。
光电共封装(Co-Packaged Optics)
在CPO方面,英伟达也是相当重视。
他们一直在研究各种解决方案,包括来自Ayar Labs的解决方案,以及他们自己从Global Foundries和台积电获得的解决方案。

目前,英伟达已经考察了几家初创公司的CPO方案,但暂时还没有做出最终的决定。
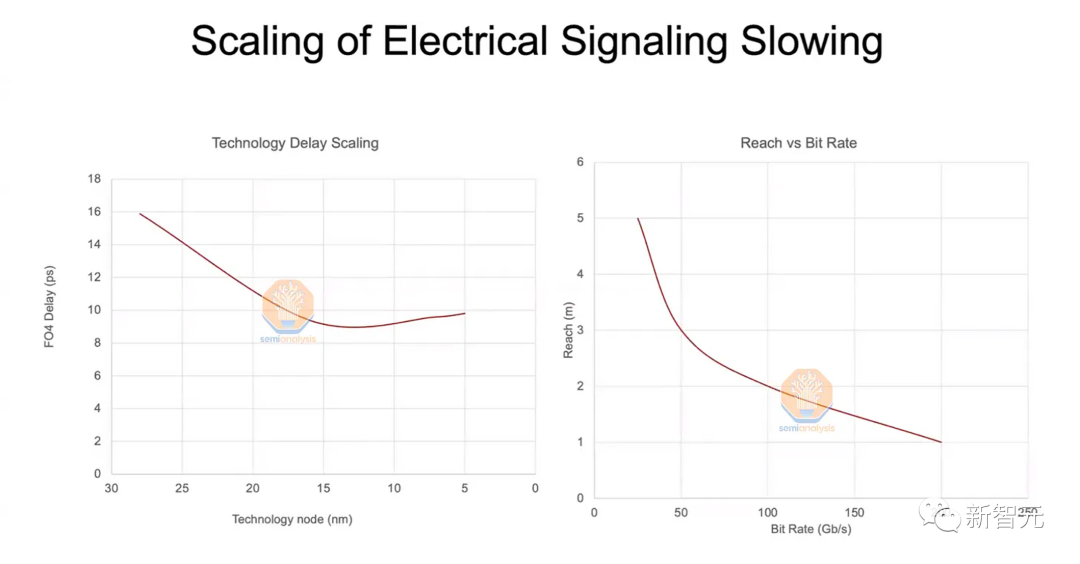
分析认为,英伟达很有可能将CPO集成到「X100」的NVSwitch上。
因为直接集成到GPU本身可能成本太高,而且在可靠性方面也很困难。
光路交换机(Optical Circuit Switch)
谷歌在人工智能基础设施方面最大的优势之一,就是它的光路交换机。
显然,英伟达也在追求类似的东西。目前,他们已经接触了多家公司,希望能够进行合作开发。
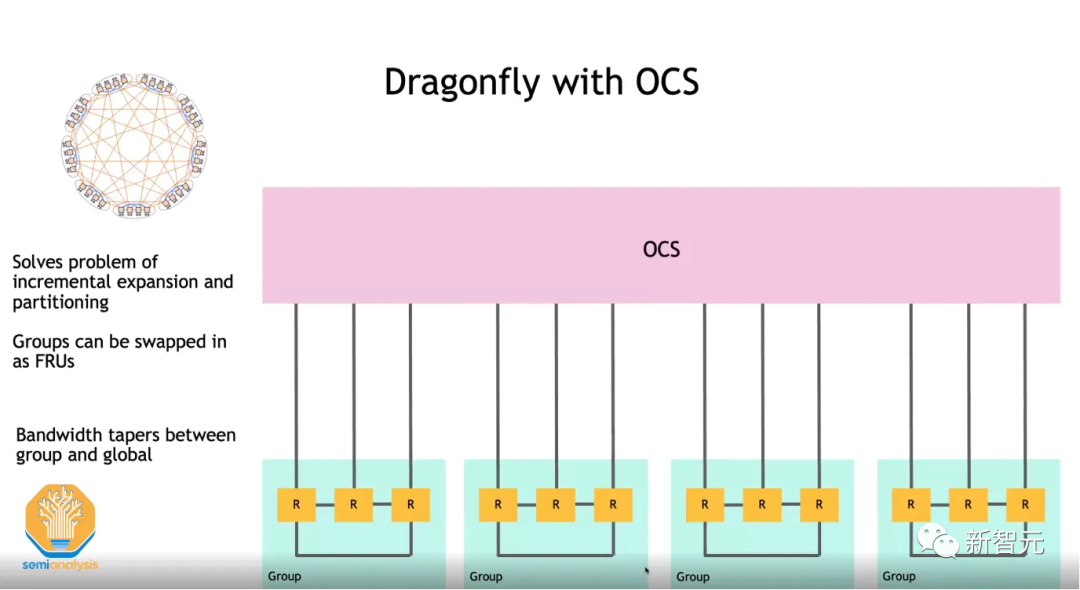
英伟达意识到,Fat Tree在继续扩展方面已经走到了尽头,因此需要另一种拓扑结构。
与谷歌选择6D Torus不同,英伟达更倾向于采用Dragonfly结构。
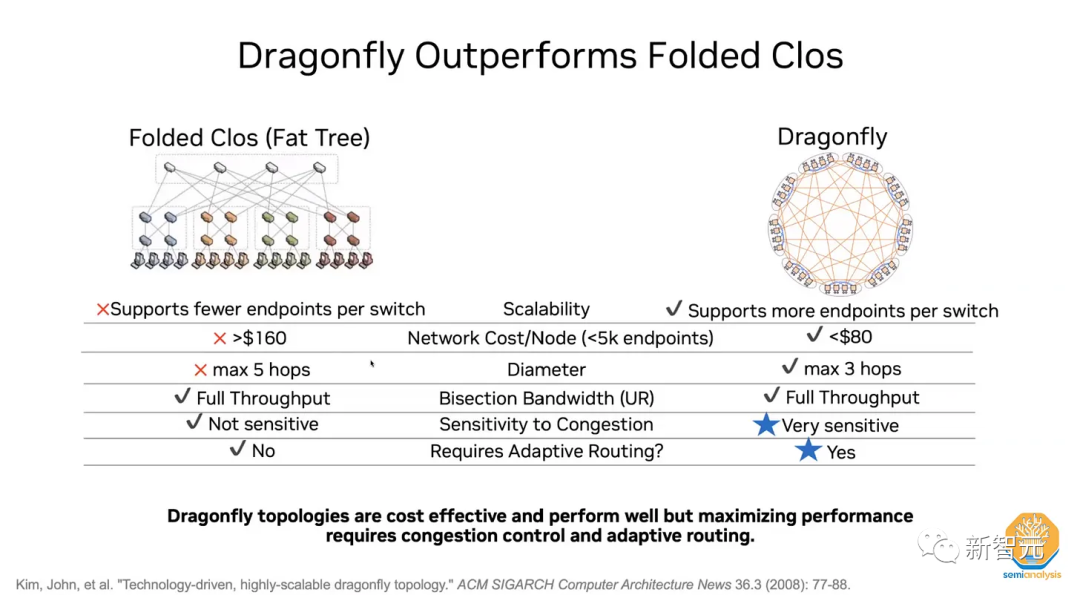
据了解,英伟达距离OCS的出货还遥遥无期,但他们希望在2025年时能够更加接近这一目标,但大概率无法实现。
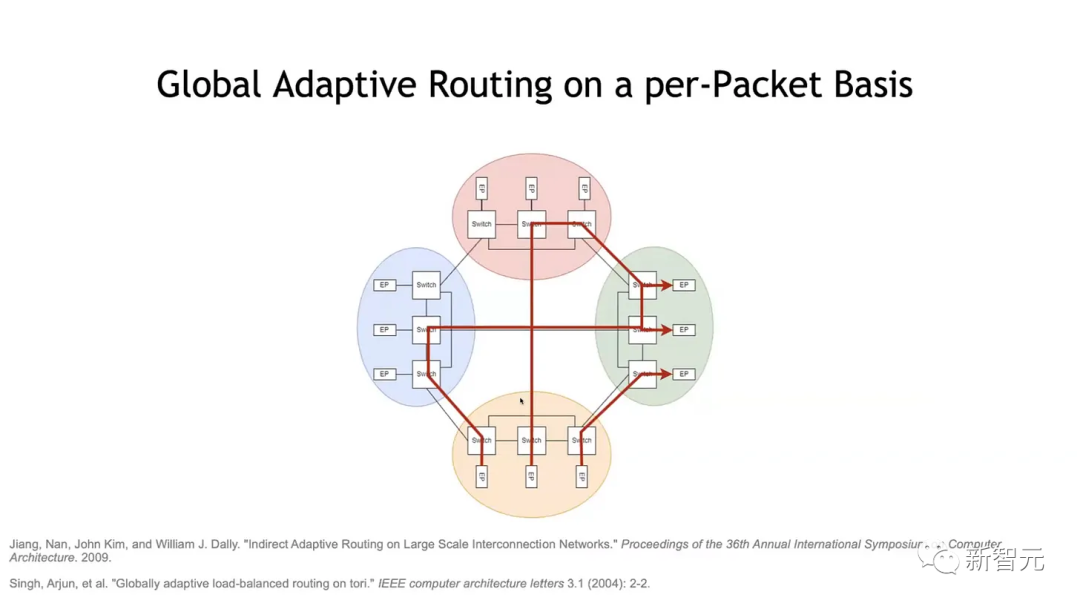
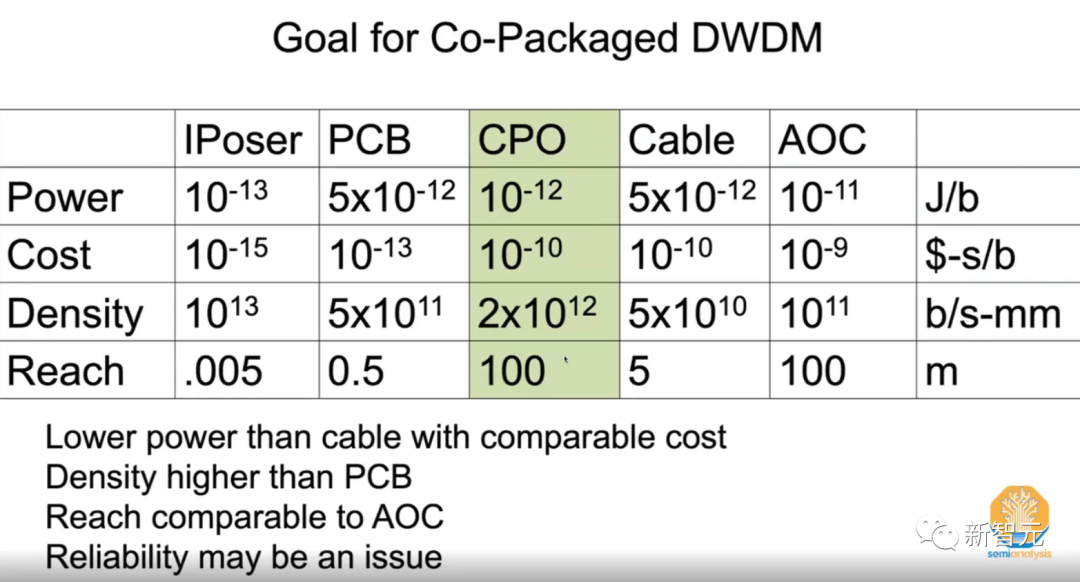
OCS + CPO是圣杯,尤其是当OCS可以实现按数据包交换时,将会直接改变游戏规则。
不过,目前还没有人展示过这种能力,甚至连谷歌也没有。
虽然英伟达的OCS和CPO还只是研究部门的两套PPT,但分析人士认为,CPO会在2025至2026年内离产品化更进一步。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK