

虚假新闻检测(CADM)《Unsupervised Domain Adaptation for COVID-19 Information Se...
source link: https://www.cnblogs.com/BlairGrowing/p/17011593.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

论文标题:Unsupervised Domain Adaptation for COVID-19 Information Service with Contrastive Adversarial Domain Mixup
论文作者:Huimin Zeng, Zhenrui Yue, Ziyi Kou, Lanyu Shang, Yang Zhang, Dong Wang
论文来源:aRxiv 2022
论文地址:download
论文代码:download
1 Introduction
2 Problem Statement
Regarding misinformation detection, we aim at training a model ff , which takes an input text xx (a COVID-19 claim or a piece of news) to predict whether the information contained in xx is valid or not (i.e., a binary classification task). Moreover, in our domain adaptation problem, we use PP to denote source domain data distribution and QQ for the target domain data distribution. Each data point (xx, yy) contains an input segment of COVID-19 claim or news (xx) and a label y∈{0,1}y∈{0,1} ( y=1y=1 for true information and y=0y=0 for false information). To differentiate the notations of the data sampled from the source distribution PP and the target distribution QQ , we further introduce two definitions of the domain data:
-
- Source domain: The subscript ss is used to denote the source domain data: Xs={(xs,ys)∣(xs,ys)∼P}Xs={(xs,ys)∣(xs,ys)∼P} .
- Target domain: Similarly, the subscript t is used to denote the target domain data: Xt={xt∣xt∼P}Xt={xt∣xt∼P} . Note that in our unsupervised setting, the ground truth labels of target domain data ytyt are not used during training.
Our goal is to adapt a classifier ff trained on PP to QQ . For a given target domain input xtxt , a well-adapted model aims at making predictions as correctly as possible.
3 Method
整体框架:
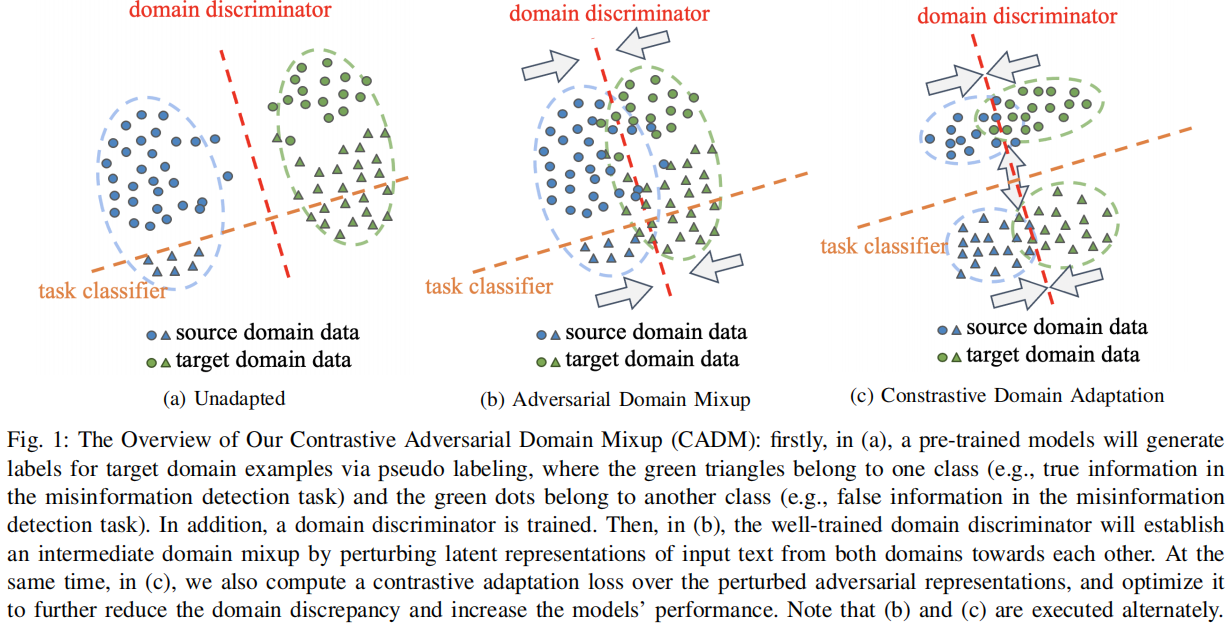
3.1 Domain Discriminator
第一步是训练一个域鉴别器 fDfD 来分类输入数据是属于源域还是属于目标域。该域鉴别器与 COVID 模型共享相同的 BERT Encoder fefe,并具有不同的二进制分类模块 fDfD。域鉴别器以 BERT Encoder 中的标记 [CLS] 表示作为输入,以预测输入数据的域,如所示:
y^=fD(z)(1)y^=fD(z)(1)
其中,zz 是 token [CLS] 的表示。
对于 fDfD 的训练,明确地将源域数据的域标签 yDyD 定义为 yD=0yD=0,将目标域数据的域标签定义为 yD=1yD=1。因此,对域鉴别器的训练可以表述为:
minfDE(x,yD)∼X′[l(fD(fe(x)),yD)](2)minfDE(x,yD)∼X′[l(fD(fe(x)),yD)](2)
其中,X′X′ 表示带有域标签的源域和目标域训练数据的合并数据集。
3.2 Adversarial Domain Mixup
在训练了域鉴别器后,我们提出直接干扰来自源域和目标域的输入数据的潜在表示到域鉴别器的决策边界,如 Figure 1b 所示。为此,来自两个域的扰动表示(即域对抗表示)可以变得更接近,表明域间隙减小。在此,从两个域生成的域对抗性表示在模型的潜在特征空间中形成了一个平滑的中间域混合。在数学上,通过求解一个优化问题,可以找到干扰训练样本 xx 的潜在表示 zz 的最优扰动 δ∗δ∗:
A(fe,fD,x,yD,ϵ)=maxδ[l(fD(z+δ),yD)] s.t. ∥δ∥≤ϵ,z=fe(x)(3)A(fe,fD,x,yD,ϵ)=maxδ[l(fD(z+δ),yD)] s.t. ‖δ‖≤ϵ,z=fe(x)(3)
注意,在上面的方程中,我们引入了一个超参数 ϵϵ 来约束扰动 δδ 的范数,从而避免了无穷大解。最后,将 Eq.3Eq.3 应用于合并训练集 X′X′ 中的所有训练样本,得到对抗域混合 Z′Z′:
Z′={z′∣z′=z+A(fe,fD,x,yD,ϵ),(x,yD)∈X′}:=Z′s∪Z′t(4)Z′={z′∣z′=z+A(fe,fD,x,yD,ϵ),(x,yD)∈X′}:=Zs′∪Zt′(4)
其中,Z′sZs′ 是扰动的源特性,Z′tZt′ 是受干扰的目标特征。我们使用投影梯度下降(PGD)来近似 Eq.3Eq.3 的解,如在[7],[8]。
3.3 Contrastive Domain Adaptation
接下来,受[6]的启发,我们提出了 ZadvZadv 的双重对比自适应损失,以进一步将源数据域的知识适应到目标数据域。首先,我们减少了类内表示之间的域差异。也就是说,如果一个表示从源数据域的标签是真(或假)和一个表示从目标数据域的伪标签是真(或假),那么这两个表示被视为类内表示,我们减少域之间的差异。其次,如 Figure 1c 所示,真实信息和虚假信息的表示之间的差异将被扩大。
为了计算我们提出的对比自适应损失,我们建议使用径向基函数(RBF)来度量标记类之间的差异。在[11]中,RBF 被证明是量化深度神经网络中不确定性的有效工具。由于我们的伪标记过程是为了自动过滤出目标域数据的低置信度标签,因此使用RBF来衡量标记类之间的差异可以有效地提高伪标签的质量,最终有助于模型的域适应。
在形式上,使用 RBF 内核的定义:k(z1,z2)=exp[−∥z1−z2∥22σ2]k(z1,z2)=exp[−‖z1−z2‖22σ2]
我们定义了错误信息检测任务的类感知损失如下:
Lcon (Z′)=−∑i=1|Z′s|∑j=1|Z′t|1(y(i)s=0,y^(j)t=0)k(z(i)s,z(j)t)∑|Z′s|l=1∑|Z′t|m=11(y(l)s=0,y^(m)t=0)−∑i=1|Z′s|∑j=1|Z′t|1(y(i)s=1,y^(j)t=1)k(z(i)s,z(j)t)∑|Z′s|l=1∑|Z′t|m=11(y(l)s=1,y^(m)t=1)+∑i=1|Z′s|∑j=1|Z′s|1(y(i)s=1,y(j)s=0)k(z(i)s,z(j)s)∑|Z′s|l=1∑|Z′s|m=11(y(l)s=1,y(m)s=0)+∑i=1|Z′t|∑j=1|Z′t|1(y^(i)t=1,y^(j)t=0)k(z(i)t,z(j)t)∑|Z′t|l=1∑|Z′t|m=11(y^(l)t=1,y^(m)t=0)(5)Lcon (Z′)=−∑i=1|Zs′|∑j=1|Zt′|1(ys(i)=0,y^t(j)=0)k(zs(i),zt(j))∑l=1|Zs′|∑m=1|Zt′|1(ys(l)=0,y^t(m)=0)−∑i=1|Zs′|∑j=1|Zt′|1(ys(i)=1,y^t(j)=1)k(zs(i),zt(j))∑l=1|Zs′|∑m=1|Zt′|1(ys(l)=1,y^t(m)=1)+∑i=1|Zs′|∑j=1|Zs′|1(ys(i)=1,ys(j)=0)k(zs(i),zs(j))∑l=1|Zs′|∑m=1|Zs′|1(ys(l)=1,ys(m)=0)+∑i=1|Zt′|∑j=1|Zt′|1(y^t(i)=1,y^t(j)=0)k(zt(i),zt(j))∑l=1|Zt′|∑m=1|Zt′|1(y^t(l)=1,y^t(m)=0)(5)
其中,y^ty^t 为目标域样本的伪标签,zz 表示标记 CLS 的表示。
3.4 Overall Contrastive Adaptation Loss
现在,我们将任务分类问题的交叉熵损失和上述对比自适应损失合并为 COVID 模型的单一优化目标:
Lall =Lce(X)+λLcon (Z′)(6)Lall =Lce(X)+λLcon (Z′)(6)
其中,LceLce 代表交叉熵损失函数。
4 Experiment
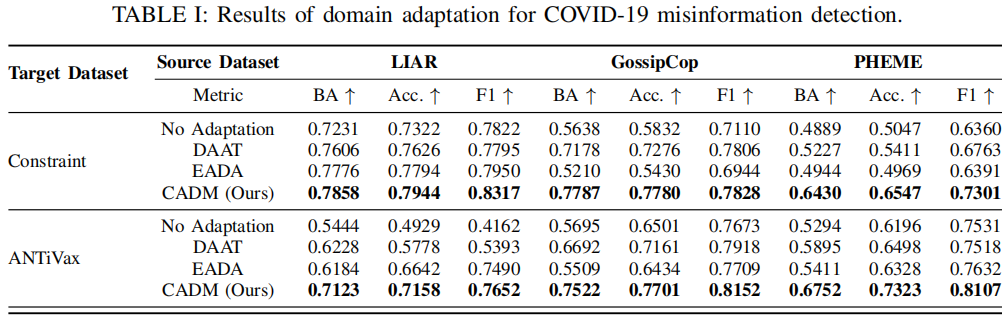
在我们的实验中,我们使用了三个 source misinformation datasets :GossipCop , LIAR and PHEME,两个 COVID misinformation datasets:Constraint and ANTiVax。
__EOF__
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK