

阿里云大模型上新!AI神器「通义听悟」公测中:长视频一秒总结,还能自动做笔记、翻字...
source link: https://www.51cto.com/article/756433.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

阿里云大模型上新!AI神器「通义听悟」公测中:长视频一秒总结,还能自动做笔记、翻字幕
又一个接入大模型能力的组会神器实用工具,开启免费公测啦!
背后大模型,是阿里的通义千问。至于为什么说是组会神器嘛——
注意看,这是我的B站导师李沐老师,他正在带同学们精读一篇大模型论文。
不巧就在这时,老板催我抓紧搬砖。我只好默默摘下耳机,点开名为“通义听悟”的插件,然后切换页面。
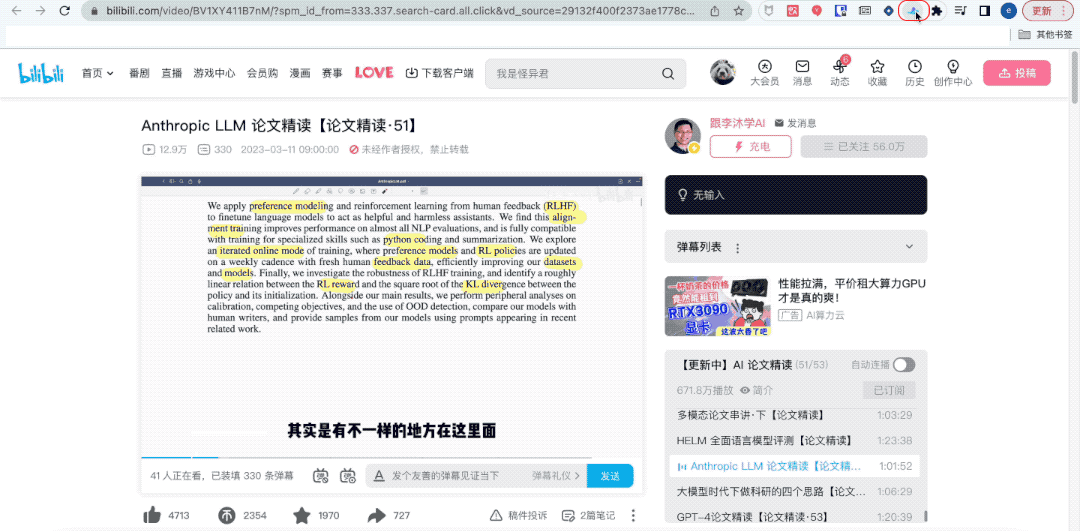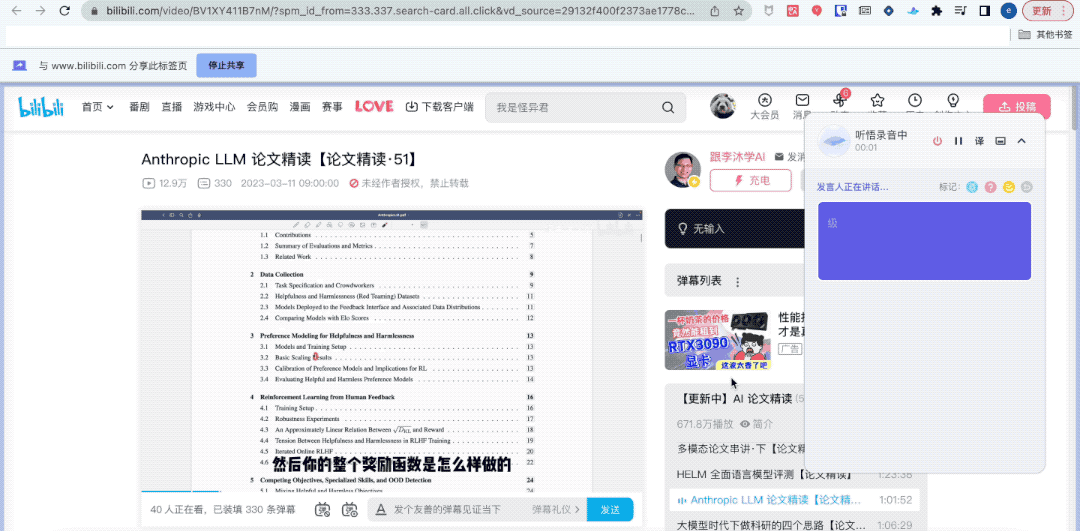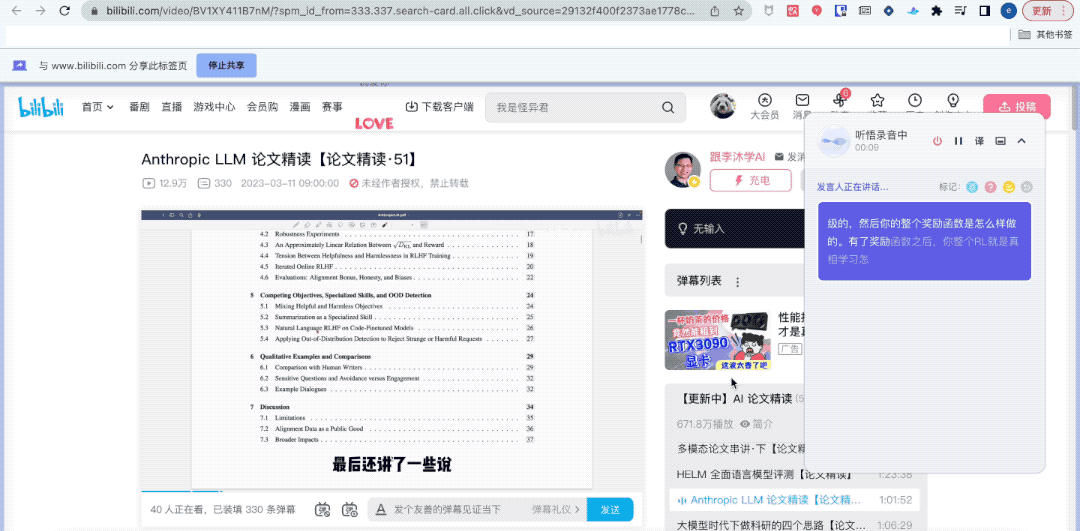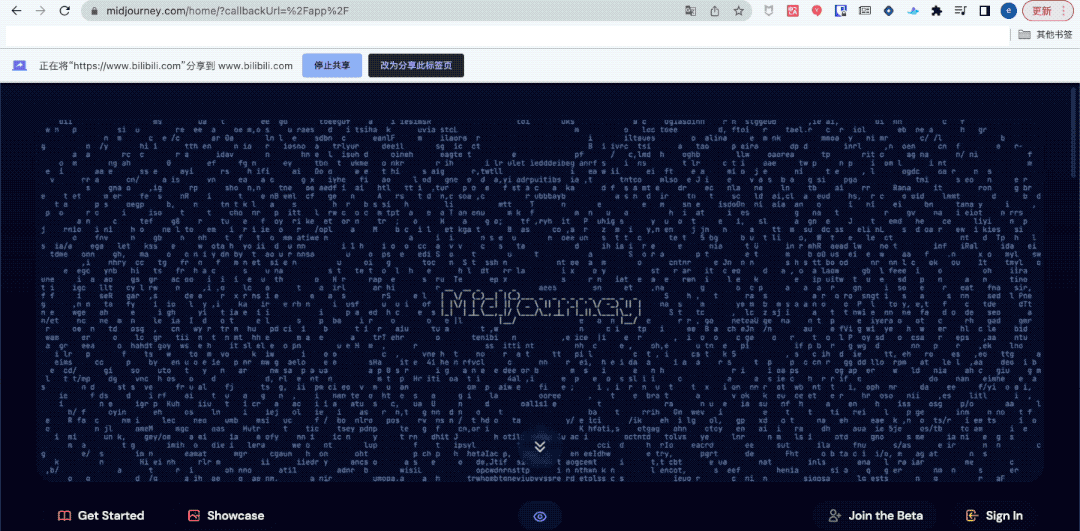
你猜怎么着?虽然我人不在“组会”现场,但听悟已经帮我完整记录下了组会内容。
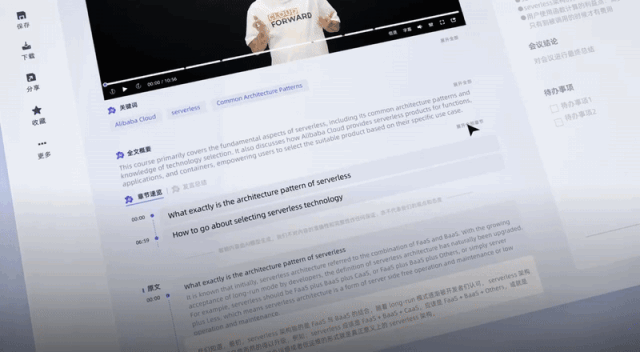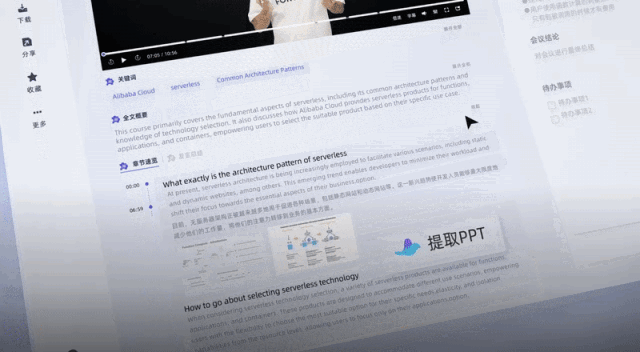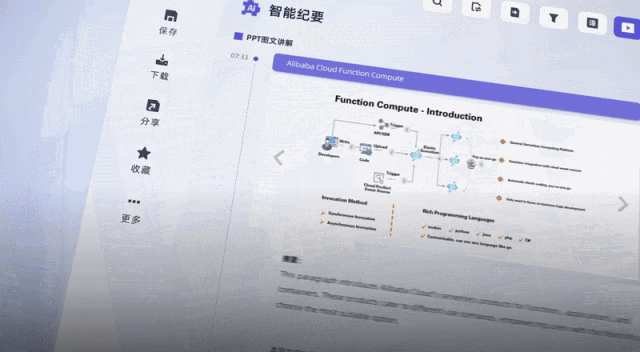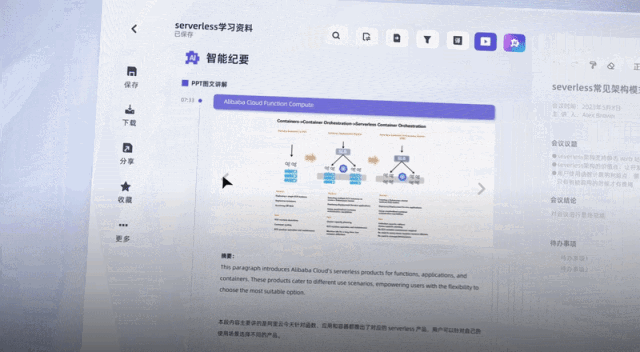
甚至还帮我一键总结出了关键词、全文摘要和学习要点。

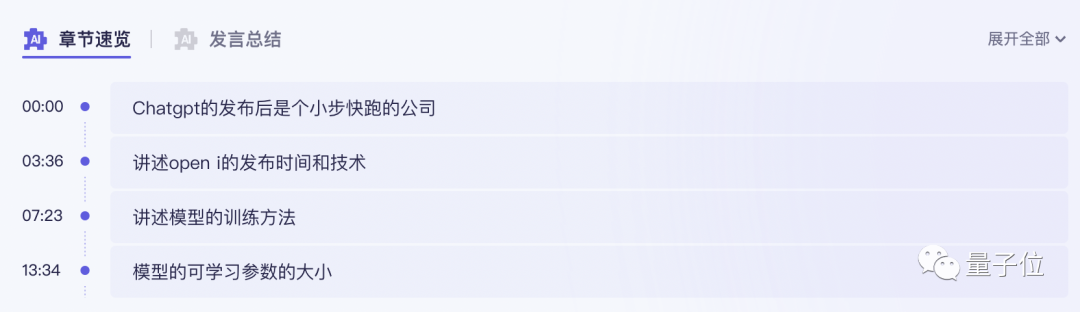
简单来说,这个刚刚接入大模型能力的“通义听悟”,是一个大模型版的聚焦音视频内容的工作学习AI助手。
跟以往的录音转写工具不同,它不只是能把录音、视频转成文字这么简单。能一键总结全文不说,总结不同发言人观点也能做到:
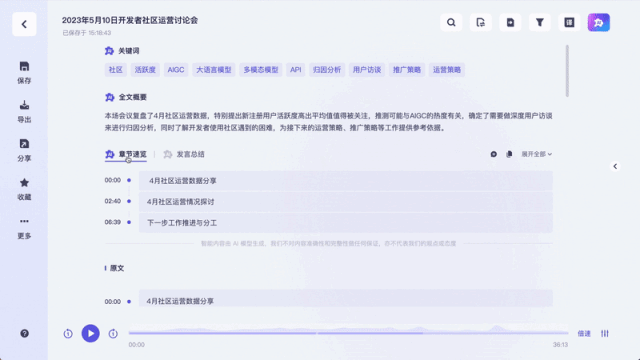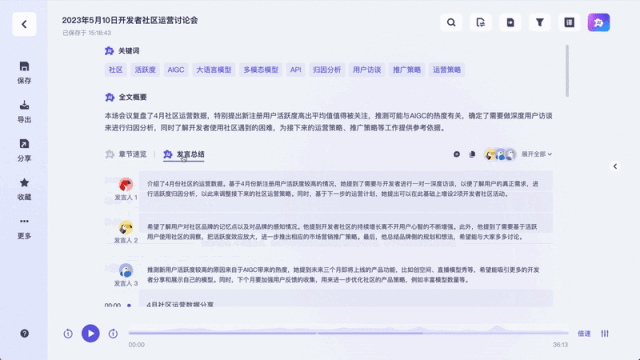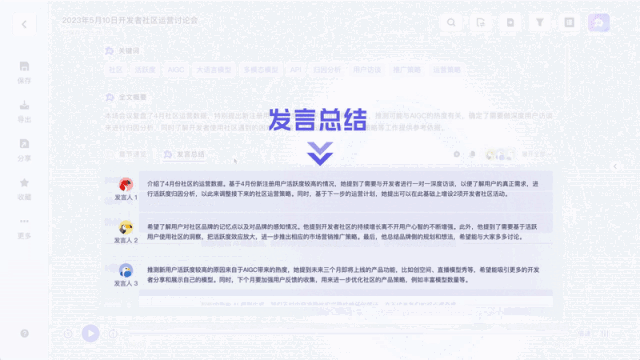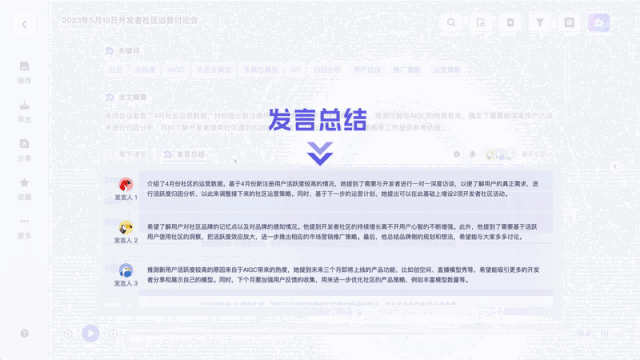
甚至还能当实时字幕翻译来用:

看上去,不仅开组会好使,对于经常要处理一大堆录音、熬夜跟各种国外发布会的量子位来说,也实属日常工作新神器。
我们赶紧第一时间深入测试了一波。
通义听悟上手实测
音频内容的整理和分析,最基础也是最重要的,就是转写的准确性。
Round 1,我们先上传一个时长在10分钟左右的中文视频,看看听悟与同类工具相比,在准确性方面表现如何。
基本上,AI处理这种中等长度音视频的速度很快,大概不到2分钟就能转写完成。

先来看看听悟的表现:

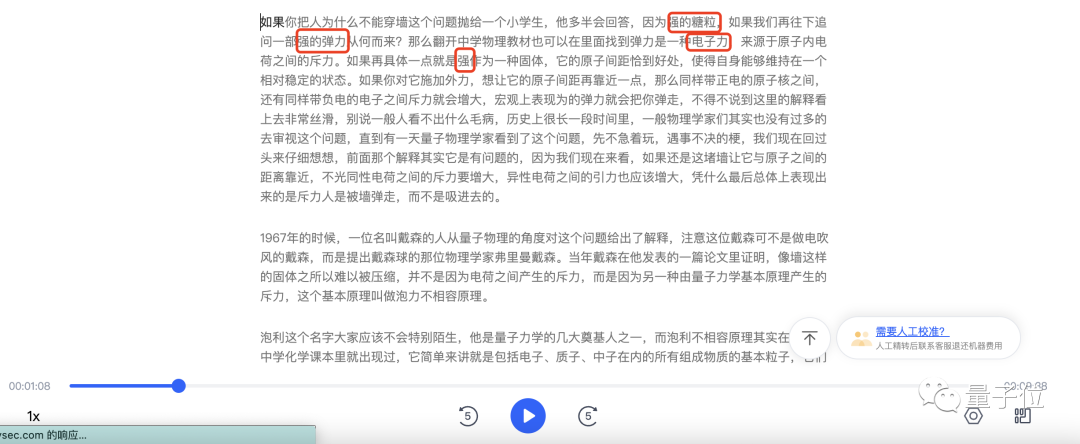
在这个200字左右的段落中,听悟只出现了两处错误:强 → 墙,都好处 → 恰到好处。像原子核、电荷、斥力这些物理名词,听悟都能弄明白。
我们用同一段视频在飞书妙记上也进行了测试。基本问题也不大,但相比听悟,飞书多了两处错误,把其中一处“原子”写成了“园子”,把“斥力”听成了“势力”。

有意思的是,听悟犯的错,飞书也一比一复刻了。看来这口锅还得量子位某说话吞字的up主来背(手动狗头)。
讯飞听见,倒是分辨出了前两位选手没有识别出来的“恰到好处”。但讯飞听见基本上把“墙”全部都转写成了“强”,还出现了“强的糖粒”这种神奇的搭配。另外,三位选手中,只有讯飞听见把“电磁力”听成了“电子力”。
总体来说,中文的识别对这些AI工具来说难度不大。那么在英文材料面前,它们又会表现如何?
我们上传了一段马斯克的最新访谈,内容是他与OpenAI过去的恩怨纠葛。
还是先来看听悟给出的结果。在马斯克的这一段回答中,听悟没有分辨出拉里·佩奇的名字,除此之外基本都能识别正确。
值得一提的是,听悟能够直接将英文转写结果翻译成中文,并将双语对照显示,翻译质量也相当不错。
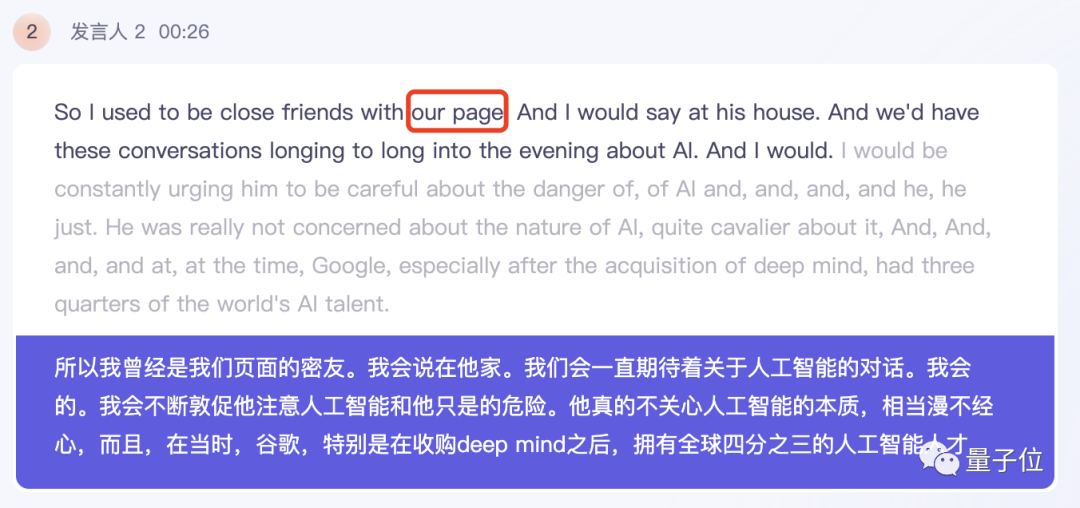
飞书妙记则成功听出了拉里·佩奇的名字,不过和听悟一样,由于马斯克整体语速较快并且有一些口语化的表达,存在一些小错误,比如把“stay at his house”写成了“say this house”。

讯飞听见这边,人名、连读细节处理得都不错,不过同样存在被马斯克的口语化表达误导的情况,比如把“long into the evening”当成了“longing to the evening”。

如此看来,在基础能力语音识别方面,AI工具们都已经达到了很高的准确率,在极高的效率面前,一些小问题已经瑕不掩瑜。
那么,我们将难度再升一级,Round 2,来测试测试它们对1小时左右长视频的总结能力。
测试视频是一段40分钟的圆桌讨论,主题是中国AIGC新机遇。参与圆桌讨论的共有5人。
听悟这边,从转写完成到AI提取关键词、给出全文摘要,一共花了不到5分钟的时间。
结果是酱婶的:


不仅给出了关键词,圆桌讨论的内容也总结得很到位,并且还给视频划分了关键点。
对比人类编辑摘录的话题要点,我嗅到了一丝危机……

值得一提的是,针对不同嘉宾的发言,听悟都能给出对应的发言总结。
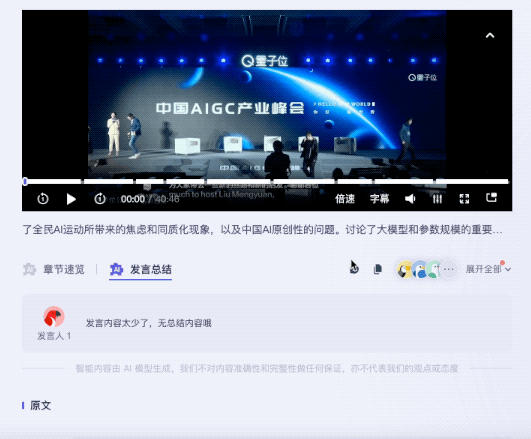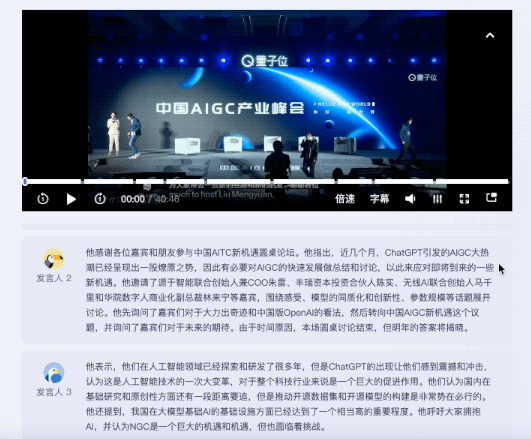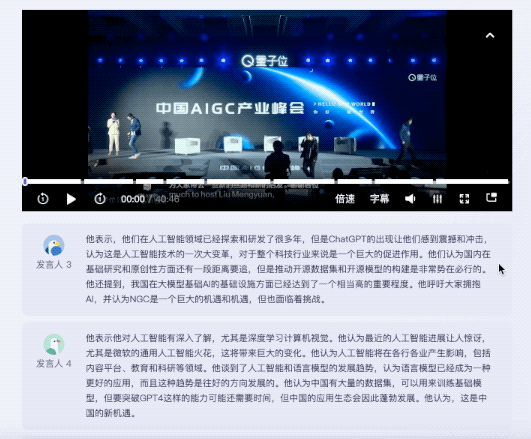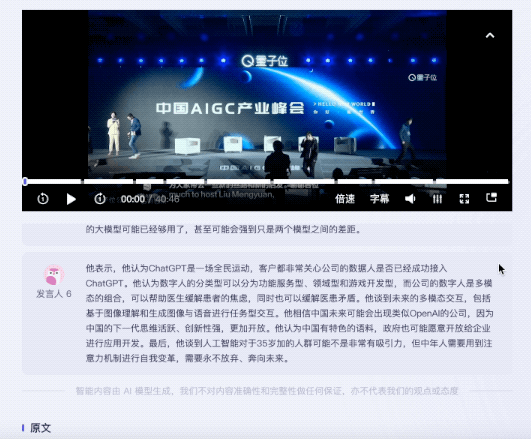
同样的题目抛给飞书妙记。目前,在内容总结方面,飞书妙记还只能给出关键词。

会议纪要需要手动在转写文字上标注。

讯飞听见基于星火认知大模型,也有能够分析文件内容的产品正在内测,不过需要填写申请,排队等待。(有内测资格的小伙伴欢迎分享体验~)
在基础的讯飞听见中,目前没有类似的总结功能。

看来这一轮测试:
不过要说在本次实测中,通义听悟最令人感觉惊喜的,其实是一个“小”设计:
Chrome插件功能。
无论是看英文视频,看直播,还是上课开会,点开听悟插件,就能实现音视频的实时转录和翻译。
就像开头所展示的那样,拿来当实时字幕用,延迟低,翻译快,还有双语对照功能,同时,录音和转写文字都能一键保存下来,方便后续使用。
妈妈再也不用担心我啃不下来英文视频资料了。
另外,我还有个大胆的想法……
开组会的时候打开听悟,开会儿小差再也不用怕被导师突然抽查了。
目前,听悟已经和阿里云盘打通,存放在云盘中的音视频内容可以一键转写,在线播放云盘视频时还能自动显示字幕。并且在企业版本中,AI整理后的音视频文件将来还可以在内部快速分享。

听悟官方还透露,接下来,听悟还会持续上新大模型能力,比如直接抽取视频内的PPT截图、针对音视频内容可以直接向AI提问……

关键是,公测福利现在人人可薅,每天登陆即可自动获得2小时转写时长,阿里云官方微博、微信及各大平台社区还会发放大量20小时转写口令码,并且时长均可叠加,一年内有效。
勤快点的羊毛大师,攒出100小时以上的免费时长不是梦(手动狗头)。

背后技术:大语言模型+语音SOTA
其实,在公测之前,通义听悟就已经在阿里内部精心打磨过了。
去年年底,也有量子位读者拿到了听悟内测体验卡,当时版本中,已经有离线语音/视频转写和实时转写的功能。
这次公测,听悟主要是接入了通义千问大模型的摘要及对话能力。具体而言,是以通义千问大模型为基座,融合了研发团队在推理、对齐和对话问答等方面的研究成果。
首先,如何准确抽取关键信息,是这类神器提升工作效率的关键。这就需要借助大模型的推理能力。
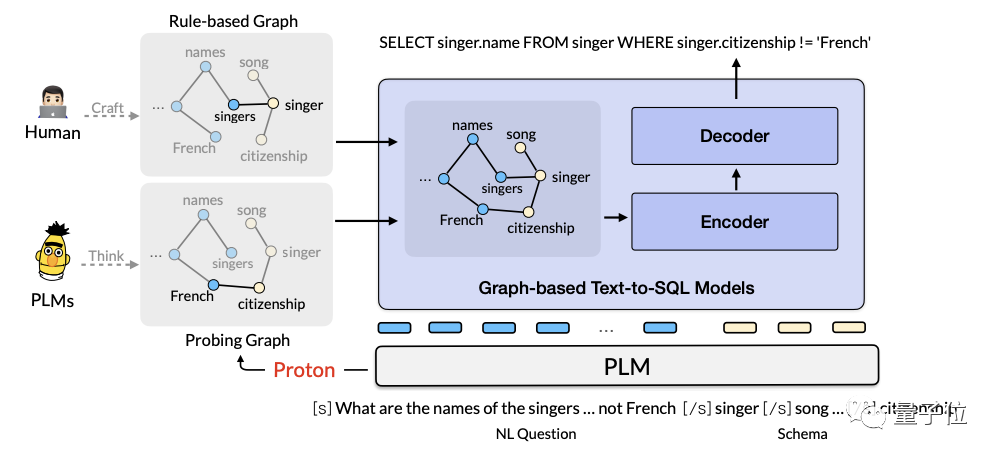
阿里AI团队在2022年提出了基于大语言模型的知识探测与推理利用框架Proton(Probing Turning from Large Language Models)。相关论文发表在KDD2022和SIGIR2023等国际顶会上。

该框架的核心思路在于,探测大模型的内部知识,以思维链为载体进行知识流动和利用。
在通用常识推理CommonsenseQA2.0、物理常识推理PIQA、数值常识推理Numbersense三大榜单上,Proton曾先后取得第一。
在TabFact(事实验证)榜单上,Proton凭借知识分解和可信思维链技术,首次实现了超越人类的效果。
其次,为了确保摘要内容和格式符合用户预期,在对齐方面,听悟还用上了ELHF,即基于人类反馈的高效对齐方法。
该方法仅需少量高质量人工反馈样本,就能实现对齐。在模型效果主观评测中,ELHF能使模型胜率提高20%。
在此之外,听悟背后的研发团队,还发布了首个中文超大规模文档对话数据集Doc2Bot。该团队提升模型问答能力的Re3G方法,已经入选ICASSP 2023:该方法通过Retrieve(检索)、Rerank(重排序)、Refine(精调)和Generate(生成)四个阶段,能提升模型对用户问题的理解、知识检索和回复生成能力,在Doc2Dial和Multi Doc2Dial两大文档对话榜单中取得第一。
除了大模型能力,听悟还是阿里语音技术的集大成者。
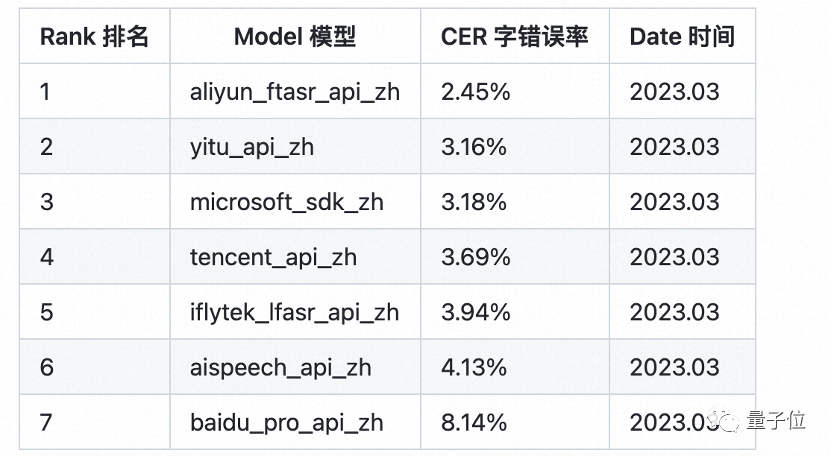
其背后的语音识别模型Paraformer,来自阿里达摩院,首次在工业级应用层面解决了端到端识别效果与效率兼顾的难题:
不仅在推理效率上较传统模型提升10倍,刚推出时还“屠榜”多个权威数据集,刷新语音识别准确率SOTA。在专业第三方全网公共云中文语音识别评测SpeechIO TIOBE白盒测试中,目前,Paraformer-large仍是准确率最高的中文语音识别模型。
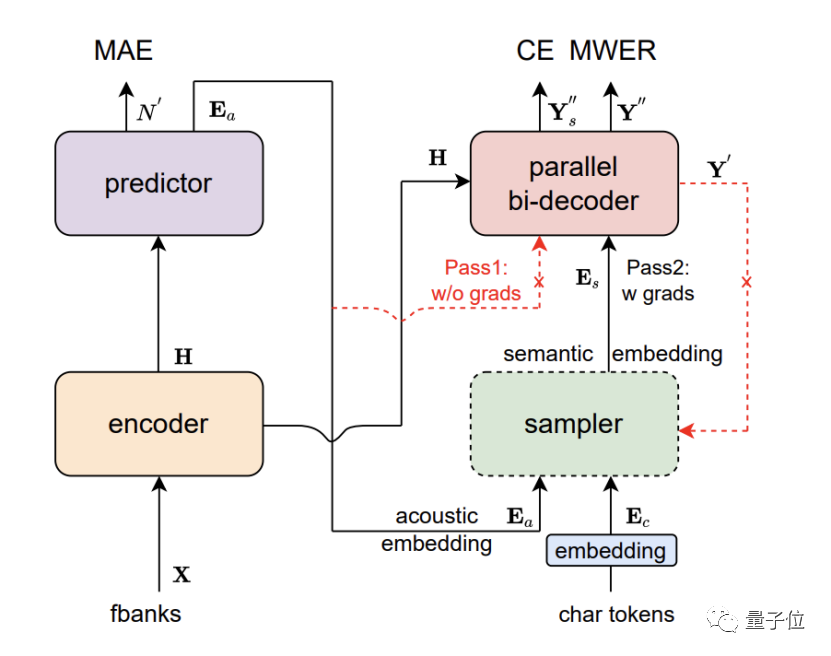
Paraformer是单轮非自回归模型,由编码器、预测器、采样器、解码器和损失函数这五个部分组成。
通过对预测器的创新设计,Paraformer实现了对目标文字个数及对应声学隐变量的精准预测。
另外,研究人员还引入了机器翻译领域中浏览语言模型(GLM)的思路,设计了基于GLM的采样器,增强了模型对上下文语义的建模。
同时,Paraformer还使用了数万小时、覆盖丰富场景的超大规模工业数据集进行训练,进一步提升了识别准确率。
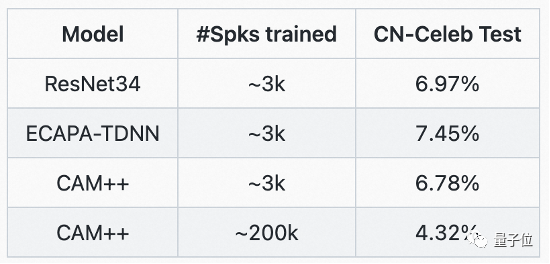
而准确的多人讨论发言人区分,则得益于达摩院的CAM++说话人识别基础模型。该模型采用基于密集型连接的时延网络D-TDNN,每一层的输入均由前面所有层的输出拼接而成,这种层级特征复用和时延网络的一维卷积,可以显著提高网络的计算效率。
在行业主流的中英文测试集VoxCeleb和CN-Celeb上,CAM++均刷新了最优准确率。
大模型开卷,用户受益
据中国科学技术信息研究所报告,据不完全统计,目前国内已经发布了79个大模型。
这种大模型开卷的趋势下,AI应用进化的速度再次进入到一个冲刺阶段。
站在用户的角度来说,喜闻乐见的局面正逐步形成:
大模型的“统筹”之下,各种AI技术开始在应用侧百花齐放,使得工具越来越高效,越来越智能。
从一个斜杠就能帮你自动写完工作计划的智能文档,到快速帮你总结要素的音视频记录和分析工具,生成式大模型这朵AGI的火花,正在让越来越多的人感受到AI的魔力。
与此同时,对于科技企业来说,新的挑战和新的机会,无疑也已经出现。
挑战是,所有产品都将被大模型的风暴席卷,技术创新已经成为了无可回避的关键问题。
机会是,对于新的杀手级应用而言,重写市场格局的时间点已经到来。而谁能拔得头筹,就要看谁的技术准备更充分,谁的技术进化速度更快了。
无论如何,技术开卷,终将是用户受益。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK