

世界模型立大功!这造假的20多种自动驾驶场景数据太逼真了......
source link: https://www.51cto.com/article/769058.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

世界模型立大功!这造假的20多种自动驾驶场景数据太逼真了......
本文经自动驾驶之心公众号授权转载,转载请联系出处。
你以为这是个平平无奇的自动驾驶视频?

NO、NO、NO……这其实是完全由AI从头生成的。
没有一帧是“真的”。

不同路况、各种天气,20多种情况都能模拟,效果以假乱真。

世界模型再次立大功了!这不LeCun看了都激情转发。
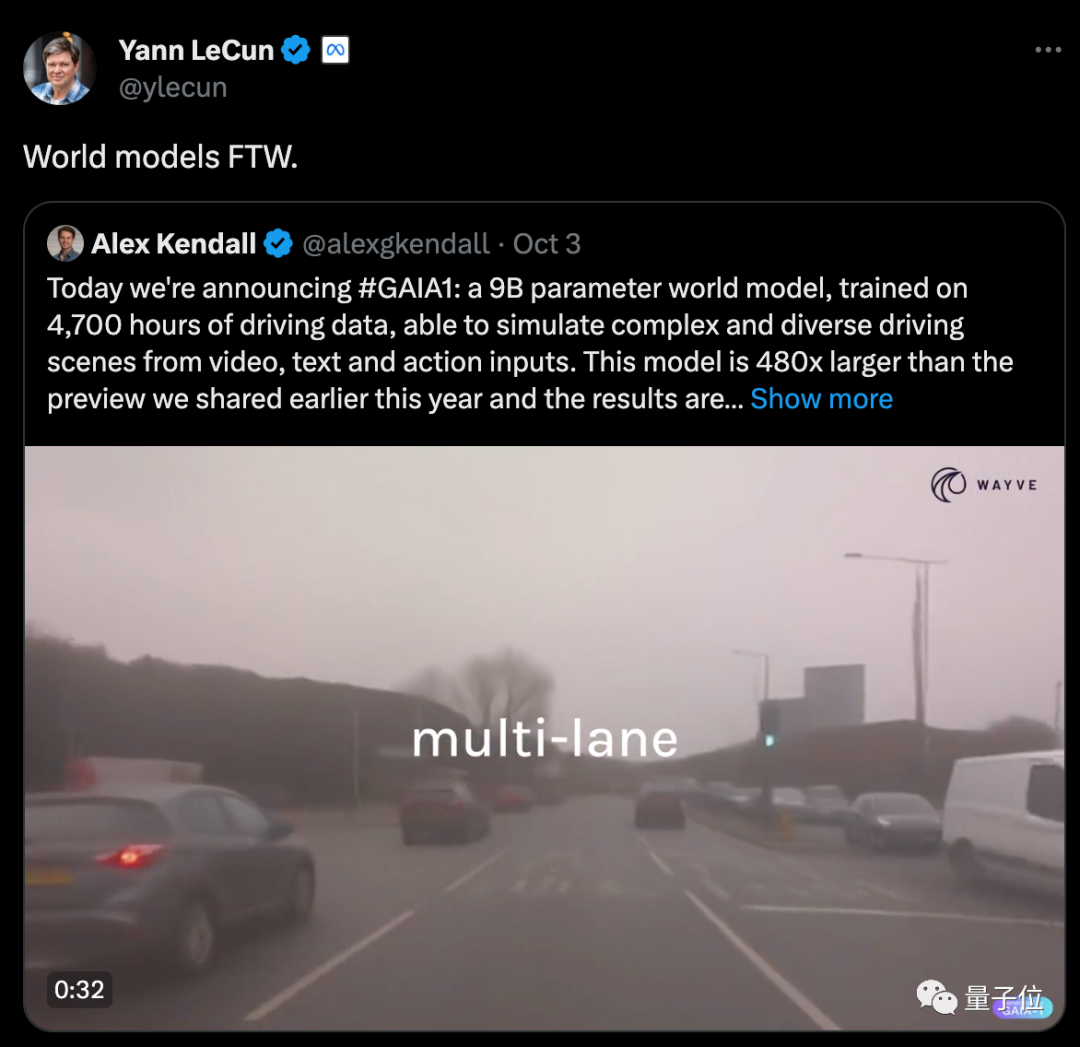
如上效果,由GAIA-1的最新版本带来。
它规模达90亿参数,用4700小时驾驶视频训练,实现了输入视频、文本或操作生成自动驾驶视频的效果。
带来的最直接好处就是——能更好预测未来事件,20多种场景都能模拟,从而进一步提升了自动驾驶的安全性、还降低了成本。

其主创团队直言,这能够改变自动驾驶的游戏规则!
所以GAIA-1是如何实现的?其实前面自动驾驶Daily已经第一时间为大家详细介绍过了自动驾驶公司Wayve团队出品的GAIA-1: A Generative World Model for Autonomous Driving,感兴趣的同学可以去公众号阅读下!
规模越大效果越好
GAIA-1是一个多模态生成式世界模型。
它利用视频、文本和动作作为输入,生成逼真的驾驶场景视频,同时可以对自主车辆的行为以及场景特征进行细粒度控制。
而且可以仅通过文本提示来生成视频。

其模型原理有点像大语言模型的原理,就是预测下一个token。
模型可以利用向量量化表示将视频帧离散,然后预测未来场景,就转换成了预测序列中的下一个token。然后再利用扩散模型从世界模型的语言空间里生成高质量视频。
具体步骤如下:
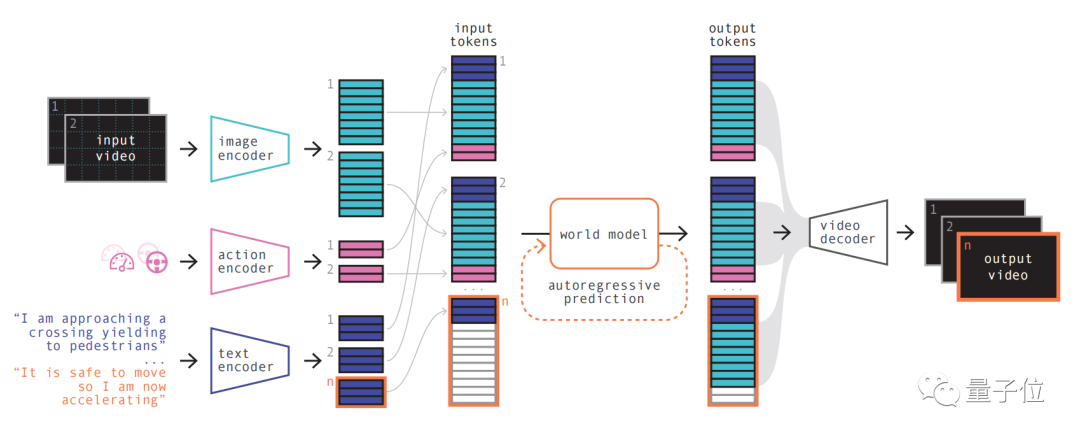
第一步简单理解,就是对各种输入进行重新编码和排列组合。
利用一个专门的编码器对各种输入进行编码,不同输入投射到共用表示里。文本和视频编码器对输入分离、嵌入,操作(action)表示则被单独投射到共用表示里。
这些编码的表示具有时间一致性。
在进行排列之后,关键部分世界模型登场。
作为一个自回归Transformer,它能预测序列中的下一组图像token。而且它不仅考虑了之前的图像token,还要兼顾文本和操作的上下文信息。
这就使得模型生成内容,不仅保持了图像一致性,而且和预测文本、动作也能保持一致。
团队介绍,GAIA-1中的世界模型规模为65亿参数,在64块A100上训练15天而成。
最后再利用视频解码器、视频扩散模型,将这些token转换回视频。
这一步关乎视频的语义质量、图像准确性和时间一致性。
GAIA-1的视频解码器规模达26亿参数规模,利用32台A100训练15天而来。
值得一提的是,GAIA-1不仅和大语言模型原理相似,同时也呈现出了随着模型规模扩大、生成质量提升的特点。
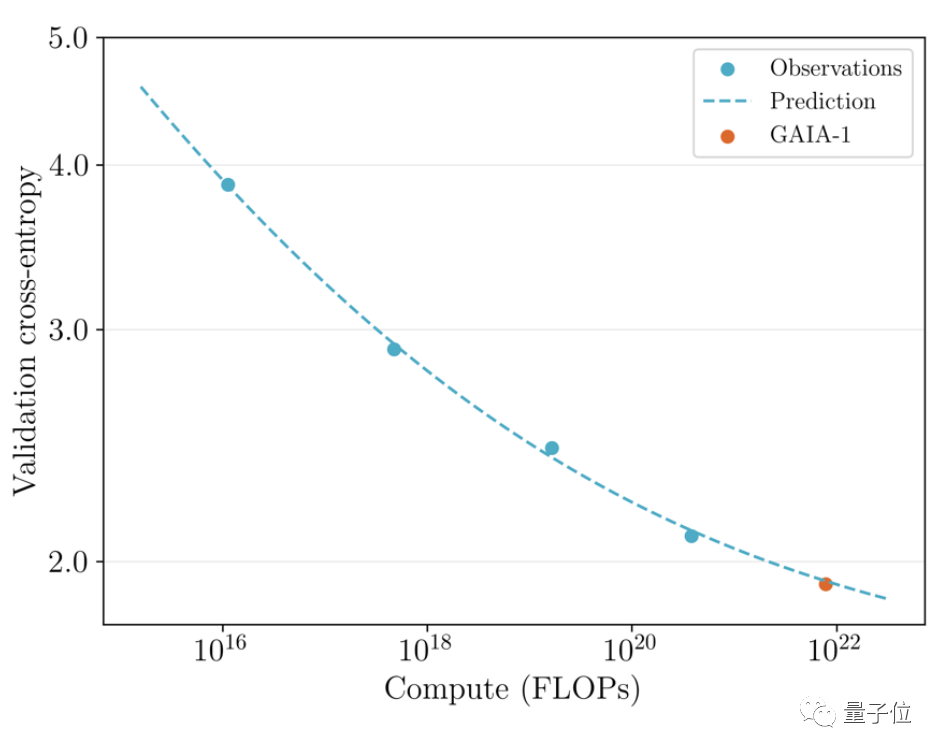
团队将此前6月发布早期版本和最新效果进行了对比。
后者规模为前者的480倍。
可以直观看到视频在细节、分辨率等方面都有明显提升。

而从实际应用方面出发,GAIA-1也带来了影响,其主创团队表示,这会改变自动驾驶的规则。

原因来自三方面:
- 综合训练数据
首先安全方面,世界模型能够通过模拟未来,让AI有能力意识到自己的决定,这对自动驾驶的安全性来说很关键。
其次,训练数据对于自动驾驶来说也非常关键。生成的数据更加安全、便宜,而且还能无限扩展。
最后,它还能解决目前自动驾驶面临的最大挑战之一——长尾场景。生成式AI可以兼顾更多边缘场景,比如在大雾天气行驶遇到了横穿马路的路人。这能更进一步提升自动驾驶的能力。
Wayve是谁?
GAIA-1来自英国自动驾驶初创公司Wayve。
Wayve成立于2017年,投资方有微软等,估值已经达到了独角兽。
创始人为现任CEO亚历克斯·肯德尔和艾玛尔·沙(公司官网领导层页已无其信息) ,两人都是来自剑桥大学的机器学习博士。

技术路线上,和特斯拉一样,Wayve主张利用摄像头的纯视觉方案,很早就抛弃高精地图,坚定的走“即时感知”路线。
前不久,该团队发布的另一个大模型LINGO-1也引发轰动。
这个自动驾驶模型能够在行车过程中,实时生成解说,更进一步提高了模型可解释性。
今年3月,比尔·盖茨还曾试乘过过Wayve的自动驾驶汽车。

论文地址:https://arxiv.org/abs/2309.17080

原文链接:https://mp.weixin.qq.com/s/bwTDovx9-UArk5lx5pZPag
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK