

你需要同款“Unreal项目自动化编译、打包和部署”方案吗?
source link: https://blog.uwa4d.com/archives/UWAPPLcase4.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

在过往几期的UWA Pipeline最佳实践案例中,我们分享了如何通过Pipeline实现性能优化、性能管理、游戏内容验收和云真机系统的应用(实现批量真机设备的自动化测试,以及针对特效性能优化的方式),其实这些高效的方法并不局限游戏引擎。今天,分享一篇来自广州钛壳树的UWA Pipeline使用心得,这是一家致力于创造独特原创IP、专注Unreal研发的游戏公司,看看UWA Pipeline如何帮助Unreal研发团队达到如虎添翼的效果。
常态化的引擎自动化编译、客户端自动打包、服务器持续部署,这是钛壳树团队在Unreal项目研发的过程中,使用UWA Pipeline实现的三大功能,大幅简化了工作流程,节省了人力与时间,提高了CI/CD的执行效率。以下分享出自钛壳树团队CEO的自述,详细介绍了具体实现的思路和方式,供广大有类似需求的Unreal团队参考。
一、Unreal引擎自动编译的实现
我们使用Windows作为流水线节点,通过流水线的简单操作,快速有效地实现不同的构建需求;通常UE引擎都有比较严格的运行环境和编译条件,借助流水线和联合编译IncrediBuild能极大提高构建效率,降低构建复杂度,减少人工干预的次数。
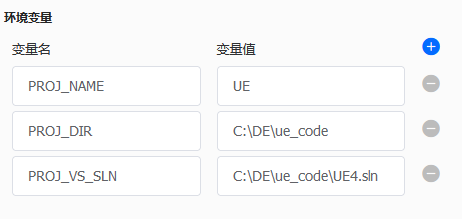
研发过程中修改Unreal引擎源码是必不可少的。获取源码后,除了有利于理解引擎的运行机制和方便调试,更多的是可以对引擎进行个性化定制,从而增强项目的游戏效果和可玩性。在构建流水线之前,大家可以通过Pipeline设置中的环境变量,来预设工作目录和工程路径,方便在后续的步骤中调用。
我们的引擎编译流水线如下图所示,主要包括“Init”、“UpdateRepos”、“BuildAndCook” 和“CommitRepos”四个阶段。

每个阶段的具体作用为:
第一阶段 Init
确保编译环境干净、当前任务独占相关资源。如此运算力资源能够充分利用,并且可以避免资源占用冲突导致的报错。我们的做法是:初始化环境、确保没有手动打开的编译进程。同时将节点的并发构建数量设置为1,确保不会有多个任务并发执行。
第二阶段 UpdateRepos
进入预设的工作目录,通过Git和凭证管理,更新位于内部Gitlab的引擎源码ue_tree。
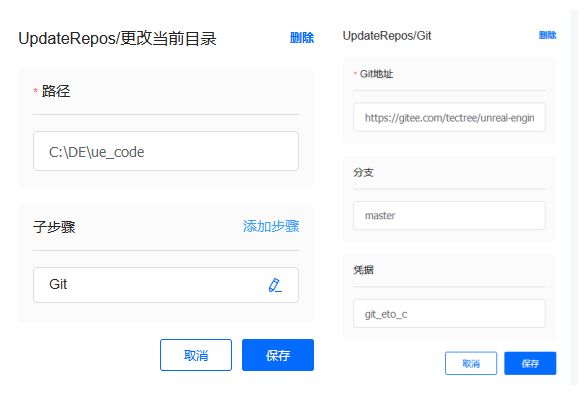
第三阶段 BuildAndCook
编译引擎。进入工作目录调用VisualStudio编译命令,对引擎工程进行命令行编译,对应的批处理脚本如下:

通常编译引擎会占用很多CPU算力资源,需要花费很长时间才能完成编译,所以非必要情况下不执行Rebuild操作。我们在这里通过Pipeline的参数化构建功能,在流水线上设定选项参数,提供多种编译方式(Build和Rebuild),在执行时,就可以将参数传递给编译器以明确编译模式。

第四阶段 CommitRepos
把最新的引擎提交到SVN,用于接下来的开发任务。引擎编译后会生成若干目录,其中包含引擎运行所需的DLL、执行程序以及中间文件。这里大家需要区分中间文件的内容,避免把不必要的文件上传到SVN仓库中。
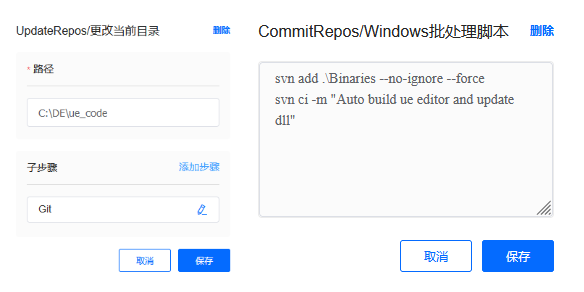
二、Unreal客户端自动打包的实现
完成引擎编译后,接下来就是对游戏客户端进行编译打包。日常的持续构建,能够方便我们随时跟进游戏研发进度,体验游戏的特性和玩法。Unreal客户端打包时,大家需要注意引擎版本的使用,将官方版本和自定义版本区别开,以免效果不符合预期。
我们的打包流水线如下图所示,主要包括“Init”、“UpdateRepos”、“StartBuild”、“BuildAndCook”和“Commit”五个阶段。

每个阶段的具体作用为:
第一阶段 Init
与编译引擎的处理方式一致,确保任务独占编译资源,保证后续步骤顺利进行。
第二阶段 UpdateRepos
获取最新的代码和资源。游戏客户端除了涉及开发代码和脚本外,还需要有数据资源,包括蓝图、配置数据、材质、模型、场景等等。其中代码和脚本使用Gitlab管理,数据资源使用SVN管理。
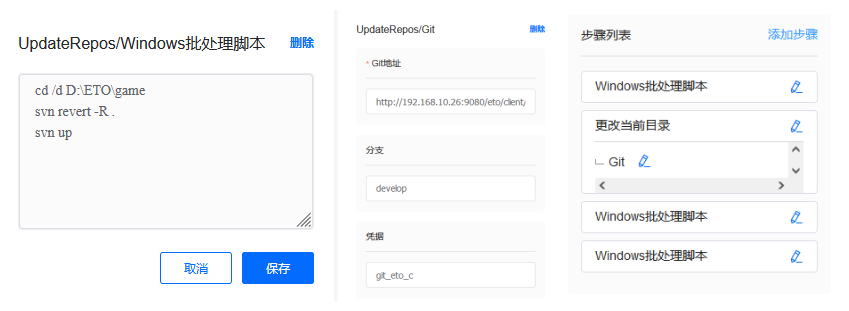
在打包的时候,大家需要再创建一个新的工作目录,把最新获取的代码和资源都拷贝到工作目录中,进行独立编译。
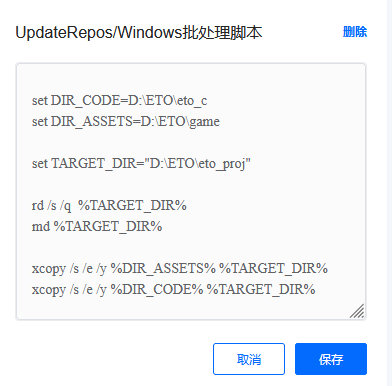
第三阶段 StartBuild
执行编译前的准备工作。
设定工程使用的引擎版本,在开发时是通过右键菜单进行选择,在流水线中则使用VersionSelector.exe命令处理。

选择引擎后需要对工程生成对应的编译工具,包括:UnrealPak、Bootstrap、CrashReport以及工程,命令如下。

第四阶段 BuildAndCook
将游戏工程生成最终能运行的程序或安装包。其中,Build执行的是针对所选平台编译二进制可执行文件;Cook是针对目标平台,将所引用的资源转换成对应的运行时格式。开始构建前,预设生成目标路径和中间目录,确保生成后的目录有效,给予下阶段使用。
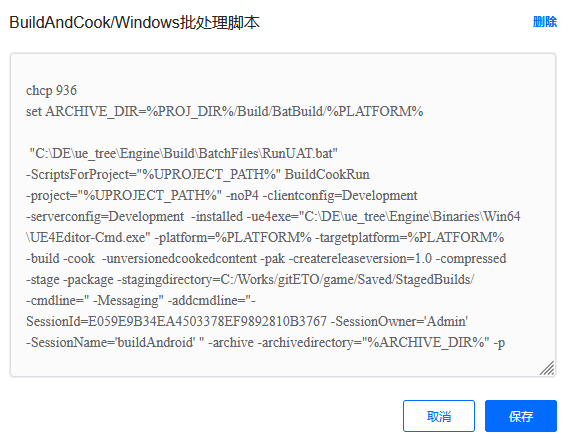
第五阶段 Commit
提交构建结果到云空间。我们在开发阶段不管是手动还是每天自动构建,都会按照日期存放到公司内部的云空间中,方便开发人员获取和验证。
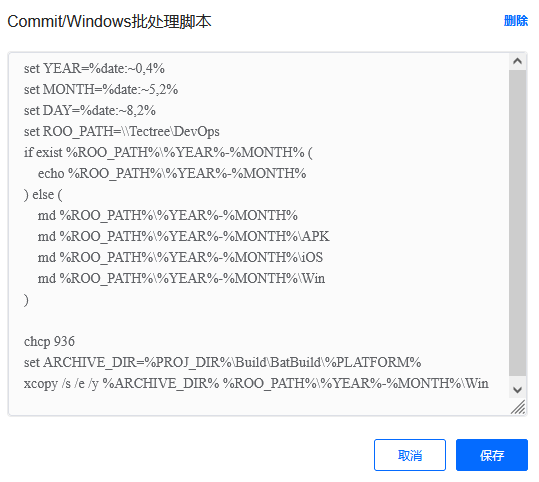
结合Gitlab实现提交时触发构建
UWA Pipeline提供了远程构建功能,激活流水线设置中的远程构建,流水线会生成一个URL地址,我们通过不同的参数配置触发流水线中对应的编译模式,达到和手动选择参数一样的效果。
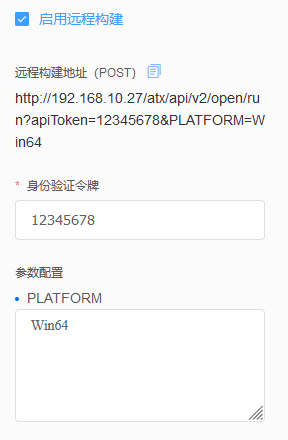
通过Gitlab的Webhooks填写对应的URL地址,通常在代码仓库PR时,就可以自动触发流水线运行,从而加快构建和部署的频率,提高开发效率。

三、服务器持续部署的实现
我们使用Linux作为流水线的节点,用于内部游戏服务的自动构建和部署,实现持续集成。
游戏服务是一个组件集群,涉及到多个进程和依赖,为了提高构建速度、降低部署复杂度,通常支持一键部署。同时为了保证构建任务的互斥和步骤顺序的正确,建议大家将节点的并发构建数设为1。同时,至于针对不同测试目的,需要在同一个节点进行持续集成。这就需要通过服务隔离、运行端口分配、第三方组件和使用容器部署等方式,实现多份服务进程的部署。
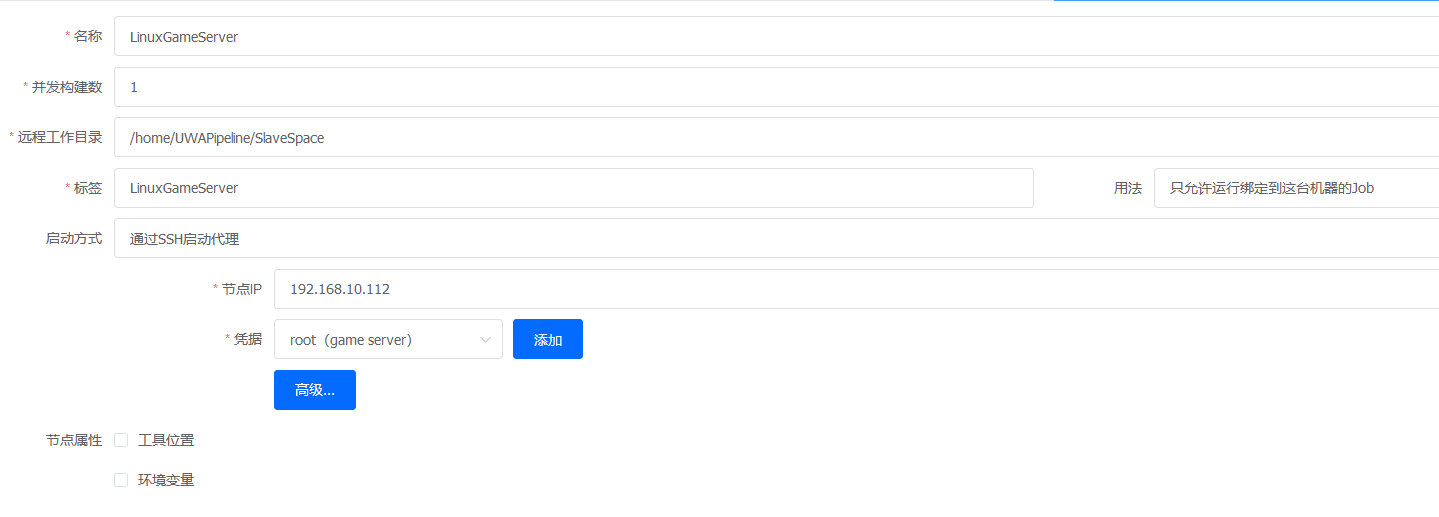
Pipeline系统设置-阶段管理-阶段设置内
可以配置节点的并发构建数,限制节点上能运行的任务数量
在单机部署测试环境中,将Linux作为流水线运行的节点时,还需要大家提前配置相关的数据库、缓存以及游戏服务所需的运行环境,我们可以通过容器方式实现快速配置。
我们的服务器部署流水线如下图所示,主要包括“Update”、“Build”和“Reboot”三个阶段。

每个阶段的具体作用为:
第一阶段 Update
从内部Gitlab拉取最新代码(C/C++、Lua)和资源配置(Lua、JSON)。通过使用流水线提供的凭证管理和Git组件,在预设的工作目录中获得最新的代码和资源。
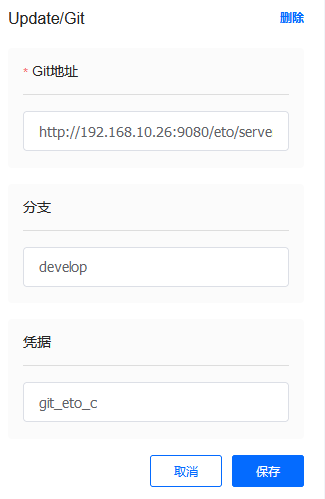
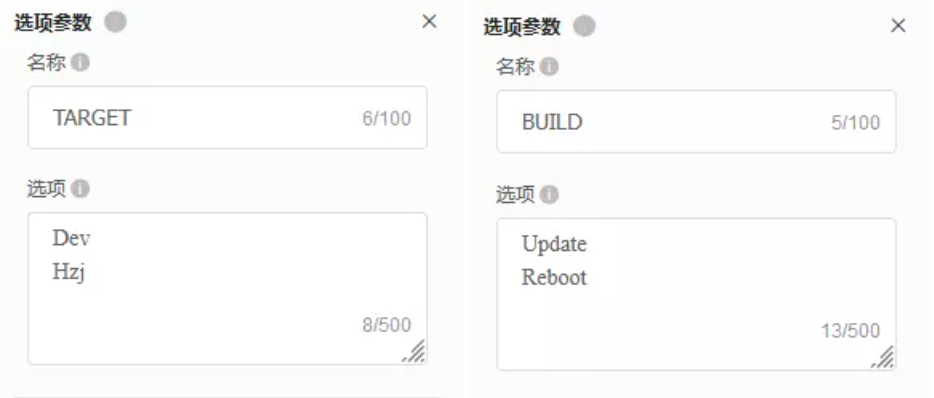
我们在构建之前,通过Pipeline流水线设置,添加了选项参数或文本参数,设置版本目标和操作类型,方便后续在执行部署时能够根据需求进行构建。
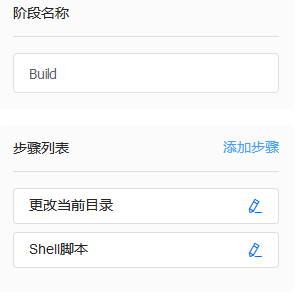
第二阶段 Build
进入工程目录,编译Framework、依赖库和游戏代码,生成so文件和脚本文件。
第三阶段 Reboot
根据预设的目标参数,从编译工作目录中把执行程序、so文件、脚本复制到目标运行目录,停止运行过程中的游戏服务并重启。
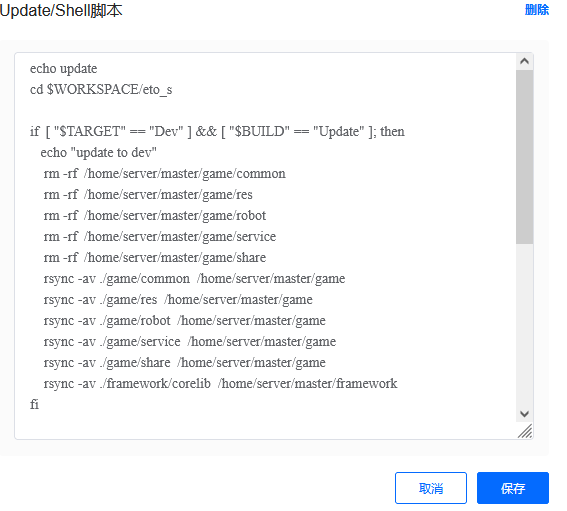
定时构建
通过Pipeline提供的自动构建方式,设定好构建触发器,根据需求设定自动构建的频率,就可以在无人值守的情况下,实现流水线的定时自动构建。我们现阶段的服务器构建仅限用于内部测试服使用,固定是每天构建一次。
感谢钛壳树团队的精心分享,有相同需求的Unreal团队都可以参考和借鉴。如果你被这个团队CEO的能力和态度所打动,愿意加入广州钛壳树的话,现开放UE4引擎开发工程师、UE4特效设计师等岗位,小编也非常乐意为你引荐。再次感谢钛壳树团队对UWA的认可,在游戏行业工业化发展的路上我们又共同迈进了一步。
更多UWA Pipeline使用案例分享可以查看:
《乐享元游的 UWA Pipeline 最佳实践分享》
《一款ARPG游戏是如何搭建云真机系统的》
《再也不用焦虑特效造成的性能问题了》
想要实际体验UWA Pipeline?请点击《免费试用 |UWA性能保障体系全体验》,15天Pipeline全服务试用就在眼前!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK