

CTR预估之FMs系列模型:FM/FFM/FwFM/FEFM
source link: https://zhuanlan.zhihu.com/p/613030015
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

ctr预估(点击率,click-through rate, CTR),指一个user在某个特定的场景下会点击一个item的概率估计,这里的item可以是广告、商品等,是推荐和广告系统中十分重要的模块。另外,这里的user-item也可以是query-document,即对于一个用户的查询query,一个document会被点击的概率估计,因此,crt预估也是搜索系统的核心。
当然,搜广推系统一般包括召回和排序,ctr预估一般应用于排序阶段。而像推荐系统,一个鲜明的特点就是数据极特别稀疏。下面,我们会持续学习那些针对稀疏数据的ctr任务而提出的模型,这篇文章则主要是关于FM系列。
FM:Factorization Machines
论文:Factorization Machines
地址:https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf
因子分解机FM(Factorization Machines)是2000年Steffen Rendle发表的论文《Factorization Machines》中提出的一种新的模型类型,结合了支持向量机SVM的优点的因子分解模型(Factorization Models),主要解决了以下痛点:
- SVM这类模型无法胜任推荐系统这类数据极其稀疏的任务;
- LR模型在高维稀疏数据下学习十分困难。
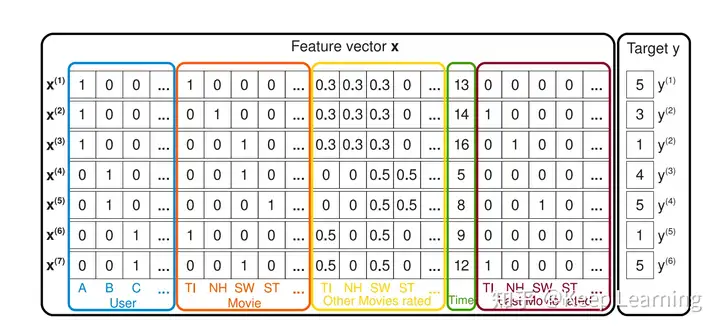
下图是论文中一个关于电影评分系统的数据集样本,符合我们常规的特征处理:
- 对于类别(离散)特征,一般会进行one-hot编码,转化为n维的0/1向量,n为特征值的 unique 数。如下图蓝色的前四列,特征存在三种取值:A、B、C,那么A=[1,0,0],B=[0,1,0],C=[0,0,1];
- 而连续型(数值)特征,则是直接使用,或者进行离散化(区间划分),然后再进行one-hot;
- 而在ctr预估任务中,target y则一般为0或1,1代表点击,0代表未点击。
从这里也可以看出,如前4列蓝色的特征User以及后面5列橙色的特征Movie,由于其存在非常多不同的取值,即特征值的 unique 数很大,因此会导致许多特征列都为0,即上述提到的数据稀疏的特性,这在推荐系统数据集中是很常见的。
在正式进入FM之前,我们简单介绍下逻辑回归-LR(Logistic Regression),是一个经典的机器学习模型,属于线性分类模型,贴合ctr预估这类二分类任务,加上简单、具有解释性和高效,因此早期的推荐系统中经常能够看到LR的身影。
LR的公式如下:
\hat{y}(x):=w_0+\sum_{i=1}^nw_ix_i\\ p(label=1|x)=\frac{1}{1+e^{-\hat{y}(x)}}
(Poly2)考虑加入二阶特征组合之后,LR变为:
\hat{y}(x):=w_0+\sum_{i=1}^nw_ix_i+\sum_{i=1}^n\sum_{j=i+1}^nw_{i,j}x_ix_j
加入组合特征之后,可以提升模型的建模能力,比如对于特征["女性","口红"],点击的概率肯定会比["男性","口红"]的高。其实特征组合也理解为一个新的特征,然后配合一个新的权重。从公式中易知,训练数据中如果x_ix_j=0,即训练数据未出现这对特征组合,那么将无法对权重w_{i,j}进行学习训练,那么在预测时由于这对组合特征的权重为0,相当于无法使用。在推荐系统这种极其稀疏的数据集中,这种情况会变得十分普遍,会导致这种特征组合建模,泛化能力很差。
我们再来看看FM对于二阶特征组合是如何处理,公式如下:
可以看到与LR不同的是二阶交叉特征权重为w_{ij}变为<v_i,v_j>,其中V\in\mathbb{R}^{n \times k},即每个特征变量都会一个对应的k维向量,一般称为隐向量,v_i为第i个变量的隐向量。然后猛然一惊,这其实不就是现在的embedding思想吗,将one-hot的0/1编码映射到向量表征吗?
那么,相对于LR,FM这种对于特征组合进行因子分解的方式有什么优点?由于每个特征都存在自己对应的向量v参数,因此二阶交叉特征不再依赖于训练数据中的特征共现了,比如特征组合x_i\ and\ x_j的权重向量参数v_i\ and\ v_j,仅仅需要训练数据中存在x_i和任意特征的组合、 x_j和任意特征的组合,就可以训练学习自己对应的向量v,那么在预测时,即使是新的组合特征,也能够计算出权重。这使得FM模型的泛化能力大大提升,能够应对推荐系统这类极其稀疏的数据集任务,解决了LR的痛点。
复杂度优化
由于FM要进行二阶的特征组合,从公式上也很容易得出:FM的复杂度是O(kn^2),但由于工业场景下,特征数量n是巨大的,这样的复杂度明显是难以接受的。幸好,FM能够将复杂度优化到O(kn):
FM模型的梯度计算也比较简单,如下式:
可以看到,v_{i,f}的梯度计算是与i无关的,因此这部分是可以直接复用前向传播即计算\hat{y}(x)的结果,也就是预先计算好的,可以认为每个梯度的计算时间都在O(1)。
FFM:Field-aware Factorization Machines
论文:Field-aware Factorization Machines for CTR Prediction
地址:https://www.csie.ntu.edu.tw/~cjlin/papers/ffm.pdf
FFM模型在FM的基础上,对隐向量引入field的区分。field(特征域)和feature(特征值)的区别:field是一类特征,而feature则是具体的特征值。比如性别、学历等等都是field,而feature则表示性别为男、学历为本科。
论文中以广告场景举例,包括三个field:网站(Publisher)三种feature为ESPN, Vogue, and NBC、广告(Advertiser)三种feature为:Nike,
Gucci, and Adidas、性别(Gender)两种feature为Male和Female。对于下面这一个样本:
FM的二阶特征组合计算为:\phi_{FM}=w_{ESPN}\cdot w_{Nike}+w_{ESPN}\cdot w_{Male}+w_{Nike}\cdot w_{Male}
在FM中,每一个feature拥有自己的一个隐向量,来学习与其他feature的隐含关系,以上面的例子,w_{ESPN}就是用来学习ESPN与Nike(w_{ESPN}\cdot w_{Nike})、ESPN与Male(w_{ESPN}\cdot w_{Male})的隐含关系。但是FFM认为Nike和Male属于不同的field,ESPN与它们的隐含关系应该也是不同的,因此FFM模型每个feature都存在f-1个隐向量,f为field的数量,即每个feature与不同field的隐含关系是通过不同的隐向量来学习。具体如下式:
\phi_{FFM}=w_{ESPN,A}\cdot w_{Nike,P}+w_{ESPN,G}\cdot w_{Male,P}+w_{Nike,G}\cdot w_{Male,A}
可以看到,ESPN在学习与Nike的隐含关系时使用的是与Advertiser关联的隐向量w_{ESPN,A},因为Nike是属于广告(Advertiser)这个特征域,而与Male的隐含关系使用的是与Gender关联的隐向量w_{ESPN,G},因为Male是属于性别(Gender)这个特征域。使用数学公式来表达,如下式:
直观点来理解,FM模型每个feature都有一个k维的隐向量(embedding),而FFM模型则是把每个feature的一个k维embedding扩展为f-1个k维的embedding。(因为feature不与自己组合交互)
ctr是一种二分类任务:loss=-log\left[ Sigmoid(\hat{y}) \right]
再加入正则化惩罚项,对于最基础的线性模型LM,最终的loss如下式(FFM也是同样的loss形式,只是把LM替换成FFM):
其中,m为训练样本的数量。论文使用的随机梯度stochastic gradient methods (SG)来学习FFM模型的参数,即每次随机使用一个样本来进行参数的更新。容易得到,FFM的梯度计算如下:
论文在使用梯度更新参数时,使用的是AdaGrad优化算法,即会根据累积梯度来对学习率进行自适应调整:
最终,整个FFM的训练流程如下图:
FFM训练流程
FwFM:Field-weighted Factorization Machines
论文:Field-weighted Factorization Machines for Click-Through Rate Prediction in Display Advertising
地址:https://arxiv.org/pdf/1806.03514.pdf
FwFM模型仍然是在FM的基础上,对feature(特征值) embedding引入field(特征域)的区分。这与FFM的思想是类似的,FFM出发点是一个feature与不同field的feature的隐含关系是不同的,因此每个feature会有f-1个embedding来与不同的field交互,这虽然显著提升了模型的能力,但却带来了参数量的巨大增加。FwFM将会在这个问题上进行优化。
Interaction Strengths
针对上述FM的问题,FwFM从field级别的交互入手,分析来自一个field pair的所有feature pairs与来自另外一个field pair的平均交互强度(interaction strength)是否不同。例如来自广告(ADVERTISER)的feature和来自网站(PUBLISHER)的feature通常存在很强的交互,因为广告的目标往往是一群特定兴趣的用户,并且不同网站的用户自然是按照兴趣分组构成的;另外,来自HOUR_OF_DAY和DAY_OF_WEEK的特征则存在较弱的交互,对是否点击的影响较小。
论文使用以下公式来刻画不同field之间的交互信息(Mutual Information)。两个特征之间的MI计算,简单来理解就是两个特征的共现频率对标签的影响,再加上一个正则来约束过于高的共现特征,这些其实对标签的贡献不大:
new-image-
下图便是不同field之间的交互信息可视化。不出所料,不同field pairs的交互强度差别是十分大的,一些field pairs存在很强的交互,比如(AD_ID, SUBDOMAIN)、(CREATIVE_ID, PAGE_TLD),而有些field pairs的交互则很弱,比如(LAYOUT_ID, GENDER), (DAY_OF_WEEK, AD_POSITION_ID),这个结论也为FwFM的提出奠定了基础。
交互信息热力图
Field权重
根据上述的分析,其实是能够以field级别来进行建模的,FwFM提出另外一种方法去显式地建模不同field之间的不同交互强度:使用权重r_{F(i)F(j)}\in \mathbb{R}来显式地建模field F(i)和field F(j)的交互强度,最终数学表示如下式:
可以看出,FwFM仍然属于是FM的扩展,使用r_{F(i)F(j)}\in \mathbb{R}来刻画不同field对的交互强度,因此,属于field F(i)的所有feature与属于field F(j)的所有feature的交互会共享一个权重r_{F(i)F(j)},参数量比FFM显著下降,特别是feature数量>>field数量的场景,具体的参数量对比如下表:
- FwFMs_LW。在常规的线性项中,使用一个权重w_i来建模feature对label的影响:\sum_{i=1}^mx_iw_i;
- FwFMs_FeLV。论文可能是受二阶特征交互使用的隐向量启发,认为使用embedding向量v_i可以捕获更多的信息,提出使用x_iv_i来表征feature(当然这里每个feature的embedding向量与二阶特征交互时是相同的),相应地,这时模型需要学习便是一个权重向量了,因此线性项则变为:\sum_{i=1}^mx_i<v_i,w_i>,那么此时FwFM模型的参数量变为 2mK+\frac{n(n-1)}{2};
- FwFMs_FiLV。当然,可以很自然的延伸到,同一个field的所有feature可以共享权重,那么线性项则变为:\sum_{i=1}^mx_i<v_i,w_{F(i)}>,此时参数量为mK+nK+\frac{n(n-1)}{2}
不同的线性项方式效果对比如下,可以看到FwFMs_FiLV在测试集表现是最好的:
在同样的参数量下,FwFM模型的效果是最优的。
FEFM:Field-Embedded Factorization Machines
论文:Field-Embedded Factorization Machines for Click-through rate prediction
地址:https://arxiv.org/pdf/2009.09931.pdf
FEFM与FwFM的思想是同属一系列,不同field的feature的交互建模是在field级别,而不是FFM的feature级别,但是FEFM不像FwFM那样显性地去学习特定field的feature embeddings,而是通过一个k \times k的对称矩阵W_{F(i)F(j)}:
new-image-
可以看出,当W_{F(i)F(j)}是一个单位矩阵I时,FEFM就会退化为FM;而当W_{F(i)F(j)}变成一个对角矩阵,且对角线的值为r_{F(i)F(j)},那么FEFM就会退化为FwFM。从这个角度来看,FEFM可以认为是一种泛化能力更强的FM和FwFM。
FM模型为每个特征引入隐向量embeddings,使得模型对二阶特征交互的学习能力大大提升,无需依赖训练样本中的特征组合共现,使得该类模型能够胜任CTR这类高维稀疏数据的任务。
后面的FFM、FwFm和FEFM都对隐向量embeddings介入field(特征域)的区分:
- FFM是将每个特征的一维隐向量embeddings扩展到n-1维,n为field的数目;
- FwFM针对FFM参数量庞大的问题,选择为每一对field创建一个权重;
- FEFM则是为每一对field创建一个k*k维的权重矩阵,进一步提升field pairs间隐含关系的学习能力。
https://github.com/QunBB/DeepLearning/blob/main/Recommendation/RANK/fms.py
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK