

自监督单目深度估计研究 - 抚琴尘世客
source link: https://www.cnblogs.com/haifwu/p/17103313.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

注:刚入门depth estimation,这也是以后的主要研究方向,欢迎同一个方向的加入QQ群(602708168)交流。
1. 论文简介
论文题目:Digging Into Self-Supervised Monocular Depth Estimation
Paper类型:深度学习(自监督)
发表刊物:ICCV
发表时间:2019
2. Abstract
半监督作为有效解决数据不足的手段;
在本文中,作者提出了一种半监督深度估计方法;
半监督尝试从更复杂的模型结构,损失函数,图像形成模型三个方面来缩小与全监督的差距。
本文的工作细节:
- 最小化重投影损失,解决遮挡问题;
- 全分辨率多尺度采用方法,降低视觉伪影;
- 一个自动掩码损失,忽略违反相机运动假设的训练像素;
在KITTTI数据集上取得了满意的效果。

3. Introduction
说明单目深度估计的研究价值。
并已有工作从立体对或视频数据来训练单目深度估计模型。


现有的两种半监督方法:
基于视频的,除了估计深度图以外,还要用一个位姿估计网络估计相机的变换;
基于立体对的,一次性离线校准,但可能导致遮挡和纹理复制伪影。

本文的三个主要工作,前面已经提到。


4. Related Work
4.1 Supervised Depth Estimation
从单个图像估计深度是一个固有的不适定问题,因为相同的输入图像可以投射到多个合理的深度。
为了解决这个问题,基于学习的方法已经证明自己能够拟合预测模型,利用彩色图像与其相应深度之间的关系。
研究人员探索了多种方法,如结合局部预测[19,55],非参数场景采样[24],到端到端监督学习[9,31,10]。基于学习的算法也是立体估计[72,42,60,25]和光流[20,63]性能最好的算法之一。

上述许多方法都是完全监督的,在训练过程中需要地面真相深度。然而,在不同的现实环境中,这是具有挑战性的。因此,越来越多的工作利用弱监督训练数据,例如,以已知对象大小[66]、稀疏顺序深度[77,6]、监督外观匹配项[72,73]或未配对的合成深度数据[45,2,16,78]的形式,所有这些都仍然需要收集额外的深度或其他注释。合成训练数据是一种替代[41],但要生成包含各种真实世界外观和运动的大量合成数据并非易事。最近的研究表明,传统的结构从运动(SfM)管道可以为摄像机姿态和深度生成稀疏训练信号[35,28,68],其中SfM通常作为预处理运行步骤与学习解耦。最近,[65]在我们的模型基础上,结合传统立体声算法的噪声深度提示,改进了深度预测。

4.2 Self-supervised Depth Estimation
在缺乏地面真实深度的情况下,一种替代方法是使用图像重建作为监督信号来训练深度估计模型。在这里,模型以立体对或单目序列的形式给出一组图像作为输入。通过对给定图像的深度产生幻觉并将其投射到附近的视图中,模型通过最小化图像重建误差来训练。

4.2.1 Self-supervised Stereo Training

4.2.2 Self-supervised Monocular Training
一种约束较少的自我监督形式是使用单目视频,其中连续的时间帧提供训练信号。在这里,除了预测深度之外,网络还必须估计帧之间的相机姿势,这在物体运动的情况下具有挑战性。这个估计的相机姿势只在训练期间需要,以帮助约束深度估计网络。
在第一个单目自监督方法中,[76]训练了一个深度估计网络和一个单独的姿态网络。为了处理非刚性场景运动,一个附加的运动解释掩码允许模型忽略违反刚性场景假设的特定区域。然而,他们的模型的后续迭代可在线禁用这一术语,实现了优越的性能。受[4]的启发,[61]提出了使用多个运动掩模的更复杂的运动模型。然而,这并没有得到充分的评估,因此很难理解其效用。[71]还将运动分解为刚性和非刚性成分,使用深度和光流来解释物体的运动。这改善了流量估计,但在流量和深度联合训练时没有改善

最近的方法已经开始缩小单眼和基于立体的自我监督之间的性能差距。[70]约束预测深度与预测表面法线一致,[69]强制边缘一致。[40]提出了一种基于匹配损失的近似几何,以鼓励时间深度一致性。[62]使用深度归一化层来克服由[15]中常用的深度平滑项引起的对较小深度值的偏好。[5]使用预先计算的实例分割掩码已知类别,以帮助处理移动对象。

4.2.3 Appearance Based Losses
自我监督训练通常依赖于对帧间物体表面的外观(即亮度恒常性)和材料属性(例如兰伯特性)的假设。[15]表明,与简单的两两像素差异相比,包含基于外观损失的局部结构[64]显著提高了深度估计性能[67,12,76]。[28]扩展了这种方法,包括误差拟合项,[43]探索将其与基于对抗的损失相结合,以鼓励逼真的合成图像。最后,受[72]的启发,[73]使用ground truth depth来训练一个外观匹配项。

5. Method
在这里,我们描述了我们的深度预测网络,它接受单一颜色输入![]() 并生成深度图
并生成深度图![]() 。
。
我们首先回顾了单眼深度估计的自监督训练背后的关键思想,然后描述了我们的深度估计网络和联合训练损失。
5.1 Self-Supervised Training
自监督深度估计通过训练网络从另一个图像的角度预测目标图像的外观,将学习问题作为一种新的视图合成问题(其实就是投影,根据估计的深度图,相机内参,相机位姿矩阵,一个视角的图像,可以投影到另一个视角的图像)。
这样就可以把深度估计看成一个中间过程,投影得到的图像和其他视角的图像计算loss来约束网络。这种方法在后面的很多工作中都有用到。
但是,每个像素都有非常多的可能不正确的深度,给定相对位姿都可以正确地重建两个视图。
经典的双目和多视角立体视觉方法通常通过加强深度图的平滑性来解决这种模糊性,并通过全局优化(例如[11])求解逐像素深度时计算补丁上的照片一致性。


这里主要讲了几个损失函数。
投影损失,它所计算的两个输入分别是目标视角下的图像和将源视角下的图像投影得到的图像;投影过程为估计的深度图,相机位姿矩阵,相机内参,源视角下的图像。
另外还计算了光测误差和边界感知平滑损失。

![]()
在立体匹配中投影最为常用,并且通常是一个深度估计网络和一个位姿估计网络。

5.2 Improved Self-Supervised Depth Estimation
现有的单目方法产生的深度质量低于最好的全监督模型。为了缩小这一差距,本文提出了几项改进,可以显著提高预测深度质量,而不需要添加额外的模型组件,这些组件也需要训练(见图3)。
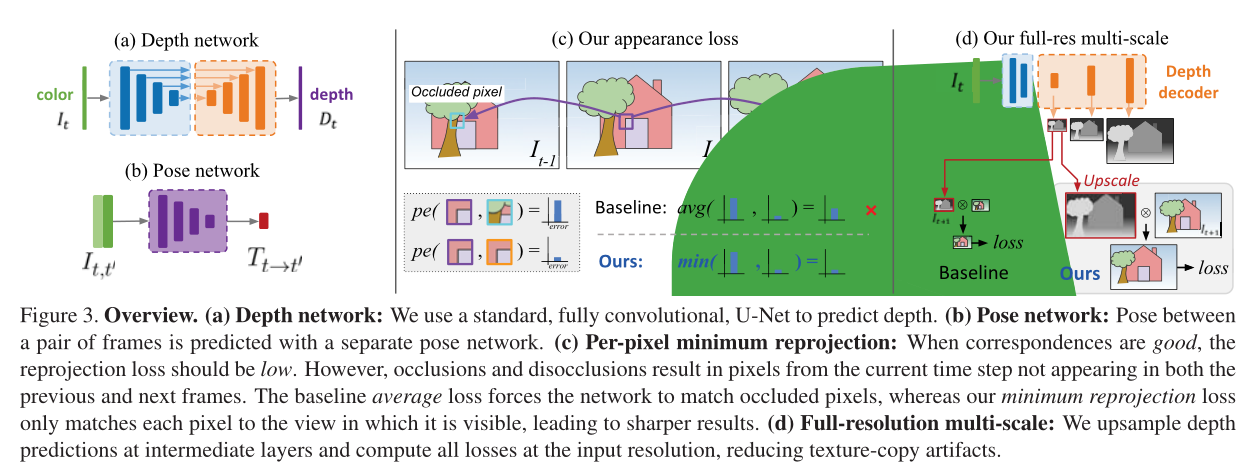
5.2.1 Per-Pixel Minimum Reprojection Loss
在计算多个源图像的重投影误差时,现有的自监督深度估计方法将每个可用源图像的重投影误差平均在一起。这可能会导致像素在目标图像中可见,但在某些源图像中不可见(如图3(c))。如果网络预测了这样一个像素的正确深度,那么闭塞源图像中的对应颜色很可能与目标不匹配,从而导致高光度误差惩罚。
这样的问题像素来自两个主要类别:由于图像边界的自我运动而超出视野的像素,以及被遮挡的像素。可以通过在重投影损失中掩盖这些像素来减少视域外像素的影响[40,61],但这不能处理去遮挡,其中平均重投影会导致模糊的深度不连续。(这种方法相当于跳过遮挡)



5.2.2 Auto-Masking Stationary Pixels
自监督单眼训练通常在移动摄像机和静态场景的假设下进行。当这些假设失效时,例如当摄像机静止或场景中有物体运动时,性能会受到很大影响。这个问题在预测测试时间深度图中表现为无限深度的“洞”,因为在训练[38]期间通常观察到物体在移动(图2)。这激发了我们的第二个贡献:一个简单的自动屏蔽方法,过滤掉序列中从一帧到下一帧不改变外观的像素。这可以让网络忽略与摄像机速度相同的物体,甚至在摄像机停止移动时忽略单目视频中的整帧

像其他工作[76,61,38]一样,我们也对损失应用逐像素掩码μ,选择性地加权像素。然而,与之前的工作相反,我们的掩码是二进制的,因此μ∈{0,1},并且在网络的正向传递上自动计算,而不是从对象运动中学习或估计。我们观察到,序列中相邻帧之间保持相同的像素通常表示静态摄像机,以等效相对平移移动的物体到摄像机,或低纹理区域。因此,我们将μ设置为仅包括丢失的像素,其中扭曲图像的重投影误差![]() 低于原始的、未扭曲的源图像
低于原始的、未扭曲的源图像![]() ,即
,即

其中[]为艾弗森方阵。当相机和另一个物体都以相似的速度移动时,μ防止图像中保持静止的像素污染损失。类似地,当相机静止时,掩模可以过滤掉图像中的所有像素(图5)。
我们实验表明,这种简单和廉价的修改损失带来了显著的改善。
![]()


5.2.3 Multi-scale Estimation
由于双线性采样器[21]的梯度局域性,为了防止训练目标陷入局部极小值,现有模型使用多尺度深度预测和图像重建。这里,总损耗是解码器中每个标度上的单个损耗的组合。[12,15]计算图像在每个解码器层分辨率上的光度误差。我们观察到,在中间较低分辨率的深度图中,这倾向于在大的低纹理区域中创建“洞”,以及纹理复制伪影(深度图中的细节不正确地从彩色图像转移过来)。深度孔可能出现在低分辨率的低纹理区域,其中光度误差是不明确的。这使得深度网络的任务变得复杂,现在可以自由地预测不正确的深度

受立体重建[56]技术的启发,我们提出了对这种多尺度公式的改进,其中我们解耦了用于计算重投影误差的视差图像和彩色图像的分辨率。我们不计算模糊低分辨率图像上的光度误差,而是首先对低分辨率深度图(从中间层)上采样到输入图像分辨率,然后重新投影,重新采样,并在这个较高的输入分辨率下计算误差pe(图3 (d))。这个过程类似于匹配补丁,因为低分辨率的视差值将在高分辨率图像中扭曲整个像素“补丁”。这有效地限制了每个比例尺上的深度图朝着相同的目标工作,即尽可能准确地重建高分辨率输入目标图像。

5.3 Additional Considerations
我们的深度估计网络基于通用的U-Net架构[53],即一个编码器-解码器网络,具有跳过连接,使我们能够表示深度抽象特征以及局部信息。我们使用ResNet18[17]作为编码器,与现有工作[15]中使用的更大、更慢的disnet和ResNet50模型相比,它包含11M个参数。与[30,16]类似,我们从ImageNet[54]上预训练的权重开始,并表明与从头开始训练相比,这提高了我们紧凑模型的准确性(表2)。我们的深度解码器类似于[15],输出处是sigmoids,其他地方是ELU非线性[7]。我们将sigmoid输出σ转换为深度D = 1/(aσ + b),其中选择a和b将D限制在0.1到100个单位之间。我们在解码器中使用反射填充来代替零填充,当样本落在图像边界之外时,返回源图像中最接近边界像素的值。我们发现这大大减少了现有方法(例如[15])中的边界构件。


对于姿态估计,我们遵循[62]并使用轴角表示来预测旋转,并将旋转和平移输出按0.01缩放。对于单目训练,我们使用三帧的序列长度,而我们的姿态网络由ResNet18组成,修改为接受一对彩色图像(或六个通道)作为输入,并预测单个6-DoF相对姿态。我们执行水平翻转和以下训练增强,概率为50%:随机亮度、对比度、饱和度和色调抖动,范围分别为±0.2、±0.2、±0.2和±0.1。重要的是,颜色增强只应用于馈送到网络的图像,而不是用于计算Lp的图像。输入到姿态和深度网络的所有三张图像都使用相同的参数进行增强。

训练参数设置;
我们的模型在PyTorch[46]中实现,使用Adam[26]训练了20个epoch,除非另有说明,批处理大小为12,输入/输出分辨率为640 × 192。对于前15个epoch,我们使用10−4的学习率,然后对于其余的epoch,学习率下降到10−5。这是使用10%的数据的专用验证集选择的。
平滑项λ设置为0.001。对于立体声(S)、单眼(M)和单眼加立体声模型(MS),单个Titan Xp的训练分别需要8小时、12小时和15小时。

6. Experiments
在这里,我们验证:(1)与现有的像素平均相比,我们的重投影损失有助于处理被遮挡的像素,(2)我们的自动掩蔽改善了结果,特别是在使用静态摄像机的场景训练时,以及(3)我们的多尺度外观匹配损失提高了精度。我们在KITTI 2015立体数据集[13]上评估了名为Monodepth2的模型,以便与之前发表的单目方法进行比较。
6.1 KITTI Eigen Split
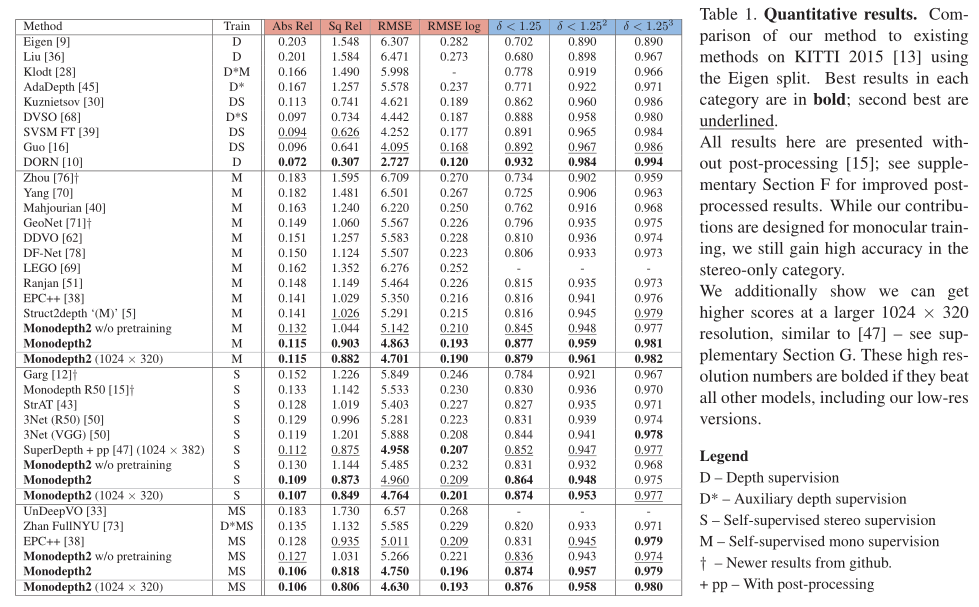
我们使用Eigen et al[8]的数据分割。除烧蚀实验外,对于使用单眼序列(即单眼和单眼加立体)的训练,我们遵循Zhou等人[76]的预处理来去除静态帧。结果有39810个单眼三图像对用于训练,4424个用于验证。我们对所有图像使用相同的intrinsic,将相机的主点设置为图像中心,焦距设置为KITTI中所有焦距的平均值。对于立体和混合训练,我们将两个立体帧之间的变换设为一个固定长度的纯水平平移。在评估过程中,我们将每个标准作业[15]的深度限制在80m。对于我们的单目模型,我们使用[76]引入的逐图像中值真实值缩放来报告结果。另请参阅补充材料D.2节,了解我们对整个测试集应用单个中值缩放的结果,而不是独立缩放每个图像。对于使用任何立体监控的结果,我们不执行中值缩放,因为在训练期间可以从已知的摄像机基线推断出尺度。

我们比较了用不同类型的自我监督训练的模型的几个变体的结果:仅单目视频(M),仅立体(S)和两者(MS)。表1中的结果表明,我们的单目方法优于所有现有的最先进的自监督方法。我们也优于最近明确计算光流和运动掩模的方法([38,51])。定性结果见图7和补充部分E。
然而,与所有基于图像重建的深度估计方法一样,当场景包含违反我们外观损失的兰伯假设的对象时,我们的模型会中断(图8)。

正如预期的那样,M和S训练数据的组合提高了准确性,这在对大深度误差(如RMSE)敏感的指标上尤其明显。尽管我们的贡献是围绕单眼训练设计的,但我们发现在只有立体的情况下,我们仍然表现良好。尽管我们使用了比[47]的1024 × 384更低的分辨率,但我们获得了很高的精度,训练时间大大减少(20对200 epoch),并且不使用后处理。


6.1.1 KITTI Eigen Split
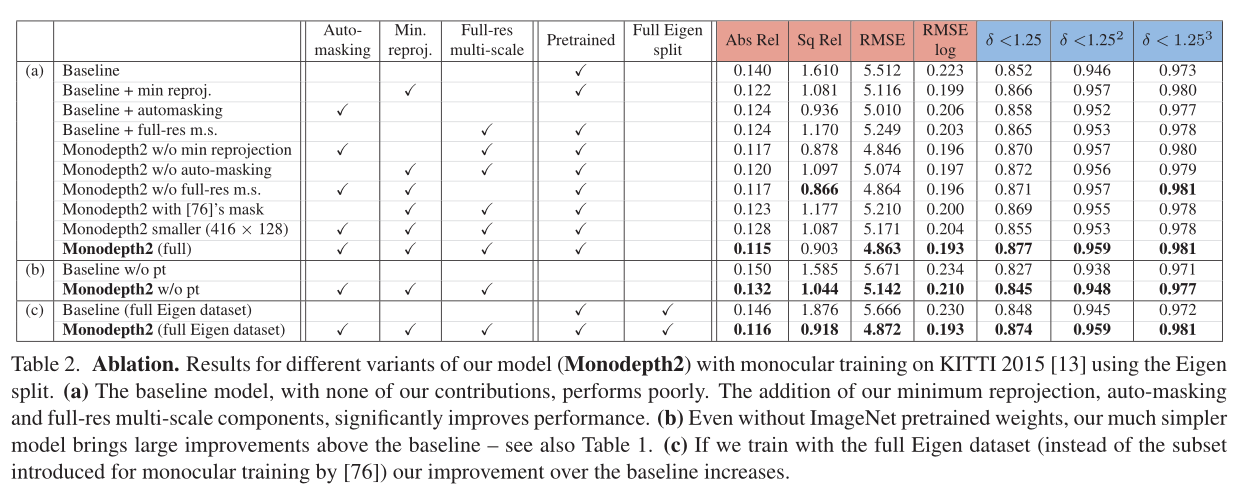
为了更好地理解我们的模型的组成部分如何对单眼训练的整体表现做出贡献,在表2(a)中,我们通过改变模型的各个组成部分来进行消融研究。我们看到基线模型,没有我们的任何贡献,表现最差。当组合在一起时,我们所有的组件都会带来显著的改进(Monodepth2 (full))。更多的实验依次关闭我们的完整模型的部分在补充材料C节中显示。

完整的Eigen [8] KITTI分割包含几个序列,其中相机不会在帧之间移动,例如数据捕捉车停在红绿灯前。这些“无相机运动”序列可能会导致自监督单目训练的问题,因此,在训练时通常会使用昂贵的计算光流来排除它们[76]。我们报告在表2(c)中完整的特征数据分割上训练的单目结果,即不移除帧。在KITTI完整分割上训练的基线模型比我们的完整模型表现得更差。
此外,在表2(a)中,我们用[76]中的预测掩码的重新实现取代了我们的自动掩码损失。
我们发现这种消融实验模型比不使用掩蔽更差,而我们的自动掩蔽在所有情况下都改善了结果。我们在图5中看到了一个自动屏蔽在实践中如何工作的例子。


我们遵循之前的工作[14,30,16],使用在ImageNet[54]上预训练的权重初始化我们的编码器。虽然其他一些单目深度预测工作选择不使用ImageNet预训练,但我们在表1中显示,即使没有预训练,我们仍然可以获得最先进的结果。我们训练这些“w/o预训练”模型30个epoch,以确保收敛。表2显示了我们的贡献给预训练网络和从头训练的网络带来的好处;更多的消融见补充材料C部分。

6.2 Additional Datasets
在补充材料的A节中,我们展示了KITTI的里程计评估。虽然我们的重点是更好的深度估计,但我们的姿态网络的表现与其他竞争方法相当。竞争的方法通常向它们的姿态网络提供更多的帧,这可能会提高它们的泛化能力。我们使用这种新的基准分割训练模型,并使用在线服务器[27]对其进行评估,并在补充部分D.3中提供结果。此外,93%的特征分割测试帧具有[59]提供的更高质量的地面真值深度。像[1]一样,我们使用这些而不是重新投影的LIDAR扫描来将我们的方法与几个现有的基线算法进行比较,仍然显示出优越的性能。

我们还在最近推出的KITTI深度预测评估数据集[59]上进行了实验,该数据集具有更准确的地面真实深度,解决了质量问题


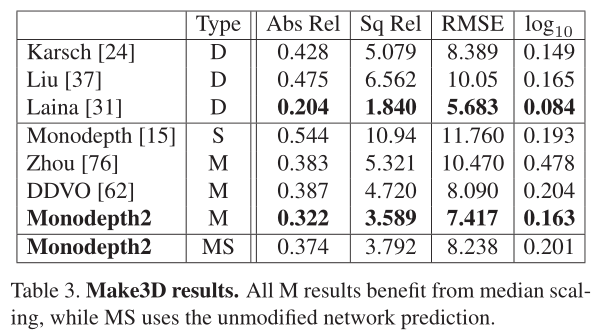
在表3中,我们使用在KITTI上训练的模型报告Make3D数据集[55]上的性能。我们优于所有不使用深度监督的方法,评估标准为[15]。但是,使用Make3D时应该谨慎,因为它的地面真实值深度和输入图像没有很好地对齐,从而导致潜在的评估问题。我们对2 × 1的中心作物进行评估,并对我们的M模型应用中值缩放。定性结果见图6和补充部分E。

本文的主要贡献:
- 提出了一个最小化投影损失(minimum reprojection loss),解决了遮挡问题;
- 提出了一个自动掩码损失(auto-masking loss),忽略混淆,静止像素;
- 提出了一种全分辨率多尺度采样方法;
这篇工作还是挺有意义的,后续很多工作都与之对比。
努力去爱周围的每一个人,付出,不一定有收获,但是不付出就一定没有收获! 给街头卖艺的人零钱,不和深夜还在摆摊的小贩讨价还价。愿我的博客对你有所帮助(*^▽^*)(*^▽^*)!
如果客官喜欢小生的园子,记得关注小生哟,小生会持续更新(#^.^#)(#^.^#)。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK