

网络爬虫流程总结 - 鹤城
source link: https://www.cnblogs.com/he-cheng/p/17201301.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

网络爬虫的大体流程其实就是解析网页,爬取网页,保存数据。三个方法,就完成了对网页的爬取,并不是很困难。以下是自己对流程的一些理解和总结,如有错误,欢迎指正。
一、解析网页,获取网页源代码
首先,我们要了解我们要爬取的网页,以豆瓣为例,我们要了解模拟浏览器头部信息,来伪装成浏览器。以及爬取的内容是什么,方便我们在后面爬取的过程中用正则表达式匹配内容,以便爬取。
首先我们打开我们需要爬取的网页,f12打开开发者模式,在network中找到发出的请求,获取我们想要的头部信息。
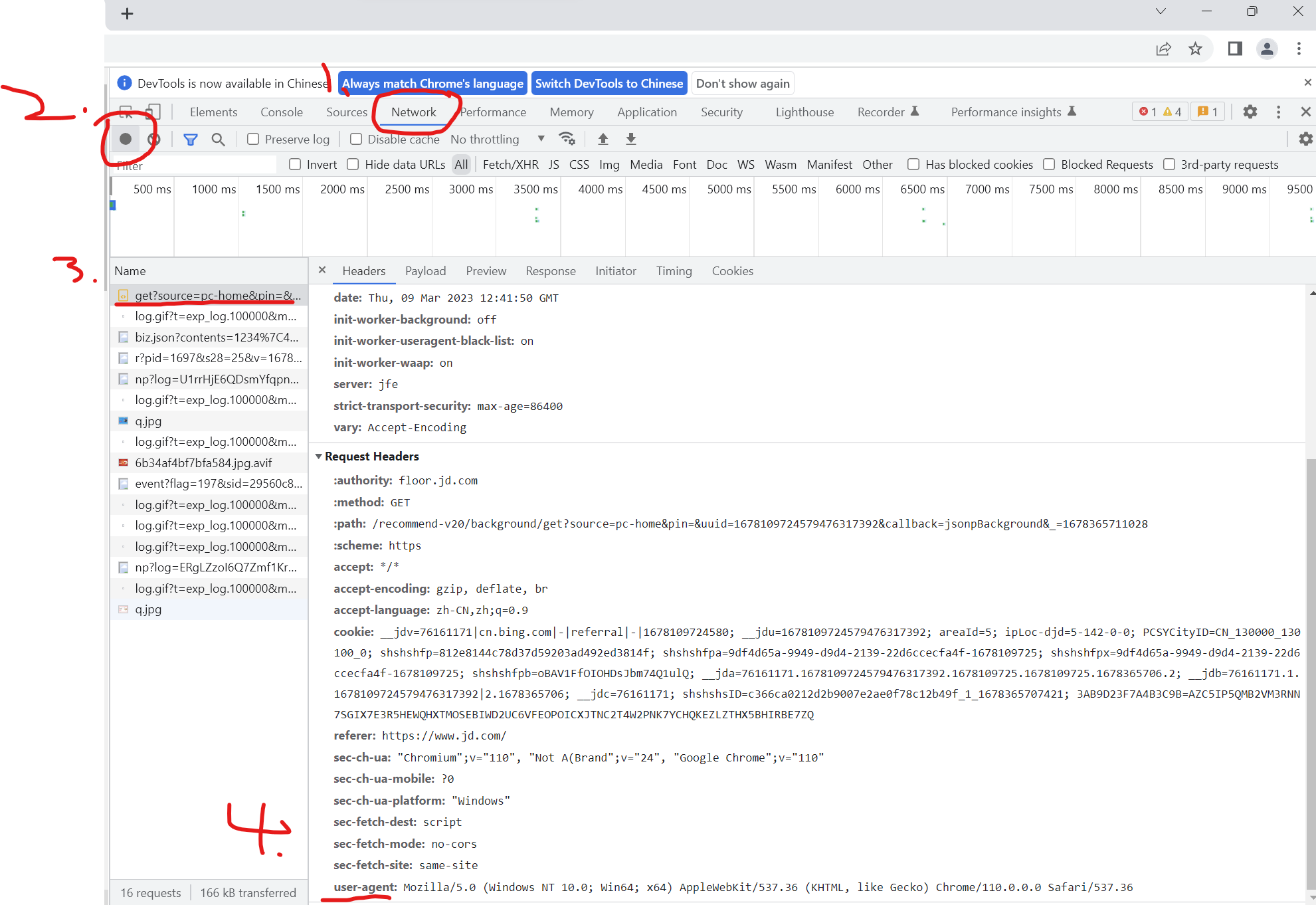
其中模拟浏览器的头部信息我们通常使用urllib库,主要是里面的request类。我们先定义一个对象req,然后获取其中的头部信息,用urllib.request.Request方法对获取的头部信息进行封装并保存到req对象中,代码如下:
req = urllib.request.Request(url=url,data=data,headers=headers,method="POST")
然后再用urllib.request.urlopen获取网页源码,代码如下
response = urllib.request.urlopen(req)
之后再设置一个对象进行存储,代码如下:
html = response.read().decode("utf-8")
总体代码:
import urllib.request
import urllib.parse
url = "http://httpbin.org/post"
data = bytes(urllib.parse.urlencode({"name":"eric"}),encoding='utf-8')
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.50",
"X-Amzn-Trace-Id": "Root=1-63f48078-2f75544f15e5c54a7b905e25"
}
req = urllib.request.Request(url=url,data=data,headers=headers,method="POST")
response = urllib.request.urlopen(req)
#print(response.read().decode("utf-8"))
html = response.read().decode("utf-8")
因为我们爬取的网页不止一页,例如爬取豆瓣影视top250,京东评论,这些都会分页,我们爬取会连续爬取很多页,所以我们通常将这一步设为一个方法askUrl(),用于获取单个指定url网页的内容。另外,有些网页会有相应的防御措施,我们有可能会爬取失败,所以,我们通常会try catch来保证代码能够运行,整体代码如下:
def askUrl(url):
head = { #模拟浏览器头部信息,向豆瓣服务器发送消息
"User-Agent": "Mozilla / 5.0(Linux; Android 6.0; Nexus 5 Build / MRA58N) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 110.0.0.0 Mobile Safari / 537.36 Edg / 110.0.1587.50"
}
#用户代理:告诉豆瓣服务器我们是什么类型的机器、浏览器,本质上是告诉服务器,我们可以接受什么样的文件内容
request = urllib.request.Request(url,headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
另外,我们还要在网页中找到我们需要爬取内容的标签,同样是开发者模式,点击箭头,在网页中选取要爬取的内容,在最下面就能看到所在的标签层次。如下图:
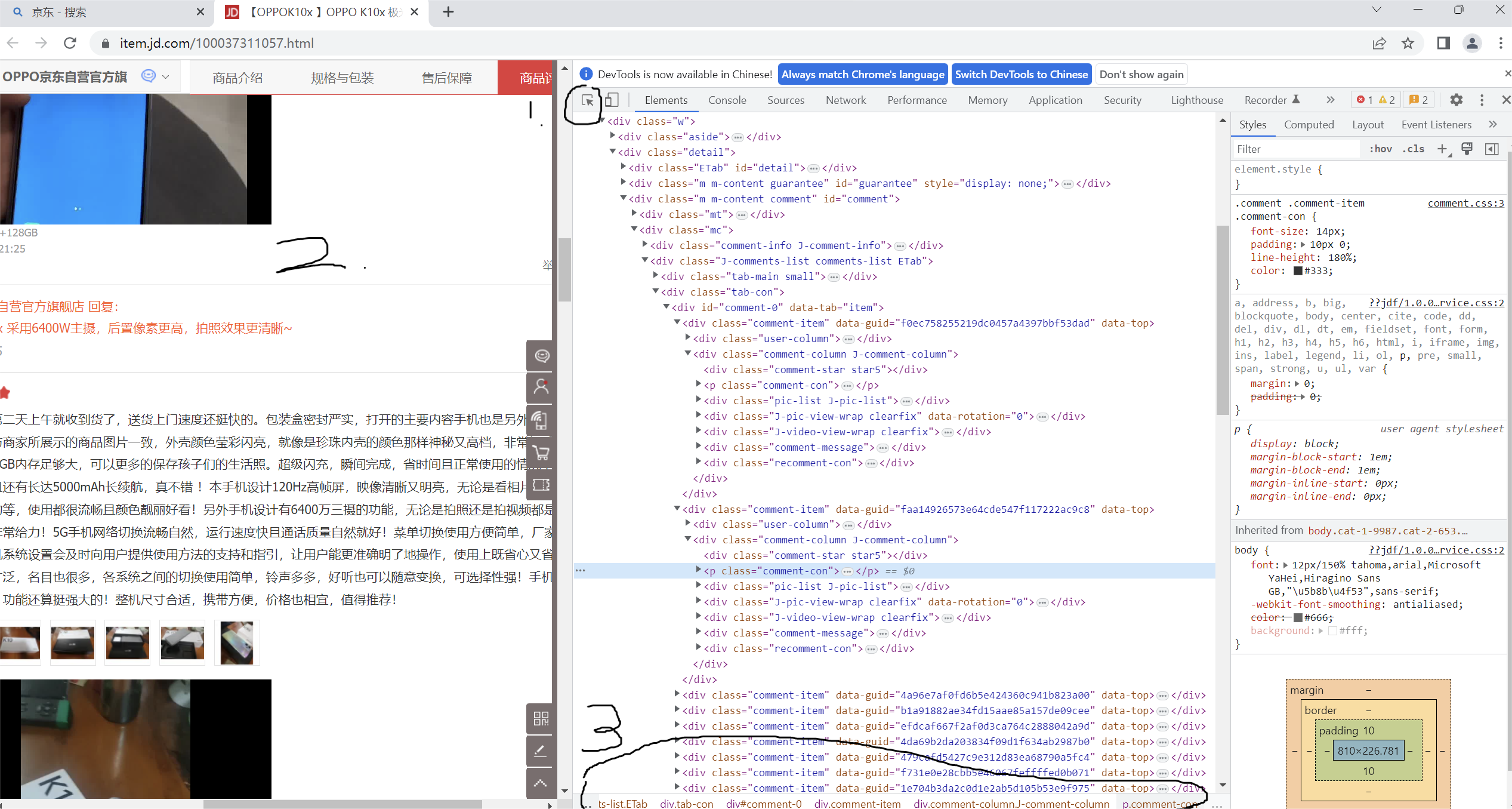
二、爬取网页,解析数据
现在我们有了网页的源代码,但是我们想要的只是网页内容的一部分,这时我们就需要解析网页的数据,利用正则表达式匹配我们想要的内容,并将其存储下来。这时我们主要用到bs4中的BeautifulSoup库。我们首先定义一个对象soup,利用BeautifulSoup解析我们上一步获得的网页源代码,并存储在soup中,代码如下:
soup = BeautifulSoup(html,"html.parser")
随后我们利用findall方法,查找符合要求的字符串。因为网页大多是一个个div的组合,而且爬取的第一页和之后的页数都有一定的共性,所以我们直接for循环来爬取。这个时候就要我们自己上一步找所在的标签了。这里我用爬取豆瓣举例,我先定义变量,再利用compile方法获取想要内容的正则表达式并存储在变量中。
#影片详情的规则
findLink = re.compile(r'<a href="(.*?)"')
又因为爬取的内容比较多,所以我们设置getData方法,在方法中我们先定义一个列表,用来存储我们爬取的数据,然后爬取一页数据,放到for循环中爬取需要的页数。
#影片详情的规则
findLink = re.compile(r'<a href="(.*?)"')
#影片图片的规则
findImgSrc = re.compile(r'<img.*src="(.*?)"',re.S)
def getData(baseurl):
datalist = []
for i in range(0,10):
url = baseurl + str(i * 25)
html = askUrl(url)
# 2.逐一解析数据
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all("div",class_ = "item"): #查找符合要求的字符串,形成列表
# print(item) #测试:查看电影item全部信息
# break
data = []
item = str(item)
#影片详情的链接
link = re.findall(findLink,item)[0] #re库通过正则表达式查找指定的字符串
data.append(link) #添加链接
imgSrc = re.findall(findImgSrc,item)[0]
data.append(imgSrc) #添加图片
datalist.append(data) #把处理好的一部电影信息放入dataList
# print(datalist)
return datalist
这里嵌套了for循环语句,实战中如何嵌套来爬取需要的内容我认为是个难点,这里需要我们多注意,多思考。
三、保存数据
我们可以将数据保存到excel和数据库中,我以excel来举例,其实都是大同小异。其中excel需要xwlt库,我们先创建workbook对象,再利用其创建工作表:
workbook = xlwt.Workbook(encoding="utf-8",style_compression=0)
worksheet = workbook.add_sheet("豆瓣电影top250",cell_overwrite_ok=True)
然后我们在工作表中写入数据:
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
for i in range(0,8):
worksheet.write(0,i,col[i]) #列名
for i in range(0,250):
print("第%d条"%(i+1))
data = datalist[i]
for j in range(0,8):
worksheet.write(i+1,j,data[j])
这边需要注意的是,如果存储到数据库中,将内容转换切割又是一个难点,也需要我们多注意,多思考。之后我们保存数据表即可:
workbook.save(savepath)
通常我们把保存数据单独写成一个方法,方便代码观看和重用。
我们在main方法中运行前面三个方法即可,我们就爬取了我们想要的内容。爬取的流程并不难理解,其中的难点在于对爬取内容的处理,例如如何找到爬取内容,如何匹配,如何分割存储。另外想要看源代码的可以看我这一篇博客:
手把手教你网络爬虫(爬取豆瓣电影top250,附带源代码)
两篇博客一起学习分析,才能更好的理解掌握,如果对代码中用的方法不理解,可以看我分类中python+爬虫学习的模块,里面记录了我学习的过程和代码讲解。还有我学习是看的b站课程:
Python课程天花板,Python入门+Python爬虫+Python数据分析5天项目实操/Python基础.Python教程,老师讲的比我的博客要细致很多,我的博客只是自己的总结理解,与大家交流学习。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK