

使用Redisearch实现的全文检索功能服务
source link: https://v3u.cn/a_id_105
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

使用Redisearch实现的全文检索功能服务
“检索”是很多产品中无法绕开的一个功能模块,当数据量小的时候可以使用模糊查询等操作凑合一下,但是当面临海量数据和高并发的时候,业界常用 elasticsearch 和 lucene 等方案,但是elasticsearch对运行时内存有着最低限额,其运行时大小推荐 2G 以上的内存空间,并且需要额外的磁盘空间做持久化存储。
其实mongoDB 内置的正则匹配搜索文本以及自带的 text 索引和 search 关键字也是一套靠谱的解决方案,但是这一次我们带来一种更加高效经济的文本检索方案:Redisearch
下图是elasticsearch和redisearch的性能对比
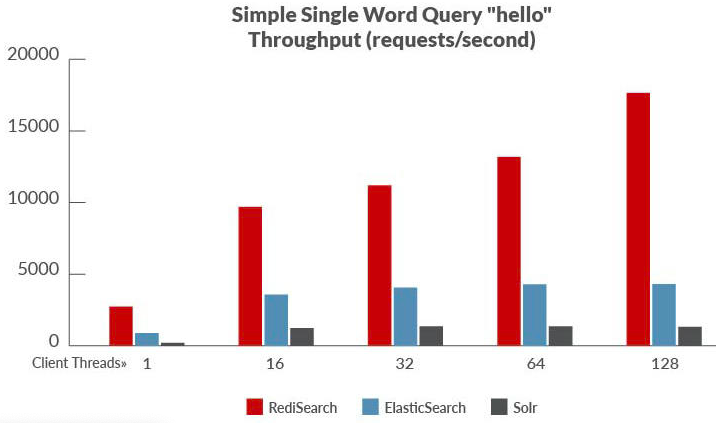
Redis Modules 是 redis 4.0 引入的一种扩展机制,用户可以通过实现 redis module 提供的 C api 接口为 redis 服务添加定制化功能。 redisLab 也希望籍此来规范 redis 社区的 ecosystem 实现。
redis module 本身的版本独立于redis,并且以编译成动态加载库 .so 文件的方式 release, 不同版本的 redis 可以 load 同一版本 module.so 文件。
redis 提供了两种加载方式。可以通过 在 conf 文件中 加入 loadmodule /path/to/mymodule.so ,也可以在 redis-cli中使用命令 MODULE LOAD /path/to/panda.so 动态加载,MODULE UNLOAD 卸载。
特性
基于文档的全文索引。
高性能增量索引。
支持文档评分,文档字段(field) 权重机制。
支持布尔复杂查询。
支持自动补全。
基于 snowball 的词干分析,多语言支持。使用 friso 支持中文分词。
utf-8 字符集支持。
redis 数据持久化支持。
自定义评分机制。
其原理是在 redis 的 hashmap 基础上就可以很容易实现倒排索引的结构。redisearch 倒排索引除了实现了基础功能外,还引入了内存管理等优化功能。如果有兴趣可以阅读源码中的 src/inverted_index.c 部分
首先,安装Rediseach,记住一点你本地的redis服务版本必须在4.0以上,网上一大堆编译安装的攻略,繁琐又浪费时间,所以又到了Docker登场时间了,hub上有编译好的免费镜像供我们下载
docker pull redislabs/redisearch下载后,直接在后台启动服务
docker run -d -p 6666:6379 redislabs/redisearch:latest

此时已经有一个docker容器在后台启动了,redis服务映射到了宿主的6666端口,我们来连接一下
redis-cli -h localhost -p 6666

检查 modules 是否成功加载
localhost:6666> MODULE list
1) 1) "name"
2) "ft"
3) "ver"
4) (integer) 10405如果返回数组中存在 "ft" , 则表明 redisearch 已经成功加载。
Redisearch 的索引概念 与elasticsearch 的 index 类似,表示某一类文档资源单元。
这里我们定义了一个 SMARTX_VM 索引,其中存储的文档 包含 了 title 和 desc 两个 类型为 TEXT 的field。
FT.CREATE SMARTX_VM SCHEMA title TEXT WEIGHT 5.0 desc TEXT然后向刚刚创建的这条索引加一个文档
FT.ADD SMARTX_VM vm-2019082911110001 1.0 LANGUAGE "chinese" FIELDS title "人工智能" desc "我在北京昌平学习人工智能"LANGUAGE "chinese" 参数 表示 使用 中文分词器 处理文本。默认为英文
此时我们进行文档检索
FT.SEARCH SMARTX_VM "人工智能" LANGUAGE "chinese"注意检索的时候也要指定语言,这里我们用中文分词,默认的英文分词是无法检索中文的

可以看到已经返回了我们想要的结果。
Redisearch 是一个高效,功能完备的内存存储的高性能全文检索组件, 十分适合应用在数据量适中, 内存和存储空间有限的环境。借助数据同步手段,我们可以很方便的将redisearch 结合到现有的数据存储中, 进而向产品提供 全文检索, 自动补全等服务优化功能。
Recommend
-
82
RediSearch Querying, secondary indexing, and full-text search for Redis
-
32
README.md
-
55
使用Elasticsearch7 java api实现pdf全文检索 ...
-
16
RediSearch is a source available Full-Text and Secondary Index engine over Redis, developed byRedis Labs . Quick L...
-
6
使用Lucene.Net实现全文检索
-
4
Create a lyrics search engine using RediSear...
-
2
使用python3和高性能全文检索引擎Redisearch进行交互首页 - Python/2019-08-30 上一篇介绍了一款
-
3
国内唯一一部在CentOS下正确编译安装和使用RediSearch的教程_TGITCIC的博客-CSDN博客 Redis6开始增加了诸多激动人心的模块,特别是:RedisJ...
-
3
ElasticSearch 实现分词全文检索 - 概述
-
3
使用 RediSearch 在 Redis 中进行全文检索
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK