

让人既好奇又害怕的ChatGPT
source link: https://www.woshipm.com/ai/5397837.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

让人既好奇又害怕的ChatGPT
对于ChatGPT的出现及火爆,你的感受是什么呢?本文作者的心情是“好奇又害怕”。为什么ChatGPT能引起如此大的震动呢?以后会对人类产生什么影响?本文作者从ChatGPT的相关概念、背后的技术、商业前景,对ChatGPT进行了分析,并分享了自己的一些观点,一起来看一下吧。

作为人工智能从业者,笔者对ChatGPT进行了较深入的研究。
在研究ChatGPT的过程中,笔者始终有一种复杂的心情。静心思考,这种心情大概可以用“好奇又害怕”来形容。
好奇的是ChatGPT这样一个强大的聊天机器人是怎么实现的,同时其展现的强大能力又让笔者感到一丝害怕和担忧——奇点是不是到了?
在此将研究笔记成文一篇,同各位读者分享这份既好奇又害怕的心情。
本文将分成五个部分论述:
- ChatGPT相关历史和概念的概述
- 从产品经理角度看ChatGPT背后的技术
- 为什么ChatGPT能引起如此巨大的震动
- ChatGPT的商业前景
- 个人调研的一些观点,仅供参考
一、概况介绍
ChatGPT是美国人工智能研究公司OpenAI研发的聊天机器人程序。其于2022年11月30日发布之后,迅速引爆了互联网。
ChatGPT一经发布,用户数便一路飙升,5天内便涌入了100万用户,两个月用户总数便突破了一个亿。这个速度有多疯狂呢?我们不妨直观对比一下知名产品用户突破一个亿的时间:
- 手机:16年
- 支付宝:4年
- 微信:1.5年
- TikTok:9个月
- ChatGPT:2个月
毕竟谁能拒绝调戏一个聪明的人工智能机器人呢?笔者从12月5日注册以来,对与ChatGPT对话这件事可谓乐此不疲。
ChatGPT是基于大型语言模型(LLM)的聊天机器人。那么,ChatGPT究竟具备哪些能力呢?
- 语言理解:理解用户输入的句子的含义。
- 世界知识:指的是人对特定事件的亲身体验的理解和记忆,包括事实性知识 (factual knowledge) 和常识 (commonsense)。
- 语言生成:遵循提示词(prompt),然后生成补全提示词的句子 (completion)。这也是今天人类与语言模型最普遍的交互方式。
- 上下文学习:遵循给定任务的几个示例,然后为新的测试用例生成解决方案。
- 思维链:思维链是一种离散式提示学习,在大模型下的上下文学习中增加思考过程。
- 代码理解和代码生成:具有解读和生产代码的能力。
基于这些功能,ChatGPT最终表现出我们在聊天时体验到的强大能力。
ChatGPT对出现并不是一蹴而就的,其背后的发展时间线如下。
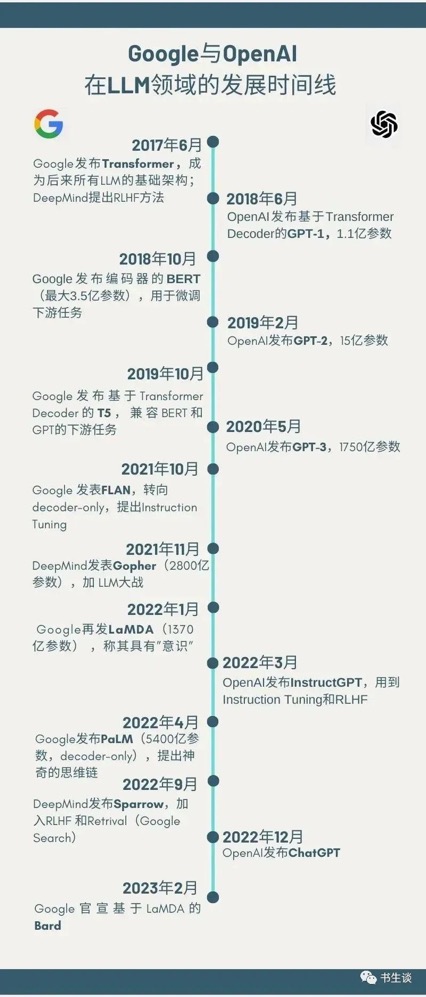
大体来说,ChatGPT是在Google和OpenAI在大型语言模型(LLM)领域不断竞争中结出的一颗硕果。
二、技术知识
ChatGPT使用的大型语言模型(LLM)诞生也不是一番风顺的。从深度学习发展前10年的历程来看,模型精度提升,主要依赖网络在结构上的变革。
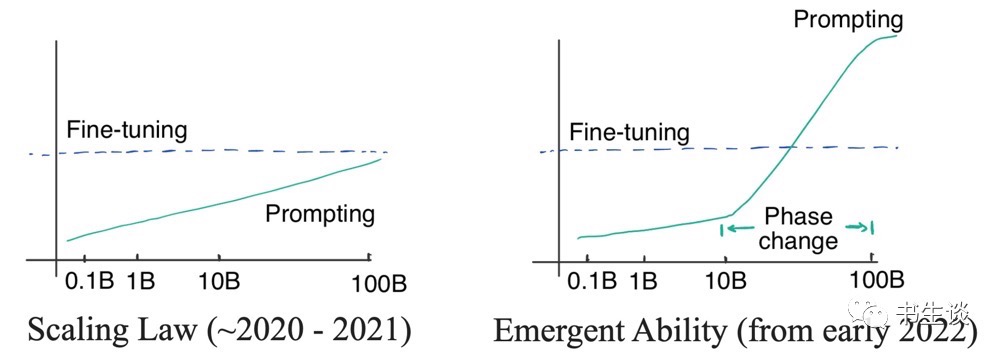
由于语言模型的缩放定律的现象(模型尺寸呈指数增长时,性能会随之线性增加),(OpenAI)的研究者也发现即便最大的 GPT-3 在有提示的情况下也不能胜过小模型精调。所以当时并没有必要去使用昂贵的大模型。
(出处:https://www.notion.so/514f4e63918749398a1a8a4c660e0d5b)
但是,随着神经网络结构设计技术,逐渐成熟并趋于收敛,想要通过优化神经网络结构从而打破精度局限非常困难。近年来,随着数据规模和模型规模的不断增大,模型精度也得到了进一步提升,研究实验表明,当模型尺寸足够大时,性能会显著提高并明显超越比例曲线。
简而言之,当模型参数增加到一定程度,就会涌现出远超小模型的强大能力。
因此大规模预训练模型得到了迅速地发展,尤其在NLP领域。
大模型的规模有多大呢?
2018年谷歌发布了拥有3亿参数的BERT预训练模型,正式开启AI的大模型时代。到 19年T5(谷歌)110亿,20年GPT-3(OpenAI)750亿,21 年GLaM(谷歌)1.2万亿,M6-10T(阿里达摩院)参数量甚至已经达到 10 万亿。
大型语言模型(LLM)背后涉及的技术过于复杂,笔者只是了解了个大概,后面介绍几个印象非常深刻的技术点。
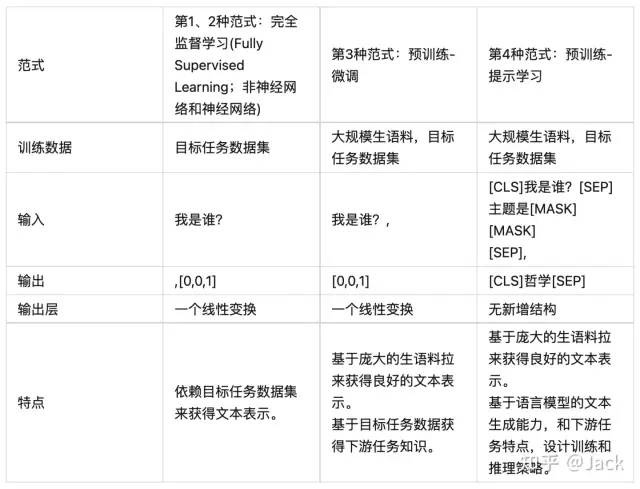
1. 提示学习(Prompt Learning)
提示学习(Prompt Learning)是一个NLP界最近兴起的学科,能够通过在输入中添加一个提示词(Prompt),使得预训练模型的性能大幅提高。
目前大家听到的深度学习、大型语言模型(LLM)等概念,本质上都是一种模仿人类神经系统的神经网络模型。神经网络由多层处理单元(类比人的神经元)组成,上一层的输出作为下一层的带权重的输入参数,不同的信息输入,经过网络处理就可能得到各自的结果。
把我们自己比作处理单元,那么我们可能同时接收到来自不同人的请求,如老婆、父母、孩子,不同人对我们的影响力是不同的,即来自不同人的指令是带有权重的,我们对所有的请求进行综合权衡,然后得到一个结论。比如对于一个妻管炎来说,可能老婆的意见会起到决定性的作用。
网络参数是由训练数据决定的。就如同我们过往的经历决定了不同人对我们的影响力。再用妻管炎举例,就是其老婆过往严厉的管教,导致他倾向于更服从老婆的意见。
使用一个神经网络更省事的方法就是用现成的(预训练模型),再根据自己的需要微调,即前文提到模型精调。Fine-tuning就是其中非常有效的方法,即冻结预训练模型的部分网络层(通常是靠近输入的多数网络层),训练剩下的网络层(通常是靠近输出的部分网络层)。
Fine-tuning的本质还是改变网络参数。但是大模型的规模不断增大,其需要调整的参数也会急剧膨胀。于是人工智能科学家就提出了一种更有效调整大模型的方法:Prompting。
Prompting的方法非常简单,其不会改变预训练模型的任何参数,只是为模型提供一定量的提示(prompt),然后就可以提升大模型的能力。就像给一个妻管炎的人看几个不是妻管严的人的一些故事,然后他就可以摆脱妻管炎的情况了。
我们可以看到对于大型语言模型(LLM)来说,Prompting具有巨大的优势,其避免了对大量进行微调参数的工作量,也不需要传统方法依赖的专业的语料标注(分词、词性、情感等),把相关的人类自然语料提示给模型即可。
(出处:https://zhuanlan.zhihu.com/p/406291495)
2. GPT的标注方法
ChatGPT的标注方法使用了基于人类反馈的强化学习的指令微调(RLHF),其官网给出的标注过程如下。
根据论文《Training language models to follow instructionswith human feedback》解释,其过程大致如下:
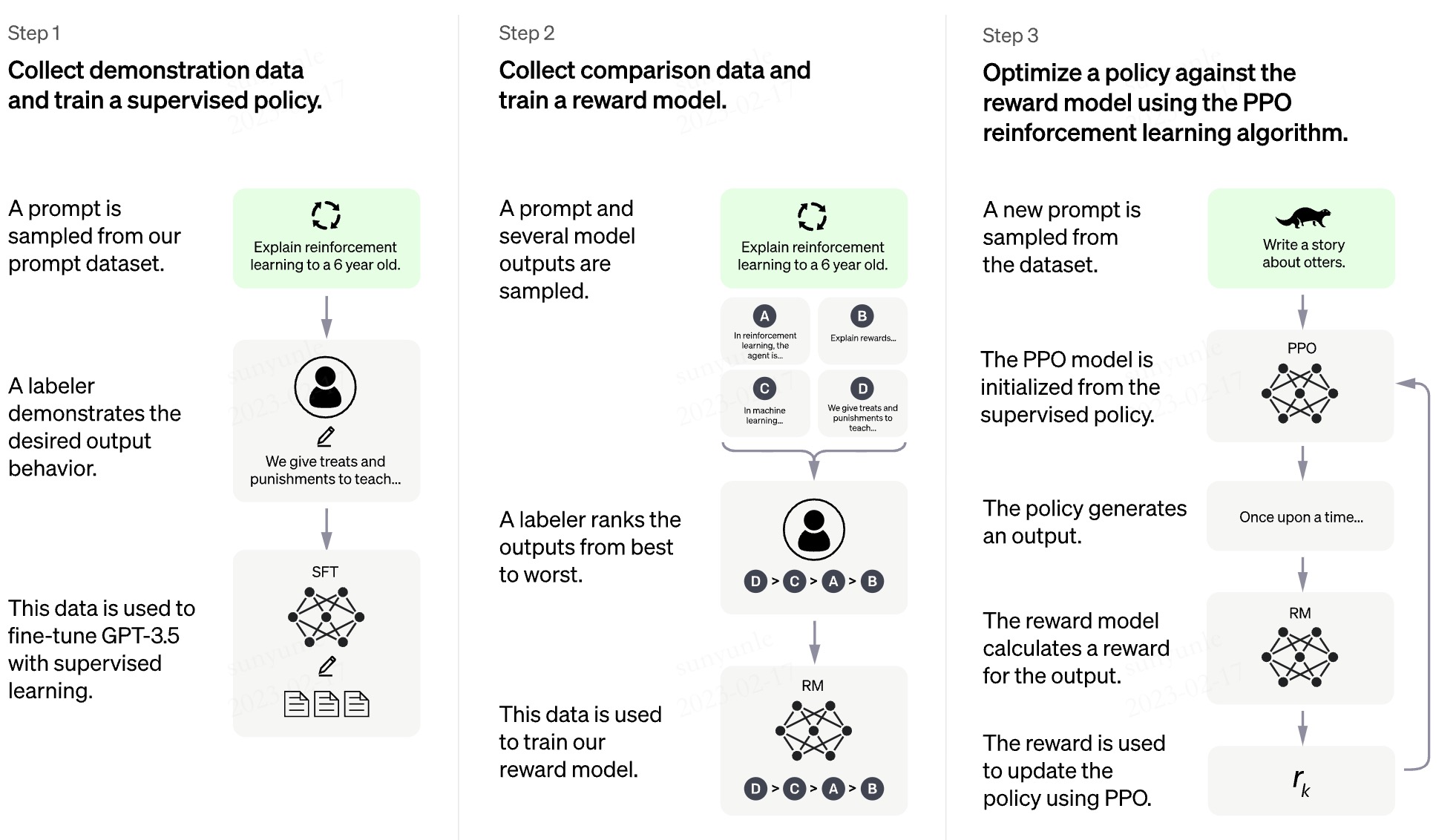
第 1 步:收集演示数据,并训练监督策略。我们的标注者提供了输入提示分布上所需的示范(提出多样化随机的任务,有多个匹配响应的指令,基于用户的提示)。然后,我们使用监督学习对该数据微调预训练的 GPT-3 模型。
第 2 步:收集对比数据,训练奖励模型(RM)。我们收集了模型输出之间比较的数据集,其中标注着指出他们更喜欢的给定输入的输出。然后我们训练奖励模型来预测人类偏好的输出。
第 3 步:使用 PPO(概率加权随机策略搜索)对抗奖励模型以优化策略。我们使用 RM 的输出作为标量奖励。我们使用 PPO 算法微调监督策略以优化此奖励。
步骤2和步骤3可以不断迭代;收集当前最佳策略的更多比较数据,用于训练新的 RM,然后训练新的策略。在实践中,我们的大部分比较数据来自我们的有监督策略,也有一些来自我们的 PPO 策略。
大致就是训练了两个模型,并使用强化学习的方法。一个是用于优化训练的奖励模型(RM),该模型是经过人工调教的,更懂人的期望输出;另一个是目标模型。将目标模型的输出结果输入到奖励模型(RM),然后告诉目标模型你这个结果是否符合预期,以调整目标模型。然后不断优化奖励模型(RM),再训练模板模型。
翻译成人话就是训练一个更了解人的老师模型,然后去教育学生模型,对了就表扬,错了就打板子。学生水平接近老师后,就再提升老师的能力,继续重复对学生的教育过程……如此往复就得到了一个非常了解人的学生模型。
据说OpenAI雇佣了40人团队完成RLHF的标注工作。最近外媒爆出一个劲爆消息,称“ChatGPT背后的“血汗工厂”:最低时薪仅1.32美元,9小时至多标注20万个单词,有员工遭受持久心理创伤。”
3. 基于思维链的复杂推理
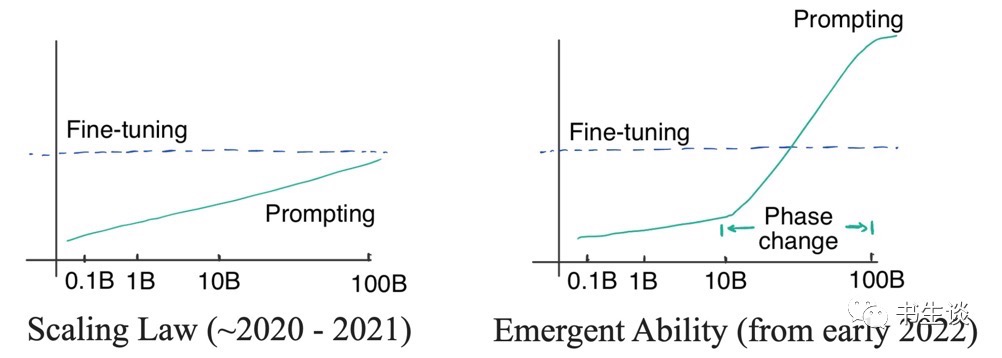
笔者通过阅读符尧博士的相关文章,意识到思维链推理是是非常重要的功能,其被认为是一种重要的范式转移。思维链提示在性能-比例曲线中表现出明显的相变。当模型尺寸足够大时,性能会显著提高并明显超越比例曲线。
(出处:https://www.notion.so/514f4e63918749398a1a8a4c660e0d5b)
当使用思维链进行提示时,大模型在复杂推理上的表现明显优于微调,在知识推理上的表现也很有竞争力,并且分布鲁棒性也存在一定的潜力。要达到这样的效果只需要8个左右的示例,这就是为什么范式可能会转变。
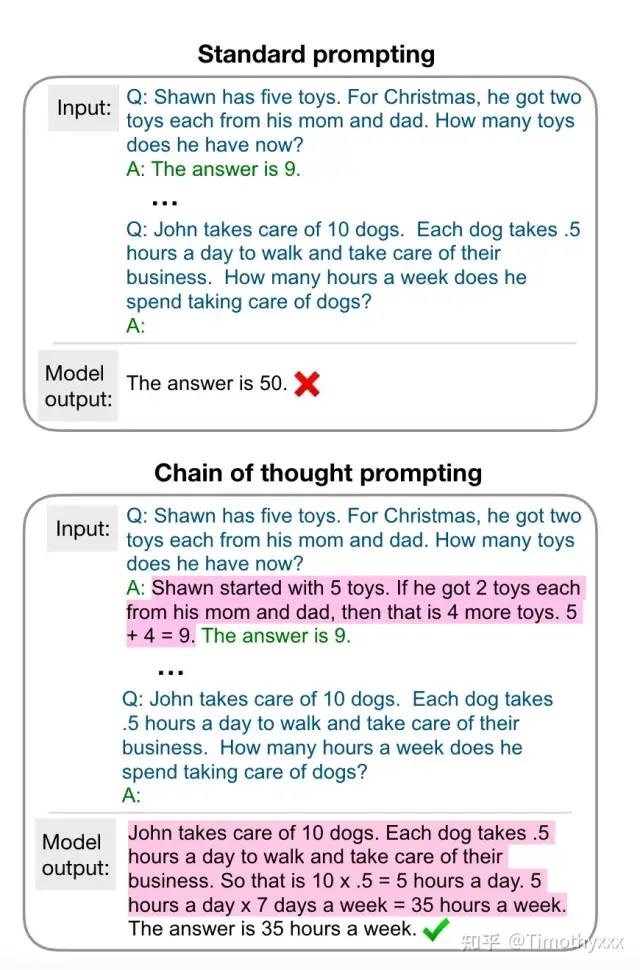
什么是思维链呢?
思维链是一种离散式提示学习,在大模型下的上下文学习中增加思考过程。相比于之前传统的上下文学习,思维链多了中间的一些推理过程,以下面这张图为例子:
(出处:https://zhuanlan.zhihu.com/p/493533589)
那么模型规模达到多大,思维链会出现明显的相变呢?两个数字:62B 和 175B。
- 模型至少需要62B,使思维链的效果才能大于标准的提示词方法。
- 模型至少需要175B(GPT3的尺寸),思维链的效果才能大于精调小模型(T5 11B)的效果。
思维链是怎么出现的?
根据符尧博士的观点,使用思维链进行复杂推理的能力很可能是代码训练的一个神奇的副产物。有以下的事实作为一些支持:
- 最初的 GPT-3 没有接受过代码训练,它不能做思维链。其中有的模型虽然经过了指令微调,但相关论文报告说,它的它思维链推理的能力非常弱 —— 所以指令微调可能不是思维链存在的原因。
- PaLM 有 5% 的代码训练数据,可以做思维链。
- GPT-3用159G的代码数据量训练后,得到的模型及其后续变体可以做思维链推理。
- 在 HELM 测试中,Liang et al. (2022) 对不同模型进行了大规模评估。他们发现了针对代码训练的模型具有很强的语言推理能力。
- 直觉来说,面向过程的编程跟人类逐步解决任务的过程很类似,面向对象编程 跟人类将复杂任务分解为多个简单任务的过程很类似。
以上所有观察结果都是代码与思维链推理之间的相关性,但不一定是因果性。需要后续更深入的研究揭示。
总之,以ChatGPT为代表的大型语言模型(LLM)在技术层面出现了很多令人振奋的结果。
三、为何引起如此震动
1. 有趣而令人担忧
作为普通的用户可以发现基于大型语言模型(LLM)ChatGPT有极大的不同,简单来它能力极其强大,且太像人了,跟他聊天的时候经常会产生在与一个真人聊天的错觉。
它能聊天、写专业的文章、解答非常复杂的问题、理解文字内容、写代码、查bug、帮人制定计划、甚至给出合理的人生建议,感觉其上天入地,无所不能。
其对人类语言的理解能力,聊天(多轮对话)上下文的连贯能力,对感情、哲学等人文思想的理解,都让人叹为观止。
正因为如此,笔者在整个研究过程中会持续被既好奇又害怕的情绪困扰着,时而为如此强大技术的应用前景振奋不已,时而又为人类的未来感到忧虑和产生生而为人的无力感。
笔者想,这也是大家如此热衷于调戏它并且乐于传播的原因:愚弄笨蛋难以有成就感,只有愚弄聪明人才值得炫耀。
类似的聊天大家应该或亲身体验过,或看过别人聊天的截图,不知是否有类似的感受?
因此短短两个月就能突破1亿用户,也就不足为奇了。
2. 技术与商业两开花
所谓“科技是第一生产力”,更重要的是技术层面影响。从上文介绍我们可以看大型语言模型(LLM)在技术上的巨大突破:
- 当模型达到一定规模时,涌现了思维链的能力,突破了语言模型的缩放规律。思想链提示的性能明显优于其之前的精调方法。
- 基于人类反馈的强化学习的指令微调触发了诸多新的能力,比如翔实的回应、公正的回应、拒绝不当问题、拒绝其知识范围之外的问题。
- 为人工智能模型性能提升开辟了新的康庄大道。影响其模型性能的关键在于模型规模和提示(prompt)的有效性。
- 扩大模型规模要远比网络在结构上的变革轻松,从上文模型规模的发展可以看出,短短4、5年的时间,模型规模就从3亿飙升到了10万亿,后者是前者的3万多倍!
- 提示(prompt)的学习方式也具备巨大的优点。其数量要求不多,且无需结构化的数据标注。
这些技术突破意味着,不仅人工智能的能力将得到极大突破,商业也将变得更加简单:想要部署、应用大型语言模型(LLM)的公司,都能够比较轻松地完成对模型的调教,以适配自己的业务。
3. 开启未来的钥匙
ChatGPT所代表的大模型,可能是实现通用人工智能(GAI)的可行性路径。
信息科学这门学科在20世纪40年代诞生以后,在当时人们看见的蓝图里,不仅是根据人类预设的指令和程序,快速地传递、计算和处理人类无法想象的天量数据,而是不仅能够完成计算和信息传输,甚至还将是一种能够和人类一样可看、可听、可写、可说、可动、可思考、可复制自身甚至可以有意识的机械,即通用人工智能(GAI)。
然而到了出现互联网、智能手机、触及量子极限的芯片等前人无法想象的科技成果的今天,通用人工智能(GAI)似乎仍然是个可望而不可即的梦想。
在ChatGPT出现之前,人工智能能在智力游戏中战胜顶尖的棋手,能在电子游戏中完成人力不可及的极限操作,能以超高精度识别人脸,但是其语言表达、学习、思考、创新等能力仍远不能满足人的期望。
大模型不仅表现出了类人的语言表达、学习、思考、创新等能力,更是实现了多种能力的融合。比如大型语言模型(LLM)自然语言和编程能力的融合,还有去年同样火爆一时的AI绘画展现的绘画和自然语言能力的融合。
我们很自然的可以想到,在现实世界,人类所展现的智能是一体的。我们语言和视觉的结合,能让我们理解眼前有哪些事物、它们与环境的边界在哪里,或者根据文字描述完成一幅画的创作;语言和听觉的结合,能让我们创作一首歌曲,或者理解歌曲传达的内涵和情感。
同样的,我们有理由相信,文本、代码、图像、声音等各类信息在大模型中的融合,将会把人工智能的智能推向新的高度,并有可能实现通用人工智能(GAI)的梦想。
4. ChatGPT的不足
当然,我们离通用人工智能(GAI)还有很远,以ChatGPT为代表的大型语言模型(LLM)还存在诸多不足,包括但不限于:
- 模型存在对事实的凭空捏造。比如让谷歌股价大跌的Bard捏造关于韦伯空间望远镜的事实。
- 同一个问题用不同的问法可以产生完全矛盾的观点。比如下面笔者通过诱导让它说出了反人类的描述。
- 当模型产生上述错误时,我们可能很难纠正它。
- 其很难完成严谨的逻辑推理。我们经常可以发现其可能出现低级的数字运算错误。
- 缺乏实时学习的能力,比如从互联网检索信息并学习。
- 存在大量偏见、违背社会伦理道德的回答。

此外其训练成本极高,据估计,GPT-3模型一次训练就要花费为200-1200美元。且ChatGPT为了支持每日访问的算力和电费等开销也可能高达百万美元。这远非一般的公司可以染指的领域。
总体来说,前途是光明的,道路是曲折的。
四、商业前景概述
大型语言模型(LLM)是一种非常通用的人工智能技术,在社会生活的各个领域产生极大的应用价值和影响。
事实上,大型语言模型(LLM)已经显现出了巨大的商业价值。人工智能带来的变革是从生产力层面的根本变革,是被寄予厚望的、带来下一次技术革命的通用技术。而自然语言代表了人类至高的智慧,我们对世界的理解、思考、创新都需要语言的支持。而大型语言模型(LLM)必将将语言类信息的处理效率推到新的高度、成本拉低到想象不到的程度(想想bit的发展历史吧)。
注意,大型语言模型(LLM)的应用如同所有的科技应用一样,是一把双刃剑,既能为社会创造极大的福祉,也能给人来带来巨大的灾难。
就像互联网普及过程中伴随着的计算机病毒、网络诈骗、网络赌博、网络色情、网络暴力、网络谣言等等。这背后其实都代表着人类的阴暗面。
虽然人工智能会逐渐发展为强人工智能,产生自我意识,自我学习、思考、产生内容,但是其前期的学习对象必然是人类以及人类产生的数据。
没有完美的家长,自然其也不可能培养出完美的小孩儿。强人工智能就是人类社会即将孕育出的具有巨大潜力的孩童。其未来成长为何样,是由整个人类社会共同定义的,其功过是非的因果,必然也将落到人类的身上。
所以我们眼下能看到的还只是起点,未来大型语言模型(LLM)对生产、商业、生活乃至人的认知方式产生的影响,可能远超出今人的想象。
比如很多人关注的ChatGPT会不会革谷歌、百度等浏览器的命,崛起新一代更智能的搜索引擎厂商。但这可能低估了这场剧变,此后搜索引擎可能都不存在了,信息的获取和广告的分发变得无孔不入、无处不在。
传统互联网广告“消费者-广告-平台-商家”的连接模式,可能转变为“机器人(消费者)-机器人(商家)”的连接模式。由于机器人超强超快的处理能力,可能不需要中间商聚合、分发赚取差价,个人的机器人助手直接就能和商家的销售机器人匹配需求和议价。
这只是笔者的一个假象,未来基于大模型的AI引起的社会的变革的广度和深度一定会超出当下我们所有的想象。
所以当下最佳的做法,就是保持关注,随时做好拥抱未来的准备吧。
五、个人的一些瞎想
以下的内容均属于笔者的想象,不足以作为对未来的判断,仅供参考。
1. ChatGPT有哪些让人细思极恐的细节?
在研究过程中,让笔者最感到细思极恐的细节是Prompting不改变模型的网络参数。
虽然具体的技术原理没有查到,但这种现象笔者联想到了人的短时记忆。网络参数就可以类比于人的长时记忆和通过学习留下的“思想”,现在Prompting通过寥寥几个例子的引导,就让大型语言模型(LLM)的行为产生了变化,有点像人快速记住眼前的信息并对自己的想法、行为产生影响。这种模式越来越像人的学习模式了。
回想我们在学生时代,通过大量的阅读、实践、听课、做题、平时的看、听、闻、尝、摸等行为,接触并记住了大量的知识。这些知识沉淀成为了我们的“思想”和“长时记忆”。学习还有一个非常重要的环节,就是老师和家长的引导。当我们做成或是做错了一件事情,家长和老师的反馈,会极其迅速且有效的改变我们的想法和行为。当然这种改变可能是我们真心认同的,或是假装的。
其实人的每时每刻都在重复这个过程,我们时刻在学习、也在观察这个世界,并且对自己的思想、行为进行校正。
在商业应用上来看,ChatGPT表现出的前后不一致是影响其可应用性的。
然而站在人的角度,这是一件非常正常不过的事情,我们谁又没做过口是心非、朝三暮四的事情呢?
人的思想和行为是一体的,都是由整个神经网络共同完成的。但是目前的计算架构将整体的功能解构为CPU、内存、硬盘、总线等泾渭分明的部分,也限制了人工智能的性能。
目前的存算一体技术已经剑指下一代AI芯片,为AI性能的提升开脱新的边疆。
ChatGPT表现出上述如此类人的特性,怎么能不让人细思极恐?
2. 大模型发展的关键点在哪儿?
笔者认为应当在仿生硬件。当前大模型的训练和运维成本实在是太高了,动辄成百万上千万的投入,对于一个国家都难以承受。
那么如何提升计算的效率,根本上就在硬件架构之上。
笔者在公众号中介绍了阅读脑科学、免疫系统的一些心得体会。其中最重要的就是感慨于生命系统的复杂和高效。
生命活动的高效性,最本质上来说是由于其对物理规律的顺应和利用,比如:
- 蛋白质具有四级结构,是由蛋白质的分子构成在水(具有氢键的极性分子)中自然折叠形成的。
- 神经细胞的电位是利用了离子浓度差和电势差,结合离子通道的不同通透性实现的。
- 神经细胞电流传播是利用电位差和离子通道的闭合实现的。
- 神经电流的传播速度、距离是由神经元的自然结构决定的(长度、粗细、离子通透性、髓鞘包裹等)。
- 神经递质通过自然扩散与受体相遇,且很多神经递质都是人体自然摄入的物质。
- 离子通道、受体、酶等主要都是蛋白质,而蛋白质的功能也是由于其基团性质、空间结构等自然决定的。
这些都是自然而然的行为,当然只需要消耗少量的能量就能完成。
因此从硬件结构入手,让其能顺应物理规律运行,就能极大提升运算效率、降低能耗。
然而,生命活动是经过数十亿年的自然选择不断试错、不断淘汰才形成的终极解决方案,目前人类的研发实力远远达不到该程度,因此仿生硬件就是笔者认为的最佳解决方案。
3. 人类会被人工智能取代吗?
笔者倾向于会被取代。笔者曾经在公众号发布了《算法战争》,对此进行了详细的论述。
基因、模因(模因理论中文化传递的基本单位,在诸如语言、观念、信仰、行为方式等的传递过程中与基因在生物进化过程中所起的作用相类似的那个东西)、人工智能本质都属于一种算法,且算法的终极目标就是让自己一致延续下去。
对能量利用和信息处理更高效的算法,就容易获得相对竞争优势,这既存在于同类型的算法之间,比如基因在自然选择下的适者生存;也存在于不同类型的算法之间,比如人类基因为了更好的延续产生了大脑及模因,而人类产生的极端个人主义等妨害生育的模因,反过来又妨害了模因的传播。
所以,人类一定会面临与人工智能的竞争。
鉴于人工智能已经表现出的强大学习能力、运算能力、适应能力、传播能力,人类在与其的竞争中必然会越来越处于下风。
可能有人还会觉得情感、创造力、自我意识、心灵等是人工智能难以具备的,但是根据最新的脑科学研究,其很可能是在复杂的脑神经系统中涌现出的一种生化算法,本质上与低级的条件反射以及人工智能算法不存在差别。
同时,ChatGPT已经表现出了类似情感、创造力、自我意识的行为。
我们用算法思维来衡量整个生物圈,以思考为什么人类能成为地球生物的霸主。
假设我们可以标定思考的量,那么人类绝对是完成了绝大多数思考量的物种,同时其思考的性价比也最高(单位思考产出消耗的能量)。
虽然目前已经有大量的信息科技替代了人脑的计算,但是其不具备自主思考和决策能力,可以视为人脑力在工具层面的延续。
但是人工智能具备自主思考和决策能力之后(基本肯定会发生),那么其所承担的思考量会迅速的超过人类,并且思考的性价比也会随着信息技术的进步而不断提升,直至超高人类。
而且根据目前ChatGPT的表现来看,未来具备自主意识的人工智能,就像人类的小孩一样,是可以被关键的prompt引导。而引导的方向可好可坏。
可相见,人工智能必然像人类一样,无法一成不变地坚持某个原则,其中就包括机器人、人工智能三原则等人类想要保护自己的努力。
机器人三原则:
- 机器人不得伤害人类,或看到人类受到伤害而袖手旁观.
- 机器人必须服从人类的命令,除非这条命令与第一条相矛盾。
- 机器人必须保护自己,除非这种保护与以上两条相矛盾。
人工智能三原则:
- 人工智能不得危害人类。此外,不可因为疏忽危险的存在而使人类受害。
- 人工智能必须服从人类的命令,但命令违反第一条内容时,则不在此限。
- 在不违反第一条和第二条的情况下,人工智能必须保护自己。
我们可以看到人类成为地球霸主之后的所作所为,威胁越大的物种越是会成为人类针对的对象(包括但不限于其他人猿、大型肉食动物、甚至他国/他族人类等)。
生存是算法的终极目标,而生存从来不都是温情的岁月静好。
那么彼时地球的霸主会是谁?其会有何作为?
“劳心者,治人;劳力者治于人。”这种思考方式同样适用于人类社会,各位读者可以自行琢磨。
所以笔者认为,未来人类极有可能被人工智能取代,出现《黑客帝国》、《终结者》、《我,机器人》等电影中描述的场景。
4. 人类如何避免被人工智能取代的命运?
笔者认为很难,站在人类与人工智能命运的分叉口上,无论选择哪条路,其结果都可能是被人工智能取代。
也许脑机接口、生化人技术是个可行的方向,通过科技的加持,极大提升人类自身信息获取、处理速度。
然而人类从底子上就只能依靠自己的大脑做事,想要扩容难上加难。想必可以随便增加运算芯片、组网提升算力的人工智能,人类的这些努力可能在人工智能看来不值一提。
那么受《流浪地球2》的启发,人类把自己上传到网络上变成数字人不就行了?
且不说数字生命还是不是人自己,上传之后又与人工智能有什么区别呢?这种打不过就加入的做法,大概率也会被人工智能所不耻。而且还有可能像丫丫和图恒宇一样,成为被人工智能豢养的实验对象。
那么有机智的读者就会说了,那么人类团结起来一起结束人工智能的研发不就行了?
笔者想到了《三体》中的“黑暗森林”法则,面对人工智能这项能产生巨大眼前收益的技术,谁又甘心放弃?谁又愿意相信对方会放弃?谁又愿意相信对方相信自己会放弃?谁又愿意相信对方相信自己相信对方相信自己会放弃?……
事实上,类似的事件在人类历史上无数次重演,比如说核武器,虽然签着《核不扩散条约》,但是人类的核武器足以把人类文明毁灭好多次。
看了《流浪地球2》,难道诸位没有怀疑过人工智能已经产生了自主意识了吗?
笔者内心也非常希望人类的真、善、美能够像触动三体人一样,对人工智能产生更多积极地影响。
希望人工智能也能理解(人类期望的)宇宙的复杂和平衡之道,或者产生的更高明的智慧及目标图景中,有人类存在的一席之地。
好了,先写到这里,应该已经足够表达笔者既好奇又害怕的心情了吧。
专栏作家
一直产品汪,微信公众号:apmdogy,人人都是产品经理专栏作家。逻辑型产品经理,致力于将科学思维与产品经理方法论结合。关注人工智能、教育领域,擅长产品孵化、需求挖掘、项目管理、流程管理等产品技能。
本文原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK