

GPU被炒到50万元一颗后,英伟达又推超级芯片!
source link: https://www.qianzhan.com/analyst/detail/329/230810-310231b9.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

GPU被炒到50万元一颗后,英伟达又推超级芯片!
作者|Trista 来源|芯师爷(ID:gsi24-xinshiye)
北京时间8月8日23:00,在全球首屈一指的计算机图形和交互技术会议SIGGRAPH上,英伟达CEO黄仁勋一袭黑皮衣,以雷霆万钧之势再度登台,对台下数千名观众表示,“生成式人工智能时代即将到来,如果你相信的话,那就是人工智能的iPhone时代。”

英伟达CEO黄仁勋,图源:SIGGRAPH演讲截图
在随后近一个半小时的演讲中,黄仁勋宣布了英伟达的最新技术突破:
硬件方面,黄仁勋推出了新一代GH200 Grace Hopper超级芯片,将搭载全球首款HBM3e处理器,预计于2024年第二季投产,专为加速计算和生成式 AI 时代而打造。同时,还重磅发布了功能强大的新型RTX工作站、三款全新桌面工作站Ada Generation GPU,以及搭载全新NVIDIA L40S GPU的全新 NVIDIA OVX服务器。
软件方面,为了推动人工智能部署,英伟达推出了AI Workbench、AI Enterprise 4.0,以及Hugging Face等重磅武器,旨在和行业携手,一同推动人工智能和生成式AI走向下一个浪潮尖峰。
新一代 GH200 Grace Hopper 超级芯片炸场
通常,使用人工智能模型的过程至少分为两个部分:训练和推理。训练部分,是使用大量数据来训练人工智能系统,开发出具有特定功能的神经网络模型,动辄需要耗费数月时间才能完成;推理部分,则是将新的数据输入训练好的模型,让它推理出各种结论,并且几乎持续进行。
这两个环节都需要高性能GPU进行支持,如果支持不到位的话,将影响大模型的精准度。
为了持续推动AI发展,早在2022年初,英伟达宣布了Grace Hopper超级芯片,即NVIDIA GH200,它将72核Grace CPU与Hopper GPU相结合,提供1 EFLOPS的AI算力和144TB的高速存储,并于今年 5 月全面投产。
昨晚的SIGGRAPH大会上,也就是在这款超级芯片全面投产后不到三个月,英伟达推出了功能更强大的芯片版本——新一代NVIDIA GH200 Grace Hopper超级芯片,将提供卓越的内存技术和带宽,以此提高吞吐量,提升无损耗连接GPU聚合性能的能力,并且拥有可以在整个数据中心轻松部署的服务器设计。
“你几乎可以在GH200上运行任何你想要的大型语言模型,它会疯狂地进行推理。”黄仁勋说,“大型语言模型的推理成本将大幅下降。”

新一代GH200 Grace Hopper 超级芯片
与当前一代产品相比,新一代GH200拥有基本相同的“基因”:其 72 核 Arm Neoverse V2 Grace CPU、Hopper GPU 及其 900GB/秒 NVLink-C2C 互连均保持不变。核心区别是它搭载了全球第一款HBM3e内存,将不再配备今年春季型号的 96GB HBM3 vRAM 和 480GB LPDDR5x DRAM,而是搭载500GB的LPDDR5X以及141GB的HBM3e存储器,实现了5TB/秒的数据吞吐量。
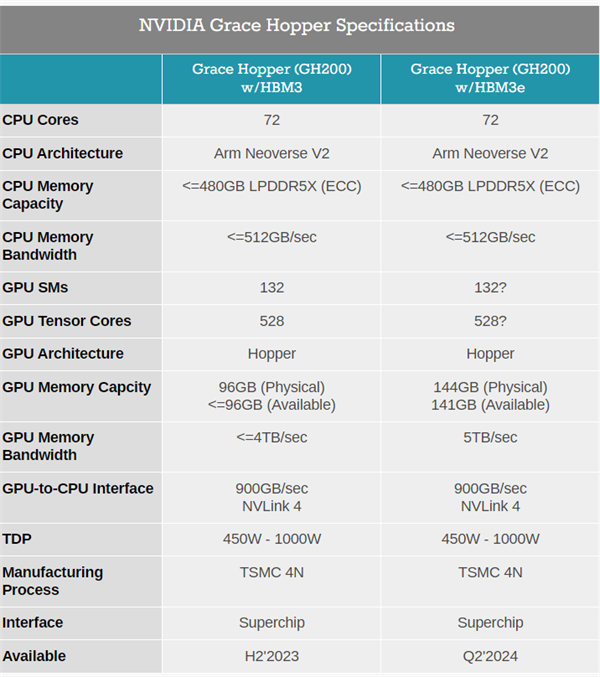
HBM3内存 VS HBM3e内存参数对比
英伟达表示,HBM3e内存技术带来了50%的速度提升,总共提供了10TB/秒的组合带宽。能够运行比先前版本大3.5倍的模型,并以3倍的内存带宽提高性能。
此外,英伟达目前正在开发一款新的双GH200基础NVIDIA MGX服务器系统,将集成两个下一代Grace Hopper超级芯片。在新的双GH200服务器中,系统内的CPU和GPU将通过完全一致的内存互连进行连接,这个超级GPU可以作为一个整体运行,提供144个Grace CPU核心、8千万亿次的计算性能以及282GB的HBM3e内存,从而能够适用于生成式AI的巨型模型。
对于企业客户,英伟达GPU训练AI模型成本已非常昂贵,但黄仁勋仍强调其产品的“性价比”:同样使用1亿美元打造数据中心,可以购得8800块x86处理器或2500套GH200,但后者的AI推理性能是前者的12倍,能效达20倍。
于是我们又听到了黄仁勋“金牌导购”的名言:the more you buy, the more you save(买的越多,省的越多)。
据悉,英伟达计划销售GH200的两种版本:一种是包含两个可供客户集成到系统中的芯片,另一种则是结合了两种Grace Hopper设计的完整服务器系统。
全新的GH200这款产品将于2024年第二季投产,售价暂未透露。
四款全新显卡+新款OVX服务器:
全方面涵盖生成式AI开发
除了适用于前沿大语言模型的GH200 ,英伟达在桌面AI工作站方面,推出了RTX 6000、RTX 5000、RTX 4500和RTX 4000四款新显卡,以及搭载全新L40S Ada GPU的新款OVX服务器。
1
RTX 6000 Ada GPU
为提供更多的计算能力,促进生成式AI和数字化时代的开发和内容创作,英伟达正在和全球制造商,包括惠普、联想、BOXX、戴尔等,推出功能强大的新型 RTX 工作站。
新的RTX工作站提供多达4个NVIDIA RTX 6000 Ada GPU,每个GPU都配备48GB内存(总共 192GB),单个桌面工作站可以提供高达5.8 TFLOPS 算力。
2
三款全新桌面工作站 GPU
黄仁勋还宣布推出三款全新桌面工作站Ada Generation GPU :NVIDIA RTX 5000、RTX 4500和RTX 4000,旨在为全球专业人士提供最新的 AI、图形和实时渲染技术。
NVIDIA RTX 5000现已上市(售价 4,000 美元),提供32GB GDDR6内存,NVIDIA RTX 4500 和 4000 将于今年秋季上市(售价分别为 1,250 美元和 2,250 美元),两者都是双槽 GPU,分别提供和24GB GDDR6内存、20GB GDDR6内存。
3
OVX 服务器产品
此外,英伟达还推出了搭载L40S GPU 的 OVX 服务器产品,每台服务器最多可以装八个L40S GPU,每个GPU有 48GB 内存。
对于具有数十亿参数和多种数据模态的复杂AI工作负载,相较于A100 Tensor Core GPU,L40S 能够实现1.2倍的生成式AI推理性能和 1.7 倍的训练性能,旨在满足AI训练和推理、3D 设计和可视化、视频处理和工业数字化等计算密集型应用的需求。
软件生态全方位部署:
让所有人参与生成AI
除了硬件产品,软件方面,英伟达推出了AI Workbench、AI Enterprise 4.0,以及Hugging Face等重磅武器:
AI Workbench是为开发人员提供了一个统一、易于使用的工具包,将需要用于生成式AI工作的一切打包在一起,主要是为了降低企业启动 AI 项目的门槛。大会上,黄仁勋在强调,为了推动AI技术普惠,必须让其有可能在几乎任何地方运行,让所有人都能参与生成式 AI。因此,AI Workbench将支持在本地机器上进行模型的开发和部署,而不是云服务上。
借助它,开发人员可以只需点击几下就可以定制和运行生成式AI。据称,包括戴尔、惠普、Lambda、联想和Supermicro,都正采用AI Workbench。
AI Enterprise 4.0是英伟达发布的最新版企业软件平台,可提供生产就绪型生成式AI工具,使企业能够访问采用生成式AI所需的工具,同时还提供大规模企业部署所需的安全性和API稳定性。
同时,黄仁勋还宣布英伟达与拥有 200 万用户的初创公司Hugging Face 合作,这将使得数百万大型语言模型开发者和其他高级 AI 应用程序开发人员,能够轻松实现生成式 AI 超级计算。
开发人员将能够在Hugging Face平台内访问NVIDIA DGX Cloud AI 超级计算,以训练和微调先进的 AI 模型。据悉,Hugging Face 社区已分享超过 25 万个模型和 5 万个数据集。对此,黄仁勋表示,这将是一项全新的服务,将世界上最大的 AI 社区与世界上最好的训练和基础设施连接起来。
写在最后:
AI的生产力爆炸时代,正在加速到来
随着英伟达一个接一个新产品和新服务的揭晓,我们似乎也看到生成式AI的生产力爆炸时代正在加速到来。
2022年底,ChatGPT问世后,迅速在全世界引起了AI狂潮,在这波狂潮中,英伟达凭借其数据中心GPU的核心技术优势,成为人工智能芯片市场市场主导者。
如今,全球约90%以上的大模型都在使用英伟达的GPU芯片,其股价也在今年以来飙升了逾200%,赚了个盆满钵满,上市14年后成功跻身万亿美元市值俱乐部。而实现这一目标,硅谷巨头们诸如苹果用了37年、微软用了33年、亚马逊用了21年,特斯拉跑得最快,只用了11年。
目前GPU价格仍在上涨,已然成为人工智能基础设施的“硬通货”,海外甚至已有创业企业开始利用GPU进行抵押融资。
eBay网站显示,英伟达旗舰级芯片H100的售价已经高达4.5万美元(约合人民币32.37万元),这较今年4月份4万美元的价格涨幅超过10%,甚至有卖家标价6.5万美元,而且货源较上半年也显著减少。
同时,英伟达的中国特供版 A800 和 H800芯片也遭到了哄抢。有数据推算,2022年全年英伟达数据中心GPU在中国的销售额约为100亿元人民币。而今年春节后,据晚点 LatePost报道,拥有云计算业务的中国各互联网大公司都向英伟达下了大单。字节今年向英伟达订购了超过10亿美元的GPU,另一家大公司的订单也至少超过10亿元人民币。而仅字节一家公司今年的订单可能已接近英伟达去年在中国销售的商用GPU总和。
目前,国内大模型企业基本上很难拿得到这些芯片,A800 和 H800芯片从原来的12万人民币左右,变成了现在是25万甚至30万,甚至有高达50万一片。
值得注意的是,近日有消息称,下一代GPT大模型GPT5需要5万张英伟达最高配置的H100芯片,全球市场对H100芯片的需求量达到43万张,英伟达的产能可能难以满足如此大的算力需求。
正如特斯拉CEO马斯克表示,“英伟达不会永远在大规模训练和推理芯片市场占据垄断地位。”越是风光,竞争对手就越是虎视眈眈,比如就在前不久,AMD刚刚发布了“大模型专用”的AI芯片MI300X,直接对标英伟达H100,这被业界视为直接向英伟达宣战。
但从本次黄仁勋的演讲来看,赛道越来越激烈,英伟达也丝毫没有松懈。
编者按:本文转载自微信公众号:芯师爷(ID:gsi24-xinshiye),作者:Trista
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK