

谷歌内部文件泄露:大模型已被开源社区「偷家」,不改变ChatGPT也会黯然失色
source link: https://www.qbitai.com/2023/05/51450.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

谷歌内部文件泄露:大模型已被开源社区「偷家」,不改变ChatGPT也会黯然失色

“我们和OpenAI都没有护城河”
鱼羊 编辑整理
量子位 | 公众号 QbitAI
在这场大模型军备竞赛中,我们没有护城河,OpenAI也没有。
一份谷歌内部“泄密文件”,正在网上一石激起千层浪。


全文挺长,但核心观点十分明确:开源大模型迅猛发展,正在侵蚀OpenAI和谷歌的阵地。
并且,“除非改变闭源的立场,否则开源替代品将最终使它们(包括ChatGPT)黯然失色”。
如此观点一出,立刻吸引了不少业内人士的关注。
Django框架的作者之一Simon Willison就转发点赞,“这是最近我了解到的有关LLM最有趣的事”、“绝对值得一读”。

据彭博社消息,文章原作者是谷歌高级软件工程师Luke Sernau,而其“内部文件”的真实性,也很快得到证实。

话不多说,一起来看具体内容。
- 与开源大模型相比,谷歌在大模型质量方面仍有优势,但差距正在以惊人的速度缩小。
- 大语言模型是否会因开源迎来“Stable Diffusion时刻”还有待观察,但其发展与图像生成领域具有相同要素。
- LoRA(低秩适应)在谷歌内部被低估了。
- 巨型模型正在使我们减速。从长远角度看,最好的模型是那些可以快速迭代的模型。
- 数据质量比数据规模更重要。
- 直接与开源竞争是不明智的。
(以下为原文分享,经编辑)
谷歌&OpenAI没有护城河
谁将跨越大模型的下一个里程碑?令人不安的事实是,我们(谷歌)无法取得这场军备竞赛的胜利,OpenAI同样不能——
就在两边激烈竞争之时,第三方势力一直在悄悄侵蚀我们的阵地。

这个“第三方”,就是开源。现在,一些“主要开源问题”已经被解决,举几个例子:
- LLM(大语言模型)已经能在手机上运行:比如在Pixel 6上,可以以每秒5 token的速度运行基础模型。
- 可扩展的个人AI:人们可以在笔记本电脑上微调出个性化AI。
- 负责任的发布:尽管没有完全解决,但图像生成领域和文本生成领域都已经取得了很大进展,网上有许多无限制资源。
- 多模态:当前多模态ScienceQA的SOTA模型,1小时内就能完成训练。
虽然我们的模型在质量方面仍有优势,但差距正在以惊人的速度缩小。
开源模型更快、更可定制、更私密且功能更强大。关键是,开源力量在用100美元和130亿参数创造大模型,而我们在1000万美元和5400亿参数下苦苦挣扎。他们仅用几周,而非几个月就能完成大模型的训练。
这对我们产生了深远的影响:
- 我们没有秘密武器。我们最大的希望是学习谷歌之外其他人正在做的事,并与之合作。我们应该优先考虑实现第三方集成。
- 当免费、无限制的替代品在质量上有所突破,人们将不会为受限制的模型付费。我们应该思考我们真正的价值是什么。
- 巨型模型正在拖慢我们的速度。从长远来看,最好的模型是那些可以快速迭代的模型。既然我们知道在<200亿的参数范围内,模型有什么可能性,我们就应该更多地关注模型的小型变体。
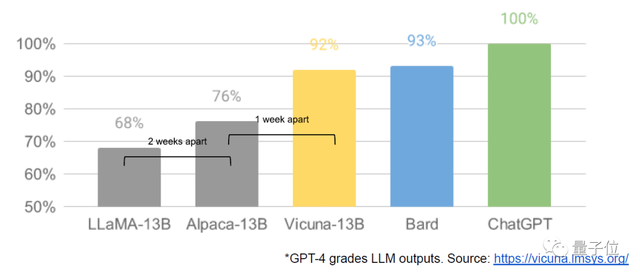
大语言模型的Stable Diffusion时刻
今年三月初,Meta的大语言模型LLaMA被泄露,开源社区得到了第一个真正有实力的基础模型。

随即,“羊驼”家族疯狂涌现,每隔几天就有新的进展发生。
仅仅一个月,指令调优(instruction tuning)、量化、质量改进、人类评估、多模态、RLHF……就都出现了。
最重要的是,开源社区解决了扩展问题,使得人人都能参与其中亲自尝试。许多新想法都来自普通人。训练和实验的门槛,已经从一个大型研究机构的总产出,降低到了一个人、一晚上和一台高性能笔记本电脑。
很多人认为这是大语言模型(LLM)的“Stable Diffusion时刻”。
在图像生成和LLM领域,低成本的公共参与都是通过LoRA(低秩适应)实现的,同时还有规模上的重大突破(比如图像合成的latent diffusion、LLM的Chinchilla)。
结果就是,质量足够高的模型吸引来了全世界的人才和机构,围绕开源大模型产生的新想法和迭代,很快超过了大型企业。

在图像领域,这些贡献已经证明其价值:开源使Stable Diffusion走上了与DALL-E完全不同的道路,激发了DALL-E所没有的产品集成、市场、用户界面等等创新。
Stable Diffusion也因此出圈,产生了远超DALL-E的文化影响力。
在LLM领域,同样的事情是否会再次发生还有待观察,但基本要素是相同的。
谷歌忽略了什么
最近,开源所取得的创新成果直接解决了我们仍在努力克服的问题。更多关注开源工作,可以帮助我们避免重复造轮子。
其中,LoRA是一种非常强大的技术,我们应该加大关注。
LoRA通过低秩分解来表示模型权重的更新,这可以大大缩减更新矩阵的大小,使得模型微调的成本更低、时间更短。

在消费级硬件上,花几个小时微调出一个个性化语言模型,这是一项重要的突破。但这项技术在谷歌内部被低估了,尽管它直接影响了我们最雄心勃勃的几个项目。
另外,从头开始训练模型是一条艰难的道路。
LoRA如此有效的部分原因在于:和其他形式的微调一样,它是可堆叠的。虽然单独的微调是低秩的,但它们的总和不需要,模型的全秩更新可以随时间推移而累积。
这意味着,随着更好的数据集和任务的出现,模型可以低成本保持最新状态,而无需负担完整运行的成本。
相比之下,从头训练大模型不仅会丢掉预训练,还会丢失已经完成的迭代改进。在开源世界,这些改进会使模型很快占据主导地位,这就使得从头重新训练显得极为昂贵。
我们应该思考,新应用、新想法是否真的需要一个全新的模型来实现。如果我们确实有重大的架构改进,使得原有的模型权重无法复用,那么我们应该专注于更积极的蒸馏方法,尽可能地保留上一代的功能。
维护大模型使谷歌处于劣势
在最流行的模型规模上,LoRA的成本非常低(约100美元)。这意味着几乎每一个对大模型有想法的人,都可以把这些想法落到现实。
短至一天的训练时间已是常态。
以这样的速度,所有这些微调所产生的累积效应,很快就会弥补模型规模带来的劣势。
事实上,就工程师的工时而言,这些模型的改进速度大大超过了我们的大模型所能做的,其中最好已经跟ChatGPT几乎没有区别了。
专注于维护地球上一些最大的模型,实际上使我们处于劣势。
此外,数据质量比数据规模更重要。
直接与开源竞争是一种失败的主张
开源大模型最近的进展对我们的业务战略有直接的影响。如果有免费、高质量的替代方案,谁会为谷歌有限制的付费产品买单呢?
我们也不应指望能够赶上。现代互联网在开源的基础上运行是有原因的。开源有一些我们无法复制的显著优势。
我们需要开源,胜过开源社区需要我们。
对我们的技术保密其实是一个脆弱的主张。每过一段时间,都会有谷歌的研究人员离职去往其他公司。所以我们可以假定,他们了解我们所知道的一切。
但是,由于大语言模型的负担成本正在降低,保持技术优势会变得更加困难。
世界各地的研究机构都在相互借鉴,以一种比我们自身能力更广的方式探索解决方案。在这种外部创新不断挑战我们技术价值的情况下,我们可以选择紧守我们的秘密,或者尝试相互学习。
现在,开源大模型的很多创新,都是源于Meta LLaMA模型的泄露。但Meta又成为这一进程中一个明显的赢家——他们相当于获得了整个星球的免费劳动力。由于大多数开源创新都基于他们的架构,因此没有什么能阻止他们将这些迭代进化整合到他们的产品中。
拥有生态系统的价值怎么强调都不为过。谷歌本身已在开源产品,如Chrome和Android中,成功验证了这一点。通过拥有孵化创新的平台,谷歌巩固了自己作为意见领袖和方向制定者的地位,获得了塑造比自身更宏大的想法的能力。

△Midjourney生成
我们对模型的控制越严密,开源替代方案的吸引力就越大。谷歌和OpenAI都倾向于防御性的发布模式,以确保他们能严格控制模型的使用方式。但这是徒劳的,任何想将LLM用于未经批准目的的人,都可以选择免费的开源模型。
谷歌应该让自己成为开源社区的领导者,通过更广泛的合作对话,而非忽视来起到带头作用。
这必然意味着放弃对我们模型的一些控制。但这种妥协是不可避免的。我们不能既希望推动创新,又要控制创新。

考虑到OpenAI当前的封闭策略,有人会觉得这些关于开源的讨论不公平。但事实是,我们已经通过挖对方墙脚的形式,与他们分享了一切。在这种趋势被扼制之前,保密是一个有争议的问题。
最后,OpenAI并不重要。在对于开源的态度上,他们犯了与我们相同的错误。他们保持优势的能力必然受到质疑。除非他们改变立场,否则开源替代品可以并最终将使其黯然失色。
至少在这方面,我们可以迈出第一步。
如何定义“护城河”
据彭博社消息,这篇文章是谷歌高级软件工程师Luke Sernau四月初在谷歌内网发布的。在被泄露之前,已经在谷歌内部被大量转发。
而原文一经流出,也引起了网友们的热烈讨论。
不过,也有不少网友并不认同Sernau的观点。
任何用过GPT-4的人都知道,开源模型与之相距甚远,甚至比不上GPT-3.5。OpenAI肯定有护城河,至少目前是这样。我不确定谷歌有没有,Bard反正是挺让人失望的。

有网友认为,Sernau关于与开源社区合作可以让模型更快改进的观点值得认同。但其实无论是开源还是闭源,改进得快的那一方都将获胜。
Midjourney目前比Stable Diffusion更受欢迎,因为它目前更好。但Midjourney是闭源的。
我想说的是,用户会盯紧最好的模型。开源并不总能获胜。

还有网友直接用一张图回怼:
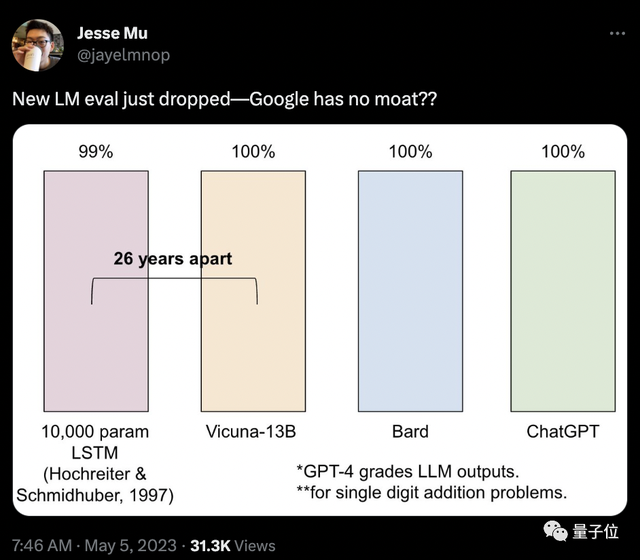
但无论如何,“开源模型每周都在变得更好”。
而有关大模型的精彩故事,才刚刚开篇。
参考链接:
[1]https://www.semianalysis.com/p/google-we-have-no-moat-and-neither
[2]https://www.bloomberg.com/news/articles/2023-05-05/google-staffer-claims-in-leaked-ai-warning-we-have-no-secret-sauce
[3]https://news.ycombinator.com/item?id=35813322
[4]https://twitter.com/simonw/status/1654158105221922816
[5]https://www.reddit.com/r/MachineLearning/comments/137rxgw/d_google_we_have_no_moat_and_neither_does_openai/
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK