

海量数据运维要给力,GaussDB(for Cassandra)来助力 - 华为云开发者联盟
source link: https://www.cnblogs.com/huaweiyun/p/17449005.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

海量数据运维要给力,GaussDB(for Cassandra)来助力
摘要:应用运维管理平台(AOM)和Cassandra是两个不可分割的组成部分,它们共同构成了一个高效的解决方案,可以帮助企业在应用运维业务上取得巨大的优势。在这篇文章中,我们将介绍AOM和Cassandra的优势和特点,揭晓它们如何为企业保持市场竞争力的秘密。
本文分享自华为云社区《海量数据运维要给力,华为云GaussDB(for Cassandra)来助力》,作者:华为云社区精选 。
随着容器技术的普及,越来越多的企业通过微服务框架开发应用,业务逐渐转变为云上实现服务,运维也逐渐转向云上运维服务。在此环境下,云上应用的运维也遭遇了新的挑战:
- 运维人员技能要求高,需要同时维护多套系统,配置繁杂。分布式追踪系统的学习和使用成本高,稳定性差,性价比低。
- 云化场景下的分布式应用问题分析困难,主要表现在如何可视化微服务间的依赖关系,如何提高应用性能体验,如何将散落的日志进行关联分析,以及如何快速追踪问题。
针对以上挑战, AOM应运而生。
AOM是什么
AOM是由华为云研发的云上应用一站式立体化运维管理平台,由应用资源管理、监控中心(可观测性分析)、自动化运维、采集管理四个子服务构成,提供一站式可观测性分析和自动化运维方案,支持快速从云端和本地采集指标、日志和性能等数据,帮助用户及时发现故障,全面掌握应用、资源及业务的实时运行状况,提升企业海量数据运维的自动化能力和效率。
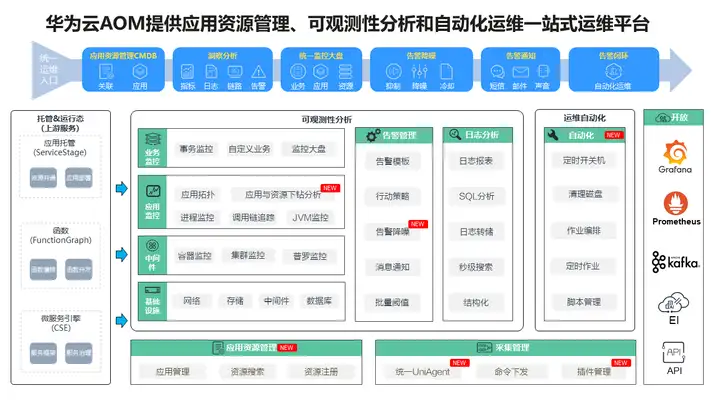
AOM优势众多,功能强大,其背后离不开支撑其海量数据运转的智能数据底座——华为云GaussDB(for Cassandra)。
为什么选择GaussDB(for Cassandra)?
华为云GaussDB(for Cassandra)是一款兼容Cassandra生态的云原生NoSQL数据库,支持类SQL语法CQL。在华为云高性能、高可用、高可靠、高安全、可弹性伸缩的基础上,提供了一键部署、快速备份恢复、计算存储独立扩容、监控告警等服务能力,尤其适用于各种海量数据处理和高并发业务场景。
- 出现数据热点的业务。例如:某新闻时事APP需要管理大量新闻时事数据,当出现社会热点事件时,相关新闻数据请求量急剧升高,此时需要保障APP正常运作,以及保持请求成功率稳定。
- 需要对时序数据建模的业务。例如:某气象站需要每分钟采集一次温度,并存储该次采集结果,同时需要保障数据的时效性,自动删除过期数据。
- 需要对会话消息数据建模的业务。例如:某社交APP需要存储大量的用户及会话消息,需要保障用户在不同会话消息间切换时耗时低、成功率高、响应时间短。
- 需要高速处理数据的业务。例如:某业务需要迅速处理来自不同设备或传感器的数据。
- 需要实时监测数据的业务。例如:某运维平台需要实时监测不同维度的数据,准确采集指标,快速完成运维。
- 需要使用社交媒体分析和推荐引擎的业务。例如:某电商APP需要分析用户喜好商品,基于用户喜好实现商品推荐,提升用户体验和产品竞争力。
此外,华为云GaussDB(for Cassandra)特性丰富,适用于广泛业务场景。
- 大数据应用:GaussDB(for Cassandra)可以处理海量数据,支持高吞吐量和低延迟的读写操作,因此适合大数据应用场景。
- 互联网应用:GaussDB(for Cassandra)可以处理高并发的读写请求,支持多数据中心部署,因此适合互联网应用场景。
- 时间序列数据:GaussDB(for Cassandra)支持时间序列数据的存储和查询,因此适合需要存储和查询时间序列数据的应用场景,如物联网、日志分析等。
- 高可用性业务。GaussDB(for Cassandra)采用多副本复制的方式来保证数据的可用性和可靠性。当一个节点出现故障时,系统可以自动将数据从其他节点中恢复,从而保证数据的完整性和一致性。
- 可伸缩性业务。GaussDB(for Cassandra)可以轻松地扩展到数百个节点,处理PB级别的数据集,同时还支持动态添加和删除节点,可以根据实际需求灵活地调整系统的规模和性能。
- 分布式存储应用。GaussDB(for Cassandra)采用分布式存储的方式,将数据分散存储在多个节点上,每个节点都可以独立地处理读写请求。这种方式可以有效地提高数据的可用性和可靠性,同时也可以提高系统的吞吐量和扩展性。
- 分布式查询应用:GaussDB(for Cassandra)支持分布式查询,可以将查询请求分发到多个节点上并行处理,从而提高查询的效率和响应速度。
综上所述,GaussDB(for Cassandra)非常适合大数据分析、实时数据处理、社交网络、物联网、分布式存储和查询等应用场景。
真实场景解读——数据热点问题
AOM功能强大,涉及多种典型业务场景,如数据热点、时序数据、实时监测等,因此选择GaussDB(for Cassandra)作为底层数据支撑引擎。接下来就数据热点问题作为切入点,揭秘GaussDB(for Cassandra)如何保障AOM在发生数据热点时稳定运行。
场景复现:
监控运维海量数据时,表中特定数据访问频率骤升,部分分区产生热点流量。表中主键设置不合理,某个分区下的业务量骤增,流量冲击会集中在一个分区上,导致该分区对应的token所在节点的CPU持续居高不下。
问题根因:
GaussDB(for Cassandra)是一个面向大数据场景的高度可扩展的高性能分布式数据库,可用于管理海量的结构化数据。在业务使用的过程中,随着业务量和数据流量的持续增长,一些业务的设计弊端逐渐暴露出来,降低了集群的稳定性和可用性。例如主键设计不合理、单个分区的记录数或数据量过大、出现超大分区键等问题,导致了节点负载不均衡、集群稳定性下降等现象,这一类问题统称为大key问题。产生大key的最主要原因是主键设计不合理,导致单个分区的记录数或数据量过大。一旦某个分区存在海量数据时,对该分区的访问会导致分区所在server的负载变高,严重时甚至会导致节点OOM等后果。
在日常生活中,经常会发生各种热门事件,例如应用中对某热点新闻进行上万次的点击浏览和评论时,会形成一个较大的请求量,这种情况下会在短时间内对同一个key频繁操作,导致该key所在节点的CPU负载飙高,从而影响该节点上的其他请求,导致业务成功率下降。诸如此类的还有热门商品促销,网红直播等场景,这些典型的读多写少的场景也会产生数据热点问题。当某个key的请求在某一主机上的访问超过server极限时,会导致热key问题的产生。大key往往是热key问题的间接原因。热key会造成以下危害:流量集中,达到物理网卡上限;请求过多,缓存分片服务被击垮;数据库击穿,引起业务雪崩等。
在上述场景中,主要是表中主键结构不合理,从而导致大key和热key的产生,表结构如下所示。movie表保存了短视频的相关信息,分区键为movieid,并且保存了用户信息(uid)。如果movieid对应的视频是一个热门短视频,有几千万甚至上亿用户点赞此短视频,则该热门短视频所在的分区非常大。
CREATE TABLE movie (
movieid text,
appid int,
uid bigint,
accessstring text,
moviename text,
access_time timestamp,
PRIMARY KEY (movieid, appid, uid, accessstring, moviename)
) 解决方案:
- 调整表结构。GaussDB(for Cassandra)与其他数据库相比,具有更加灵活的数据结构,支持主键和分区键的灵活设置,通过合理设置主键和分区键,调整表结构与查询语句,对表中数据进行划分,能够有效优化查询速度,提升运维效率。在上述场景中,movie表的主键设置不合理,查询数据量十分庞大,耗时久。创建新表为如下所示表结构时,表中数据量显著减少。新表用于保存热门短视频信息,只保留短视频公共信息,不包含用户信息,确保该表不会产生大的分区键。
CREATE TABLE hotmovieaccess (
movieid text,
appid int,
accessstring text,
access time timestamp,
PRIMARY KEY (movieid, appid)
)- 使用缓存。缓存可以提高读操作的响应性,需要使用额外的内存来存储数据,从而尽可能减少必须完成的磁盘读。随着缓存大小的增加,可以从内存提供服务的“命中”数也会增加。GaussDB(for Cassandra)内置的缓存包括键缓存和行缓存等类型。键缓存存储了分区键与行索引之间的一个映射,以便于更快地访问存储在磁盘上的SSTable;行缓存可以为每个分区缓存一定的行,提高频繁访问的行的读取速度。
在上述场景中,可以使用缓存来缓解流量冲击。业务应用先从缓存中读取热点信息,没有查询到则从数据库中查询,减少数据库查询次数。整体逻辑流程如下所示。
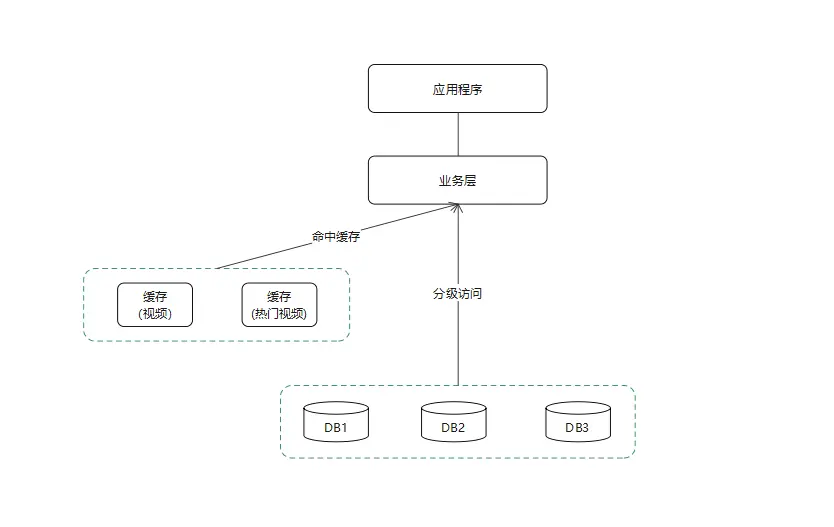
数据热点检测工具:
数据热点会给业务带来压力,影响业务正常运行。出现数据热点后再去解决为时已晚,因此需要预知数据热点问题,提前设计解决方法,保证业务正常运行。为此,GaussDB(for Cassandra)为业务提供了大key和热key的检测和预警工具。
- 大key检测。通过大规模业务观察学习,GaussDB(for Cassandra)定义超过以下任意阈值的key即为大key:1. 单个分区键的行数不能超过10万行;2. 单个分区的大小不超过100MB。
- 热key检测。通过大规模业务观察学习,GaussDB(for Cassandra)定义访问频率大于100000次/min的key即为热key。
GaussDB(for Cassandra)支持大key和热key的检测和告警工具,客户可根据实际业务需求,在产品界面配置实例的大key和热key告警。同时,在发生大key和热key事件时,系统会第一时间发送预警通知,客户可在产品界面查看监控事件数据,及时处理相关告警,避免业务波动。
针对数据热点问题,GaussDB(for Cassandra) 提供了大key和热key的实时检测,以帮助业务进行合理的方案设计,规避业务稳定性风险;提供了大key和热key的实时监控,确保第一时间感知业务风险;提供了大key和热key的解决方案,在面对大数据量洪峰场景时,增强了集群的稳定性与可用性,为客户业务持续稳定运行保驾护航。
综上所述,在线业务在使用GaussDB(for Cassandra)时,必须执行相关的开发规则和使用规范,在开发设计阶段就降低使用风险。一般按照“制定规范”→“接入评审”→“定期巡检”→“优化规则”的治理流程进行。合理的设计一般会降低大部分风险发生的概率,对于业务来说,任何表的设计都要考虑是否会导致大key和热key的产生、是否会造成负载倾斜的问题。另外需要建立数据老化机制,表中的数据不能无限制的增长而不删除或者老化。针对读多写少的场景,要增加缓存机制,来应对读热点问题,提升查询性能;针对每个分区键以及每行数据,要控制其大小,超出限制后要及时优化,否则将影响性能和稳定性。
AOM和GaussDB(for Cassandra)的组合成功打造了一套高效、可扩展、高性能、灵活和可定制的海量数据监控运维平台,可以帮助企业更好地管理和利用监控数据,提高运维效率,助力企业在不断变化的市场环境中保持竞争优势。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK