

Protocol Overview | AT Protocol
source link: https://atproto.com/guides/overview
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Protocol Overview#
The Authenticated Transfer Protocol, aka ATP, is a protocol for large-scale distributed social applications. This document will introduce you to the ideas behind the AT Protocol.
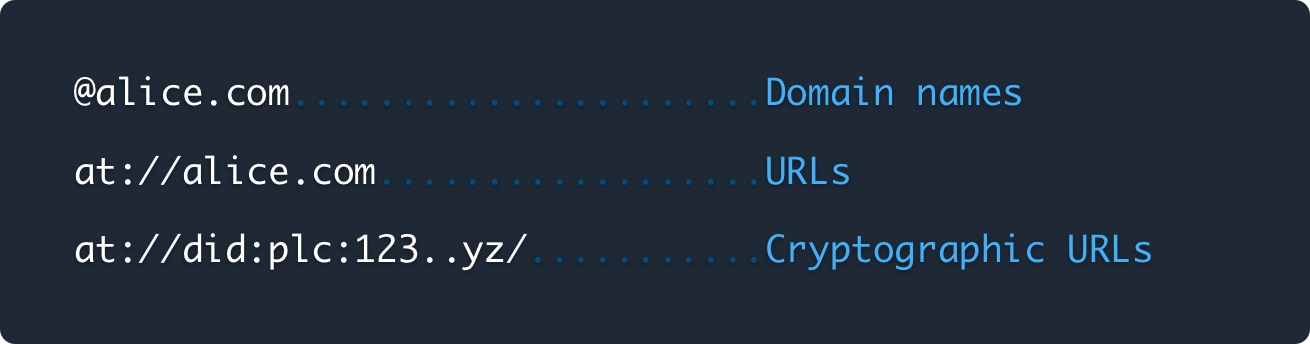
Identity#
Users are identified by domain names in AT Protocol. These domains map to cryptographic URLs which secure the user's account and its data.
Data repositories#
User data is exchanged in signed data repositories. These repositories are collections of records which include posts, comments, likes, follows, media blobs, etc.

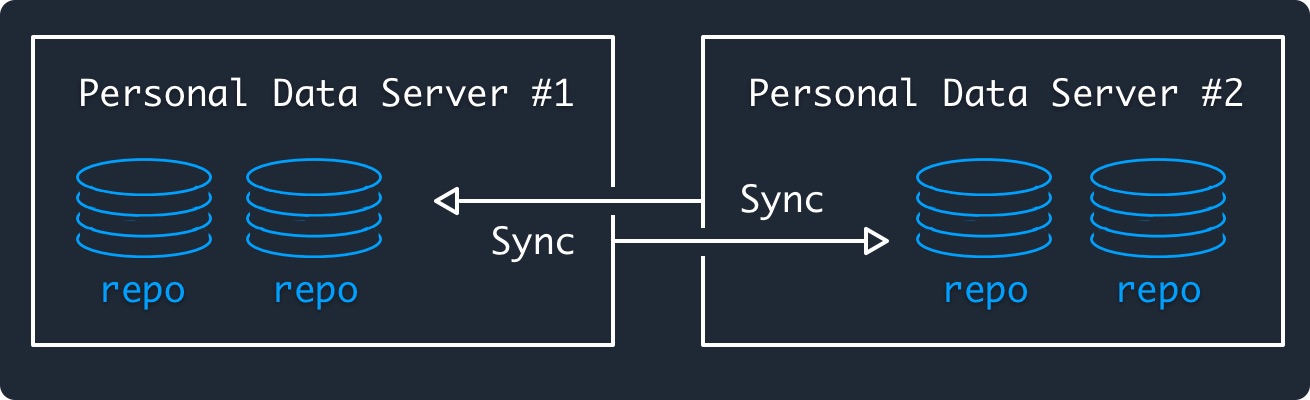
Federation#
ATP syncs the repositories in a federated networking model. Federation was chosen to ensure the network is convenient to use and reliably available. Commands are sent between servers using HTTPS + XRPC.
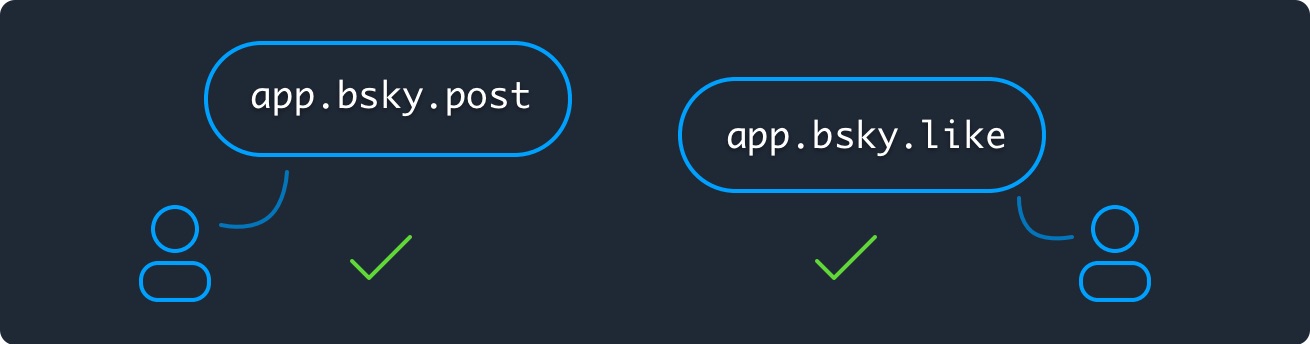
Interoperation#
A global schemas network called Lexicon is used to unify the names and behaviors of the calls across the servers. Servers implement "lexicons" to support featuresets, including the core ATP Lexicon for syncing user repositories and the Bsky Lexicon to provide basic social behaviors.
While the Web exchanges documents, the AT Protocol exchanges schematic and semantic information, enabling the software from different orgs to understand each others' data. This gives ATP clients freedom to produce user interfaces independently of the servers, and removes the need to exchange rendering code (HTML/JS/CSS) while browsing content.
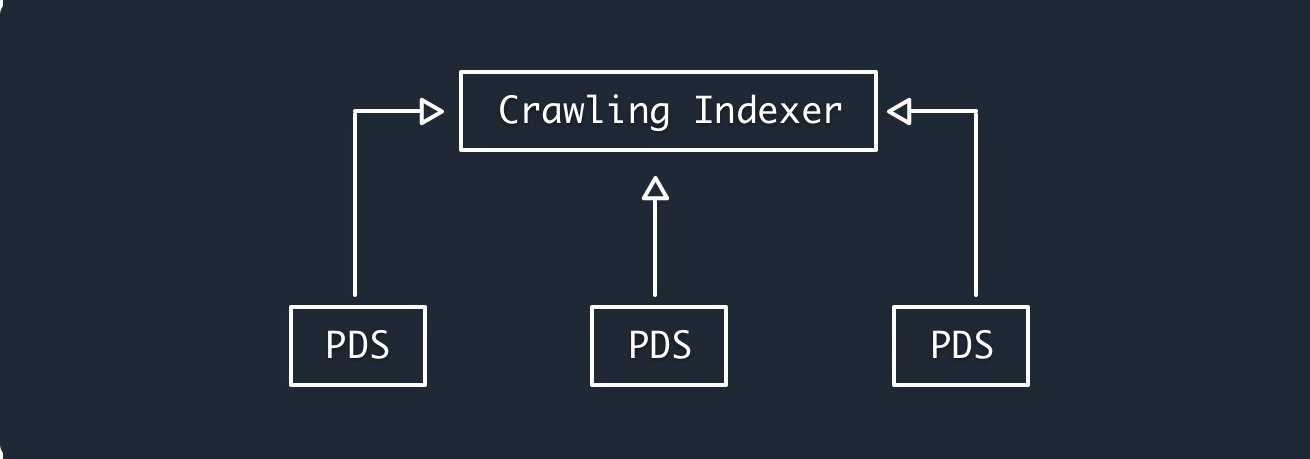
Achieving scale#
ATP distinguishes between "small-world" vs "big-world" networking. Small-world networking encompasses inter-personal activity while big-world networking aggregates activity outside of the user's personal interactions.
- Small-world: delivery of events targeted at specific users such as mentions, replies, and DMs, and sync of datasets according to follow graphs.
- Big-world: large-scale metrics (likes, reposts, followers), content discovery (algorithms), and user search.
Personal Data Servers (PDS) are responsible for small-world networking while indexing services separately crawl the network to provide big-world networking.
The small-world/big-world distinction is intended to achieve scale as well as a high degree of user-choice.
Algorithmic choice#
As with Web search engines, users are free to select their indexers. Each feed, discovery section, or search interface is integrated into the PDS while being served from a third party service.

Account portability#
We assume that a Personal Data Server may fail at any time, either by going offline in its entirety, or by ceasing service for specific users. ATP's goal is to ensure that a user can migrate their account to a new PDS without the server's involvement.
User data is stored in signed data repositories and verified by DIDs. DIDs are essentially registries of user certificates, similar in some ways to the TLS certificate system. They are expected to be secure, reliable, and independent of the users' PDS.
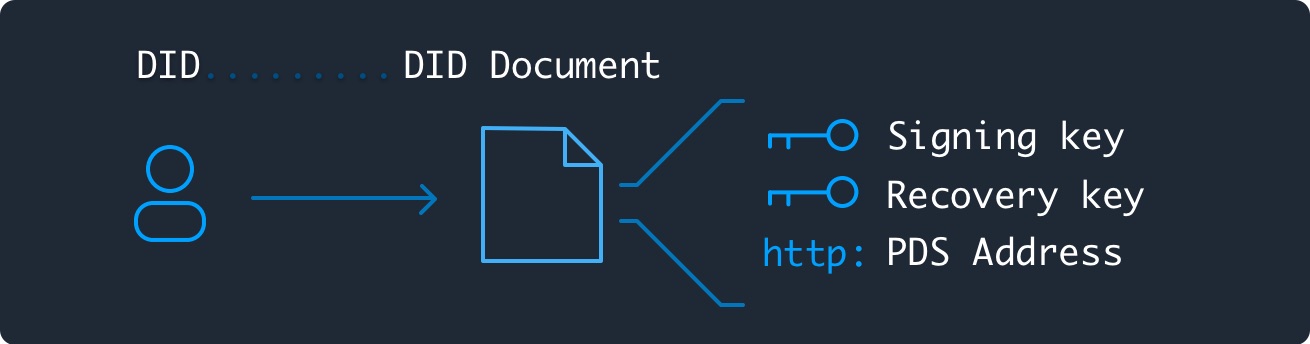
Each DID Document publishes two public keys: a signing key and a recovery key.
- Signing key: Asserts changes to the DID Document and to the user's data repository.
- Recovery key: Asserts changes to the DID Document; may override the signing key within a 72-hour window.
The signing key is entrusted to the PDS so that it can manage the user's data, but the recovery key is saved by the user, e.g. as a paper key. This makes it possible for the user to update their account to a new PDS without the original host's help.

A backup of the user’s data is persistently synced to their client as a backup (contingent on the disk space available). Should a PDS disappear without notice, the user should be able to migrate to a new provider by updating their DID Document and uploading the backup.
Speech, reach, and moderation#
ATP's model is that speech and reach should be two separate layers, built to work with each other. The “speech” layer should remain neutral, distributing authority and designed to ensure everyone has a voice. The “reach” layer lives on top, built for flexibility and designed to scale.
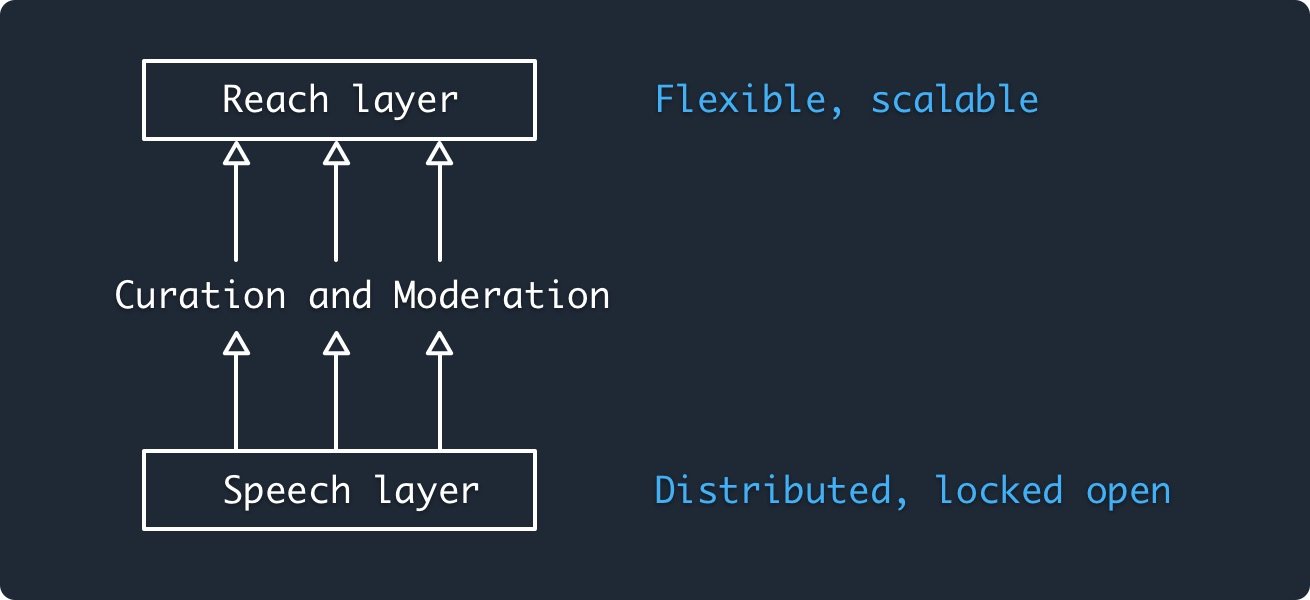
The base layer of ATP (Personal Data Repositories and Federated Networking) creates a common space for speech where everyone is free to participate, analogous to the Web where anyone can put up a website. The Indexing services then enable reach by aggregating content from the network, analogous to a search engine.
Specifications#
Five primary specs comprise the v1 of the @-protocol. These specs are:
These specs can be organized into three layers of dependency:

From here you can continue reading the guides and specs.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK