

译|llustrated Guide to Monitoring and Tuning the Linux Networking Stack: Receiv...
source link: https://www.cyningsun.com/04-26-2023/illustrated-guide-to-monitoring-and-tuning-the-Linux-networking-stack-recv-cn.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

TL;DR
本文是对我们之前的文章监控和调优 Linux 网络堆栈:接收数据的扩展,其中包含了一系列旨在帮助读者更清晰地了解 Linux 网络堆栈工作原理的图表。
在监控或调优 Linux 网络堆栈时,没有捷径可走。运维人员必须努力全面了解各个系统及其相互作用,才有可能对它们进行调优。也就是说,之前博客文章的长度可能使读者难以概念化各个系统如何相互作用。希望这篇博客文章能够帮助澄清这一点。
Getting Start
这些图表旨在概述 Linux 网络堆栈的工作原理。因此,许多细节被省略了。为了获得完整的画面,建议读者阅读我们的博客文章,其中详细介绍了网络堆栈的各个方面:监控和调优 Linux 网络堆栈:接收数据。这些图的目的是帮助读者形成一个心智模型,了解内核中的一些系统如何在高层次上相互交互。
让我们首先看一下在理解数据包处理之前必要的一些重要初始设置。
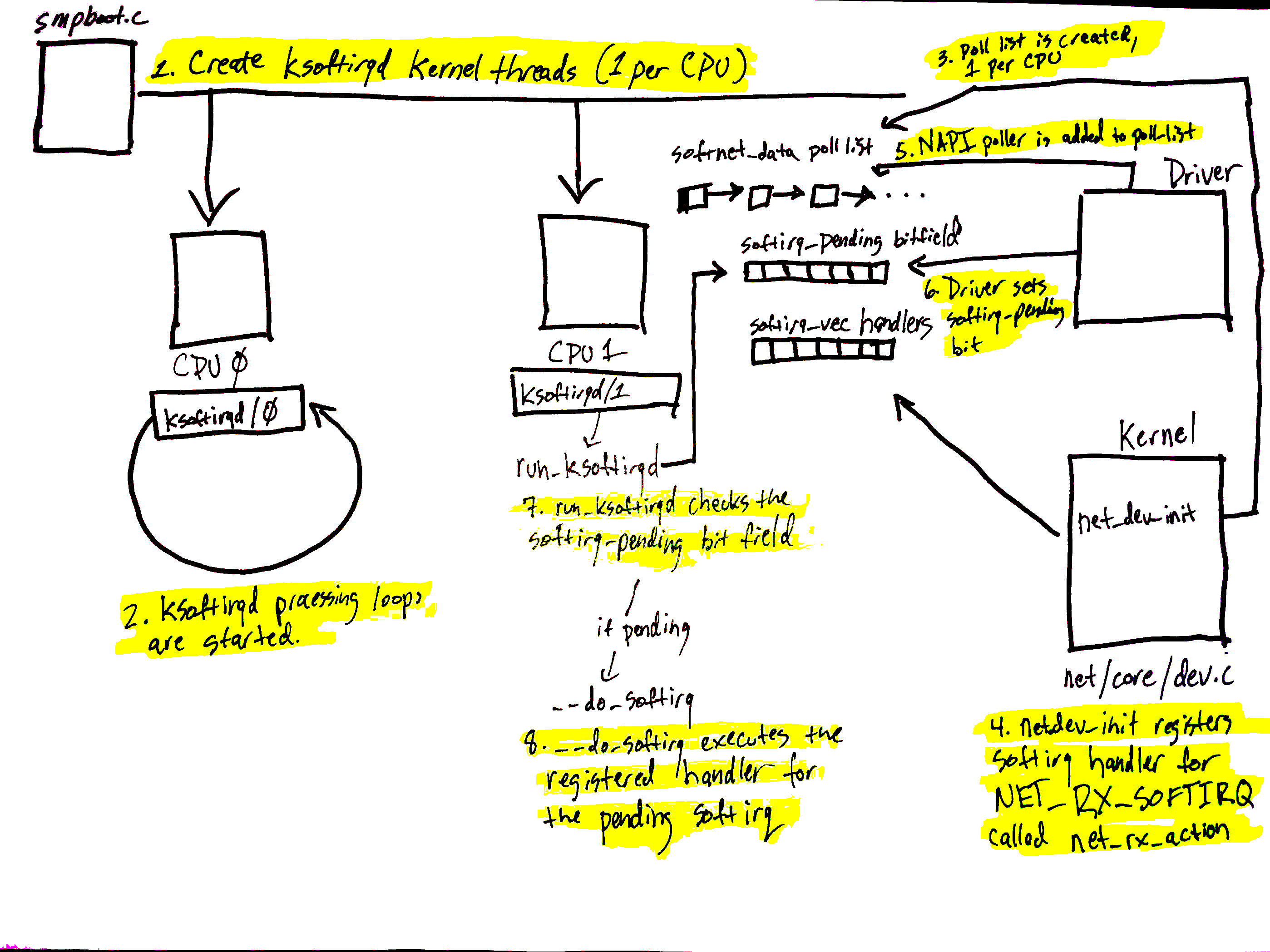
设备有许多方法来提醒计算机系统的其他部分,有一些工作已经准备好进行处理。在网络设备的情况下,NIC 常常会产生一个 IRQ 来表示一个数据包已经到达并准备好被处理。当 Linux 内核执行 IRQ 处理程序时,它以非常高的优先级运行,并且通常阻止生成其他的 IRQ。因此,设备驱动程序中的 IRQ 处理程序必须尽快执行,并推迟所有长时间运行的工作到在此上下文之外执行。这就是“softIRQ”系统存在的原因。
Linux 内核的“softIRQ”系统是内核用来在设备驱动程序 IRQ 上下文之外处理工作的系统。在网络设备的情况下,softIRQ 系统负责处理传入的数据包。softIRQ 系统在内核启动过程的早期初始化。
上图对应文章的 softIRQ 部分,显示了 softIRQ 系统及其每个 CPU 内核线程的初始化过程。
softIRQ 系统的初始化如下:
- 通过从 kernel/smpboot.c调用
smpboot_register_percpu_thread,在 kernel/softirq.c 中的spawn_ksoftirqd中创建 softIRQ 内核线程(每个 CPU 一个)。如代码所示,函数run_ksoftirqd被列为thread_fn,这是将在循环中执行的函数。 - ksoftirqd 线程开始在
run_ksoftirqd函数中执行它们的处理循环。 - 接下来,每个 CPU 创建一个
softnet_data结构。这些结构保存着对处理网络数据的重要数据结构的引用。poll_list后续将再次看到。poll_list是调用napi_schedule或来自设备驱动程序的其他 NAPI API 来添加 NAPI poll worker 结构的地方。 - 然后,
net_dev_init调用open_softirq向 softirq 系统注册NET_RX_SOFTIRQsoftirq,如此处所示。注册的处理程序函数称为net_rx_action。这是 softirq 内核线程为处理数据包而执行的函数。
图上的步骤 5 - 8 与到达的数据处理有关,并将在下一节中提及。继续阅读以获取更多信息!
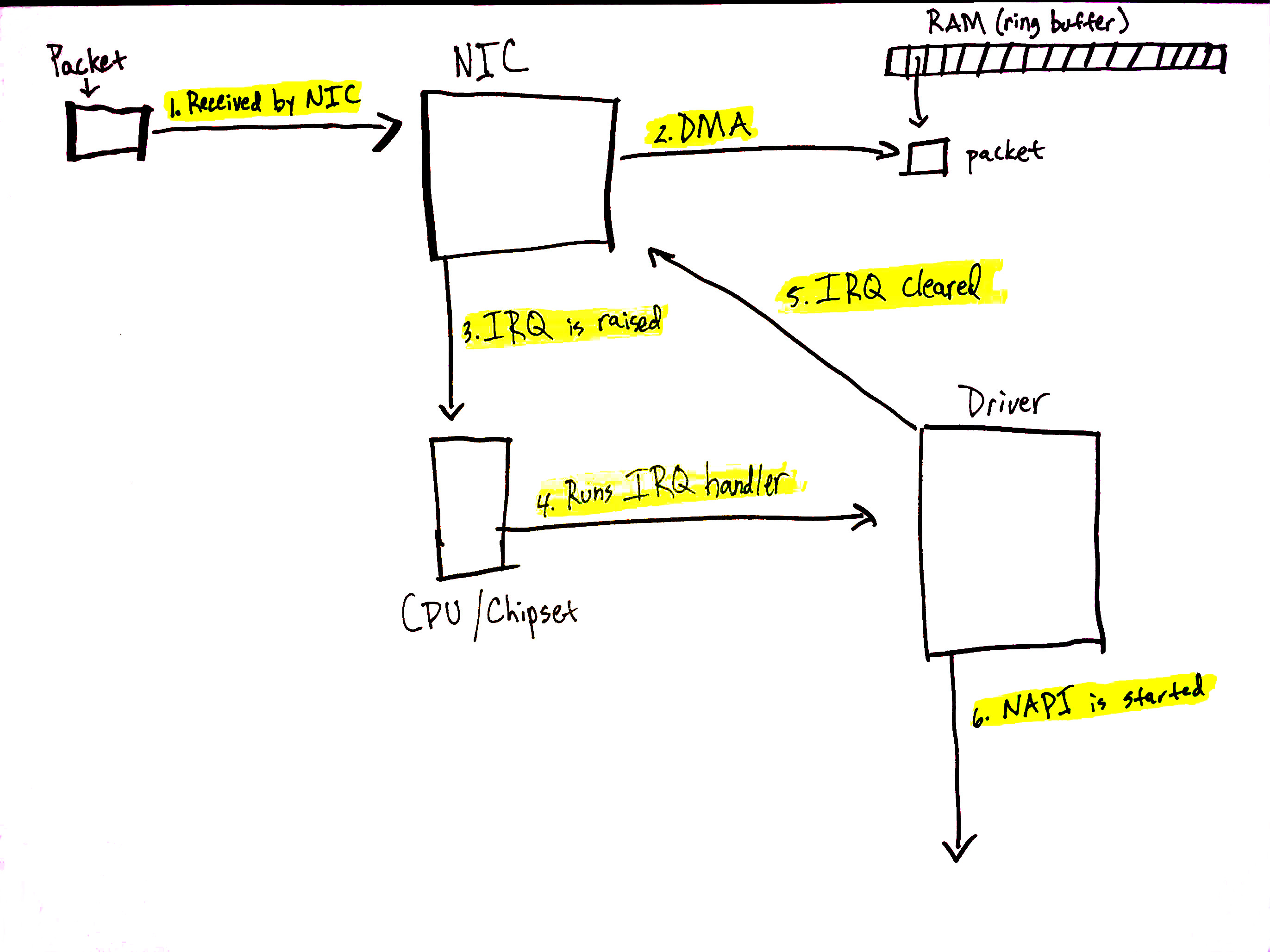
当网络数据到达 NIC 时,NIC 将使用 DMA将数据包数据写入 RAM。在 igb 网络驱动程序的情况下,RAM 中设置了一个指向接收数据包的环形缓冲区。需要注意的是,一些 NIC 是“多队列” NIC,这意味着它们可以 DMA 传入的数据包到 RAM 中的多个环形缓冲区之一。正如我们很快就会看到的,这样的 NIC 能够利用多个处理器来处理传入的网络数据。阅读有关多队列 NIC 的更多信息。上图为了简单起见只显示了一个环形缓冲区,但根据您使用的 NIC 和硬件设置,您的系统上可能有多个队列。
阅读更多关于下面描述过程的详细信息在此部分网络博客文章中。
让我们来看一下接收数据的过程:
- NIC 从网络接收数据 。
- NIC 使用 DMA 将网络数据写入 RAM。
- NIC 产生一个 IRQ。
- 执行设备驱动程序的已注册 IRQ 处理程序。
- 清除 NIC 上的 IRQ,以便它可以为新数据包到达生成 IRQ。
- 调用
napi_schedule启动 NAPI softIRQ 轮询循环。
调用 napi_schedule 触发了前面图表中步骤 5 - 8 的开始。正如我们将看到的,NAPI softIRQ 轮询循环的启动仅仅是在位域中翻转一个位,并将一个结构添加到 poll_list 中进行处理。napi_schedule 不做任何其他工作,这正是驱动程序如何将处理推迟到 softIRQ 系统的方式。
继续前一节中的图表,使用那里找到的数字:
- 驱动程序调用
napi_schedule添加驱动程序的 NAPI 轮询结构到当前 CPU 的poll_list中。 - 设置 softirq 挂起位,以便此 CPU 上的
ksoftirqd进程知道有数据包要处理。 - 执行
run_ksoftirqd函数(由ksoftirq内核线程在循环中运行)。 - 调用
__do_softirq,检查挂起位域,看到 softIRQ 挂起,并调用挂起 softIRQ 的已注册处理程序:net_rx_action,它完成了传入网络数据处理的所有繁重工作。
需要注意的是,执行 net_rx_action 的是 softIRQ 内核线程,而不是设备驱动程序 IRQ 处理程序。
网络数据处理开始
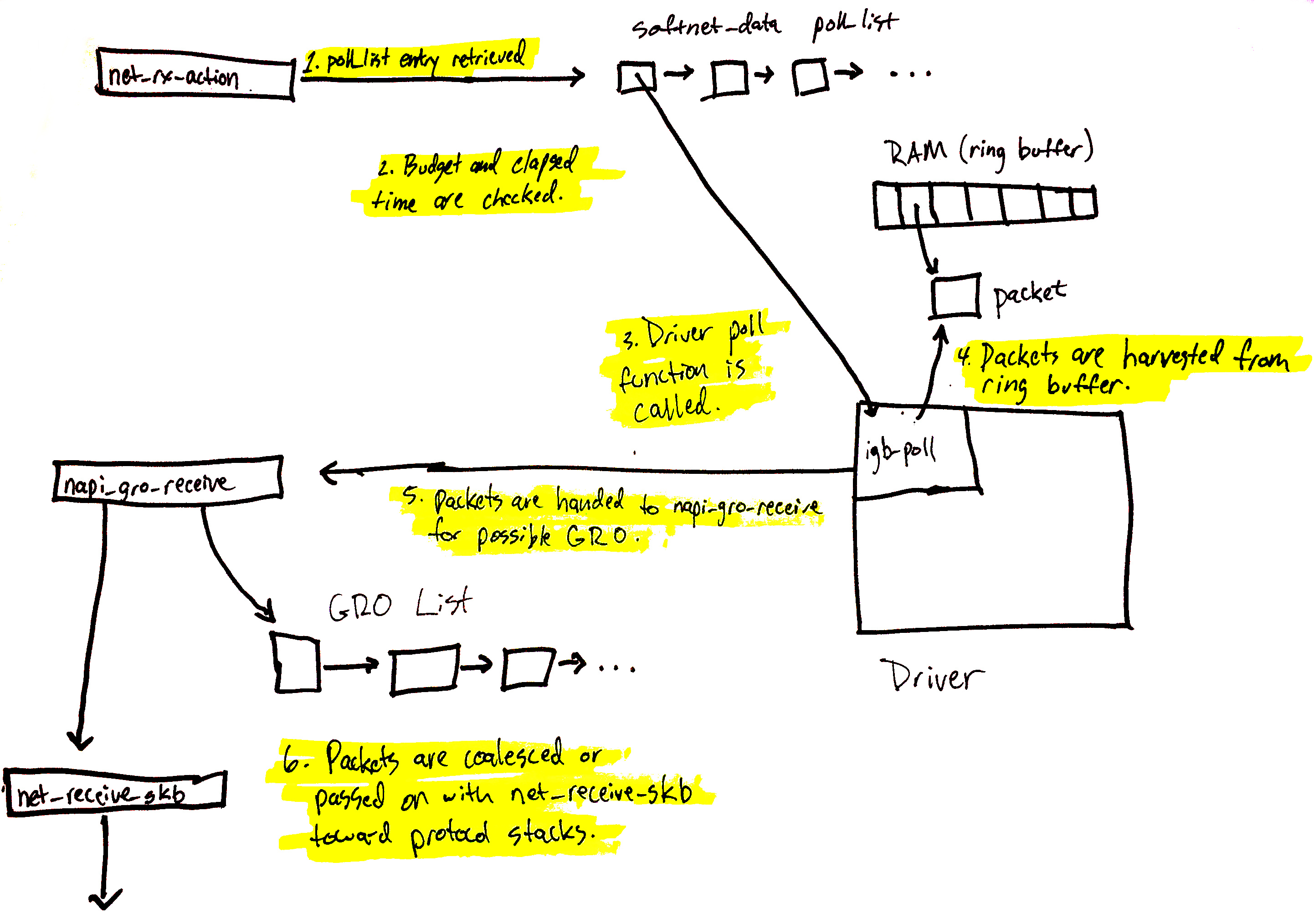
现在,数据处理开始。net_rx_action 函数(从 ksoftirqd 内核线程调用)开始处理已添加到当前 CPU 的 poll_list 中的任何 NAPI 轮询结构。通常在两种情况下,添加轮询结构:
我们将从 poll_list 中获取驱动程序的 NAPI 结构开始。 (下一节介绍 RPS 如何使用 IPI 注册 NAPI 结构)。
上面的图表在这里进行了深入的解释,可以总结如下:
net_rx_action循环开始检查 NAPI 轮询列表中的 NAPI 结构。- 检查
budget和经过的时间以确保 softIRQ 不会垄断 CPU 时间。 - 调用已注册的
poll函数。在这种情况下,igb_poll函数由igb驱动程序注册。 - 驱动程序的
poll函数从 RAM 中的环形缓冲区收取数据包。 - 数据包交给
napi_gro_receive,它将处理可能的通用接收卸载。 - 数据包要么保留用于 GRO,调用链在此结束,要么数据包被传递给
net_receive_skb,继续向协议栈上方进行。
接下来我们将看到 net_receive_skb 如何处理 Receive Packet steering,以在多个 CPU 之间分配数据包处理负载。
网络数据处理继续
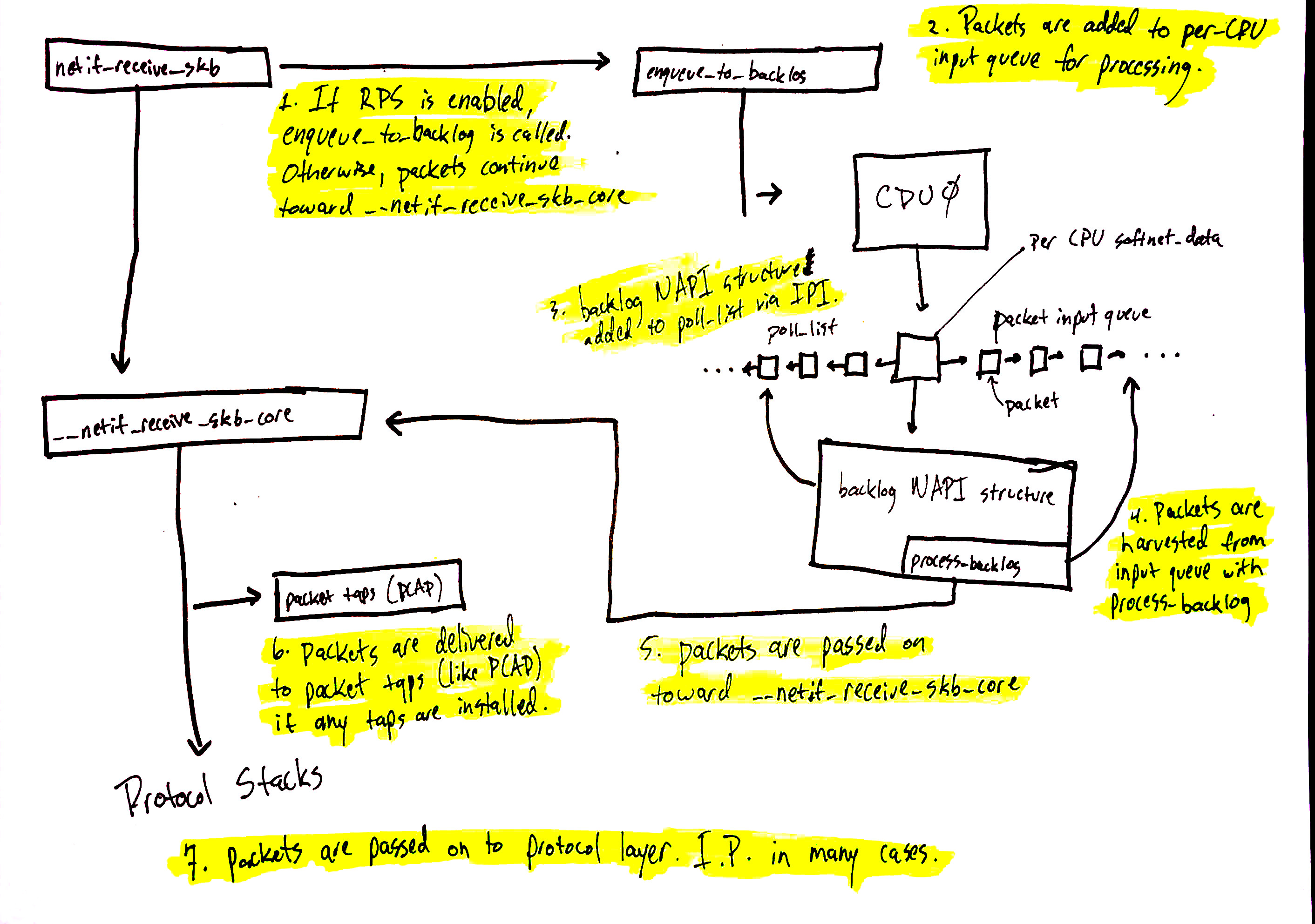
网络数据处理从 netif_receive_skb 继续,但数据的路径取决于是否启用了 Receive Packet Steering (RPS)。一个“开箱即用”的 Linux 内核默认不会启用 RPS,如果您想使用它,需要显式启用并配置。
在禁用 RPS 的情况下,使用上图中的数字:
netif_receive_skb将数据传递给__netif_receive_core。__netif_receive_core将数据传递给任何 tap(如PCAP)。__netif_receive_core将数据传递给已注册的协议层处理程序。在许多情况下,是 IPv4 协议栈已注册的ip_rcv函数。
netif_receive_skb将数据传递给enqueue_to_backlog。- 数据包被放置在每个 CPU 的输入队列中等待处理。
- 远程 CPU 的 NAPI 结构被添加到该 CPU 的
poll_list中,并排队一个 IPI,如果远程 CPU 上的 softIRQ 内核线程尚未运行,则触发它唤醒。 - 当远程 CPU 上的
ksoftirqd内核线程运行时,它遵循前一节中描述的相同模式,但这次,已注册的poll函数是process_backlog,它从当前 CPU 的输入队列中收取数据包。 - 数据包被传递到
__net_receive_skb_core。 __netif_receive_core将数据传递给任何 tap(如PCAP)。__netif_receive_core将数据传递给已注册的协议层处理程序。在许多情况下,是 IPv4 协议栈已注册的ip_rcv函数。
协议栈和用户界面套接字
接下来是协议栈、netfilter、berkley packet filters,最后是用户空间套接字。这条代码路径很长,但线性且相对简单。
您可以继续跟踪网络数据的详细路径。一个非常简短的高层次总结路径是:
- 数据包由
ip_rcv接收到 IPv4 协议层。 - 执行 Netfilter 和路由优化。
- 传送到当前系统的数据被传送到更高级别的协议层,如 UDP。
- 数据包由
udp_rcv接收到 UDP 协议层,并由udp_queue_rcv_skb和sock_queue_rcv排队到用户空间套接字的接收缓冲区。在排队到接收缓冲区之前,处理伯克利数据包过滤器。
请注意,在此过程中多次咨询 netfilter。确切的位置可以在我们的详细演练中找到。
Linux 网络堆栈非常复杂,有许多不同的系统相互作用。任何调优或监控这些复杂系统的努力都必须努力理解它们之间的相互作用以及如何更改一个系统中的设置会影响其他系统。
这篇(画得不好的)博客文章试图使我们的更长的博客文章更易于管理和理解。
本文作者 : cyningsun
本文地址 : https://www.cyningsun.com/04-26-2023/illustrated-guide-to-monitoring-and-tuning-the-Linux-networking-stack-recv-cn.html
版权声明 :本博客所有文章除特别声明外,均采用 CC BY-NC-ND 3.0 CN 许可协议。转载请注明出处!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK