

全链路根因定位,虎牙APM可观测平台建设实践 - 运维 - dbaplus社群:围绕Data、Blockc...
source link: https://dbaplus.cn/news-134-5398-1.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
全链路根因定位,虎牙APM可观测平台建设实践

随着虎牙业务量的大规模增长,分布式应用服务架构日益复杂,排障定位变得越来越困难,原有传统监控方式已无法跟上业务发展需要。虎牙新建设了一套APM平台,结合虎牙直播业务特性,也紧靠业界标准做了高度自研扩展,帮助研发和运维提高工作效率,保障线上应用服务稳定运行。
本次分享将通过以下几个部分来介绍整体思路和实践过程:
分享概要
一、项目背景 - 从当时痛点来思考关键切入点
二、方案实践 - 采集、关联、分析的设计思路和整体架构
三、效果展示 - 一站式排障,全链路根因定位
四、开放赋能 - Metric & Trace & Log对外赋能
五、Q&A
一、项目背景

虎牙当时各团队的应用监控方案多样,有自建应用接口日志采集监控,也有直接使用各类开源Trace系统,这样就导致跨团队的链路无法相互打通,同时也缺乏统一的产品设计,极大地影响了整体排障效率。
2.切入点从客户端到后端分布式应用服务的全链路打通,提供透明零成本的接入方案快速覆盖业务,对Metric/Trace/Log监控数据进行整合并分析错误和异常,最终做到全链路根因定位。
3.目标建设APM可观测项目落地,根据错误的发现、定位和影响面分析等核心指标来指导方向和衡量效果,最终帮助用户提高排障效率。
二、方案实践
1.设计方案思考
-
数据采集:接入透明零成本是用户愿意接的关键
-
数据关联:Metric & Trace & Log的可观测关联模型设计
-
全链路:客户端 -> Nginx/信令 -> 分布式应用服务 -> 数据库/缓存
-
根因定位:根据关联模型数据的实时自动化分析来发现和定位问题
2.可观测模型分析
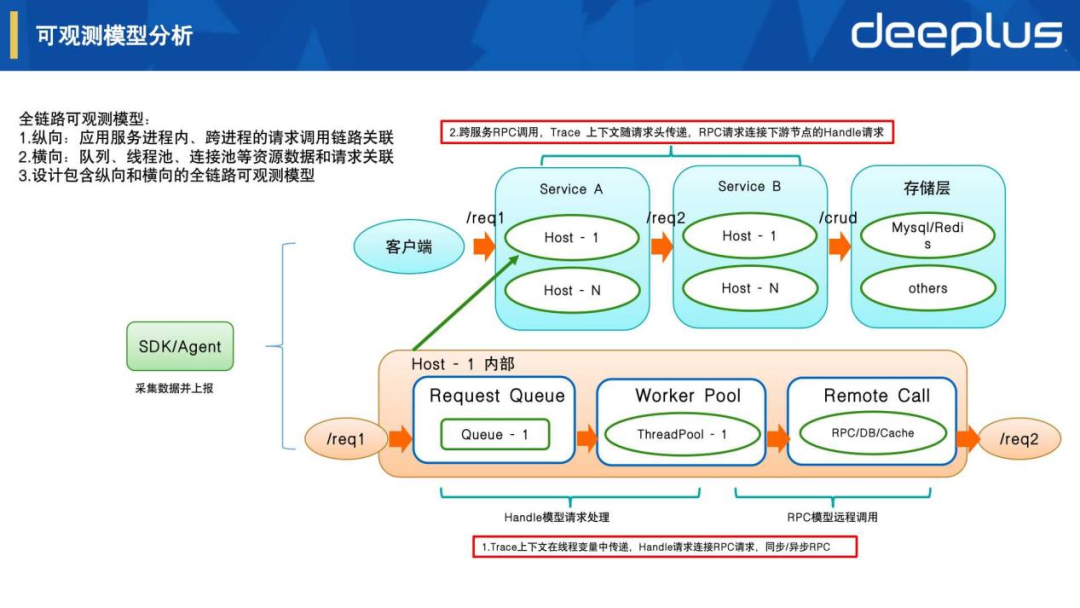
根据应用服务处理请求的过程设计以下模型:
-
Handle模型
描述该应用服务处理了什么请求,调用什么处理方法,使用什么资源等,包括相关Metric/Span/Log数据采集,Trace上下文随请求处理在线程本地变量中进行透明传递。
-
RPC模型
描述该应用服务有什么RPC、Http、数据库、缓存等请求调用,包括相关Metric/Span/Log数据采集,Trace上下文随请求头在跨服务进程之间传递。
-
可观测模型关联
-
纵向:应用服务进程内、跨进程的请求调用链路关联
-
横向:队列、线程池、连接池等资源数据和请求关联
总结:设计包含从Handle和RPC数据采集,到纵向和横向整体关联的全链路可观测模型,我们根据模型进一步设计了SDK和服务端的整体架构。
3.SDK架构介绍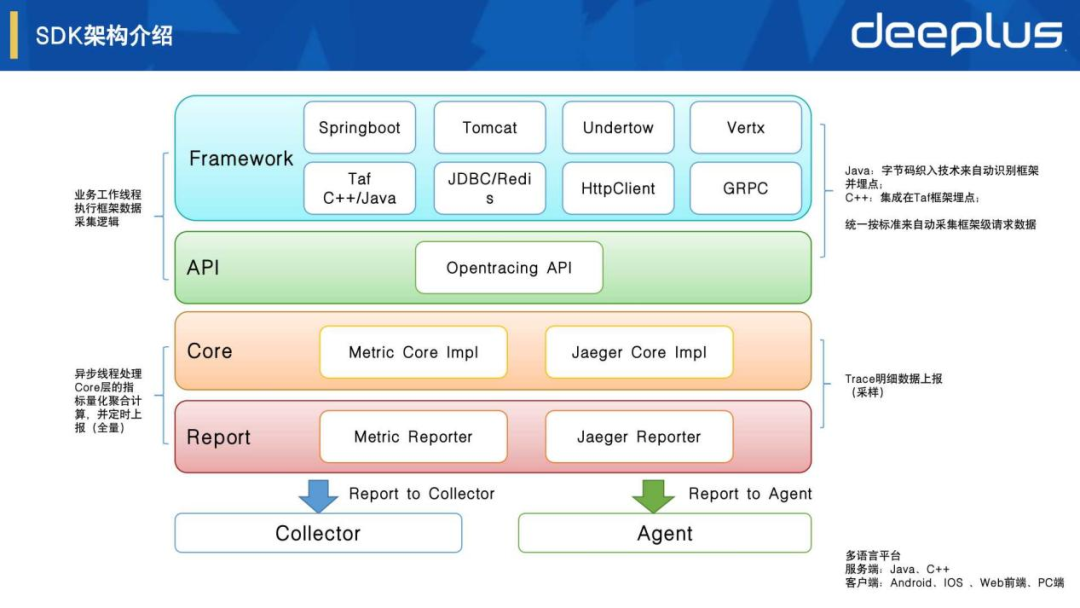
-
零成本接入
-
Java:字节码织入技术来自动识别多种框架并埋点
-
C++:集成在Taf框架埋点
-
客户端:集成在信令SDK埋点
-
基于业界标准
基于Opentracing标准选择了Jaeger tracing的实现,通过自研设计和实现了Metric采集、聚合和关联等逻辑。
-
分层和插件化
整体SDK架构分层清晰,基于Opentracing标准接口,相关底层和框架层都可以扩展实现一些个性功能,通过插件化设计来按需加载使用。
-
全量和采样
Metric指标全量采集并聚合后上报。Trace Span明细需要采样,支持远程控制的动态前置采样,以及有损后置采样方案。
4.服务端架构介绍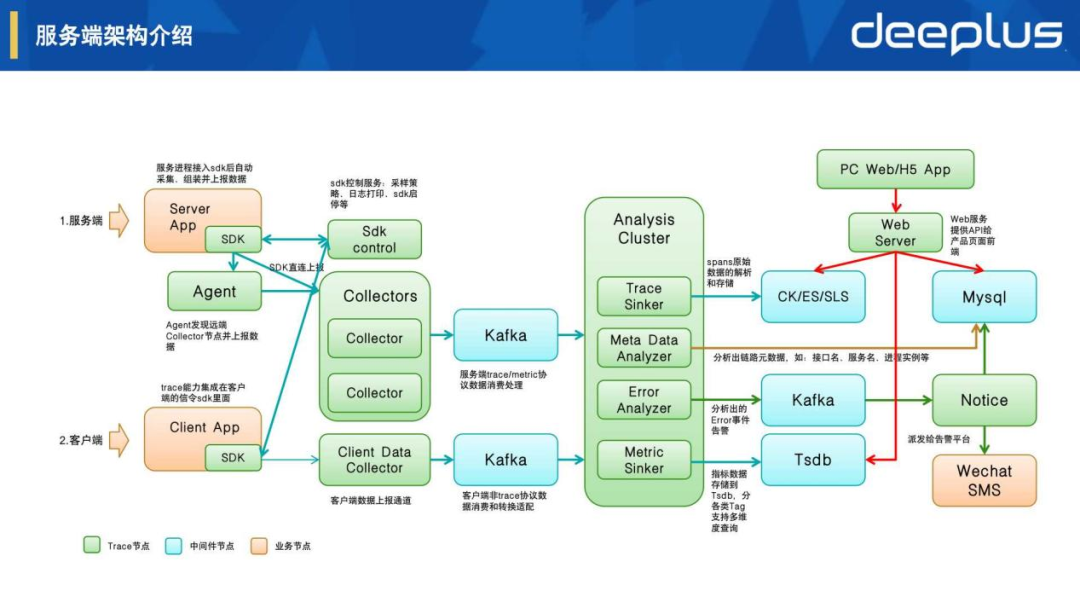
-
采集、上报和控制
-
Server App:Trace SDK在应用服务框架层进行自动化采集和上报
-
Client App:集成在信令SDK层进行自动化采集和上报
-
Sdk Control:sdk远程控制服务,包括采样策略、日志打印、功能启停等控制
-
Collector:数据接收服务,处理流控、验证、清洗、转换等逻辑
-
存储、分析和告警
-
Trace Sinker:spans明细数据的解析和存储,按自研模型设置具体明细tags和logs
-
Metric Sinker:指标数据解析和存储,按自研模型设置相应的指标维度tags
-
Meta Data Analyzer:分析出链路元数据,包含:请求uri、接口名、服务名、进程实例等
-
Error Analyzer:分析时间线错误和异常来发现问题,再通过指标关联和链路追踪来定位根因
-
可视化和告警输出
-
Web Server:产品后端的API服务,负责数据检索和业务逻辑处理
-
Web/H5 App:产品前端的页面展示、交互处理等可视化能力
-
Wechat/SMS:企业微信、短信等方式的告警输出
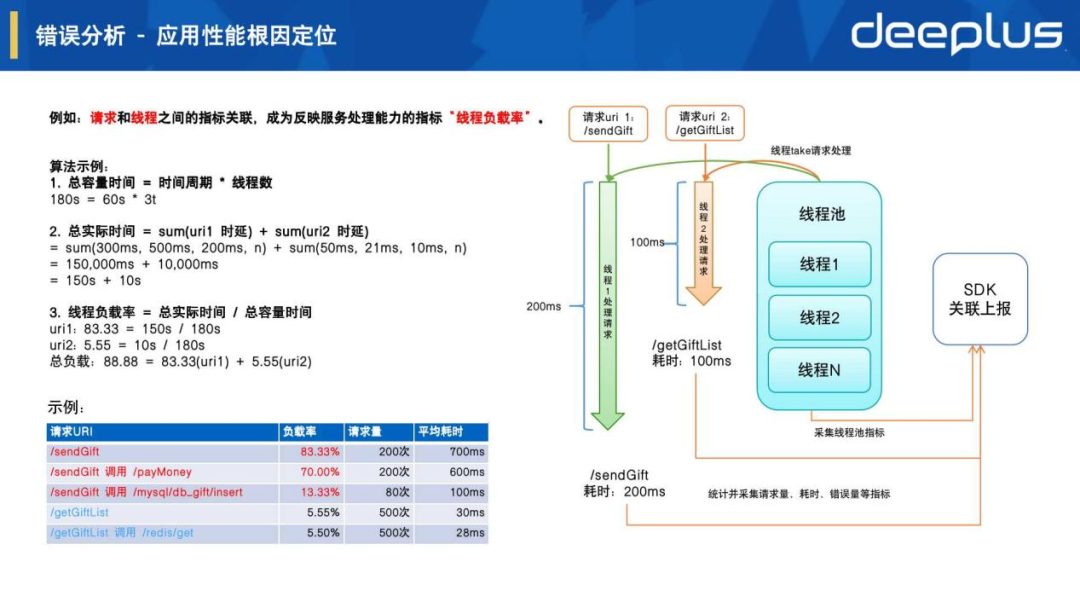
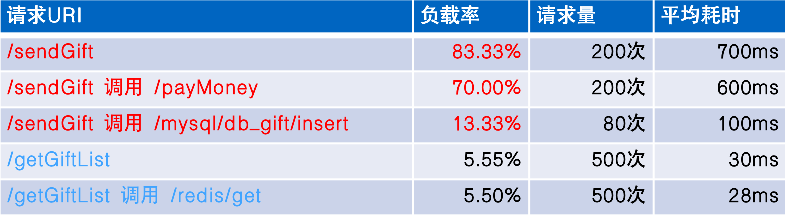
上图右边可以看到对请求处理流程的进一步解析,核心在于如何把请求处理追踪和线程资源进行关联,我们设计了反映服务处理能力的指标:线程负载率
上图左边的算法示例可以看到能发现应用服务GiftServer出现了线程负载高,应用性能不足问题,通过各请求的负载率分布来进一步分析,可以发现是由于/sendGift请求处理导致,而它里面的RPC请求/payMoney是根因问题。
效果示例:
-
Metric错误检测
如上图绿色框内是对应用服务内部Handle和RPC模型各类指标进行错误检测:
Request Metrics // 请求指标uri: /payMoney // 请求uri或方法名totalCount: 1000 // 总请求数errorCount: 200 // 错误请求数latency avg: 2000ms // 请求平均耗时errorRate: 20% // 请求错误率...
发现请求错误率和平均耗时增加并在几个周期内连续出现,按对应的告警分析规则就会判定为异常并产生实时告警发送给用户。
-
Metric关联分析
如上图指标的tag会记录相应维度信息来建立指标关联,并通过的指标和链路关联来进行错误根因分析:
service: GiftServer // 应用服务名host: 192.168.1.1:8080 // 服务实例ip portpeerService: MoneyServer // rpc对端服务名peerHost: 192.168.1.2:8081 // rpc对端实例ip porttype: rpc // 请求类型service: MoneyServer // 应用服务名host: 192.168.1.2:8081 // 服务实例ip portpeerService: Mysql // rpc对端服务名peerHost: 192.168.1.3:3306 // rpc对端实例ip porttype: mysql // 请求类型建立关联:请求: /sendGift 调用 /payMoney服务: GiftServer 调用 MoneyServer实例: 192.168.1.1:8080 调用192.168.1.2:8081
-
Metric & Trace & Log
如上图底部所示,通过从Metric宏观错误告警到下钻Trace/Log明细的关联分析,建设实时全链路根因定位的平台能力。
三、效果展示
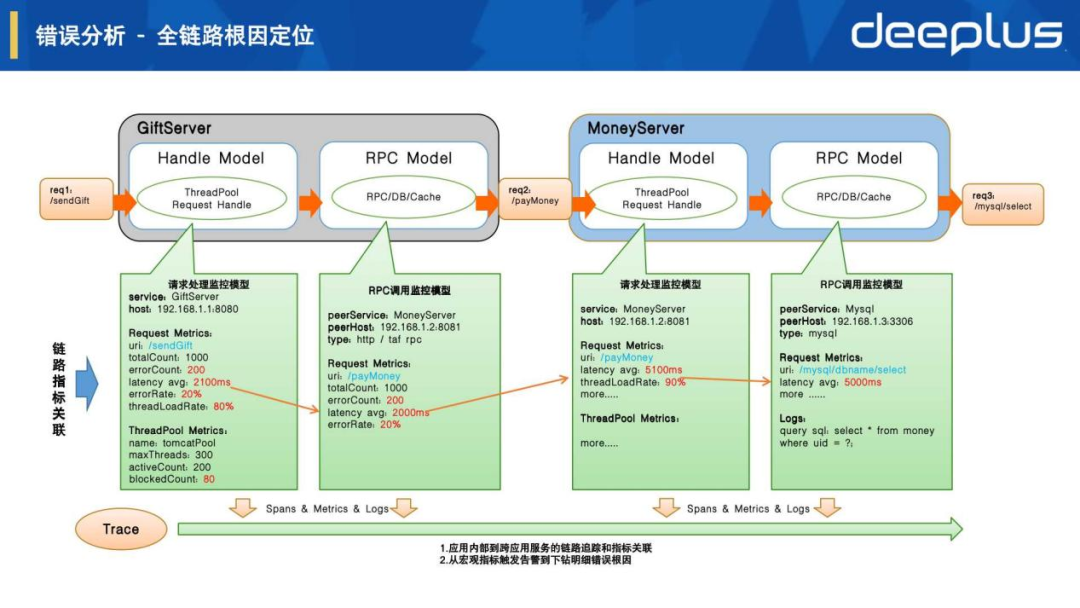
1.全链路根因分析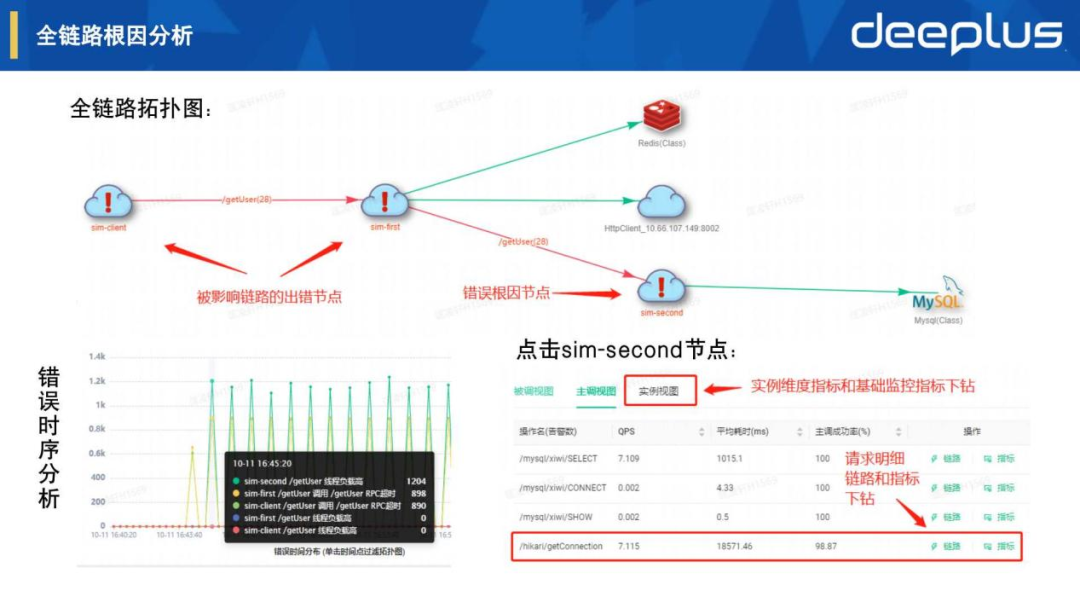
如上图全链路拓扑图展示错误根因节点和被影响链路节点,点击节点可以进一步按被调、主调和实例视图来查看宏观指标情况,其中我们定位到是/hikari/getConnection耗时比较长导致,我们还可以点击链路按钮来进一步下钻分析。
2.链路 - Trace明细分析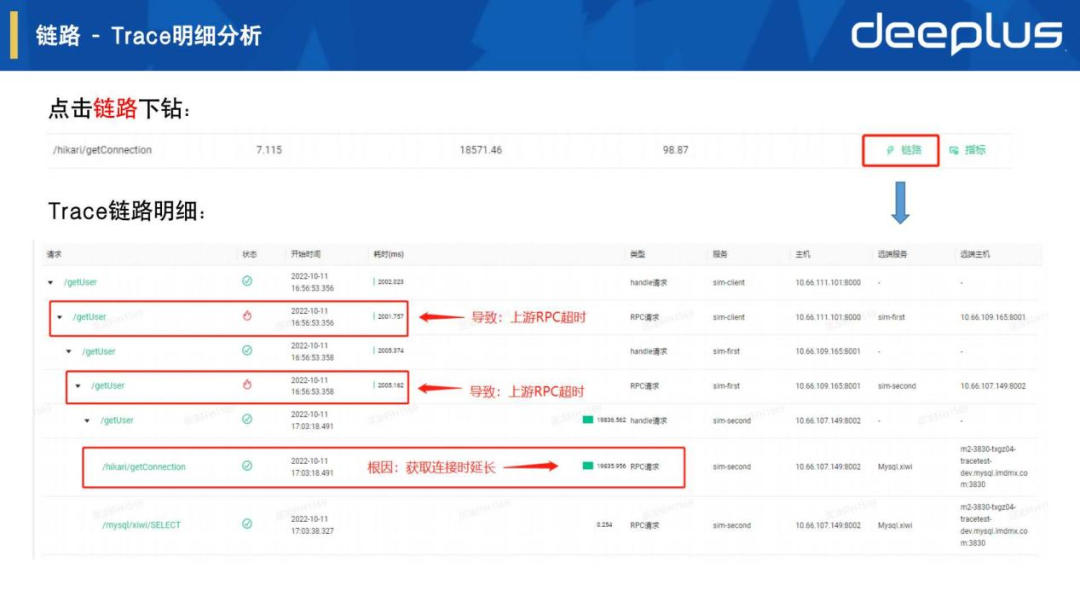
点击链路按钮后打开Trace链路明细页面,可以看到每次请求的明细链路情况,点击其中一条出错的Trace,就可以看到如上图所示的请求调用链视图。可以快速分析定位到根因是获取链接/hikari/getConnection的耗时长,导致上游的/getUser请求处理超时。
3.指标 - 应用性能分析
点击指标按钮后可以看具体的应用进程性能,通过右图表请求处理的线程负载占比可以看到请求 /getUser 调用 /hikari/getConnection的线程负载率占比较高,左图表线程状态分析发现其根因是由于大多数工作线程阻塞在获取连接的操作上。
4.指标 - 请求性能分析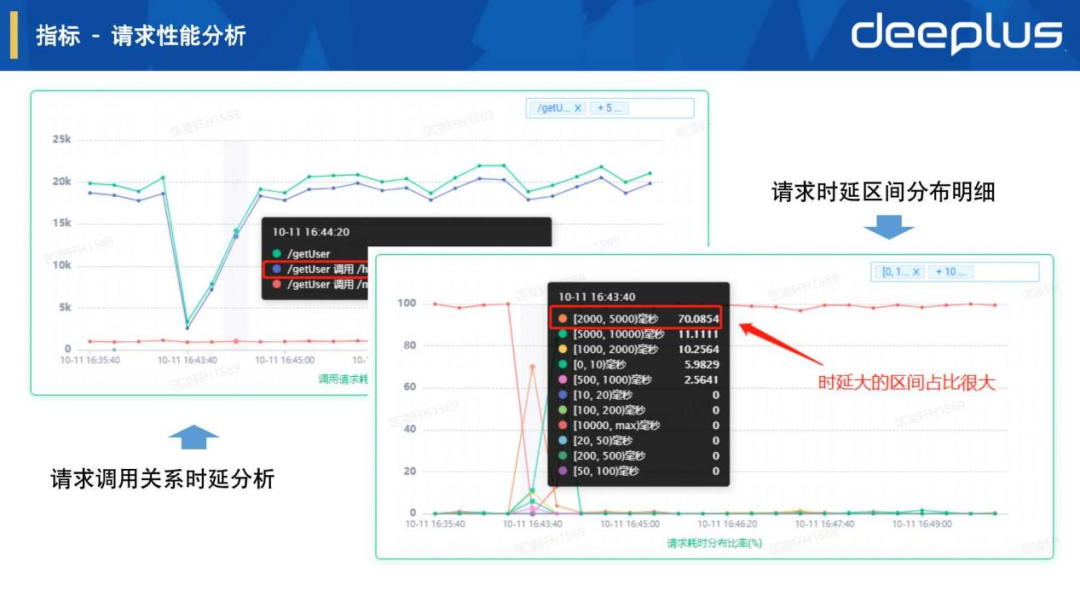
来进一步看更多的请求性能指标,通过右图表请求调用关系时延可以看到请求 /getUser 调用 /hikari/getConnection的平均耗时很大,左图表可以分析具体的请求耗时区间分布占比情况,通过以上各种时序折线图帮助我们快速分析具体的指标异常和变化趋势。
5.告警分析 - 单节点聚集性问题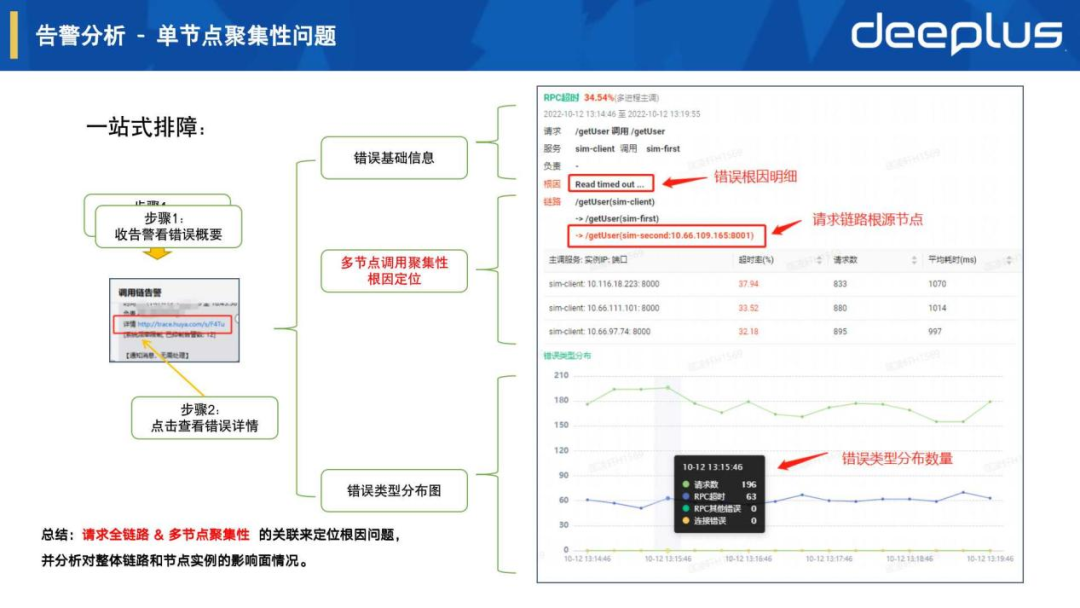
如上图一站式排障流程,错误详情页面由上至下展示了错误基础信息、错误类型分布图等,这里可重点介绍一下中间的多节点调用聚合性根因定位:
链路 /getUser(sim-client) // URI接口(应用服务名)-> /getUser(sim-first)-> /getUser(sim-second:10.66.109.165:8001) // URI接口(应用服务名:实例ip:端口)根因 Read timed out... // trace span log存储的异常信息,也可进一步看异常堆栈
主调影响范围如下表:
| 主调服务:实例ip:端口 | 超时率(%) | 请求数 | 平均耗时(ms) |
| sim-client:10.116.18.223:8000 | 37.94 | 833 | 1070 |
| sim-client:10.116.18.223:8000 | 33.52 | 880 | 1014 |
| sim-client:10.116.18.223:8000 | 32.18 | 895 | 997 |
总结:从上面信息可以直接看出多个节点主调发生超时异常,是由于链路的根因节点sim-second:10.66.109.165:8001导致,并能快速把范围性影响的根因聚集到具体出错节点上。该场景的核心就是把请求全链路 & 多节点聚集性进行关联分析。
6.告警分析 - 应用性能瓶颈问题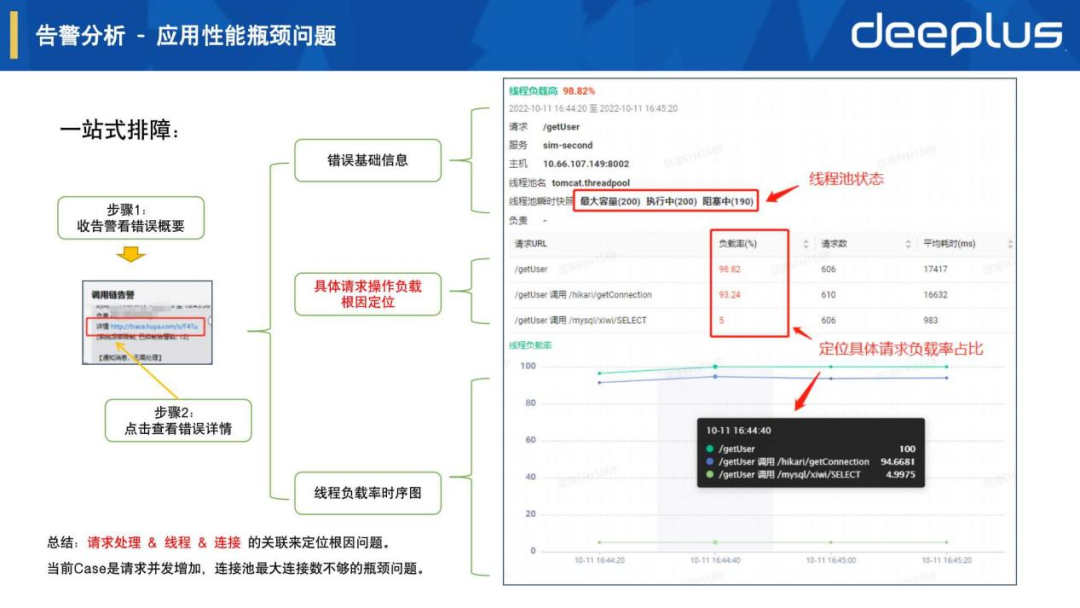
如上图一站式排障流程,错误详情页面由上至下展示了错误基础信息、线程负载率时序图等,还是重点介绍中间的请求负载根因定位:
线程池名 tomcat.threadpool // 关联当前服务框架的工作线程池线程池快照 最大容量(200) 执行中(200) 阻塞中(190) // 关联线程池资源指标
线程负载分布如下表:
| 请求URI | 负载率(%) | 请求数 | 平均耗时(ms) |
| /getUser | 98.82 | 606 | 17417 |
| /getUser 调用 /hikari/getConnection | 93.24 | 610 | 16632 |
| /getUser 调用 /hikari/xiwi/SELECT | 5 | 606 | 983 |
总结:从上面信息可以一直看出工作线程池已经跑满,而且大部分线程执行中遇到了阻塞等待,从负载率具体请求分布来看,根因是由于/getUser 调用 /hikari/getConnection占比较高导致。该场景的核心就是把请求处理 & 线程 & 连接进行关联分析。
四、开放赋能

自从APM可观测平台上线运营后,除了用户对产品一些反馈需求,也收到了很多对于平台能力开放的需求,因此我们建设了APM开放平台,用于开放能力赋能公司其他团队,如上图所示:
Case1:Metric时序数据赋能AIOps异常检测,提供各应用服务的请求时序数据给AI模型训练,对部分个性服务和指标提供AI告警。
Case2:Trace明细数据赋能自动化测试请求追踪,自动化测试可以快速从客户端到服务端全链路获取错误根因,集成在自身系统逻辑中。
Case3:Trace包裹传递赋能全链路请求染色,如对某个用户进行染色后,会保障用户uid随着trace上下文在整个请求链路进行透明传递,各应用服务都可通过trace sdk的api获取用户uid来打印日志或其他操作。
总结:APM可观测平台这块在虎牙统一可观测规划上属于应用监控/链路追踪,我们也在推进基础设施监控、业务监控一起做一些整合,关键切入点还是在于各监控平台元数据的关联分析,后续有机会再介绍这块的思考和实践。
Q&A
Q1:对应用有没有性能影响?A1:Metric数据对应用性能影响非常小,主要是在异步线程中做相关聚合运算,也就是说会把请求明细span按模型的指标定义来做聚合,生成请求量、耗时分布、错误量等指标,一个周期内10000次请求也只会对指标值做改变,如:请求量: 10000次。但Trace span明细数据量是和请求量相关的,也就是采样率100%的情况下当前节点会上报10000个span,在测试中发现对应用进程会有不少性能开销,如果都上报的话对网络流量和存储也会开销比较大,而大多数的明细span在实践中价值不大,所以会采用一些前置采样加有损后置采样的策略来降低对整体性能和成本的影响。Q2:链路span是怎么跟那个时候的日志和指标关联?A2:SDK会根据Handle和RPC模型把Metric指标设置各种维度tag,这些tag会跟Trace span tag保持对应来关联请求调用链指标和资源指标,而Trace span log会关联保存一些详细异常日志和框架层日志。例如PPT分享的错误分析之应用性能根因定位和全链路根因定位里有详细介绍这块的实现原理,进一步在PPT效果展示中也可以看到把Metric&Trace&Log进行关联分析后的产品效果和应用场景。Q3:开发人员自定义的日志可以采集吗?A3:Java主要使用基于slf4j的log4j或logback实现,我们对此在SDK开发了一个MDC(Mapped Diagnostic Context)扩展,在日志里自动带上traceId、spanId等信息,而C++也把相应能力集成在框架日志组件中。这些自定义日志落盘后会被采集上报,在Log日志平台中可查询展示,我们也跟日志平台在产品层做了打通联动,会自动带上trace id条件来查询该请求链路上的所有自定义日志明细。获取本期PPT,请添加群秘微信号:dbachen
点这里可回看本期直播
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK