

源码分析 golang ristretto 高性能缓存的设计实现原理
source link: https://xiaorui.cc/archives/7383
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

源码分析 golang ristretto 高性能缓存的设计实现原理 – 峰云就她了
源码分析 golang ristretto 高性能缓存的设计实现原理
ristretto 是 golang 社区里排头部的高性能的数据缓存库,支持键值过期和 LFU 缓存淘汰,还支持最大的内存空间限制,根据写时传入 cost 计算已使用的内存值,通常 cost 为对象的 size,但也可以当个数使用。其他缓存库多按照条数进行限制,不合理使用时容易造成 OOM 的风险。
其相比 freecache、bigcache 来说,存储 value 可以为任意值 interface{}。而 freecache、bigcache 内部通过一个大的 ringbuffer 来存放 value,而 value 需要是 []byte 字节数组,该设计对于 golang gc 很友好,但应用上受限,读写的时候需要对进行编码解码,这个开销不低的。
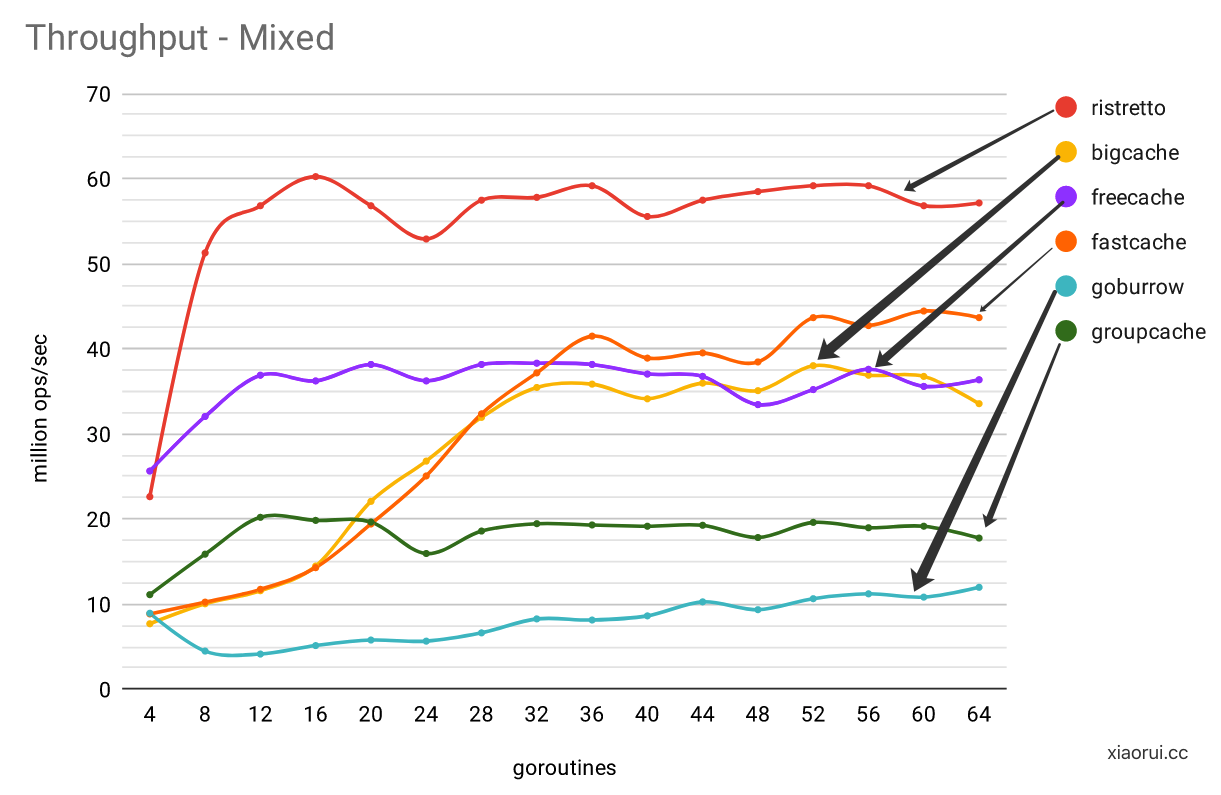
ristretto 在混合读写压测场景下,其吞吐表现要比其他 go cahce 库要好,当然压测的 case 通常是偏向自己的,懂的自然懂。
ristretto 使用方法
func main() {
cache, err := ristretto.NewCache(&ristretto.Config{
NumCounters: 1e7, // number of keys to track frequency of (10M).
MaxCost: 1 << 30, // maximum cost of cache (1GB).
BufferItems: 64, // number of keys per Get buffer.
})
if err != nil {
panic(err)
}
// 写数据,cost 为 1.
cache.Set("key", "value", 1)
// 由于 ristretto 是异步写,所以需要等待协程消费处理完.
cache.Wait()
// 获取数据
value, found := cache.Get("key")
if !found {
panic("missing value")
}
fmt.Println(value)
// 删除数据
cache.Del("key")
}
ristretto 项目地址:
https://github.com/dgraph-io/ristretto
ristretto 设计原理
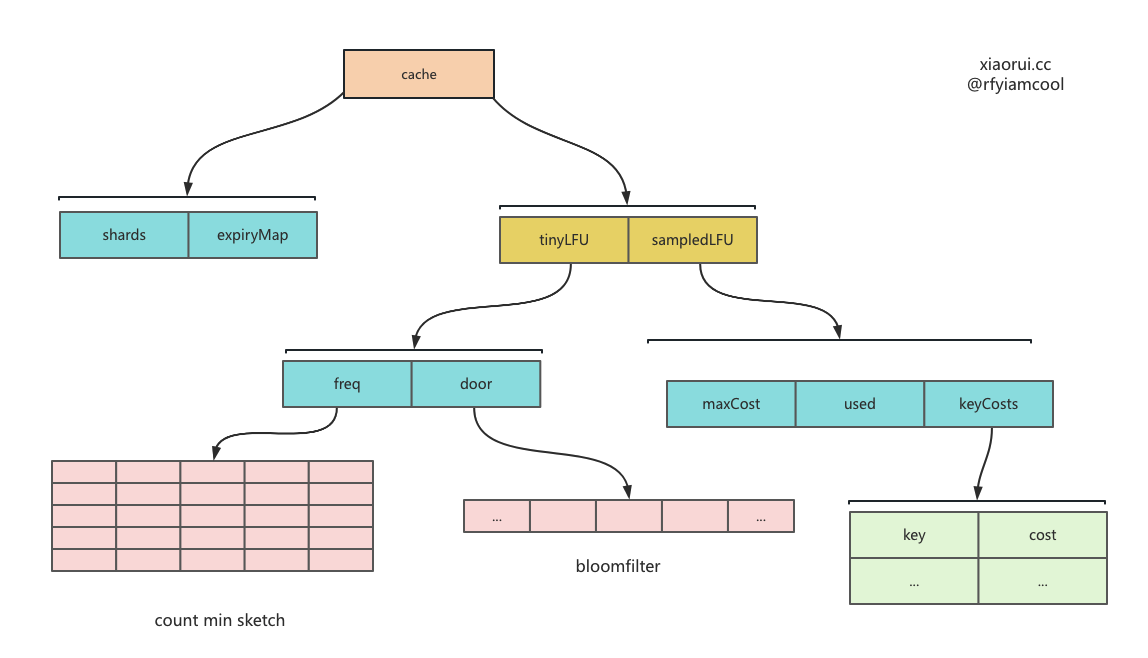
ristretto 的 kv 存储使用分片map来实现的,而缓存淘汰则使用 tinyLFU 实现。
ristretto store 的结构
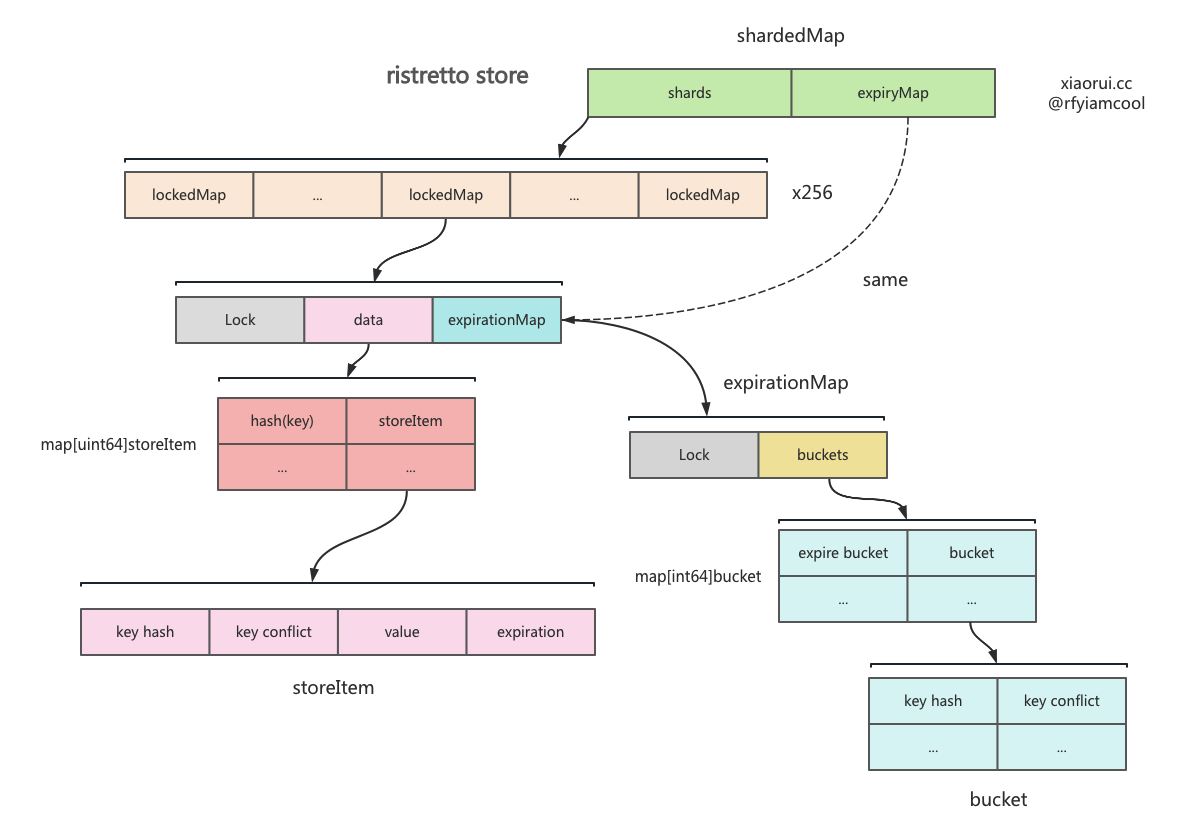
ristretto 设计了一个长度为 256 的分片集合,该结构类型为 shardedMap,其每个分片里有一个存数据的 map 和独立的锁,其目的是为了减少锁竞争,提高读写性能。增删改查的时候,通过对 key 进行取摸定位数据在哪一个 shard 分片上。
shardedMap 内部使用 expirationMap 来存键值过期数据的,所有分片共用一个 expirationMap 对象,ristretto 没有使用分片来构建过期数据集。
// 最大的分片数量,常量不能改.
const numShards uint64 = 256
type shardedMap struct {
shards []*lockedMap
expiryMap *expirationMap
}
func newShardedMap() *shardedMap {
sm := &shardedMap{
shards: make([]*lockedMap, int(numShards)),
expiryMap: newExpirationMap(),
}
for i := range sm.shards {
sm.shards[i] = newLockedMap(sm.expiryMap)
}
return sm
}
type lockedMap struct {
sync.RWMutex
data map[uint64]storeItem // 该 map 的 key 为数据key的哈希值.
em *expirationMap
}
type expirationMap struct {
sync.RWMutex
buckets map[int64]bucket // 该 map 的 key 过期时间的索引值,计算方法为 `ts/5 + 1`
}
// key 为键值 key 的 hash 值,value 为 conflict 值,是另一个 hash 值.
type bucket map[uint64]uint64
shardedMap 里不存储真正的 key 值,而是存储数据 key 两个 hash 值,为什么使用两个 hash 值标记对象,为了避免概率上的冲突,所以另使用另一个 xxhash 算法计算 hash 值,该值在 ristretto 定义为 conflict 哈希值。
KeyToHash 是 ristretto 默认的 hash 方法,传入的 key 不能是指针类型,也不能是 struct。返回值为两个 hash 值,其内部的 MemHash 其实是 runtime.memhash 映射的方法,golang 内部的 map 也使用该 hash 算法。xxhash 则为社区中较为火热的 hash 库。
func KeyToHash(key interface{}) (uint64, uint64) {
if key == nil {
return 0, 0
}
switch k := key.(type) {
case uint64:
return k, 0
case string:
return MemHashString(k), xxhash.Sum64String(k)
case []byte:
return MemHash(k), xxhash.Sum64(k)
case byte:
return uint64(k), 0
case int:
return uint64(k), 0
case int32:
return uint64(k), 0
case uint32:
return uint64(k), 0
case int64:
return uint64(k), 0
default:
panic("Key type not supported")
}
}
ristretto 缓存驱逐策略
社区中常常使用 LRU 和 LFU 算法来实现缓存淘汰驱逐,ristretto 则使用 LFU 算法,但由于 LFU 标准实现开销过大,则使用 TinyLFU 实现数据淘汰。
TinyLFU 里主要使用 count-min sketch 统计算法粗略记录各个 key 的缓存命中计数。该 count-min Sketch 算法通常用在不要求精确计数,又想节省内存的场景,虽然拿到的计数缺失一定的精准度,但确实节省了内存。
但就 ristretto 缓存场景来说,记录 100w 个 key 的计数也才占用 11MB 左右,公式是 ( 100 * 10000 ) * (8 + 4) / 1024/ 1024 = 11MB,这里的 8 为 key hash 的大小,而 4 为 hit 的类型 uint32 大小。
count-min sketch 统计算法实现

count-min sketch 中的 increment 和 estimate 方法实现原理很简单,流程如下。
- 选定 d 个 hash 函数,开一个 dm 的二维整数数组作为哈希表 ;
- 对于每个元素,分别使用d个hash函数计算相应的哈希值,并对m取余,然后在对应的位置上增1,二维数组中的每个整数称为sketch ;
- 要查询某个元素的频率时,只需要取出d个sketch, 返回最小的那一个。
ristretto 对 count-min sketch 并不是一直累计累加的,在 policy 累计对象超过 resetAt 时,则会对 cm-sketch 统计对象进行重置。不然一直递增,缓存淘汰场景下,对于新对象很不友好。
policy 数据结构的设计
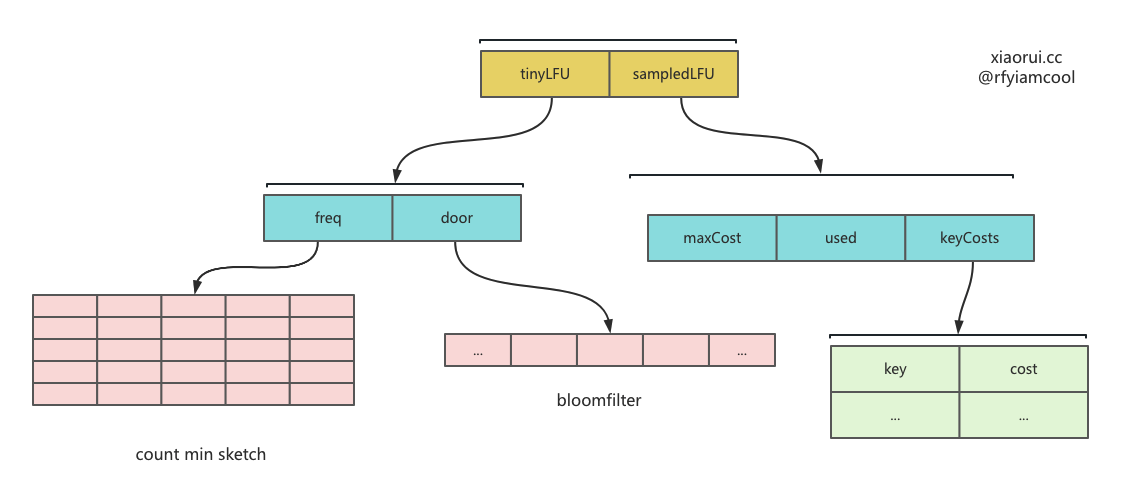
type defaultPolicy struct {
sync.Mutex
admit *tinyLFU // 实现了 tinyLFU 淘汰算法.
evict *sampledLFU // 记录最大 cost,已使用 cost,及 key 对应的 cost 值.
// 异步的维护缓存淘汰策略.
itemsCh chan []uint64
stop chan struct{}
isClosed bool
metrics *Metrics
}
type sampledLFU struct {
maxCost int64 // 最大 cost 阈值
used int64 // 已使用 cost 值
metrics *Metrics // 指标
keyCosts map[uint64]int64 // key 为数据的 key hash,value 为对应的 cost 值.
}
type tinyLFU struct {
freq *cmSketch // count min sketch
door *z.Bloom // bloomfilter
incrs int64
resetAt int64
}
policy tinylfu
policy 在实例化是除了实例化 defaultPolicy 对象,还会启动一个协程运行 processItems 方法,该方法用来监听 cache 传递的增删改事件,在 tinylfu count-min-sketch 里做记录,超过一定阈值后会重置,其目的为了避免老的 lfu freq 越来越大,不容易被淘汰掉。
func newDefaultPolicy(numCounters, maxCost int64) *defaultPolicy {
p := &defaultPolicy{
admit: newTinyLFU(numCounters),
evict: newSampledLFU(maxCost),
itemsCh: make(chan []uint64, 3),
stop: make(chan struct{}),
}
go p.processItems()
return p
}
func (p *defaultPolicy) processItems() {
for {
select {
case items := <-p.itemsCh:
p.Lock()
p.admit.Push(items)
p.Unlock()
case <-p.stop:
return
}
}
}
func (p *tinyLFU) Push(keys []uint64) {
for _, key := range keys {
p.Increment(key)
}
}
func (p *tinyLFU) Increment(key uint64) {
// Flip doorkeeper bit if not already done.
if added := p.door.AddIfNotHas(key); !added {
// Increment count-min counter if doorkeeper bit is already set.
p.freq.Increment(key)
}
p.incrs++
if p.incrs >= p.resetAt {
p.reset()
}
}
写时缓存淘汰驱逐
ristretto 没有实现后台协程主动淘汰驱逐的逻辑,而是采用了写时淘汰驱逐,每次写数据时,判断是否有足够的 cost 插入数据。如果不足,则进行驱逐。采样驱逐的方法有点类似 redis 的方案,每次从 simpleLFU 里获取 5 个 key,然后遍历计算这 5 个 key 的命中率,淘汰掉命中率最低的 key,然后再判断是否有空闲 cost 写入,不足继续采样淘汰,知道满足当前 key 的写入。
命中率是通过 tinyLFU 来计算的,由于该实现是通过 count-min sketch 算法实现,所以计算出的缓存命中数会产生些偏差。
func (p *defaultPolicy) Add(key uint64, cost int64) ([]*Item, bool) {
p.Lock()
defer p.Unlock()
// 添加的 cost 不能超过总 cost 阈值.
if cost > p.evict.getMaxCost() {
return nil, false
}
// 如果 simpleLfu 里有 key 值,则更新 cost 值.
if has := p.evict.updateIfHas(key, cost); has {
return nil, false
}
// 如果 key 在 simpleLFU 不存在,则走下面的逻辑.
// 计算减去 cost 后还剩多少可用的 cost.
room := p.evict.roomLeft(cost)
if room >= 0 {
// 如果足够 cost 开销,则更新 lfu 内指标.
p.evict.add(key, cost)
// 这里的 nil 代表,没有需要淘汰的数据,true 代表可以插入.
return nil, true
}
incHits := p.admit.Estimate(key)
// 构建一个可以放 5 条采样数据的集合
sample := make([]*policyPair, 0, lfuSample)
// 需要删除的 key
victims := make([]*Item, 0)
// 尝试淘汰数据,直到有空余的 cost.
for ; room < 0; room = p.evict.roomLeft(cost) {
// 采样获取 5 条 key,并填满 sample 数组.
sample = p.evict.fillSample(sample)
// 在取样集合里获取中最少被使用的 key,也就是缓存命中率最低的 key.
minKey, minHits, minId, minCost := uint64(0), int64(math.MaxInt64), 0, int64(0)
for i, pair := range sample {
// 获取该 key 的 hits 命中率
if hits := p.admit.Estimate(pair.key); hits < minHits {
minKey, minHits, minId, minCost = pair.key, hits, i, pair.cost
}
}
if incHits < minHits {
p.metrics.add(rejectSets, key, 1)
return victims, false
}
// 在 simpleLFU 中删除 key,且减去 cost.
p.evict.del(minKey)
sample[minId] = sample[len(sample)-1]
sample = sample[:len(sample)-1]
// 把需要淘汰掉的 key 添加到 victims 集合里.
victims = append(victims, &Item{
Key: minKey,
Conflict: 0,
Cost: minCost,
})
}
// 在 simpleLFU 记录 key 的 cost,且累加 cost.
p.evict.add(key, cost)
// 指标
p.metrics.add(costAdd, key, uint64(cost))
return victims, true
}
ristretto 读写流程源码分析
Set 写流程
// 带 cost 参数来写入 kv.
func (c *Cache) Set(key, value interface{}, cost int64) bool {
return c.SetWithTTL(key, value, cost, 0*time.Second)
}
// 带 cost 和过期参数来写入 kv.
func (c *Cache) SetWithTTL(key, value interface{}, cost int64, ttl time.Duration) bool {
// 判空
if c == nil || c.isClosed || key == nil {
return false
}
// 判断过期时间
var expiration time.Time
switch {
case ttl == 0:
break // 其他不加也行
case ttl < 0:
return false
default:
// 当前时间加上 ttl 过期时长为过期时间
expiration = time.Now().Add(ttl)
}
// 使用不同的 hash 算法计算出 key 的两个 hash 值,一个用来做 key 的哈希值,另一个用来用来做判断冲突的哈希值.
keyHash, conflictHash := c.keyToHash(key)
// 构建 item 对象.
i := &Item{
flag: itemNew, // 默认为新增
Key: keyHash,
Conflict: conflictHash,
Value: value,
Cost: cost,
Expiration: expiration,
}
// 判断是有存在值,存在则更新数据及 expire 信息,另外把 flag 设为更新.
if prev, ok := c.store.Update(i); ok {
c.onExit(prev)
i.flag = itemUpdate // 改为 update 更新
}
// 尝试把 item 发给 policy
select {
case c.setBuf <- i:
return true
default:
if i.flag == itemUpdate {
return true
}
// 统计
c.Metrics.add(dropSets, keyHash, 1)
return false
}
}
store update 方法
func (sm *shardedMap) Update(newItem *Item) (interface{}, bool) {
// 通过 key hash 取摸找到 shard,并执行 shard 的 update 方法.
return sm.shards[newItem.Key%numShards].Update(newItem)
}
func (m *lockedMap) Update(newItem *Item) (interface{}, bool) {
m.Lock()
// 判断是否已经存在 ?
item, ok := m.data[newItem.Key]
if !ok {
m.Unlock()
// 无,直接返回
return nil, false
}
// 有,则判断 hash conflict hash 是否一致,不一致则不为同一个值,直接跳出.
if newItem.Conflict != 0 && (newItem.Conflict != item.conflict) {
m.Unlock()
return nil, false
}
// 在 shard expirationMap 里更新过期信息.
m.em.update(newItem.Key, newItem.Conflict, item.expiration, newItem.Expiration)
// 把数据加到 shard data 里.
m.data[newItem.Key] = storeItem{
key: newItem.Key,
conflict: newItem.Conflict,
value: newItem.Value,
expiration: newItem.Expiration,
}
m.Unlock()
// 返回数据和true, 表明更新成功.
return item.value, true
}
ProcessItems
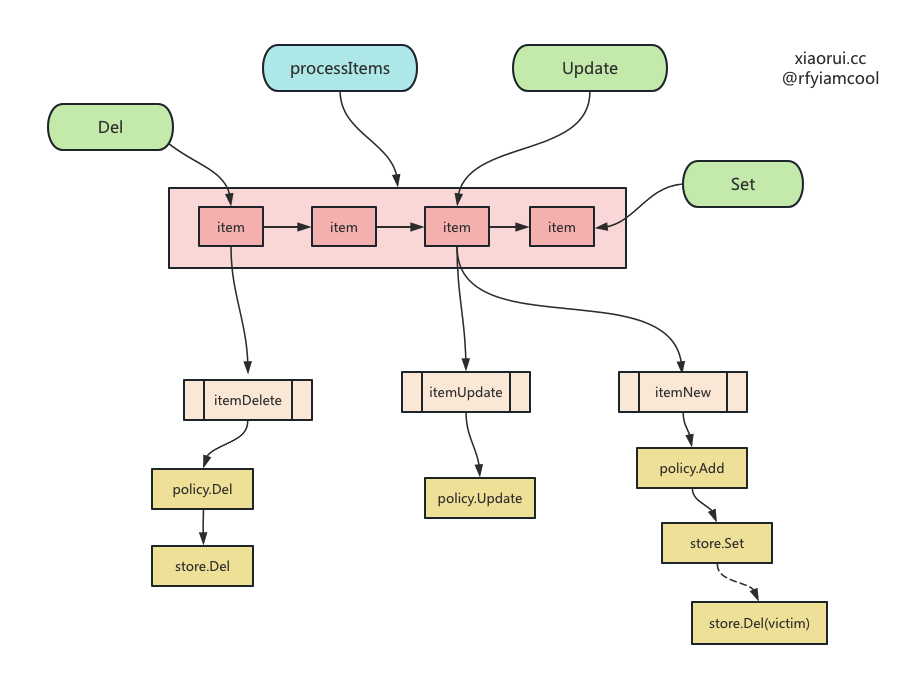
ristretto 实例化的时候会开启一个协程运行 processItems,processItems 方法可以处理 item 的增删改,还可以周期性进行 GC 垃圾回收。
// processItems is ran by goroutines processing the Set buffer.
func (c *Cache) processItems() {
startTs := make(map[uint64]time.Time)
numToKeep := 100000 // TODO: Make this configurable via options.
trackAdmission := func(key uint64) {
if c.Metrics == nil {
return
}
startTs[key] = time.Now()
if len(startTs) > numToKeep {
for k := range startTs {
if len(startTs) <= numToKeep {
break
}
delete(startTs, k)
}
}
}
onEvict := func(i *Item) {
if ts, has := startTs[i.Key]; has {
c.Metrics.trackEviction(int64(time.Since(ts) / time.Second))
delete(startTs, i.Key)
}
if c.onEvict != nil {
c.onEvict(i)
}
}
for {
select {
case i := <-c.setBuf:
if i.wg != nil {
i.wg.Done()
continue
}
// 如果是添加和更新,则需要计算 item 的开销
if i.Cost == 0 && c.cost != nil && i.flag != itemDelete {
i.Cost = c.cost(i.Value)
}
// 判断是否需要忽略内部数据结构的开销.
if !c.ignoreInternalCost {
// 累加 Item 自身的字节开销
i.Cost += itemSize
}
// 根据 flag 类型执行增删改逻辑.
switch i.flag {
case itemNew:
// 当超过阈值时,返回需要删除的数据 victims,added 为是否添加成功.
victims, added := c.policy.Add(i.Key, i.Cost)
if added {
// 在 store 里添加 item 对象.
c.store.Set(i)
// 统计信息
c.Metrics.add(keyAdd, i.Key, 1)
trackAdmission(i.Key)
} else {
// 回调传入的 onreject 方法,且执行 onExit 方法.
c.onReject(i)
}
// 删除相关记录
for _, victim := range victims {
victim.Conflict, victim.Value = c.store.Del(victim.Key, 0)
// 被缓存策略驱逐需要回调 onEvict 方法.
onEvict(victim)
}
case itemUpdate:
// 由于在 cache.Set 方法里处理了 Update 的数据,这里只做 policy 通知即可.
c.policy.Update(i.Key, i.Cost)
case itemDelete:
// 在 policy里 删除
c.policy.Del(i.Key) // Deals with metrics updates.
// 在 store 删除该记录
_, val := c.store.Del(i.Key, i.Conflict)
// 执行回调方法
c.onExit(val)
}
case <-c.cleanupTicker.C:
// 进行 GC 垃圾回收,删除过期的数据.
c.store.Cleanup(c.policy, onEvict)
case <-c.stop:
return
}
}
}
store Set
先从 sharedMap 里找到相关的 shard,然后在 shard 判断是否以前有值, 如果有前值,且 key conflict hash 值不一致,则直接跳出,否则更新 expireMap,然后把 item 接到 shard 的 data 里。
代码位置: github/ristretto/store.go
// 在 shardedMap 里写入.
func (sm *shardedMap) Set(i *Item) {
if i == nil {
return
}
// 对 key hash 取摸计算出 shard,再对 shard 调用 set 来写入.
sm.shards[i.Key%numShards].Set(i)
}
// 在 shard 里写入.
func (m *lockedMap) Set(i *Item) {
if i == nil {
// If the item is nil make this Set a no-op.
return
}
// 执行 shard 内部的锁
m.Lock()
defer m.Unlock()
// 尝试获取先前数据
item, ok := m.data[i.Key]
if ok {
// 如果有前值,且 key conflict hash 值不一致,则直接跳出.
if i.Conflict != 0 && (i.Conflict != item.conflict) {
return
}
// 如果有旧值,则在 expire map 里更新过期时间.
m.em.update(i.Key, i.Conflict, item.expiration, i.Expiration)
} else {
// 如果没有,在 expire map 里添加过期信息.
m.em.add(i.Key, i.Conflict, i.Expiration)
}
// 把 item 里加到 data 里.
m.data[i.Key] = storeItem{
key: i.Key, // key hash1
conflict: i.Conflict, // key hash2
value: i.Value,
expiration: i.Expiration,
}
}
add 在 expirationMap 里添加过期数据,update 则是在 expirationMap 删除以前的过期数据,添加新的过期数据。
代码位置: github/ristretto/ttl.go
var (
bucketDurationSecs = int64(5)
)
// 每 5 秒为一个 bucket.
func storageBucket(t time.Time) int64 {
return (t.Unix() / bucketDurationSecs) + 1
}
func (m *expirationMap) add(key, conflict uint64, expiration time.Time) {
// 判空
if m == nil {
return
}
// 过期为空, 则直接跳出.
if expiration.IsZero() {
return
}
// 通过过期时长获取 bucket 索引.
bucketNum := storageBucket(expiration)
m.Lock()
defer m.Unlock()
// 把 key 和 conflict 加到 bucket 里.
b, ok := m.buckets[bucketNum]
if !ok {
b = make(bucket)
m.buckets[bucketNum] = b
}
b[key] = conflict
}
func (m *expirationMap) update(key, conflict uint64, oldExpTime, newExpTime time.Time) {
if m == nil {
return
}
m.Lock()
defer m.Unlock()
// 删旧
oldBucketNum := storageBucket(oldExpTime)
oldBucket, ok := m.buckets[oldBucketNum]
if ok {
delete(oldBucket, key)
}
// 加新
newBucketNum := storageBucket(newExpTime)
newBucket, ok := m.buckets[newBucketNum]
if !ok {
newBucket = make(bucket)
m.buckets[newBucketNum] = newBucket
}
newBucket[key] = conflict
}
Get 读流程
Get 用来读取数据, 其流程如下。
func (c *Cache) Get(key interface{}) (interface{}, bool) {
// 基本判空
if c == nil || c.isClosed || key == nil {
return nil, false
}
// 使用不同的 hash 算法计算出 key 的两个 hash 值,一个用来做 key 的哈希值,另一个用来用来做判断冲突的哈希值.
keyHash, conflictHash := c.keyToHash(key)
// 调用 ringBuffer 的 push 接口,把 key hash 放进去.
// 其目的用来实现 lfu 策略.
c.getBuf.Push(keyHash)
// 从 store 里获取 value
value, ok := c.store.Get(keyHash, conflictHash)
if ok {
// 如果有值,则在 hit 统计里加一.
c.Metrics.add(hit, keyHash, 1)
} else {
// 如果没有值,则在 miss 统计里加一.
c.Metrics.add(miss, keyHash, 1)
}
// 返回
return value, ok
}
从 shardedMap 里获取数据, 其内部流程是先取摸计算出 key 应该在哪个 shard,然后再从 shard 里获取 kv,然后对比 key conflict hash 值,不一致则说明不是同一条数据,接着判断 kv 是否过期,如过期也返回 false,不过期则返回数据。
// 从 shardedMap 里获取数据.
func (sm *shardedMap) Get(key, conflict uint64) (interface{}, bool) {
return sm.shards[key%numShards].get(key, conflict)
}
// 从 shard 里获取数据.
func (m *lockedMap) get(key, conflict uint64) (interface{}, bool) {
m.RLock()
item, ok := m.data[key]
m.RUnlock()
if !ok {
return nil, false
}
if conflict != 0 && (conflict != item.conflict) {
return nil, false
}
// 判断是否超时,当 kv 过期超时,这里不主动删除数据,而直接返回无数据的错误.
// 这里的删除等待定时器的 gc 垃圾回收处理.
if !item.expiration.IsZero() && time.Now().After(item.expiration) {
return nil, false
}
// 返回数据
return item.value, true
}
Del 删除数据
Del 用来删除数据, 其流程如下。
// Del deletes the key-value item from the cache if it exists.
func (c *Cache) Del(key interface{}) {
// 判空
if c == nil || c.isClosed || key == nil {
return
}
// 通过不同的 hash 算法获取 key 的两个 hash 值.
keyHash, conflictHash := c.keyToHash(key)
// 在 store 里删除数据
_, prev := c.store.Del(keyHash, conflictHash)
// 回调 exit 方法
c.onExit(prev)
// 像 setBuf 里传递 item 对象,flag 标记为 delete.
c.setBuf <- &Item{
flag: itemDelete,
Key: keyHash,
Conflict: conflictHash,
}
}
从 shardedMap 里删除数据,其流程如下。
- 通过 key hash 获取 item ;
- 判断 hash conflict hash 值是否一致,不一致则直接 return ;
- 如果 item 配置了过期时间,则在 expirationMap 里删除相关记录 ;
- 在 map 里删除 item.
// 从 shardedMap 里删除数据.
func (sm *shardedMap) Del(key, conflict uint64) (uint64, interface{}) {
return sm.shards[key%numShards].Del(key, conflict)
}
// 从 shard 里删除数据.
func (m *lockedMap) Del(key, conflict uint64) (uint64, interface{}) {
m.Lock()
// 通过 key hash 获取 item
item, ok := m.data[key]
if !ok {
// 没有值,无需删除,返回
m.Unlock()
return 0, nil
}
// 判断 hash conflict hash 值是否一致.
if conflict != 0 && (conflict != item.conflict) {
m.Unlock()
return 0, nil
}
// 如果 item 配置了过期时间,则在 expirationMap 里删除.
if !item.expiration.IsZero() {
m.em.del(key, item.expiration)
}
// 删除 item.
delete(m.data, key)
m.Unlock()
// 返回 hash 冲突值和 value.
return item.conflict, item.value
}
expire gc 过期垃圾回收的设计原理
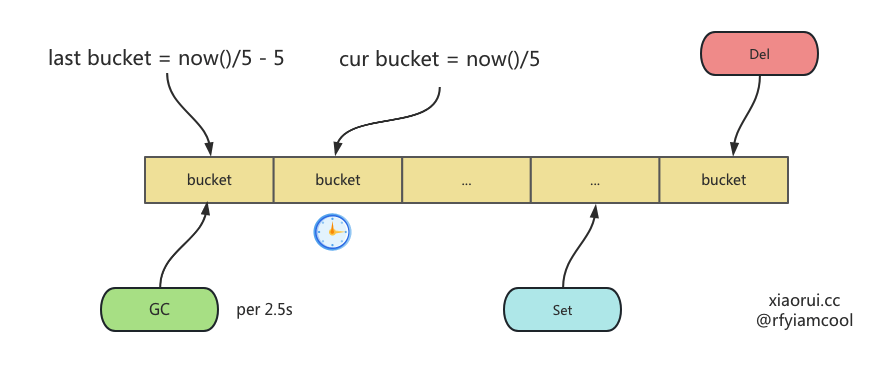
ristretto 初始化会启动一个协程来执行 processItems, 该方法里不仅监听 setBuf 管道来对数据增删改,且还会监听垃圾回收定时器来完成垃圾回收。 每 2.5 秒调用 Cleanup 方法执行过期键的垃圾回收。
var (
bucketDurationSecs = int64(5)
cleanupTicker = time.NewTicker(time.Duration(bucketDurationSecs) * time.Second / 2),
)
func (c *Cache) processItems() {
startTs := make(map[uint64]time.Time)
numToKeep := 100000
onEvict := func(i *Item) {
if ts, has := startTs[i.Key]; has {
c.Metrics.trackEviction(int64(time.Since(ts) / time.Second))
delete(startTs, i.Key)
}
if c.onEvict != nil {
c.onEvict(i)
}
}
for {
select {
case i := <-c.setBuf:
// ...
case <-c.cleanupTicker.C:
// 执行过期数据垃圾回收.
c.store.Cleanup(c.policy, onEvict)
}
}
}
Cleanup 是过期键垃圾回收的核心方法,其内部流程如下。
先获取当前时间点以前的 bucket,然后遍历该 bucket 内的所有 keys,判断是否过期,如过期则在 store 里删除 item,没过期则跳过。
func (sm *shardedMap) Cleanup(policy policy, onEvict itemCallback) {
sm.expiryMap.cleanup(sm, policy, onEvict)
}
func cleanupBucket(t time.Time) int64 {
return storageBucket(t) - 1
}
func (m *expirationMap) cleanup(store store, policy policy, onEvict itemCallback) {
// 判空
if m == nil {
return
}
m.Lock()
now := time.Now()
// 取出当前时间对应的上一个 bucket 时间点.
bucketNum := cleanupBucket(now)
// 取出该 bucket 的 key hash 和 conflict hash.
keys := m.buckets[bucketNum]
// 在 buckets 集合里删该 bucket.
delete(m.buckets, bucketNum)
// 放锁,因为后面的路基是慢逻辑.
m.Unlock()
// 遍历上一个 bucket 的 key hash 集合, 尝试删除过期的键值.
for key, conflict := range keys {
// 没过期,跳过
if store.Expiration(key).After(now) {
continue
}
// 如过期获取 key 的 cost 开销值.
cost := policy.Cost(key)
// 在 policy 里删除 key.
policy.Del(key)
// store 里删除该值.
_, value := store.Del(key, conflict)
// 执行回调方法.
if onEvict != nil {
onEvict(&Item{Key: key,
Conflict: conflict,
Value: value,
Cost: cost,
})
}
}
}
简单说, ristretto 的 kv 存储使用分片map来实现的,而缓存淘汰则使用 tinyLFU 实现。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK