

强化学习在长时间运行系统中的限制
source link: http://guileen.github.io/2020/04/05/limitation-of-rl-in-long-term/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

强化学习在长时间运行系统中的限制
近日尝试使用强化学习解决8x8大小的2048游戏。游戏环境是一个8x8的方格,环境每回合随机生成2个方块,方块的值为2或4,AI的决策空间是上、下、左、右四个操作,所有方块都将向所指示的方向堆叠,如果两个相邻的值相同方块在堆叠方向挤压,则这两个方块合并为1个方块,值是两个方块值的和。如果任何方向都无法移动方块,则游戏结束。游戏的目标是尽可能久的玩下去,合并出最大的方块。
最初我尝试用PG来训练这个看似简单的游戏。每一步,都视为1点奖励,如果失败则给予-1000惩罚。算法很快习得了一个偷懒的方法,每一步都进行无效的移动,以此来苟延残喘。于是将无效的移动操作,视为重大的失误,也同样给予-1000的惩罚。算法很快学会了在一个局面下的有效移动操作。但这个游戏,哪怕只是随机的移动也能够取得一个普通的结果,如果要突破极限,则需要使用一些特殊的策略,我期待算法是否能在训练中学会这些策略。

对于这个游戏,达到2048,需要大约500次移动,达到4096,则需要1000,达到1M,也就大约需要20多万次移动,达到4M,则需要上百万次移动。每到达一个新的难度,面临的局面都不同,之前所习得的经验就不一定继续有效了。2048游戏是一个比围棋要简单很多的游戏,围棋拥有更多的选点,2048只有4个操作选择。他们的主要区别在于围棋一般在100多手内结束,而2048的游戏时间则近乎无限长。理想的游戏结果如下图所示:
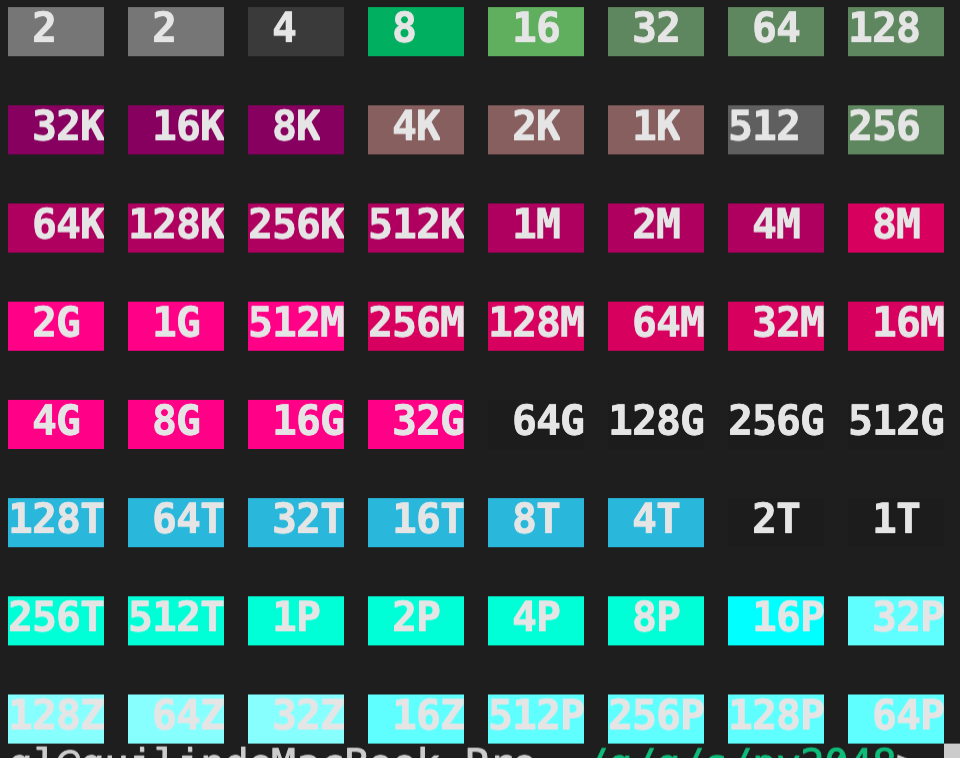
这一游戏是存在理想玩法的,经过很多局的游戏,我已总结出一些经验。但是这些经验是感性的,很难使用逻辑规则表达出来,很多时候是凭直觉的。我手段操作达到了512K的结果,虽然我依然可以挑战更高的游戏记录,但显然我不能将如此多的时间浪费在滑动手指上。这也是我要编程解决这个问题的初衷,但是强化学习算法,只能在一次次的失败中得到教训,可是这个游戏的特点是,训练的越好,游戏时间越长,获得失败经验的成本就越大。所以无论该算法在理论上是多么的正确,但在实际操作过程中已经变得不可行了。
DQN、PG等强化学习算法的基本过程是根据系统给予的奖励,努力最大化收益。但是对于一个没有明确获胜终点的系统,如果验证训练结果的有效性却是一个非常大的问题。由于强化学习本质上是通过过往的经验来调整自己的策略的,如果有明显的获胜路径,则算法可以有充分的胜利经验可供借鉴。但如果目标是永远安全的运行下去,没有获胜的路径,只有失败的惩罚,那么算法只能在有限的教训中得到学习。假设我们正在训练一个自动飞行系统,获取每一个经验教训的成本都非常巨大,强化学习在这一方面的应用,必须要搭配一些人类的理性评估作为辅助,但是将人类的意识转化为可以实施的程序逻辑又是非常复杂的事情。
如果我们训练的是一个自动驾驶系统呢?在未来无人驾驶会应用的越来越多。无人驾驶的安全性会很快超越人类,随即人们期望可以进一步提升驾驶的平均速度或其他一些智能驾驶的指标。因为无人驾驶的安全性已经超越了人类,所以无法再依赖于人类的驾驶经验给予其帮助,只能依赖于自身驾驶中的经验(尤其是事故)作为训练依据。那么这时这个系统还可能是安全的吗?
在未来的相关强化学习领域,一个好的环境模拟系统、事故全息信息的采集和共享系统,才是提升人工智能的关键,而不是算法。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK