

sql处理重复的列,更好理清分组和分区 - 一乐乐
source link: https://www.cnblogs.com/shan333/p/17206824.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

一、分组统计、分区排名
1、语法和含义:
如果查询结果看得有疑惑,看第二部分-sql处理重复的列,更好理清分组和分区,有建表插入数据的sql语句
分组统计:GROUP BY 结合 统计/聚合函数一起使用
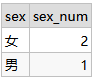
-- 举例子: 按照性别统计男生、女生的人数
select sex,count(distinct id) sex_num from student_score group by sex;
分区排名:ROW_NUMBER() OVER(PARTITION BY 分区的字段 ORDER BY 升序/降序字段 [DESC])
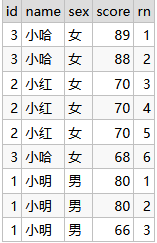
-- 举例子: 按照性别-男生、女生进行分区,按照成绩进行降序
select id,name,sex,score,
ROW_NUMBER() OVER(PARTITION BY sex ORDER BY score DESC) rn
from student_score;
2、使用注意事项:
▷ 排名函数row_number() 需要的mysql 版本需要8及以上!
▷ 对于分组统计 group by 容易出现的报错问题:
因为规定要求 select 列表的字段非聚合字段,必须出现在group by后面进行分组。
报错:Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column '数据库.表.字段' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
SELECT列表的表达式-不在GROUP BY子句中,并且包含非聚合列'数据库.表.字段'。
▷ 对于排名函数ROW_NUMBER,容易出现的报错问题:
- 一般是你的分区字段写得有问题,可以坚持一下分区字段!比如在hive中,分区字段为 get_json_object(map_col,'$.title'),但是漏掉了一个'
报错:Failed to breakup Windowing invocations into Groups. At least 1 group must only depend on input columns. Also check for circular dependencies.
未能将窗口调用分解为组。至少 1 个组必须仅依赖于输入列。还要检查循环依赖。
二、sql处理重复的列,更好理清分组和分区
1、sql语句-建表、插入数据的语句
DROP TABLE IF EXISTS `student_score`;
CREATE TABLE `student_score` (
`id` int(6),
`name` varchar(255),
`sex` varchar(255),
`subject` varchar(30),
`score` float
) ENGINE = InnoDB;
INSERT INTO `student_score` VALUES (1, '小明', '男','语文', 80);
INSERT INTO `student_score` VALUES (2, '小红', '女','语文', 70);
INSERT INTO `student_score` VALUES (3, '小哈', '女','语文', 88);
INSERT INTO `student_score` VALUES (1, '小明', '男','数学', 66);
INSERT INTO `student_score` VALUES (2, '小红', '女','数学', 70);
INSERT INTO `student_score` VALUES (3, '小哈', '女','数学', 89);
INSERT INTO `student_score` VALUES (1, '小明', '男','英语', 80);
INSERT INTO `student_score` VALUES (2, '小红', '女','英语', 70);
INSERT INTO `student_score` VALUES (3, '小哈', '女','英语', 68);
2、查询所有学生的成绩:
- select * from student_score;
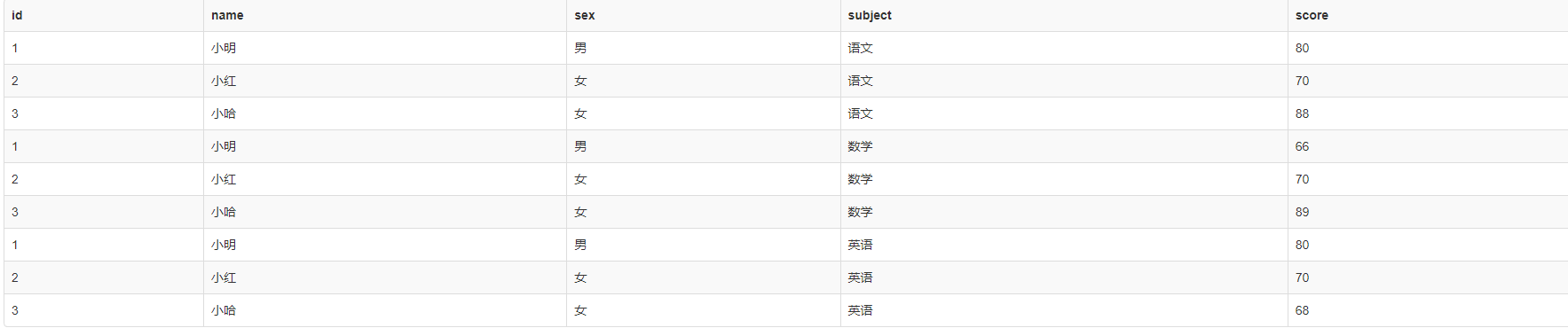
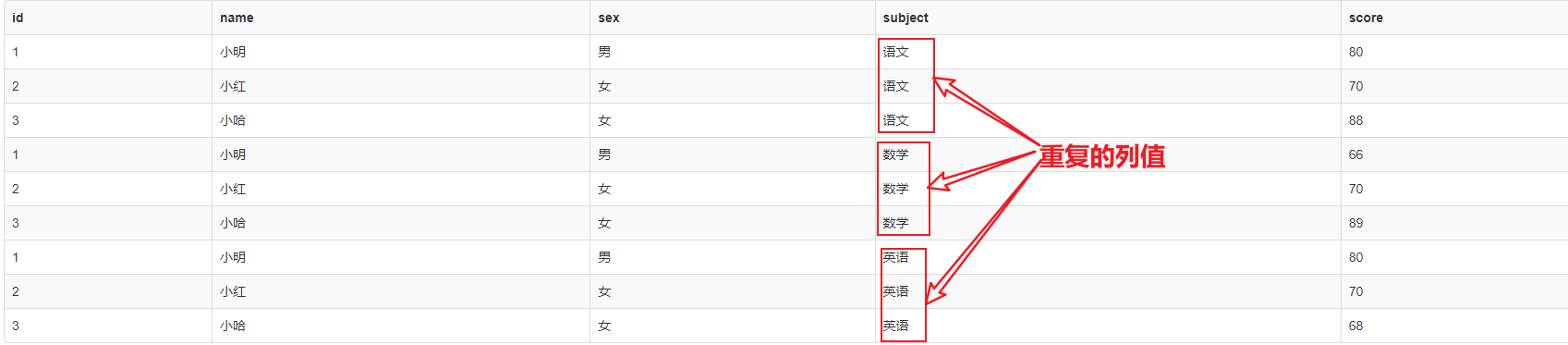
3、结果,有重复的列值
相应的成绩对应的学科名称是以列的形式展示的,造成了语文、语文、语文的重复
4-1、处理重复的列-方式1-合并去除重复的列值[列转行]
对应到常见的sql应用场景,统计各个学生的各科成绩,实现方式有两种,一种是分组统计的方式,一种是分区排名的方式
分组统计:
select id,name,sex,
max(case when subject='语文' then score else 0 end) as chinese,
max(case when subject='英语' then score else 0 end) as english,
max(case when subject='数学' then score else 0 end) as math
from student_score
group by id
order by score desc

按成绩降序排序,可以看到默认选择第一门学科-语文的成绩进行降序排序。
4-2、处理重复的列-方式2-对重复的列值进行排名
select id,name,subject,score,
row_number() over(partition by subject order by score desc) rn
from student_score;
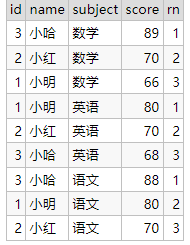
三、总结分组、分区的区别
例如按学科分组或按学科分区,那么,分组得到的是一个列值(一条记录数据)的结果,分区是多个列值(多条记录数据)的结果。
分组-一条记录

分区-多条记录

如果本文对你有帮助的话记得给一乐点个赞哦,感谢!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK