

超越核方法的量子机器学习,量子学习模型的统一框架
source link: https://www.51cto.com/article/745911.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

超越核方法的量子机器学习,量子学习模型的统一框架
基于参数化量子电路的机器学习算法是近期在嘈杂的量子计算机上应用的主要候选者。在这个方向上,已经引入和广泛研究了各种类型的量子机器学习模型。然而,我们对这些模型如何相互比较以及与经典模型进行比较的理解仍然有限。
近日,来自奥地利因斯布鲁克大学的研究团队确定了一个建设性框架,该框架捕获所有基于参数化量子电路的标准模型:线性量子模型。
研究人员展示了使用量子信息论中的工具如何将数据重新上传电路有效地映射到量子希尔伯特空间中线性模型的更简单图像中。此外,根据量子比特数和需要学习的数据量来分析这些模型的实验相关资源需求。基于经典机器学习的最新结果,证明线性量子模型必须使用比数据重新上传模型多得多的量子比特才能解决某些学习任务,而核方法还需要多得多的数据点。研究结果提供了对量子机器学习模型的更全面的了解,以及对不同模型与 NISQ 约束的兼容性的见解。
该研究以「Quantum machine learning beyond kernel methods」为题,于 2023 年 1 月 31 日发布在《Nature Communications》上。
论文链接:https://www.nature.com/articles/s41467-023-36159-y
在当前嘈杂的中级量子 (NISQ) 时代,已经提出了一些方法来构建与轻微的硬件限制兼容的有用量子算法。大多数这些方法都涉及量子电路 Ansatz 的规范,以经典方式优化以解决特定的计算任务。除了化学中的变分量子特征求解器和量子近似优化算法的变体之外,基于这种参数化量子电路的机器学习方法是产生量子优势的最有希望的实际应用之一。
核方法(kernel methods)是一类模式识别的算法。其目的是找出并学习一组数据中的相互的关系。核方法是解决非线性模式分析问题的一种有效途径,其核心思想是:首先,通过某种非线性映射将原始数据嵌入到合适的高维特征空间;然后,利用通用的线性学习器在这个新的空间中分析和处理模式。
以前的工作通过利用一些量子模型和经典机器学习的核方法之间的联系,在这个方向上取得了长足的进步。许多量子模型确实是通过在高维希尔伯特空间中编码数据,并仅使用在此特征空间中评估的内积来对数据的属性进行建模来运行。这也是核方法的工作原理。
基于这种相似性,给定的量子编码可用于定义两种类型的模型:(a) 显式量子模型,其中编码数据点根据指定其标签的变分可观测值进行测量;或 (b) 隐式核模型,其中编码数据点的加权内积用于分配标签。在量子机器学习文献中,很多重点都放在隐式模型上。
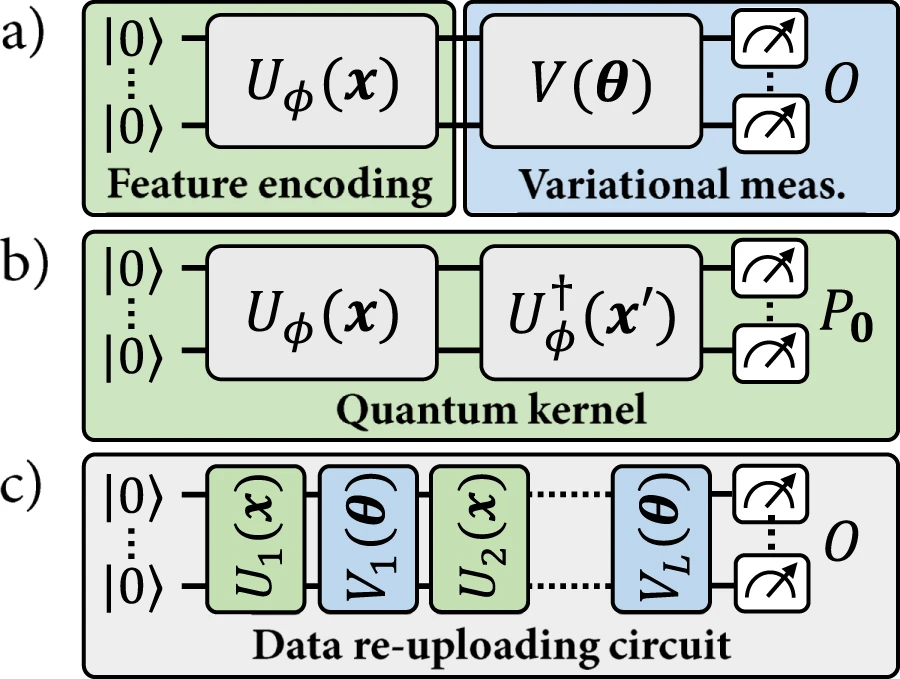
图 1:这项工作中研究的量子机器学习模型。(来源:论文)
最近,所谓的数据重新上传(data re-uploading)模型取得了进展。数据重新上传模型可以看作是显式模型的推广。然而,这种概括也打破了与隐式模型的对应关系,因为给定的数据点 x 不再对应于固定的编码点 ρ(x)。数据重新上传模型比显式模型严格更通用,并且它们与内核模型范例不兼容。到目前为止,在核方法的保证下,是否可以从数据重新上传模型中获得一些优势仍然是一个悬而未决的问题。
在这项工作中,研究人员引入了一个用于显式、隐式和数据重新上传量子模型的统一框架。
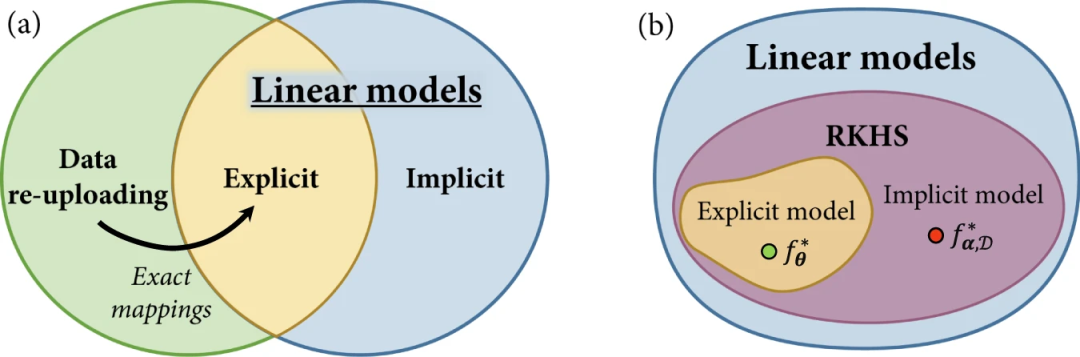
图 2:量子机器学习中的模型族。(来源:论文)
量子学习模型的统一框架
首先回顾线性量子模型的概念,并根据量子特征空间中的定义线性模型解释显式和隐式模型。然后,展示了数据重新上传模型,并展示了尽管被定义为显式模型的推广,但它们也可以通过更大的希尔伯特空间中的线性模型来实现。
线性量子模型
下图给出了一个说明性结构,以直观地说明如何实现从数据重新上传到显式模型的映射。
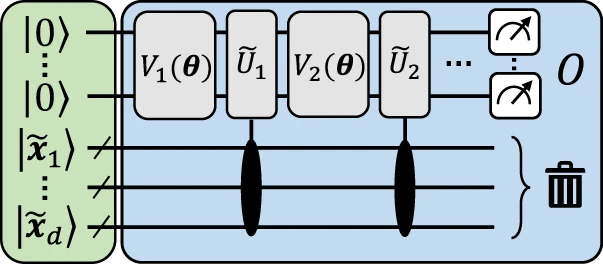
图 3:近似于数据重新上传电路的说明性显式模型。(来源:论文)
这种结构背后的总体思想是将输入数据 x 编码为辅助量子比特,达到有限精度,然后可以重复使用它来使用与数据无关的单一体来近似数据编码门。
现在转向主要结构,导致数据重新上传和显式模型之间的精确映射。在这里,依赖于与前面结构相似的思想,在辅助量子位上对输入数据进行编码,然后使用数据独立操作在工作量子位上实现编码门。这里的区别在于,使用门传送( gate-teleportation)技术,一种基于测量的量子计算,直接在辅助量子位上实现编码门,并在需要时将它们传送回(通过纠缠测量)到工作量子位上。
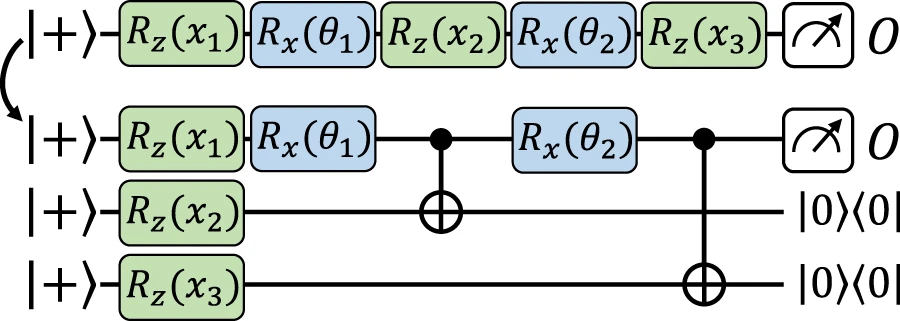
图 4:使用门隐形传态从数据重新上传模型到等效显式模型的精确映射。(来源:论文)
研究人员证明了线性量子模型不仅可以描述显式和隐式模型,还可以描述数据重新上传电路。更具体地说,任何假设类的数据重新上传模型都可以映射到等效类的显式模型,即具有受限可观察量族的线性模型。
接着,研究人员更严格地分析了显式和数据重新上传模型相对于隐式模型的优势。在例子中,通过量子比特数和实现非平凡预期损失所需的训练集大小来量化量子模型解决学习任务的效率。关注的学习任务是学习奇偶函数。
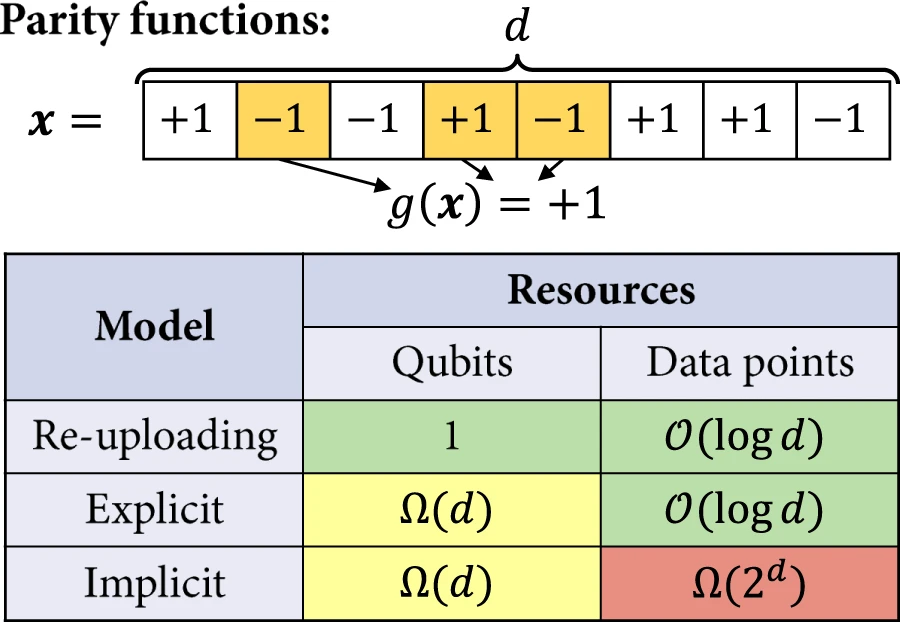
图 5:学习分离。(来源:论文)
超越核方法的量子优势
量子机器学习的一个主要挑战是,表明这项工作中讨论的量子方法可以实现优于(标准)经典方法的学习优势。
在这方面的研究中,谷歌量子人工智能的 Huang 等人(https://www.nature.com/articles/s41467-021-22539-9)建议研究目标函数本身由(显式)量子模型生成的学习任务。
与 Huang 等人类似,研究人员使用来自 fashion-MNIST 数据集的输入数据进行回归任务,每个示例都是一个 28x28 的灰度图像。
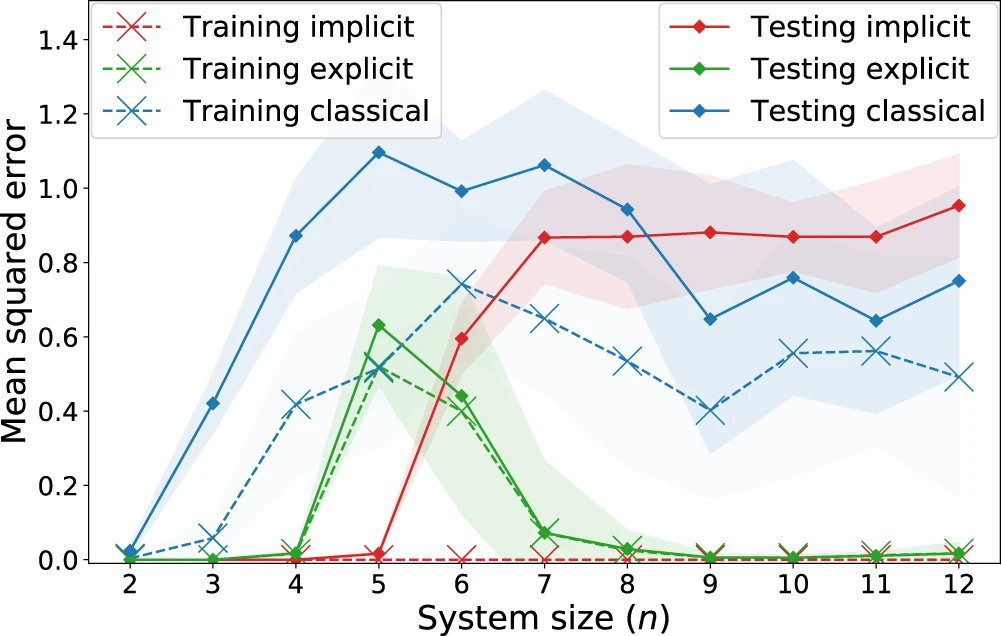
图 6:显式、隐式和经典模型在「量子定制」学习任务上的回归性能。(来源:论文)
观察到:隐式模型系统地实现比显式模型更低的训练损失。特别是对于非正则化损失,隐式模型实现了 0 的训练损失。另一方面,关于代表预期损失的测试损失,从 n = 7 量子位开始的明显分离,其中经典模型开始与隐式模型具有竞争性能,而显式模型明显胜过他们两个。这表明,不应仅通过将经典模型与量子核方法进行比较来评估量子优势的存在,因为显式(或数据重新上传)模型也可以隐藏更好的学习性能。
这些结果让我们对量子机器学习领域有了更全面的了解,并拓宽了我们对模型类型的看法,以便在 NISQ 机制中实现实际的学习优势。
研究人员认为证明不同量子模型之间存在指数学习分离的学习任务是基于奇偶函数的,这在机器学习中不是一个实际感兴趣的概念类。然而,下限结果也可以扩展到其他具有大维度概念类(即由许多正交函数组成)的学习任务。
量子核方法必然需要许多与该维度成线性比例的数据点,而正如我们在结果中展示的那样,数据重新上传电路的灵活性以及显式模型的有限表达能力以节省大量资源。探索这些模型如何以及何时可以针对手头的机器学习任务进行定制仍然是一个有趣的研究方向。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK