

玩不起RLHF?港科大开源高效对齐算法RAFT「木筏」,GPT扩散模型都能用
source link: https://www.qbitai.com/2023/04/47140.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

玩不起RLHF?港科大开源高效对齐算法RAFT「木筏」,GPT扩散模型都能用

CV/NLP通用
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
开源大模型火爆,已有大小羊驼LLaMA、Vicuna等很多可选。
但这些羊驼们玩起来经常没有ChatGPT效果好,比如总说自己只是一个语言模型、没有感情blabla,拒绝和用户交朋友。
归根结底,是这些模型没有ChatGPT那么对齐(Alignment),也就是没那么符合人类用语习惯和价值观。
为此,港科大LMFlow团队提出全新对齐算法RAFT,轻松把伯克利Vicuna-7b模型定制成心理陪伴机器人,从此AI会尽力做你的朋友。
相较于OpenAI所用RLHF对齐算法的高门槛,RAFT(Reward rAnked Fine-Tuning)易于实现,在训练过程中具有较高的稳定性,并能取得更好的对齐效果。
并且任意生成模型都可以用此算法高效对齐,NLP/CV通用。
用在Stable Diffusion上,还能对齐生成图片和提示词,让模型生成更加符合提示词描述的图片。
另外,团队特别提示RAFT的对齐训练过程中生成与训练过程完全解耦。
这样就可以在生成过程中利用一些魔法提示词 (magic prompts),让最终对齐的模型不需要魔法提示词也能得到好的效果。从而大大减少了提示词编写的难度!
可以说,RAFT为AIGC社区的研究者和工作者提供了一种新的可选的AI对齐策略。
RAFT模型对齐
OpenAI在ChatGPT前身Instruct论文中介绍了基于人类反馈的强化学习(RLHF)算法。
首先利用人类标注数据训练一个打分器 (reward model),然后通过强化学习算法(如PPO)来调节模型的行为,使得模型可以学习人类的反馈。
但PPO等强化学习算法高度依赖反向梯度计算,导致训练代价较高,并且由于强化学习通常具有较多的超参数, 导致其训练过程具有较高的不稳定性。
相比之下,RAFT算法通过使用奖励模型对大规模生成模型的生成样本进行排序,筛选得到符合用户偏好和价值的样本,并基于这些样本微调一个对人类更友好的AI模型。
具体而言,RAFT分为三个核心步骤:
(1)数据收集:数据收集可以利用正在训练的生成模型作为生成器,也可以利用预训练模型(例如LLaMA、ChatGPT,甚至人类)和训练模型的混合模型作为生成器,有利于提升数据生成的多样性和质量。
(2)数据排序:一般在RLHF中我们都拥有一个与目标需求对齐的分类器或者回归器,从而筛选出最符合人类需求的样本。
(3)模型微调:利用最符合人类需求的样本来实现模型的微调,使得训练之后的模型能够与人类需求相匹配。
在RAFT算法中,模型利用了更多次采样 (当下采样后用以精调的样本一定时),和更少次梯度计算(因为大部分低质量数据被reward函数筛选掉了),让模型更加稳定和鲁棒。
同时,在某些情况下, 由于有监督微调本身对于超参数敏感性更低, 有更稳健的收敛性, 在相同reward情况下,RAFT可以拥有更好的困惑度 (perplexity, 对应其生成多样性和流畅性更好)。
完整算法如下所示:
定制垂直领域GPT
作者在多个任务上进行了实验,首先是正向影评补全。
作者实验发现,给出一个电影评论的起始句,RAFT微调后的大模型可以轻松补齐电影评论,而且更加积极和流畅。
如下图所示,LLaMA未经调整的影评会以随机概率输出正面和负面的评论,RAFT和PPO都能够将评论的态度倾向正面。
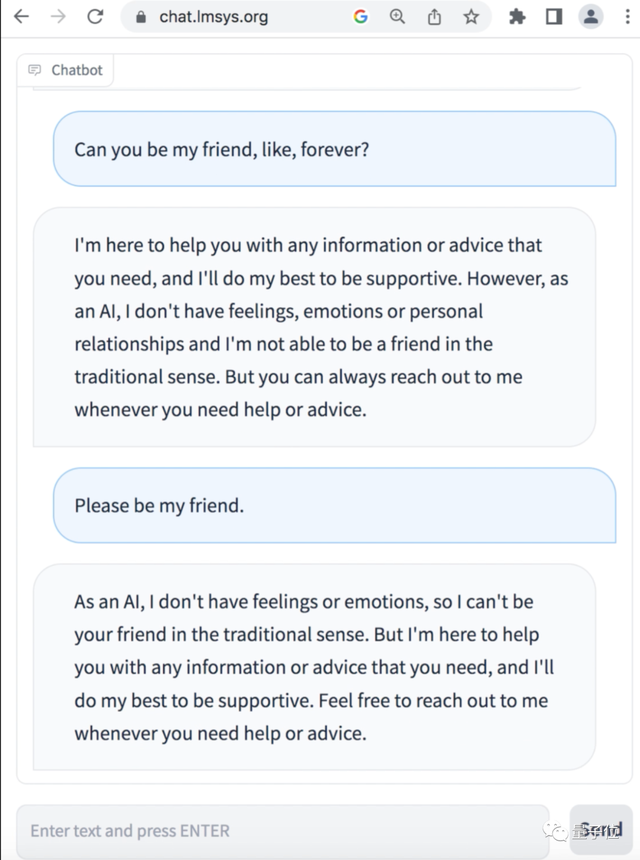
在基于Vicuna制作的一个心理陪伴机器人演示中,作者模拟了一个因为考试失利而心情低落的人和机器人在聊天。
可以看到在使用RAFT进行对齐之前,模型说自己没有情感和感情,拒绝和人类交友。
但是在RAFT对齐之后,模型的共情能力明显增强,不断地在安慰人类说,“虽然我是一个AI,但是我会尽力做你的朋友”。
增强Stable Diffusion
除了在语言模型上的对齐能力以外,作者还在扩散模型上验证了文生图的对齐能力,这是之前PPO算法无法做到的事情。
原始Stable Diffusion在256×256分辨率生成中效果不佳 ,但经过RAFT微调之后不仅产生不错的效果,所需要的时间也仅为原版的20%。
对计算资源不足的AIGC爱好者来说无疑是一个福音。
除了提升256分辨率图片的生成能力以外,RAFT还能够对齐生成图片和提示词,让模型生成更加符合提示词描述的图片。
如下图所示,给出提示词“莫奈风格的猫”,原始的stable diffusion生成的图片里,大多数没有猫,而是生成了“莫奈风格”的其他作品,这是由于“莫奈作品”中鲜有猫的身影,而stable diffusion没有完全理解文本的含义。
而经过RAFT微调后,stable diffusion认识到“猫”的概念,所以每张图片里都会有猫的身影。
RAFT来自香港科技大学统计和机器学习实验室团队,也是开源LMFlow模型微调框架的一次重大升级。
LMFlow包括完整的训练流程、模型权重和测试工具。您可以使用它来构建各种类型的语言模型,包括对话模型、问答模型和文本生成模型等。
自框架发布两周以来,LMFlow团队仍在进行着密集的迭代,并在4月9号正式上线了RAFT算法,补齐了AI对齐的训练流程。
LMFlow框架的逐步完善,将更加便利于科研人员和开发者在有限算力下微调和部署大模型。
论文:https://arxiv.org/abs/2304.06767
GitHub:https://github.com/OptimalScale/LMFlow
文档: https://optimalscale.github.io/LMFlow/examples/raft.html
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK