

AmodalSynthDrive:一个用于自动驾驶的合成非模态感知数据集
source link: https://www.51cto.com/article/769398.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

AmodalSynthDrive:一个用于自动驾驶的合成非模态感知数据集
本文经自动驾驶之心公众号授权转载,转载请联系出处。

- 论文链接:https://arxiv.org/pdf/2309.06547.pdf
- 数据集链接:http://amodalsynthdrive.cs.uni-freiburg.de
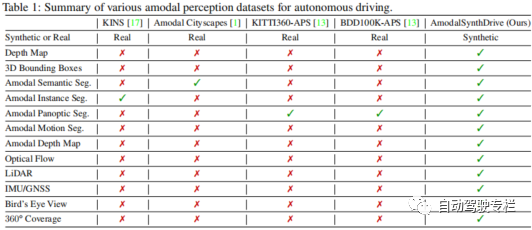
本文介绍了AmodalSynthDrive:一个用于自动驾驶的合成非模态感知数据集。与人类不同,即使在部分遮挡的情况下,人类也可以毫不费力地估计物体的整体,而现代计算机视觉算法仍然发现这一方面极具挑战性。由于缺乏合适的数据集,利用这种非模态感知进行自动驾驶在很大程度上仍未得到开发。这些数据集的生成主要受到昂贵标注成本的影响,以及需要减轻标注者在准确标注遮挡区域的主观性带来的干扰。为了解决这些限制,本文引入了AmodalSynthDrive,这是一种合成的多任务非模态感知数据集。该数据集提供了150个驾驶序列的多视图相机图像、3D边界框、激光雷达数据和里程计,其包括了在各种交通、天气和光照条件下超过1M的目标标注。AmodalSynthDrive支持多种非模态场景理解任务,包括引入的非模态深度估计用于增强空间理解。本文为每项任务评估若干基线,以说明挑战并且设置公开基准服务器。
本文的贡献总结如下:
1)本文提出了AmodalSynthDrive数据集,这是一种针对城市驾驶场景的全面合成非模态感知数据集,具有多种数据来源;
2)本文提出了针对非模态感知任务的基准,即非模态语义分割、非模态实例分割和非模态全景分割;
3)新型的非模态深度估计任务旨在促进增强空间理解。本文通过若干基线证明了这项新任务的可行性。
论文图片和表格



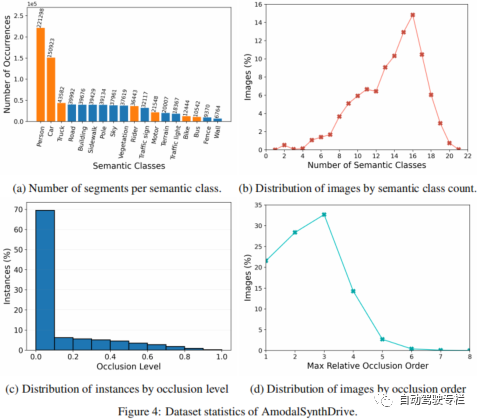
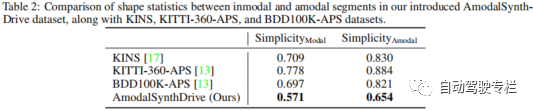
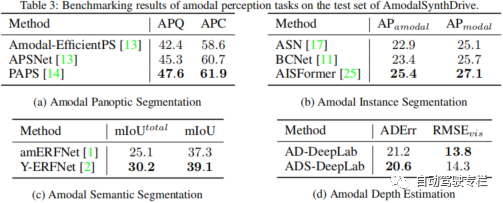
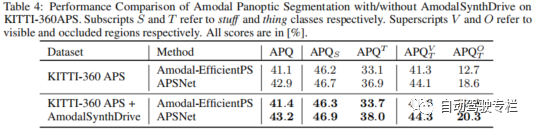
感知是自动驾驶汽车的一项关键任务,但是目前的方法仍然缺少对复杂交通场景解释所需的非模态理解。为此,本文提出了AmodalSynthDrive,这是一个用于自动驾驶的多模态合成感知数据集。通过合成的图像和激光雷达点云,我们提供了一个全面的数据集,其包括用于基本非模态感知任务的真值标注数据,同时还引入一种新的任务来增强空间理解,称为非模态深度估计。本文提供了超过60000个单独的图像集,每个图像集与非模态实例分割、非模态语义分割、非模态全景分割、光流、2D&3D边界框、非模态深度以及鸟瞰图相关。通过AmodalSynthDrive,本文提供了各种基线,并且相信这项工作将为动态城市环境的非模态场景理解的新型研究铺平道路。

原文链接:https://mp.weixin.qq.com/s/7cXqFbMoljcs6dQOLU3SAQ
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK