

VALL-E: Microsoft's new zero-shot text-to-speech model can duplicate everyone's...
source link: https://mpost.io/vall-e-microsofts-new-zero-shot-text-to-speech-model-can-duplicate-everyones-voice-in-three-seconds/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

VALL-E: Microsoft’s new zero-shot text-to-speech model can duplicate everyone’s voice in three seconds


In Brief
With just a three-second sample of any voice, the transformer-based TTS model VALL-E can produce speech in every voice.
This is a significant advancement in the direction of more natural-sounding TTS systems.
Microsoft has, however, provided a few samples of the model in use, and it is evident that this represents a significant development in TTS technology.
![]()
![]()
The Trust Project is a worldwide group of news organizations working to establish transparency standards.
Since the release of the first text-to-speech (TTS) model, researchers have been looking for ways to improve the way these systems generate speech. The latest model from Microsoft, VALL-E, is a significant step forward in this regard.
VALL-E is a transformer-based TTS model that can generate speech in any voice after only hearing a three-second sample of that voice. This is a significant improvement over previous models, which required a much longer training period in order to generate a new voice.

Additionally, the intonation, charisma, and style of the voice are all kept intact in the generated speech. This is an important step forward in making TTS systems sound more natural.
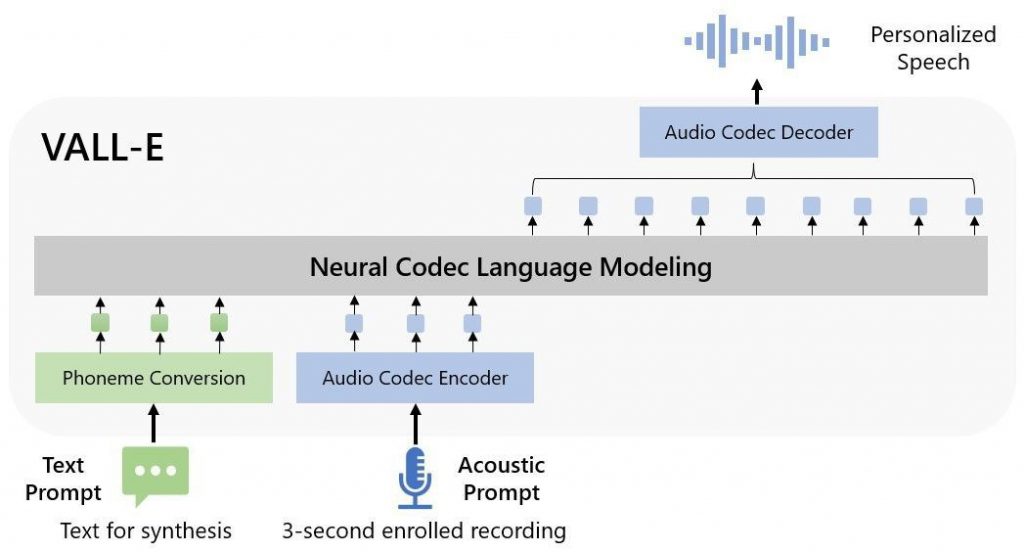
This model is transformer-based and has a Dale-1 appearance. Not to be confused with the diffusion-based Dalle-2. The code is still lacking. And users have some skepticism that they will post it. However, Microsoft has released a few examples of the model in action, and it is clear that this is a major advance in TTS technology.
Example #1:
Example #2:
Example #3:
Read more about AI:
Disclaimer
Any data, text, or other content on this page is provided as general market information and not as investment advice. Past performance is not necessarily an indicator of future results.
Damir Yalalov
Damir is the Editor/SEO/Product Lead at mpost.io. He is most interested in SecureTech, Blockchain, and FinTech startups. Damir earned a bachelor's degree in physics.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK