

在开源项目中看到一个改良版的雪花算法,现在它是你的了。
source link: https://www.cnblogs.com/thisiswhy/p/17611163.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

在开源项目中看到一个改良版的雪花算法,现在它是你的了。
你好呀,我是歪歪。
在 Seata 的官网上看到一篇叫做“关于新版雪花算法的答疑”的文章。
http://seata.io/zh-cn/blog/seata-snowflake-explain.html

看明白之后,我觉得还是有点意思的,结合自己的理解和代码,加上画几张图,给你拆解一下 Seata 里面的“改良版雪花算法”。
虽然是在 Seata 里面看到的,但是本篇文章的内容和 Seata 框架没有太多关系,反而和数据库的基础知识有关。
所以,即使你不了解 Seata 框架,也不影响你阅读。
当你理解了这个类的工作原理之后,你完全可以把这个只有 100 多行的类搬运到你的项目里面,然后就变成你的了。
你懂我意思吧。

如果你的项目中涉及到需要一个全局唯一的流水号,比如订单号、流水号之类的,又或者在分库分表的情况下,需要一个全局唯一的主键 ID 的时候,就需要一个算法能生成出这样“全局唯一”的数据。
一般来说,我们除了“全局唯一”这个基本属性之外,还会要求生成出来的 ID 具有“递增趋势”,这样的好处是能减少 MySQL 数据页分裂的情况,从而减少数据库的 IO 压力,提升服务的性能。
此外,在当前的市场环境下,不管你是啥服务,张口就是高并发,我们也会要求这个算法必须得是“高性能”的。
雪花算法,就是一个能生产全局唯一的、递增趋势的、高性能的分布式 ID 生成算法。
关于雪花算法的解析,网上相关的文章比雪花还多,我这里就不展开了,这个玩意,应该是“面试八股文”中重点考察模块,分布式领域中的高频考题之一,如果是你的盲区的话,赶紧去了解一下。
比如一个经典的面试题就是:雪花算法最大的缺点是什么?

背过题的小伙伴应该能立马答出来:时钟敏感。
因为在雪花算法中,由于要生成单调递增的 ID,因此它利用了时间的单调递增性,所以是强依赖于系统时间的。
如果系统时间出现了回拨,那么生成的 ID 就可能会重复。
而“时间回拨”这个现象,是有可能出现的,不管是人为的还是非人为的。
当你回答出这个问题之后,面试官一般会问一句:那如果真的出现了这种情况,应该怎么办呢?
很简单,正常来说只要不是不是有人手贱或者出于泄愤的目的进行干扰,系统的时间漂移是一个在毫秒级别的极短的时间。
所以可以在获取 ID 的时候,记录一下当前的时间戳。然后在下一次过来获取的时候,对比一下当前时间戳和上次记录的时间戳,如果发现当前时间戳小于上次记录的时间戳,所以出现了时钟回拨现象,对外抛出异常,本次 ID 获取失败。
理论上当前时间戳会很快的追赶上上次记录的时间戳。
但是,你可能也注意到了,“对外抛出异常,本次 ID 获取失败”,意味着这段时间内你的服务对外是不可使用的。
比如,你的订单号中的某个部分是由这个 ID 组成的,此时由于 ID 生成不了,你的订单号就生成不了,从而导致下单失败。
再比如,在 Seata 里面,如果是使用数据库作为 TC 集群的存储工具,那么这段时间内该 TC 就是处于不可用状态。
你可以简单的理解为:基础组件的错误导致服务不可用。
基于前面说的问题,Seata 才提出了“改良版雪花算法”。
http://seata.io/zh-cn/blog/seata-analysis-UUID-generator.html
在介绍改良版之前,我们先把 Seata 的源码拉下来,瞅一眼。
在源码中,有一个叫做 IdWorker 的类:
io.seata.common.util.IdWorker
我带你看一下它的提交记录:
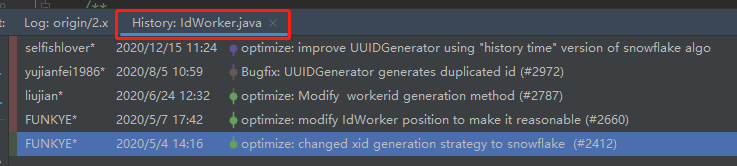
2020 年 5 月 4 日第一次提交,从提交时的信息可以看出来,这是把分布式 ID 的生成策略修改为 snowflake,即雪花算法。
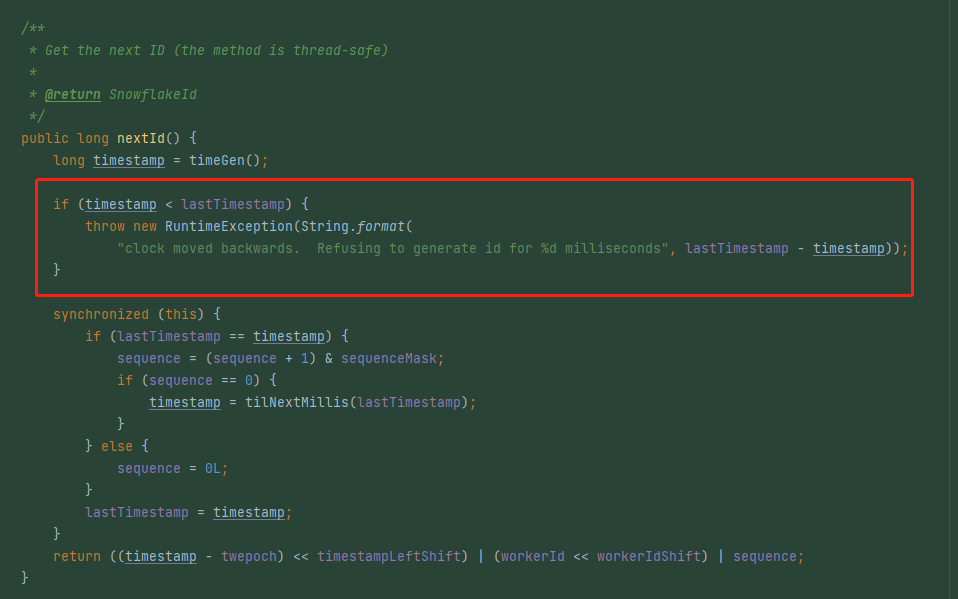
同时我们也能在代码中找到前面提到的“对外抛出异常,本次 ID 获取失败”相关代码,即 nextId 方法,它的比较方式就是用当前时间戳和上次获取到的时间戳做对比:
io.seata.common.util.IdWorker#nextId
这个类的最后一次提交是 2020 年 12 月 15 日:
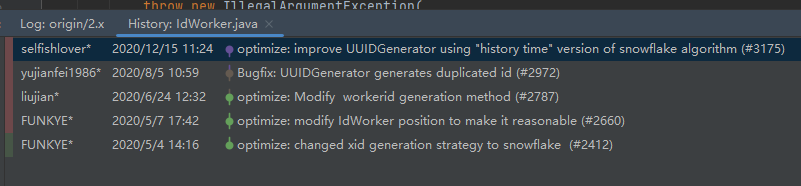
这一次提交对于 IdWorker 这个类进行了大刀阔斧的改进,可以看到变化的部分非常的多:
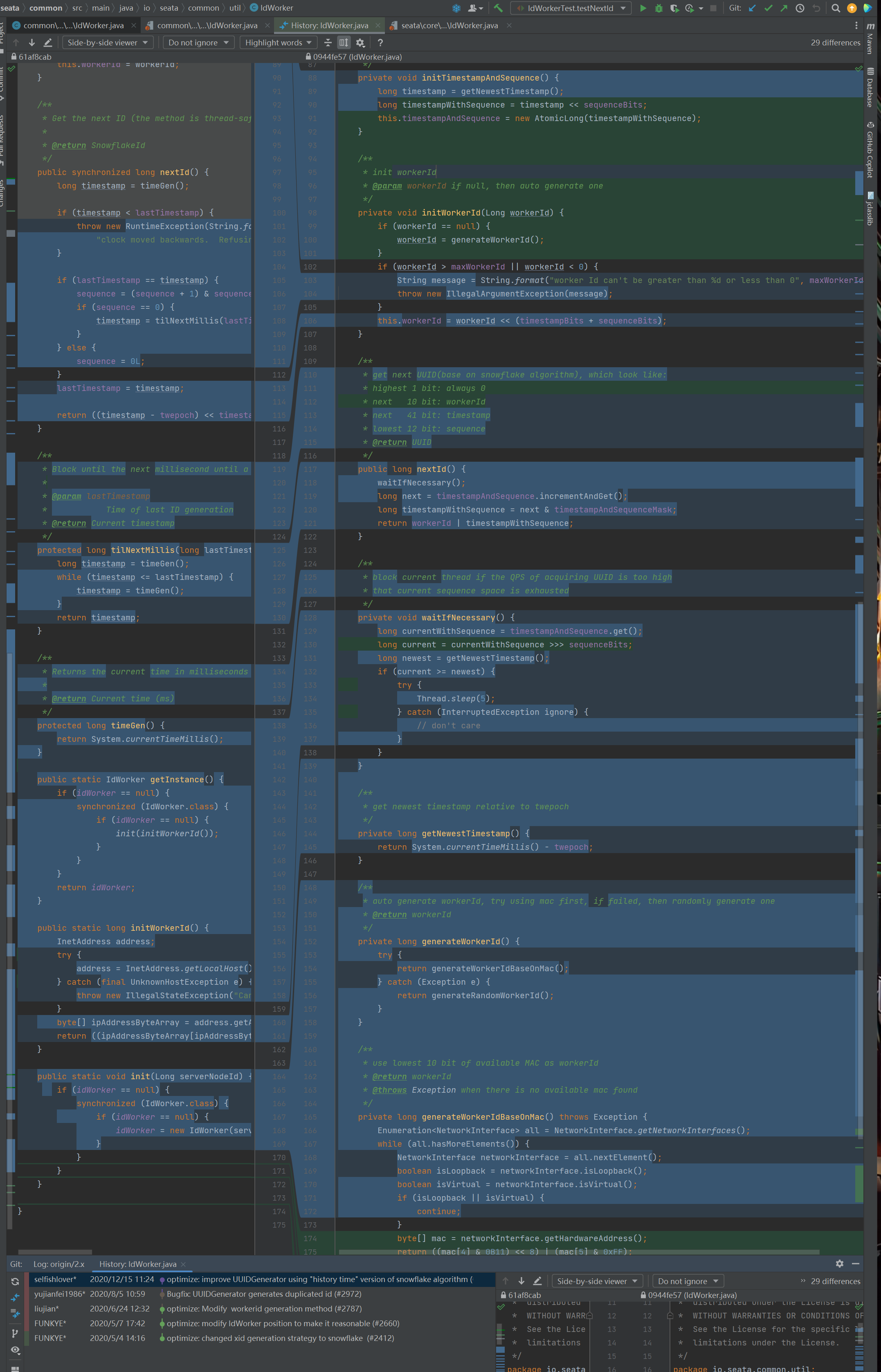
我们重点关注刚刚提到的 nextId 方法:
整个方法从代码行数上来看都可以直观的看到变化,至少没有看到抛出异常了。
这段代码到底是怎么起作用的呢?
首先,我们得理解 Seata 的改良思路,搞明白思路了,再说代码就好理解一点。
在前面提到的文章中 Seata 也说明了它的核心思路,我带着你一起过一下:

原版的雪花算法 64 位 ID 是分配这样的:

可以看到,时间戳是在最前面的,因为雪花算法利用了时间的单调递增的特性。
所以,如果前面的时间戳一旦出现“回退”的情况,即打破了“时间的单调递增”这个前提条件,也就打破了它的底层设计。
它能怎么办?
它只能给你抛出异常,开始摆烂了。
然后我主要给你解释一下里面的节点 ID 这个玩意。
节点 ID 可以理解为分布式应用中的一个服务,一个服务的节点 ID 是固定的。
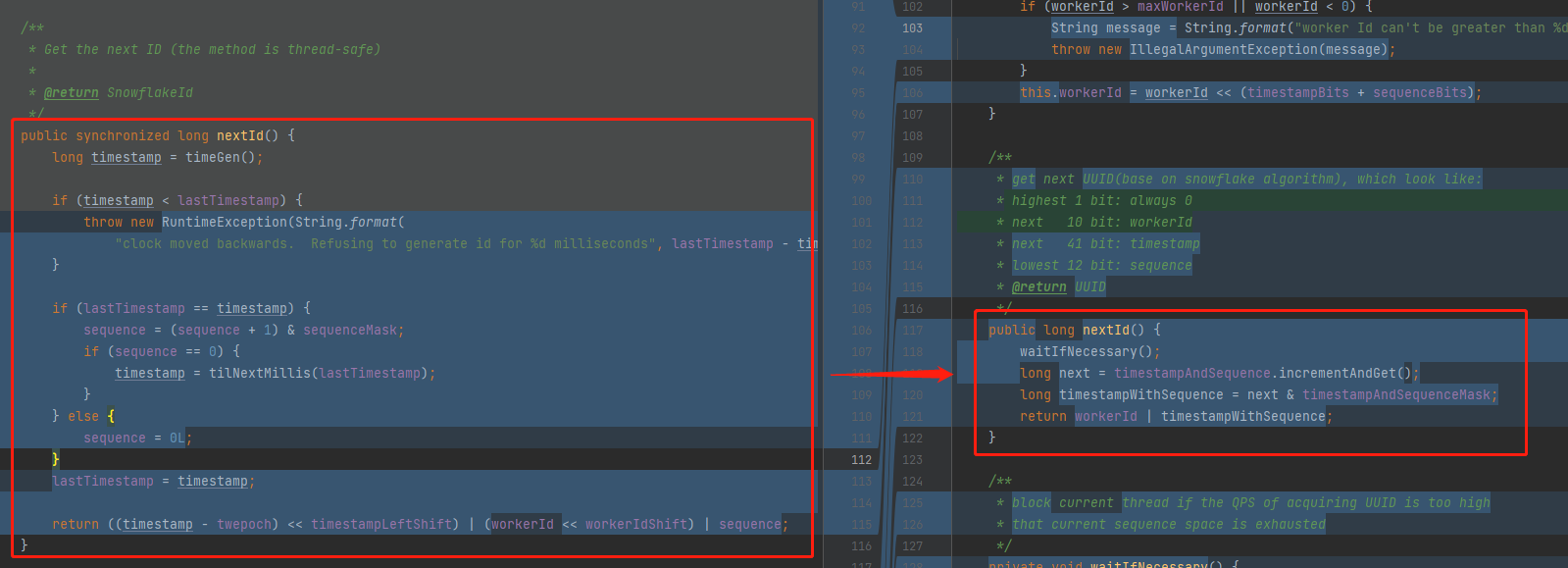
可以看到节点 ID 长度为二进制的 10 位,也就是说最多可以服务于 1024 台机器,所以你看 Seata 最开始提交的版本里面,有一个在 1024 里面随机的动作。
因为算法规定了,节点 ID 最多就是 2 的 10 次方,所以这里的 1024 这个值就是这样来的:
包括后面有大佬觉得用这个随机算法一点都不优雅,就把这部分改成了基于 IP 去获取:
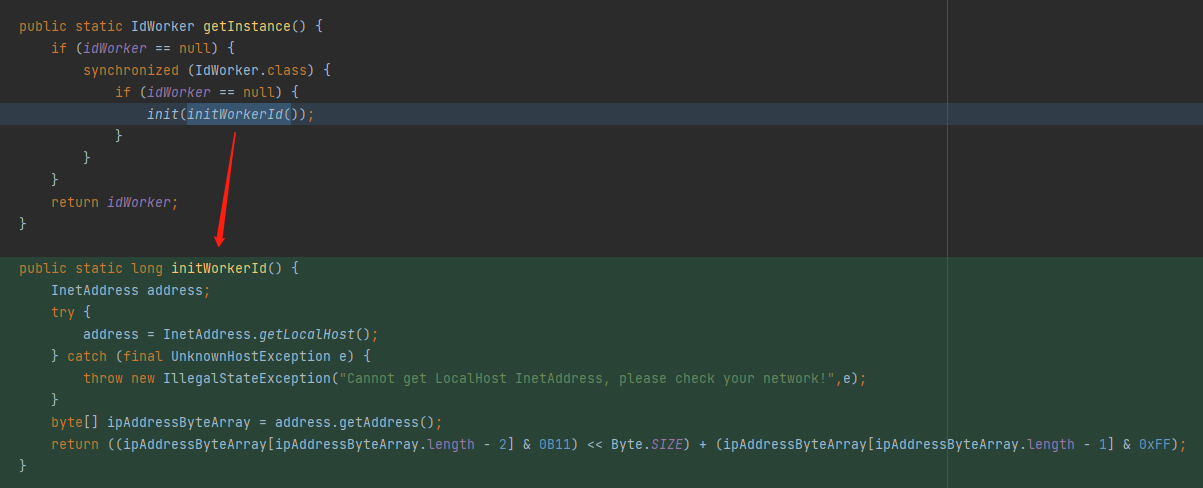
看起来有点复杂,但是我们仔细去分析最后一行:
return ((ipAddressByteArray[ipAddressByteArray.length - 2] & 0B11) << Byte.SIZE) + (ipAddressByteArray[ipAddressByteArray.length - 1] & 0xFF);
变量 & 0B11 运算之后的最大值就是 0B11 即 3。
Byte.SIZE = 8。
所以,3 << 8,对应二进制 1100000000,对应十进制 768。
变量 & 0xFF 运算之后的最大值就是 0xFF 即 255。
768+255=1023,取值范围都还是在 [0,1023] 之间。
然后你再看现在最新的算法里面,官方的老哥们认为获取 IP 的方式不够好:

所以又把这个地方从使用 IP 地址改成了获取 Mac 地址。
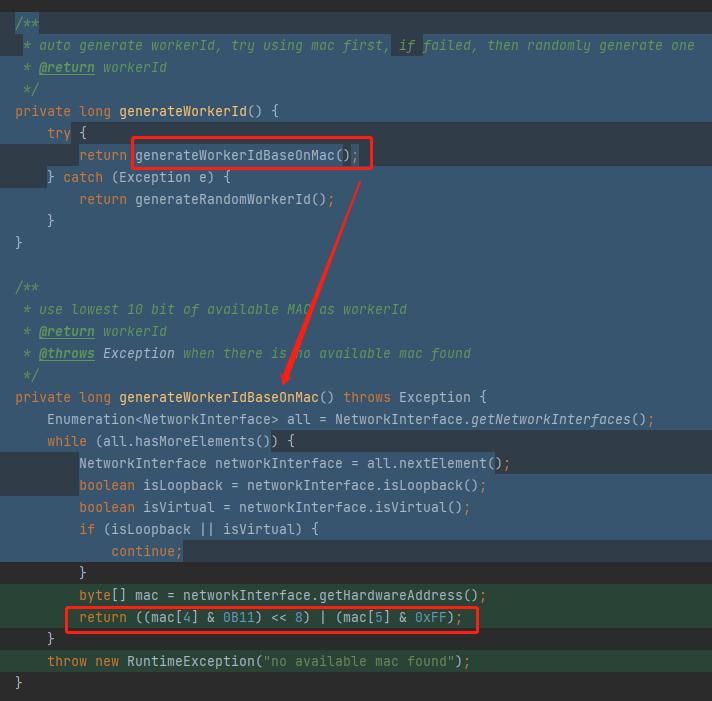
最后一行是这样的:
return ((mac[4] & 0B11) << 8) | (mac[5] & 0xFF);
还是我刚刚说的 0B11 << 8 和 0xFF。
那么理论上的最大值就是 768 | 255 ,算出来还是 1023。
所以不管你怎么玩出花儿来,这个地方搞出来的数的取值范围就只能是 [0,1023] 之间。
别问,问就是规定里面说了,算法里面只给节点 ID 留了 10 位长度。
最后,就是这个 12 位长度的序列号了:

这个玩意没啥说的,就是一个单纯的、递增的序列号而已。
既然 Seata 号称是改良版,那么具体体现在什么地方呢?
简单到你无法想象:

是的,仅仅是把时间戳和节点 ID 换个位置就搞定了。
然后每个节点的时间戳是在 IdWorker 初始化的时候就设置完成了,具体体现到代码上是这样的:
io.seata.common.util.IdWorker#initTimestampAndSequence
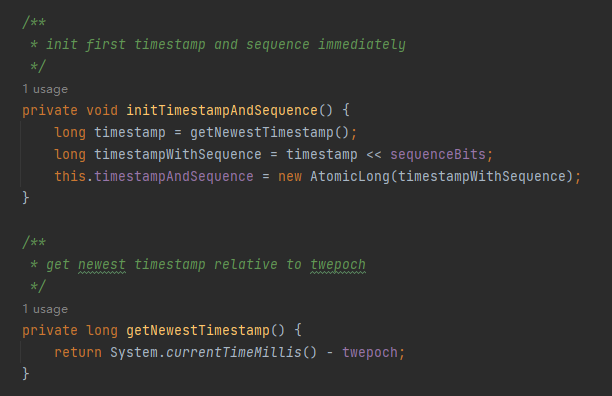
主要看第一行:
long timestamp = getNewestTimestamp();
可以看到在 getNewestTimestamp 方法里面获取了一次当前时间,然后减去了一个 twepoch 变量。
twepoch 是什么玩意?
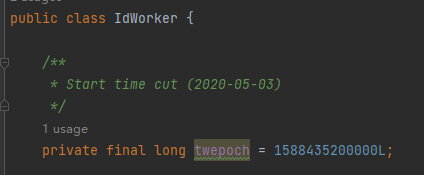
是 2020-05-03 的时间戳。
至于为什么是这个时间,我想作者应该是在 2020 年 5 月 3 日写下的关于 IdWorker 的第一行代码,所以这个日期是 IdWorker 的生日。
作者原本完全可以按照一般程序员的习惯,写 2020 年 1 月 1 日的,但是说真的,这个日期到底是 2020-01-01 还是 2020-05-03 对于框架来说完全不重要,所以还不如给它赋予一个特殊的日期。
他真的,我哭死...
那么为什么要用当前时间戳减去 twepoch 时间戳呢?
你想,如果仅仅用 41 位来表示时间戳,那么时间戳的最大值就是 2 的 41 次方,转化为十进制是这么多 ms:
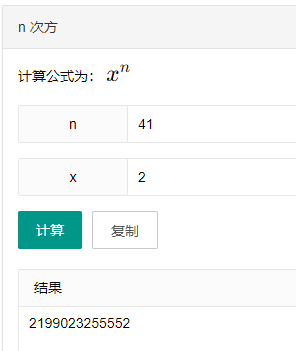
然后再转化为时间:
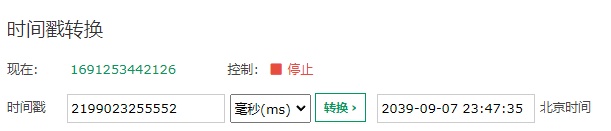
也就是说,在雪花算法里面,41 位时间戳最大可以表示的时间是 2039-09-07 23:47:35。
算起来也没几年了。
但是,当我们减去 2020-05-03 的时间戳之后,计算的起点不一样了,这一下,咔咔的,就能多用好多年。
twepoch 就是这么个用途。
然后,我们回到这一行代码:
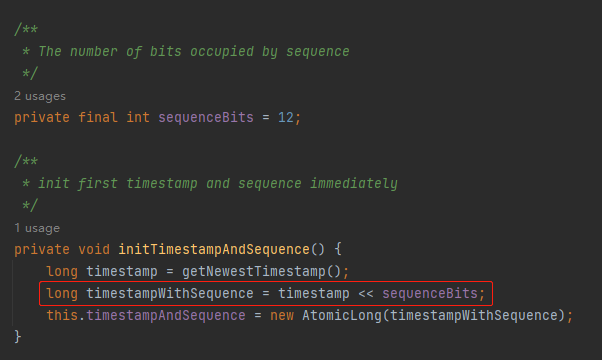
前一行,我们把 41 位的时间戳算好了,按照 Seata 的设计,时间戳之后就是 12 位的序列号了呀:

所以这里就是把时间戳左移 12 位,好把序列号的位置给腾出来。
最后,算出来的值,就是当前这个节点的初始值,即 timestampAndSequence。
所以,你看这个 AtomicLong 类型的变量的名字取的,叫做 timestampAndSequence。
timestamp 和 Sequence,一个字段代表了两个含义,多贴切。
Long 类型转化为二进制一共 64 位,前 11 位不使用,中间的 41 位代表时间戳,最后的 12 位代表序列号,一个字段,两个含义。
程序里面使用的时候也是在一起使用,用 Long 来存储,在内存里面也是放在一块的:
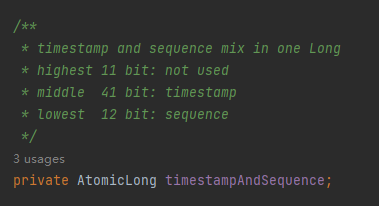
优雅,实在优雅。
上一次看到这么优雅的代码,还是线程池里面的 ctl 变量:
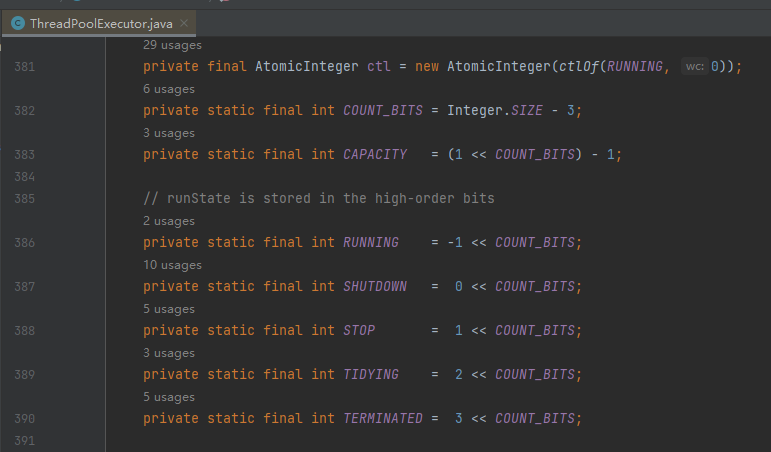
现在 timestampWithSequence 已经就位了,那么获取下一 ID 的时候是怎么搞的呢?
看一下 nextId 方法:
io.seata.common.util.IdWorker#nextId
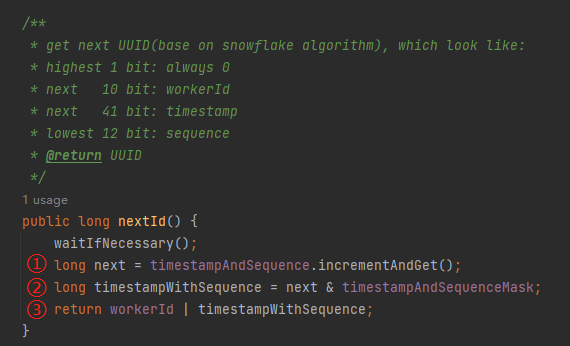
标号为 ① 的地方是基于 timestampWithSequence 进行递增,即 +1 操作。
标号为 ② 的地方是截取低 53 位,也就是 41 位的时间戳和 12 位的序列号。
标号为 ③ 的地方就是把高 11 位替换为前面说过的值在 [0,1023] 之间的 workerId。
好,现在你再仔细的想想,在前面描述的获取 ID 的过程中,是不是只有在初始化的时候获取过一次系统时间,之后和它就再也没有关系了?
所以,Seata 的分布式 ID 生成器,不再依赖于时间。
然后,你再想想另外一个问题:
由于序列号只有 12 位,它的取值范围就是 [0,4095]。
如果我们序列号就是生成到了 4096 导致溢出了,怎么办呢?
很简单,序列号重新归 0,溢出的这一位加到时间戳上,让时间戳 +1。
那你再进一步想想,如果让时间戳 +1 了,那么岂不是会导致一种“超前消费”的情况出现,导致时间戳和系统时间不一致了?
朋友,慌啥啊,不一致就不一致呗,反正我们现在也不依赖于系统时间了。
然后,你想想,如果出现“超前消费”,意味着什么?
意味着在当前这个毫秒下,4096 个序列号不够用了。
4096/ms,约 400w/s。
你啥场景啊,怎么牛逼?
(哦,原来是面试场景啊,那懂了~)
另外,官网还抛出了另外一个问题:这样持续不断的"超前消费"会不会使得生成器内的时间戳大大超前于系统的时间戳,从而在重启时造成 ID 重复?
你想想,理论上确实是有可能的。假设我时间戳都“超前消费”到一个月以后了。
那么在这期间,你服务发生重启时我会重新获取一次系统时间戳,导致出现“时间回溯”的情况。
理论上确实有可能。
但是实际上...
看看官方的回复:

别问,问就是不可能,就算出现了,最先崩的也不是我这个地方。
好,到这里,我终于算是铺垫完成了,前面的东西就算从你脑中穿脑而过了,你啥都记不住的话,你就抓住这个图,就完事了:
现在,你再仔细的看这个图,我问你一个问题:
改良版的算法是单调递增的吗?
在单节点里面,它肯定是单调递增的,但是如果是多个节点呢?
在多个节点的情况下,单独看某个节点的 ID 是单调递增的,但是多个节点下并不是全局单调递增。
因为节点 ID 在时间戳之前,所以节点 ID 大的,生成的 ID 一定大于节点 ID 小的,不管时间上谁先谁后。
这一点我们也可以通过代码验证一下,代码的意思是三个节点,每个节点各自生成 5 个 ID:
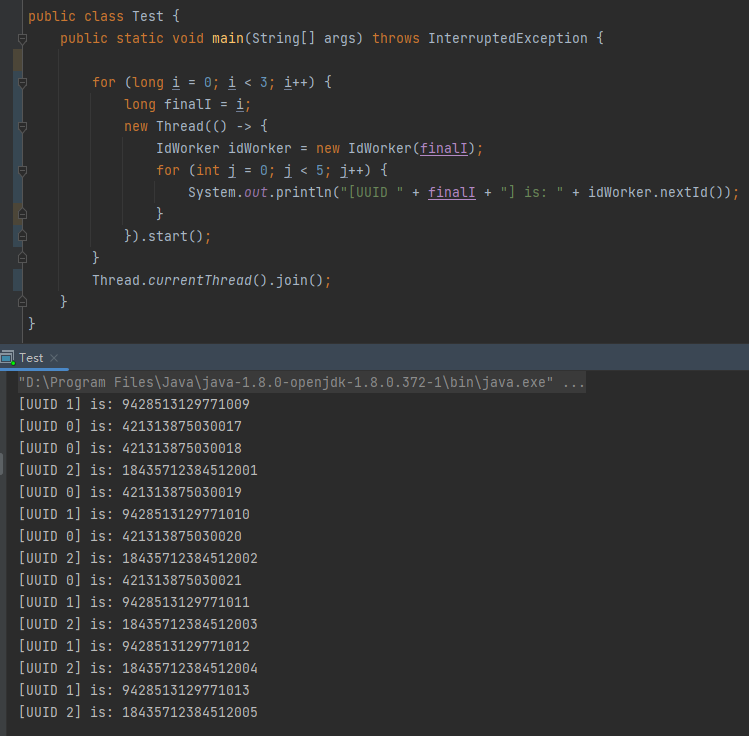
从输出来看,一眼望去,生成的 ID 似乎是乱序的,至少在全局的角度下,肯定不是单调递增的:
但是我们把输出按照节点 ID 进行排序,就变成了这样,单节点内严格按照单调递增,没毛病:
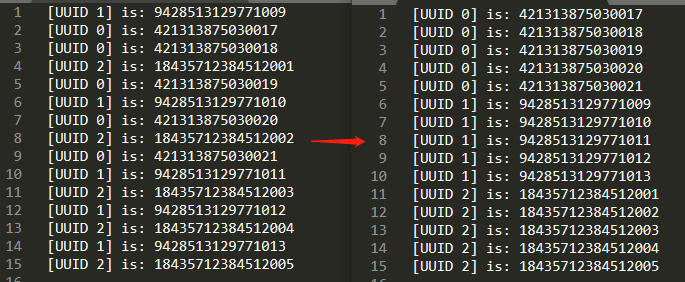
而在原版的雪花算法中,时间戳在高位,并且始终以系统时钟为准,每次生成的时候都会严格和系统时间进行对比,确保没有发生时间回溯,这样可以保证早生成的 ID 一定小于晚生成的 ID ,只有当 2 个节点恰好在同一时间戳生成 ID 时,2 个 ID 的大小才由节点 ID 决定。
这样看来,Seata 的改进算法是不是错的?
好,我再说一次,前面的所有的内容都是铺垫,就是为了引出这个问题,现在问题抛出来了,你得读懂并理解这个问题,然后再继续往下看。

分析之前,先抛出官方的回答:

我先来一个八股文热身:请问为什么不建议使用 UUID 作为数据库的主键 ID ?
就是为了避免触发 MySQL 的页分裂从而影响服务性能嘛。
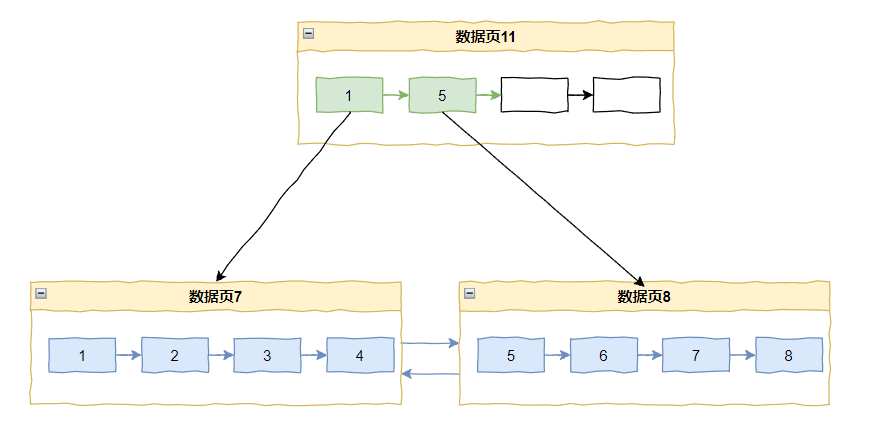
比如当前主键索引的情况是这样的:
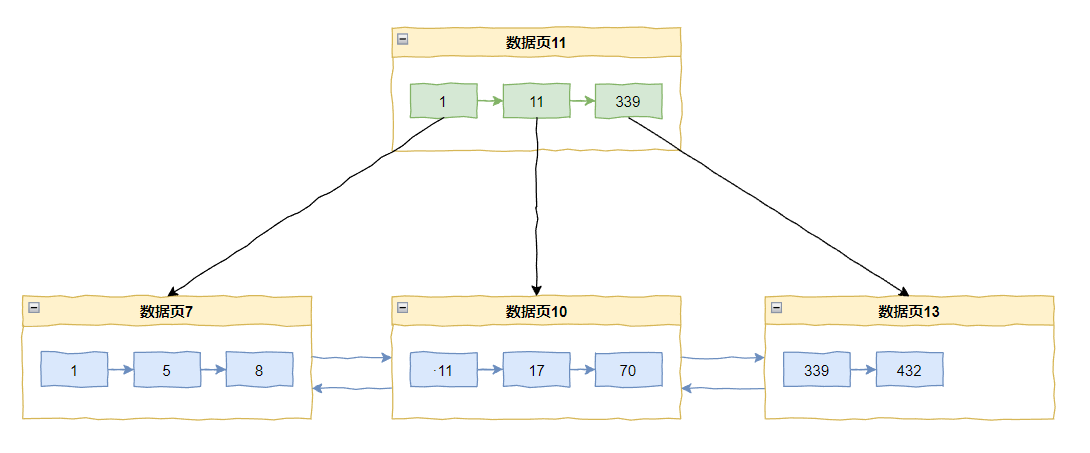
如果来了一个 433,那么直接追加在当前最后一个记录 432 之后即可。
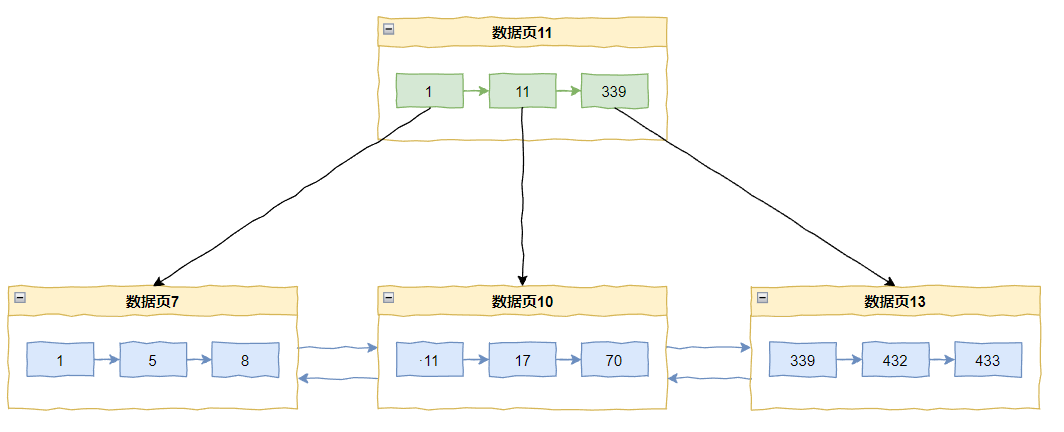
但是如果我们要插入一个 20 怎么办呢?
那么数据页 10 里面已经放满了数据,所以会触发页分裂,变成这样:

进而导致上层数据页的分裂,最终变成这样的一个东西:
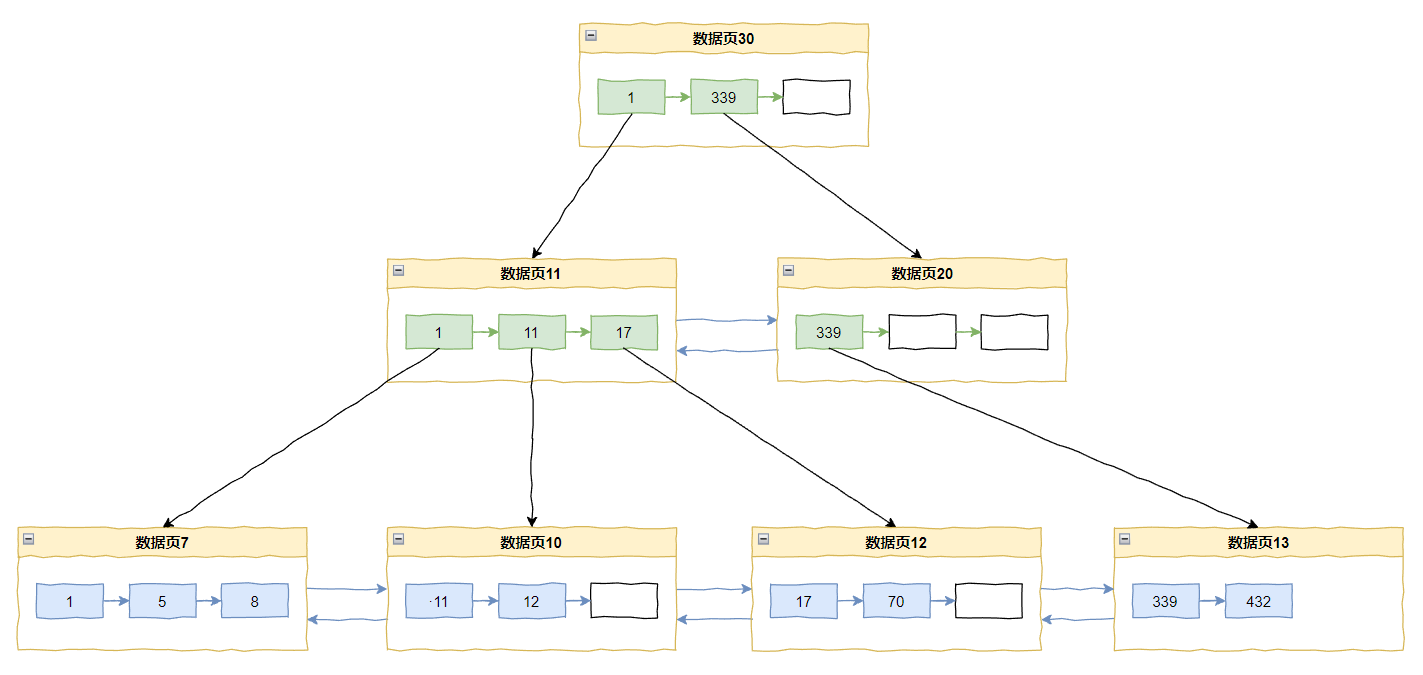
上面的我们可以看出页分裂伴随着数据移动,所以我们应该尽量避免。
理想的情况下,应该是把一页数据塞满之后,再新建另外一个数据页,这样 B+ tree 的最底层的双向链表永远是尾部增长,不会出现上面画图的那种情况:在中间的某个节点发生分裂。
那么 Seata 的改良版的雪花算法在不具备“全局的单调递增性”的情况下,是怎么达到减少数据库的页分裂的目的的呢?
我们还是假设有三个节点,我用 A,B,C 代替,在数值上 A < B < C,采用的是改良版的雪花算法,在初始化的情况下是这样的。

假设此时,A 节点申请了一个流水号,那么基于前面的分析,它一定是排在 A-seq1 之后,B-seq1 之前的。
但是这个时候数据页里面的数据满了,怎么办?
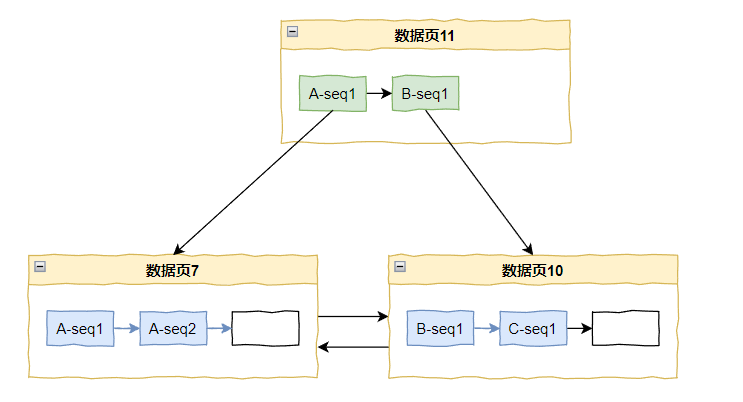
又来了 A-seq3 怎么办?
问题不大,还放的下:
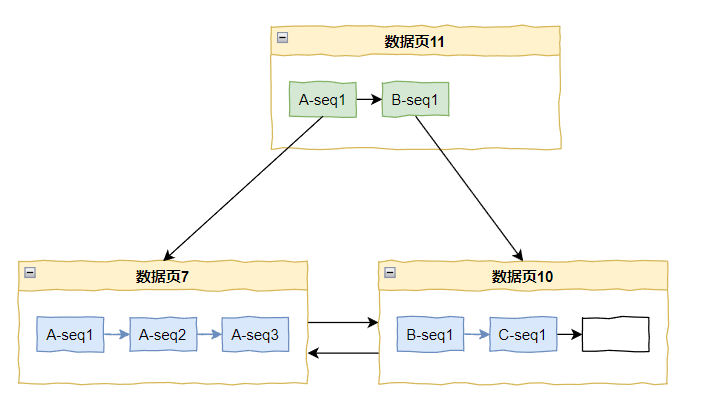
好,这个时候数据页 7 满了,但是又来了 A-seq4,怎么办?
只有继续分裂了:
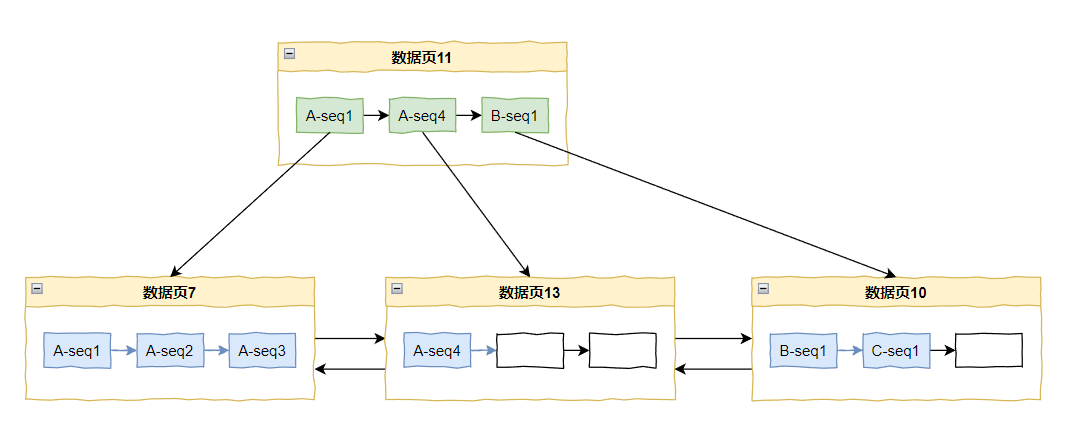
看到这个分裂的时候,你有没有嗦出一丝味道,是不是有点意思了?
因为在节点 A 上生成的任何 ID 都一定小于在节点 B 上生成的任何 ID,节点 B 和节点 C 同理。
在这个范围内,所有的 ID 都是单调递增的:
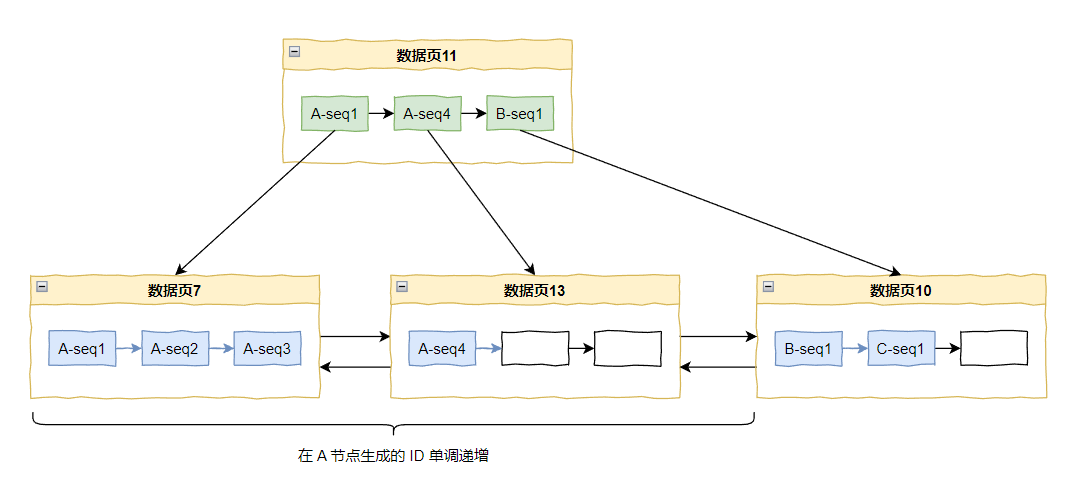
而这样的范围最多有多少个?
是不是有多少个节点,就有多少个?
那么最多有多少个节点?

2 的 10 次方,1024 个节点。
所以官方的文章中有这样的一句话:
新版算法从全局角度来看,ID 是无序的,但对于每一个 workerId,它生成的 ID 都是严格单调递增的,又因为 workerId 是有限的,所以最多可划分出 1024 个子序列,每个子序列都是单调递增的。
经过前面的分析,每个子序列总是单调递增的,所以每个子序列在有限次的分裂之后,最终都会达到稳态。
或者用一个数学上的说法:该算法是收敛的。
再或者,我给你画个图:
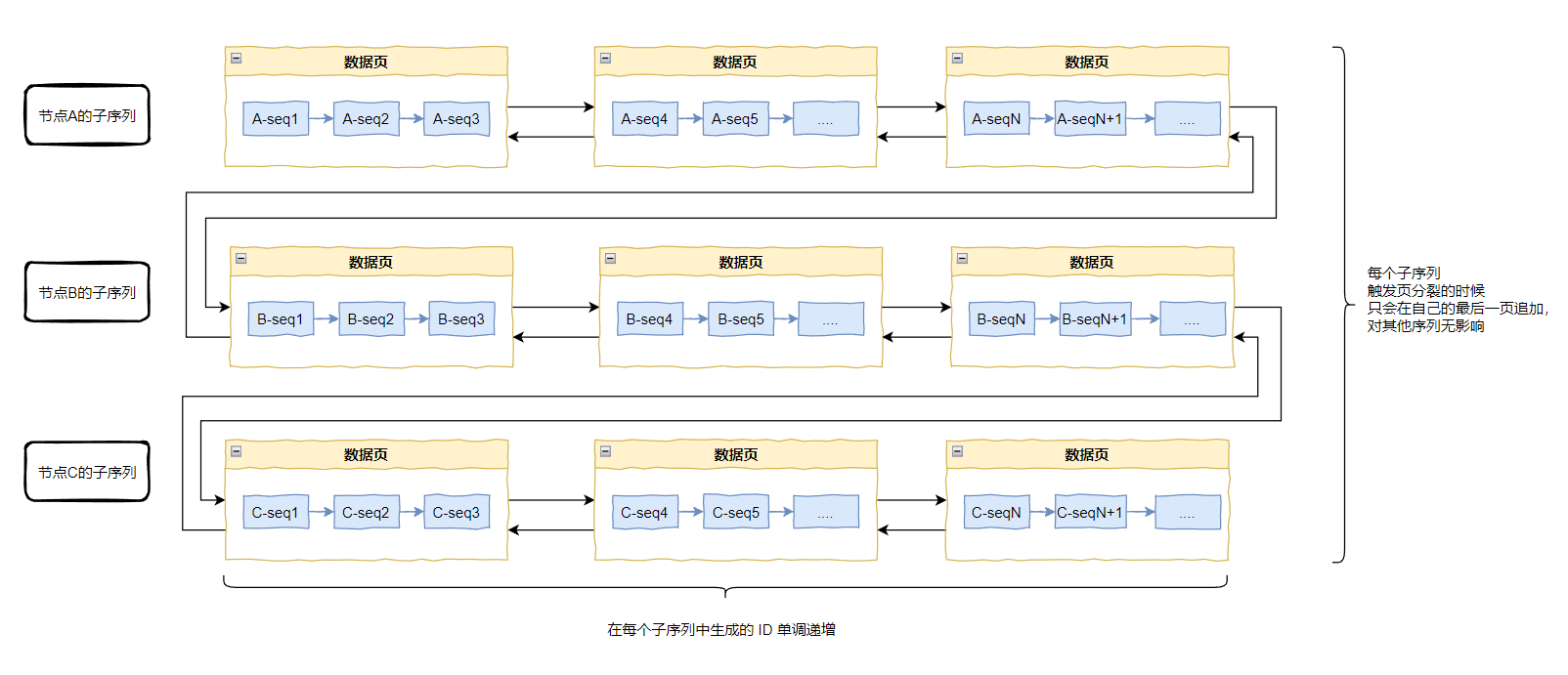
我画的时候尽力了,至于你看懂看不懂的,就看天意了。
如果看不懂的话,自信一点,不要怀疑自己,就是我画的不好。大胆的说出来:什么玩意?这画的都是些啥,看求不懂。呸,垃圾作者。

前面写的所有内容,你都能在官网上我前面提到的两个文章中找到对应的部分。
但是关于页分裂部分,官方并没有进行详细说明。本来也是这样的,人家只是给你说自己的算法,没有必要延伸的太远。
既然都说到页分裂了,那我来补充一个我在学习的时候看到的一个有意思的地方。
也就是这个链接,这一节的内容就是来源于这个链接中:
http://mysql.taobao.org/monthly/2021/06/05/
还是先搞个图:
问,在上面的这个 B+ tree 中,如果我要插入 9,应该怎么办?
因为数据页中已经没有位置了,所以肯定要触发页分裂。
会变成这样:

这种页分裂方式叫做插入点(insert point)分裂。
其实在 InnoDB 中最常用的是另外一种分裂方式,中间点(mid point)分裂。
如果采用中间点(mid point)分裂,上面的图就会变成这样:
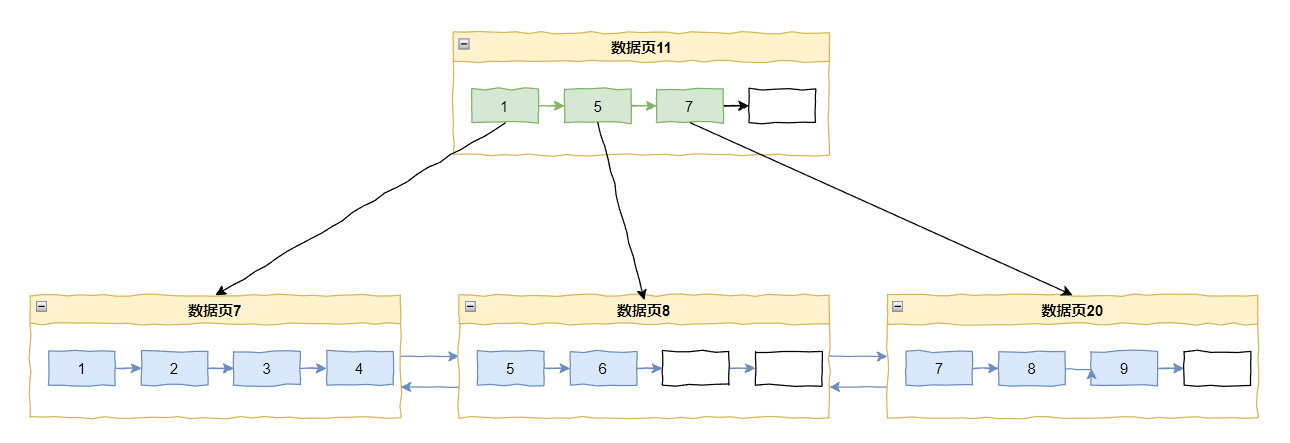
即把将原数据页面中的 50% 数据移动到新页面,这种才是普遍的分裂方法。
这种分裂方法使两个数据页的空闲率都是 50%,如果之后的数据在这两个数据页上的插入是随机的话,那么就可以很好地利用空闲空间。
但是,如果后续数据插入不是随机,而是递增的呢?
比如我插入 10 和 11。
插入 10 之后是这样的:
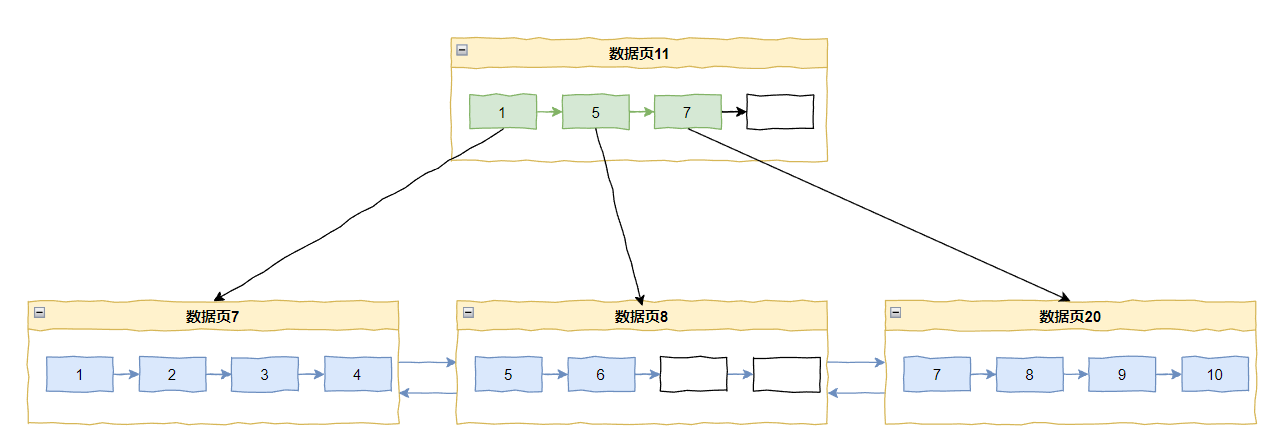
插入 11 的时候又要分页了,采用中间点(mid point)分裂就变成了这样:
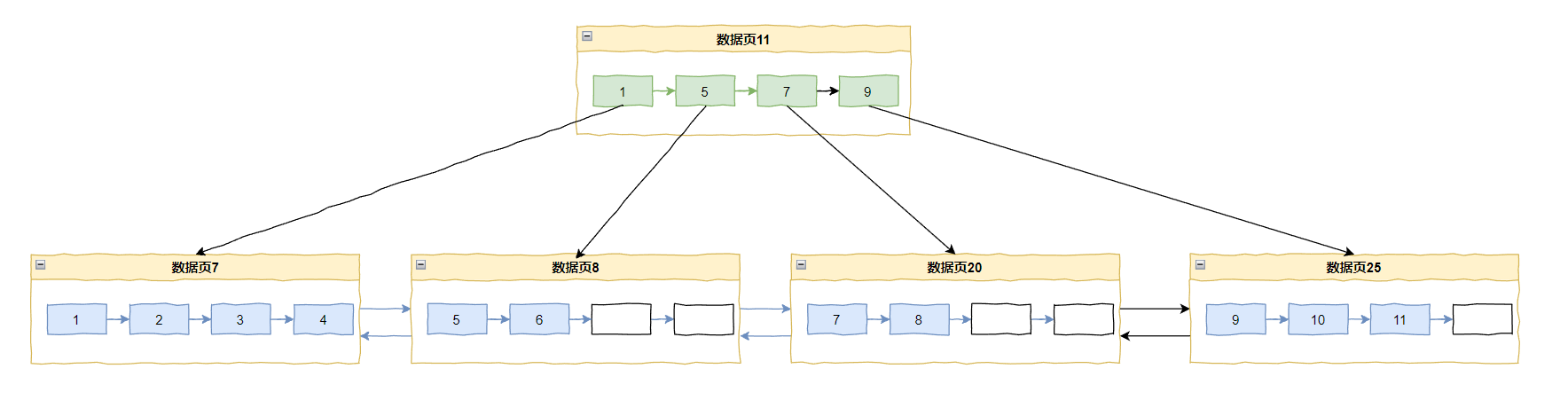
你看,如果是在递增的情况下,采用中间点(mid point)分裂,数据页 8 和 20 的空间利用率只有 50%。
因为数据的填充和分裂的永远是右侧页面,左侧页面的利用率只有 50%。
所以,插入点(insert point)分裂是为了优化中间点(mid point)分裂的问题而产生的。
InnoDB 在每个数据页上专门有一个叫做 PAGE_LAST_INSERT 的字段,记录了上次插入位置,用来判断当前插入是是否是递增或者是递减的。
如果是递减的,数据页则会向左分裂,然后移动上一页的部分数据过去。
如果判定为递增插入,就在当前点进行插入点分裂。
比如还是这个图:
上次插入的是记录 8,本次插入 9,判断为递增插入,所以采用插入点分裂,所以才有了上面这个图片。
好,那么问题就来了,请听题:
假设出现了这种情况,阁下又该如何应对?
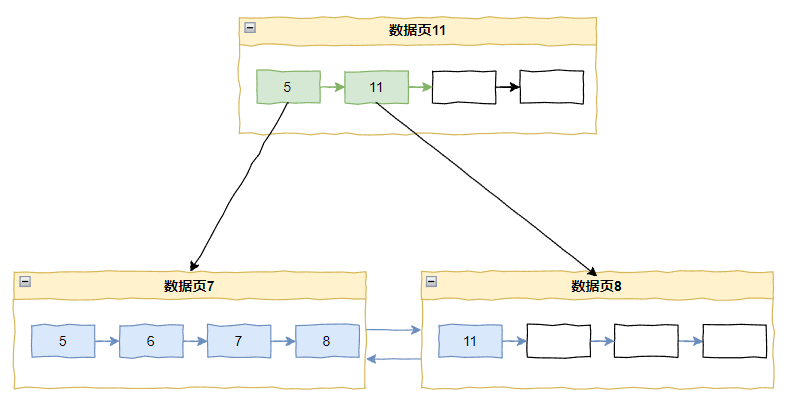
在上面这个图的情况下,我要插入 10 和 9:
当插入 10 的时候,按 InnoDB 遍历 B+ tree 的方法会定位到记录 8,此时这个页面的 PAGE_LAST_INSERT 还是 8。所以会被判断为递增插入,在插入点分裂:
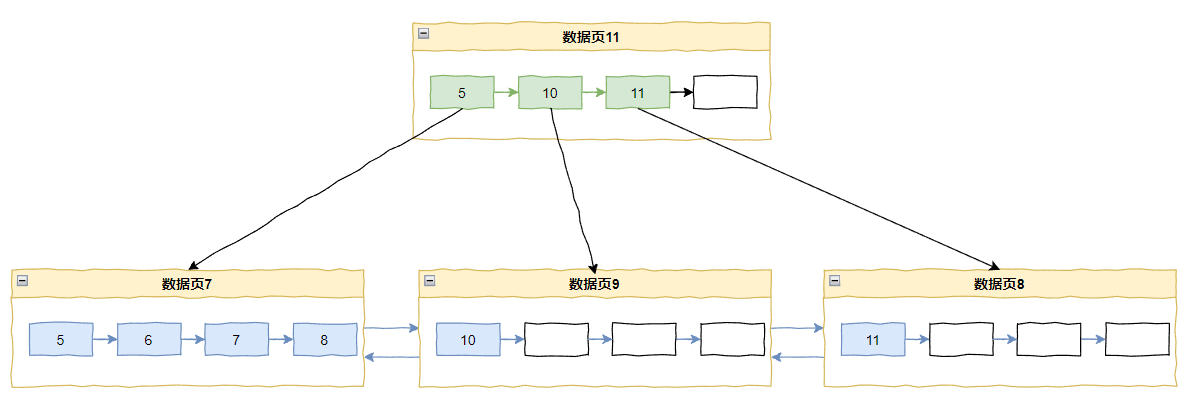
同理插入 9 也是这样的:
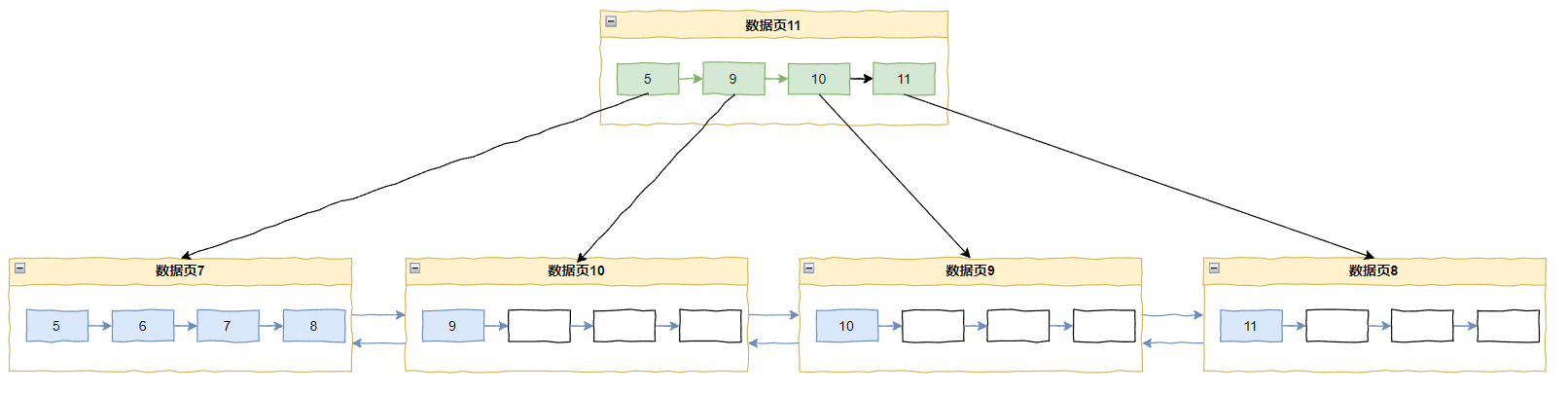
最终导致 9、10、11 都独自占据一个 page,空间利用率极低。
问题的根本原因在于每次都定位到记录 8(end of page),并且都判定为递增模式。
哦豁,你说这怎么办?
答案就藏在这一节开始的时候我提到的链接中:
前面我画的所有的图都是在没有并发的情况下展开的。
但是在这个部分里面,牵扯到了更为复杂的并发操作,同时也侧面解释了为什么 InnoDB 在同一时刻只能有有一个结构调整(SMO)进行。
这里面学问就大了去了,有兴趣的可以去了解一下 InnoDB 在 B+ tree 并发控制上的限制,然后再看看 Polar index 的破局之道。
反正我是学不动了。
哦,对了。前面说了这么多,还只是聊了页分裂的情况。
有分裂,就肯定有合并。
那么什么时候会触发页合并呢?
页合并会对我们前面探讨的 Seata 的改良版雪花算法带来什么影响呢?
别问了,别问了,学不动了,学不动了。

自己看一下吧:

最后,如果本文对你有一点点帮助的话,点个免费的赞,求个关注,不过分吧?

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK