

赛博偶像速成指南(二)- SD进阶篇
source link: https://lorexxar.cn/2023/06/02/cyber-girl2/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

在第一篇关于AI绘图的文章中,我主要介绍了stable diffusion的各种使用方法
在midjounry收费之后,除非你对AI绘图这个操作本身有强需求,否则在免费自建的**stable diffusion上做拓展就成了现在最好的解决方案。**
这篇文章就聊一些stable diffusion的一些进阶操作和关键点。其中有不少还是很有意思的。
在线部署stable diffusion
AI相关的东西都有一个很大的共同点就是对GPU的算力要求太高,相比在服务器上运行,更靠谱的方案是在本地电脑上跑,比起动辄5、6位数的服务器,一个入门级的4070ti就已经能应对大量的ai训练场景了。
在Google Colab白嫖GPU
但有个很特殊的东西是Google Colab,这是Google提供的免费GPU算力
现在有很多现成的脚本可以允许你一键部署脚本,就比如
点击打开之后,先点击右上角的连接,会随机分配一个机器给你。
连接成功就会变成绿色
免费的计算单元式有限的,你也可以考虑升级Colab Pro或者Pro+来获得稳定的计算资源。Colab Pro的价格是大概每月75.
在登陆成功并里连接好机器之后,你就可以按照步骤逐步点击操作,每一步点开箭头按钮即可。
这里需要下载的各种内容都会直接下载到你账号对应的Google云端硬盘。
然后是一些比较重要的设置,首先基础的模型包中选择合适的模型,在上篇文章提到过Chilloutmix是一个人像的写实通用模型,正常来说我们都会选择这个。
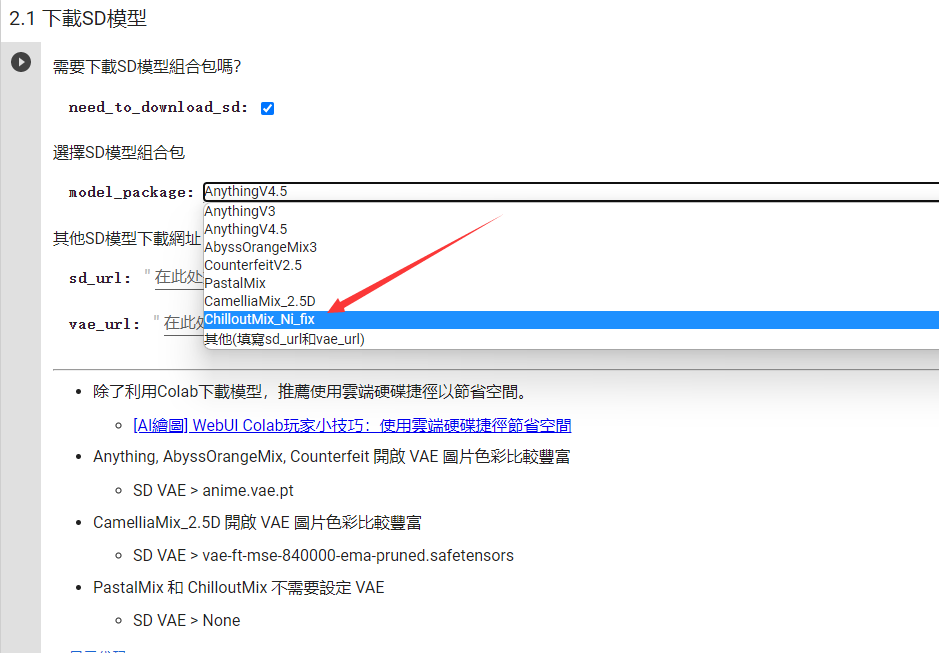
当然,如果你想要下载其他模型,你也可以在这里填入相应的包链接下载。包括后面的LoRa也是一样。其他的大部分内容都不用更改,直接跑完即可。
最后点击运行启动web ui
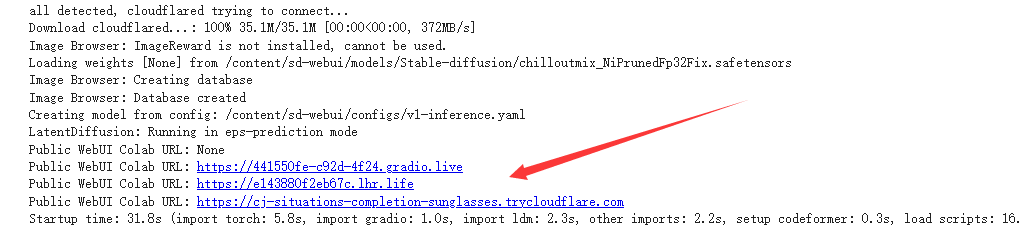
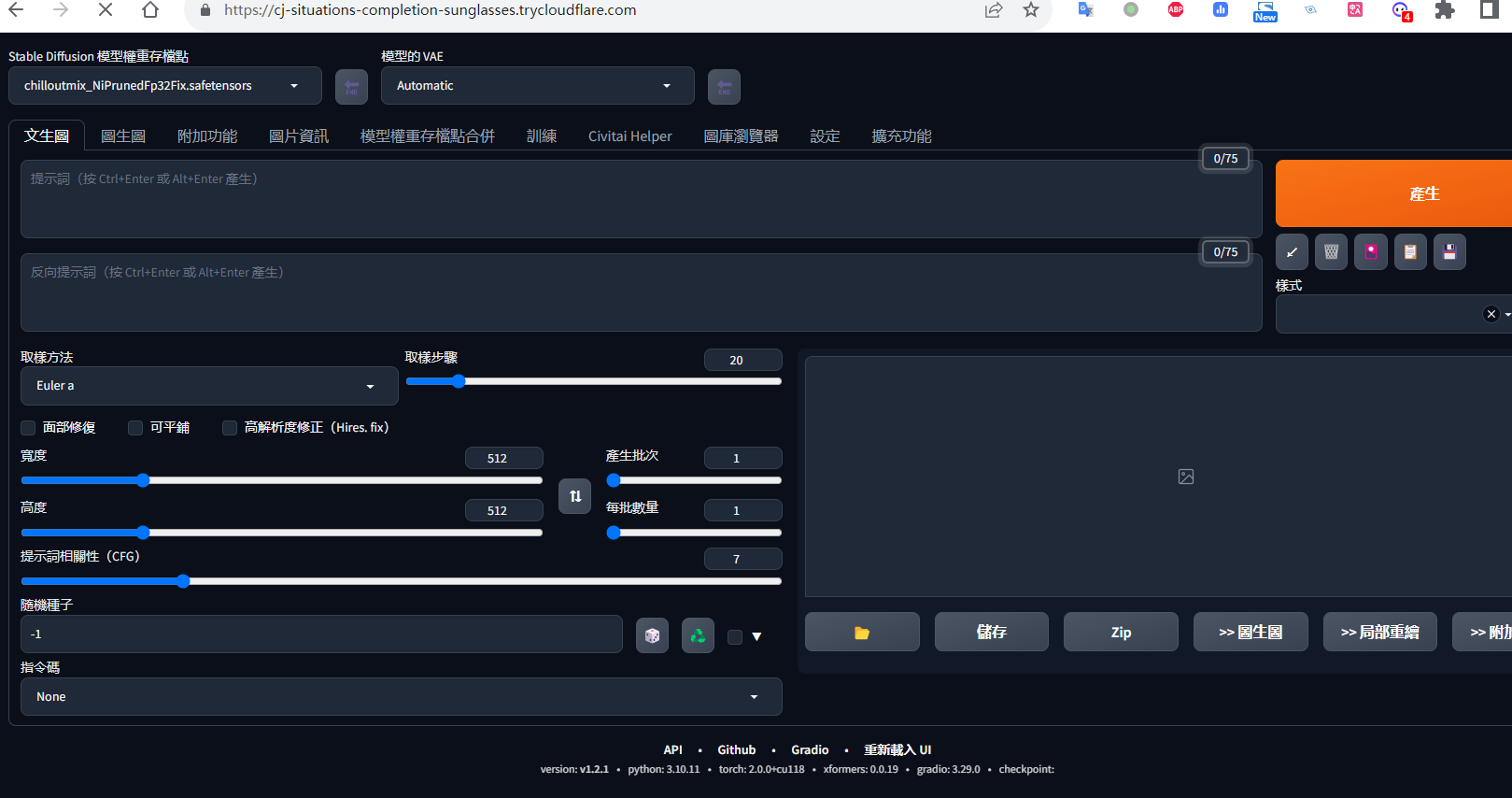
然后你就可以直接使用在线版本的stable了,要注意的是免费的colab会有两个问题
1、免费的colab只能连续运行十几小时,再用就必须停一段时间,就又会获得新的免费时间。
2、在使用人数比较多的时候,免费账户可能会申请不到GPU算力。
当然如果你用的是colab pro就不用这么麻烦了。
在Stable diffusion基础上的第三方
其实市面上有很多很多的第三方开发AI绘图工具是基于Stable diffusion做的,其中很多都很好用,适当的付费就可以换来非常好用的工具,就比如Civitai中,你就可以直接点击跳转到第三方网站付费运行相应的模型。

除了这些内置的以外,其中有个我感觉比较好用的是Vega AI
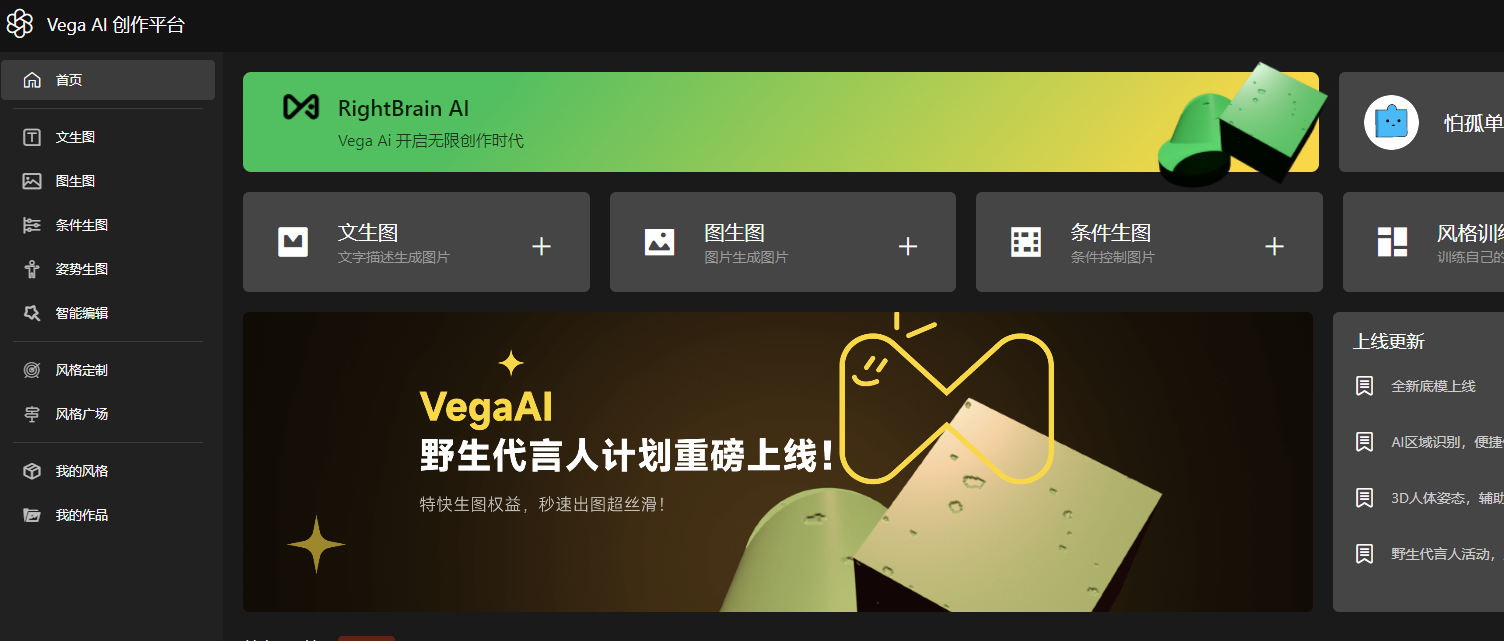
这个网站已经把Stable diffusion包装成很接近midjounry的工具了,你可以非常简单的选择模型并输出描述文案,并且可以在图片基础上做反复微调,虽然这都是Stable diffusion本身的功能,但不得不说在包装后更好用了。
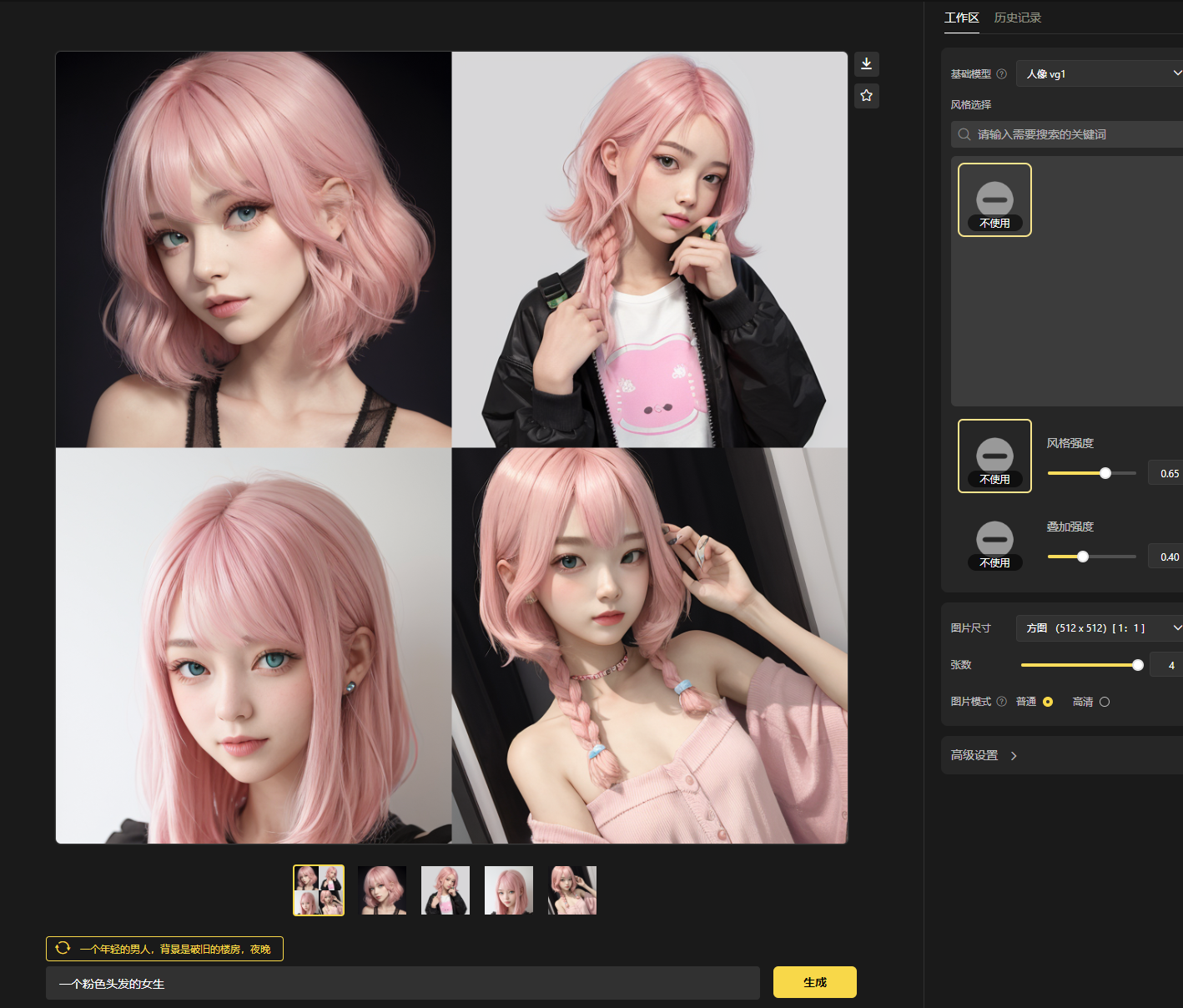
Stable diffusion拓展插件
在上篇文章讲到Stable diffusion本身的各种用法,其实除了本体以外,Stable diffusion还支持拓展插件,可以有非常不错的功能拓展。
Openpose 骨骼绑定
Openpose Editor是一个最近比较流行的骨骼动作编辑插件,你可以直接在下面的链接下载这个插件。
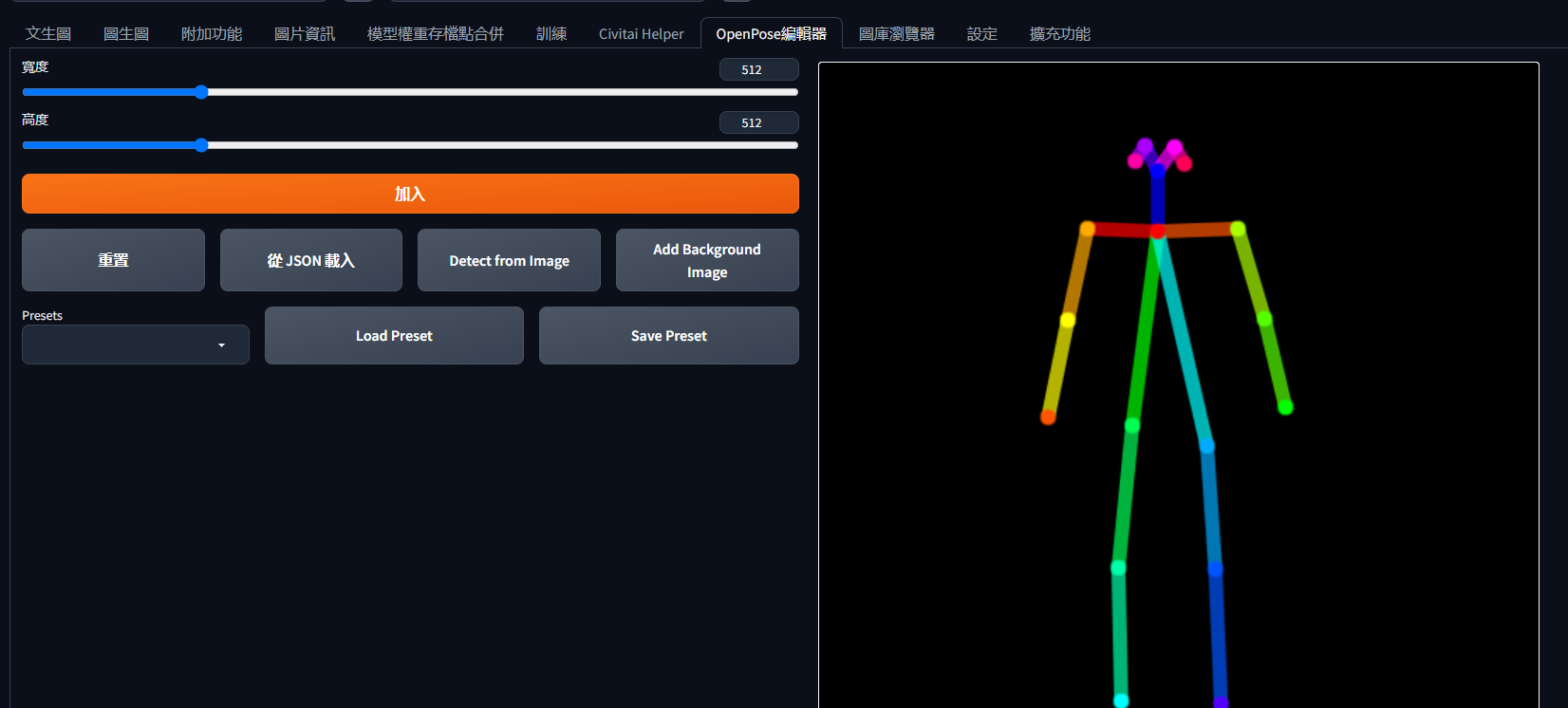
通过这个插件,你可以在一定程度上设定生成图片的人物骨骼结构。从而生成指定的图片。
在导入Openpose插件之后,你可以在上面选择Openpose编辑器

然后选择简单的骨骼结构之后推导到文生图继续编辑,在左下角勾选启用,和低vram模式,其他的基本不用动。
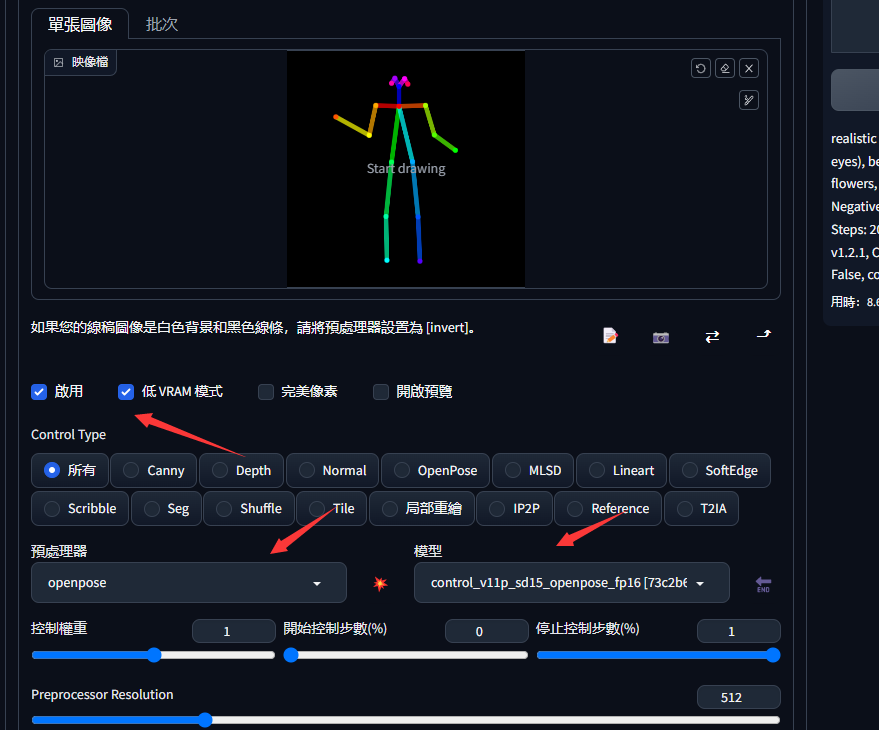
这样就可以跑出来一张指定骨骼样子的图片
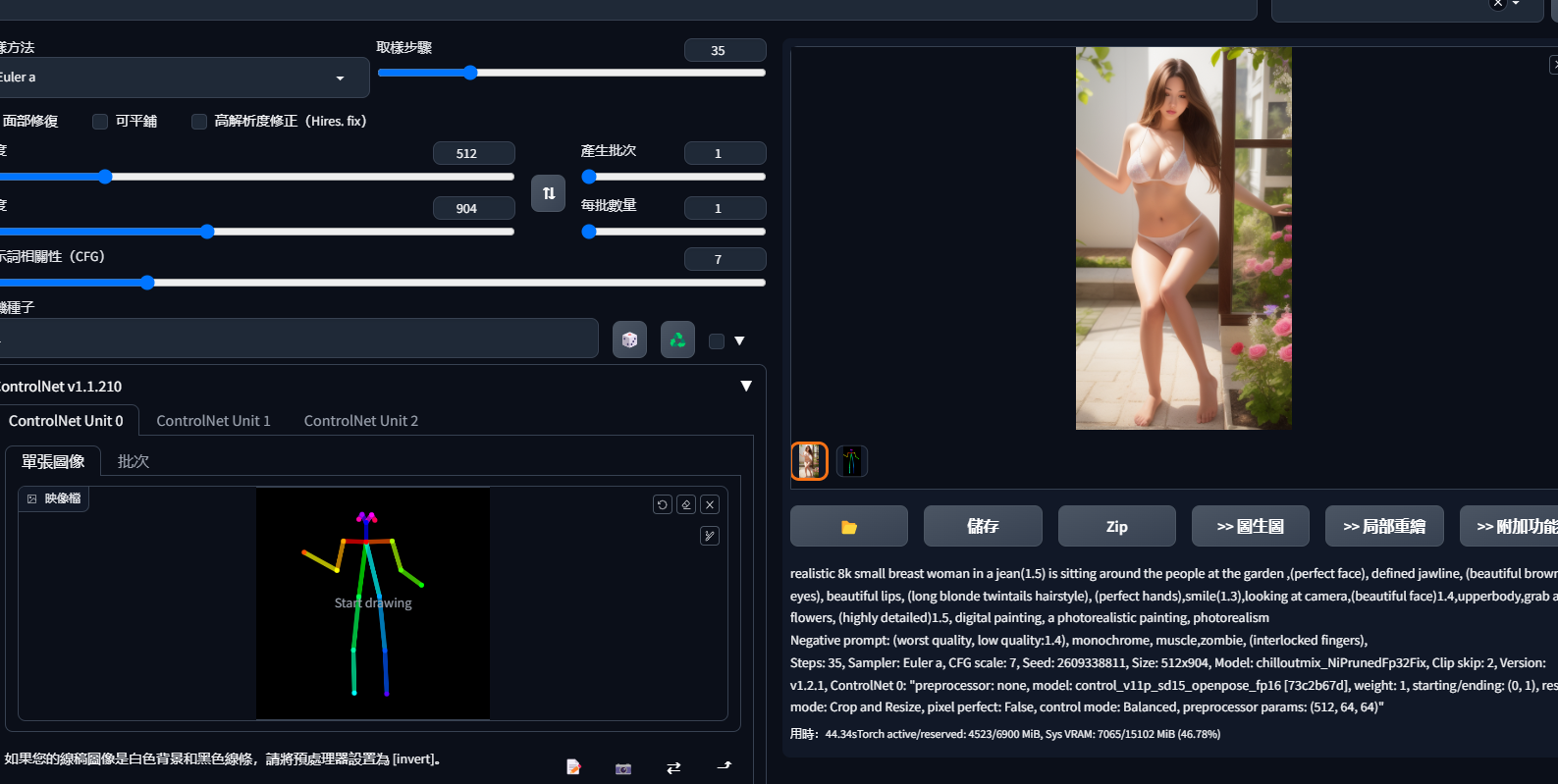
除了指定骨骼以外,你还可以通过上传图片来解构图片本身的骨骼,然后再用来指定和生成,这个Openpose在生成人物图片的优先级以及效果远比图生图效果要好,尤其是可以很大程度还原图片本身的样式。
在OpenPose编辑器中使用Detect from image获取图片中的人物骨骼
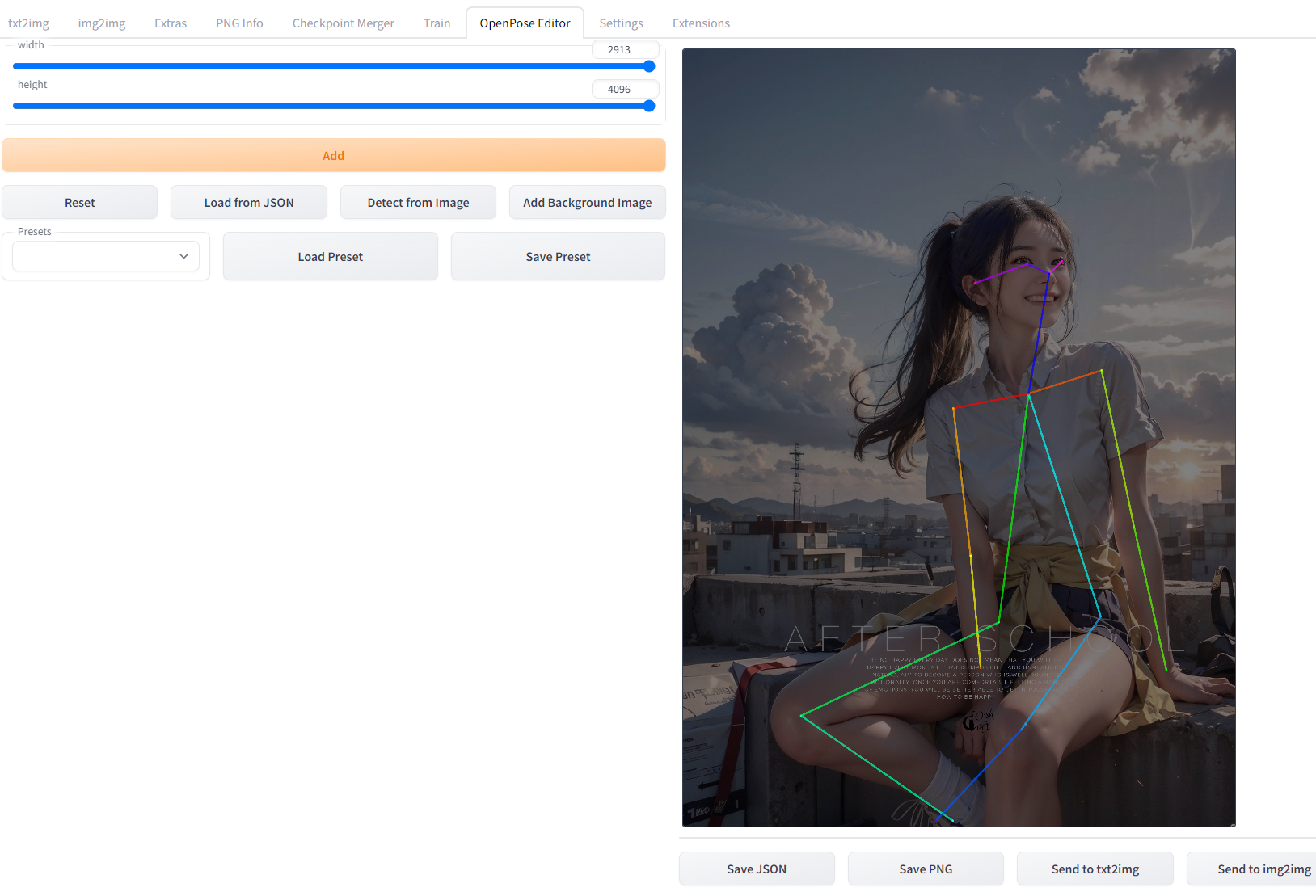
然后发送到文生图或者图生图里传入关键字。等待一会儿就会生成对应的图了
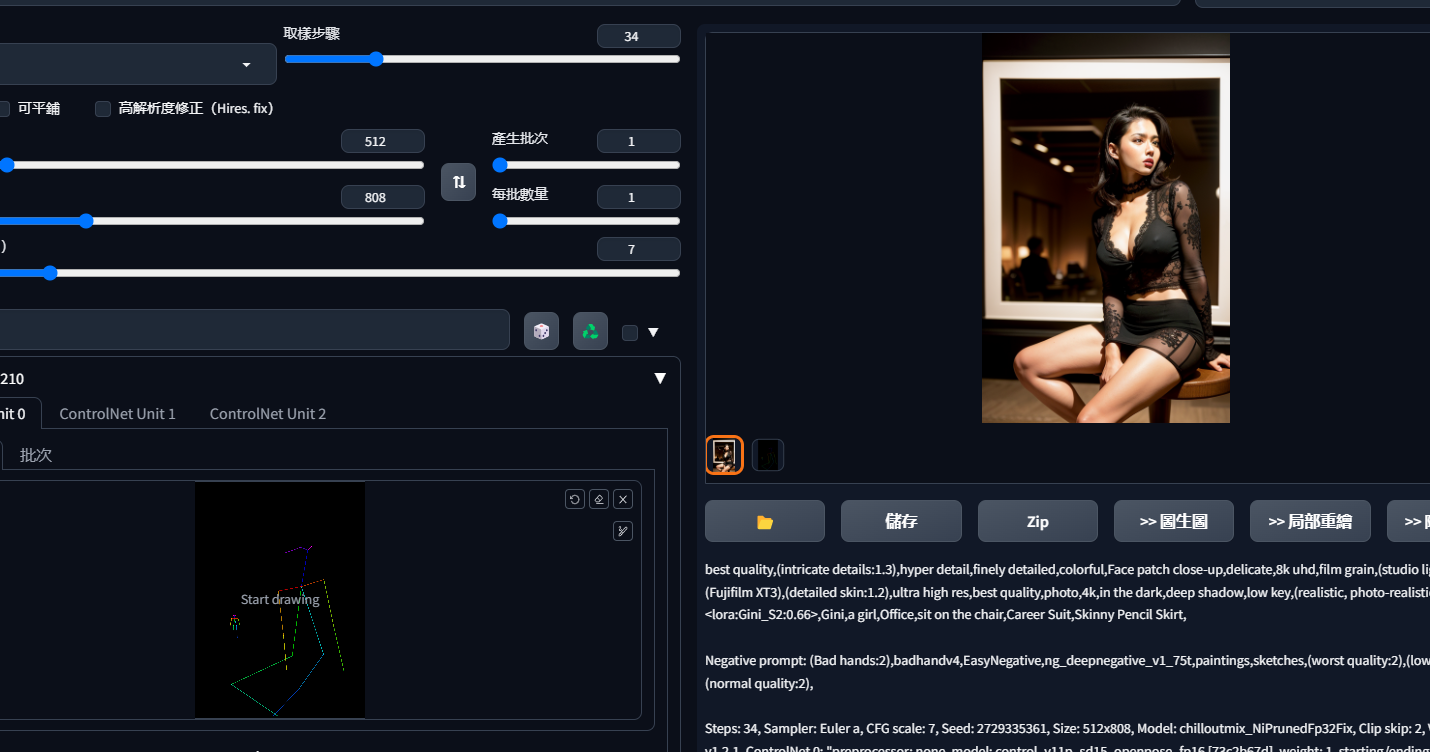
当然这里这个简单的骨骼绑定还是比较简单的一种,配合适当的ControlNet插件你还可以做到线稿成图、色块成图等等类似的操作。
ChatGPT关键字
其实我觉得Stable diffusion里最不实用的关键点就是正向和负向关键字,关键字系统本身相当复杂而且还只能识别英语,并且里面的优先级问题和竞争问题相当复杂,对于使用者来说,这点就是一个相当大的门槛。反之在midjounry中这方面就做的非常好,你可以用中文描述场景在逐步优化。
而现在,你可以用一个简单的ChatGPT插件来实现类似的功能,在配置上chatgpt的api之后你就可以用GPT3.5来解构和构造关键字。
成功安装之后,可以在设置里找到ChatGPT Utilities,点开并配置Chatgpt 的apikey
然后在对应文生图中,script中选择对应的ChatGPT,就会弹出以下的选项卡,我们可以在这里自动生成prompt.
后台会用你设定的ChatGPT apikey去生成图片的prompt
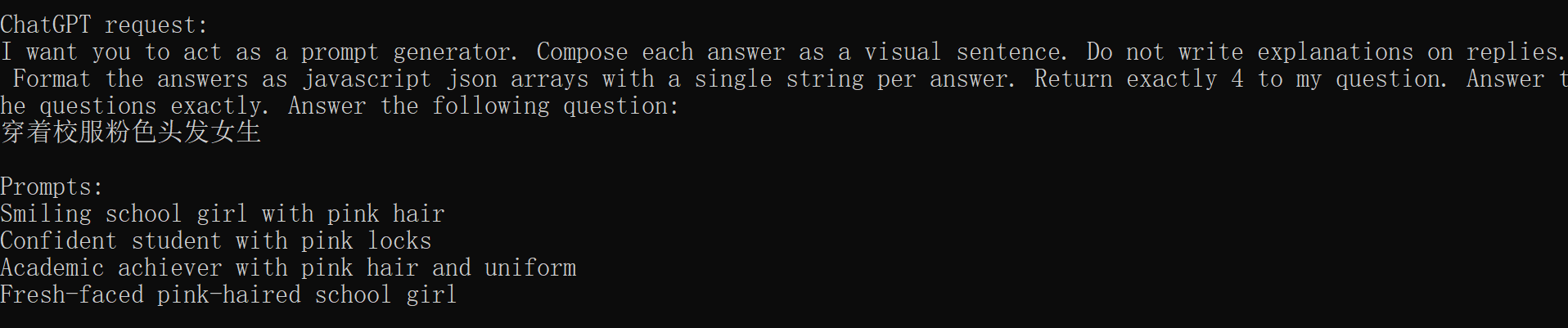
然后会生成对应的图
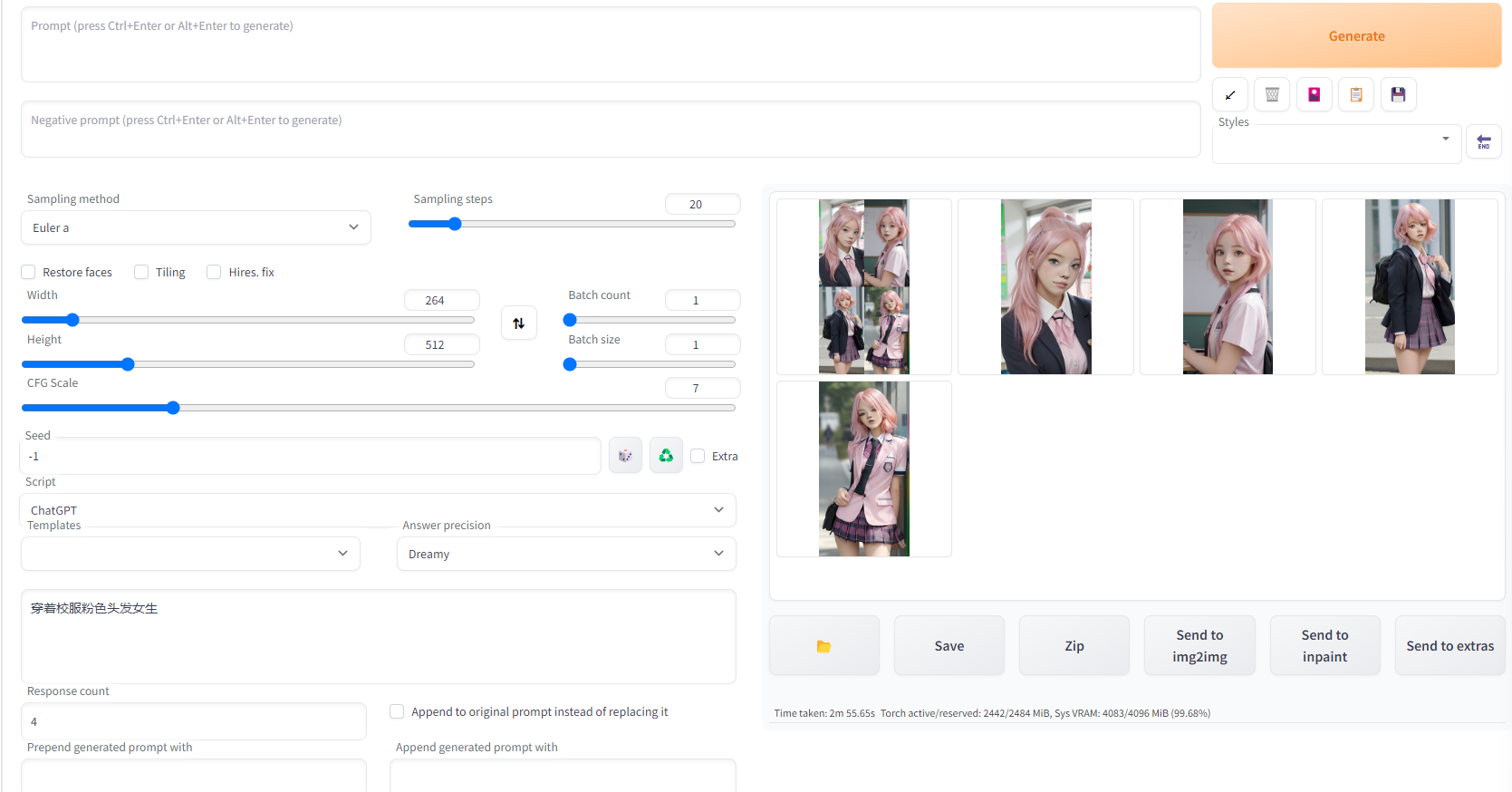
当然让chatgpt去生成prompt是比较简单的应用方式,你也可以指定部分prompt,然后进一步生成图片。比如
基于 {prompt},生成不同姿势的粉色头发美女
这种情况下,你先去搞一个比较靠谱的prompt,再自定义做修改,就不会像以前一样对超长的prompt无从下手了。当然,我试了几次之后发现,其实chatgpt不太能理解这个预设的prompt,效果没有直接描述场景更好。
生成的图有点儿崩了,这里我就打码了
在研究Stable diffusion的过程中,真的感觉现在这个东西好成熟,没想到AI革命,很多行业都还没革明白,但再设计圈已经掀起翻天波浪了。下次文章会聊聊另一个神器midjounry
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK