

干货 | 数据仓库建模超详细攻略!
source link: https://www.woshipm.com/data-analysis/5695063.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

数据仓库建模,就是数据的组织和存储方法,它强调从业务出发,将数据有序组织和存储起来。本文作者对数据仓库建模常用模型进行了分析,一起来看一下吧。

一、数据仓库建模是什么?
数据仓库建模就是数据的组织和存储方法,举个例子,数据仓库的建模就类似于家庭物品收纳问题,我们会按照物品的特性以及自身的喜好将物品进行一个井然有序的整理收纳,使我们清晰地知道物品归放的位置,便于日后查找使用,也能无形地让大脑标记物品位置,形成归类统一意识,渐渐成为一种好习惯。
数据建模也是如此,它强调从业务出发,将数据有序组织和存储起来,只有做到这样,数据才可以高效率、高质量、高性能、低成本地使用,才可以更好地支持企业决策,赋能企业业务,提升企业综合实力。
二、数据仓库建模常用模型浅析
1. ER模型(实体关系模型)
数据仓库之父Bill Inmon提出的建模方法是从全企业的高度,用实体关系(Entity Relationship,ER)模型来描述企业业务,并用规范化的方式表示出来,在范式理论上符合3NF。
1)什么是实体关系模型
实体关系模型由美籍华裔计算机科学家陈品山发明,用概念数据模型的描述所使用的数据或模式图,实体关系模型将复杂的数据抽象为两个概念——实体和关系。实体表示一个对象,例如商店、员工这两个对象,关系是指两个实体之间的关系,例如员工和商店的从属关系。对象与对象的关系可以分为1-1,1-n,n-n这三种类型,举例说明:
- 1-1:一个商店只能有一个店长,一个店长只能在一个商店中任职,则商店和店长就是1对1的关系。
- 1-n:一个商店有很多雇员,雇员只属于这个商店。则商店和雇员就是1对多的关系。
- n-n:商店里有很多商品,商品也可以在多个商店售卖,则商店和商品就是多对多的关系。
2)范式理论是什么?
范式是表结构设计标准的级别,是关系的约束条件的规范,关系型数据库的范式一共有六种,分别是第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF)。遵循的范式级别越高,数据冗余性就越低。
因为数据仓库ER建模遵循3范式标准,本文就只针对于前3个范式进行讲解,其他的范式不再赘述, 感兴趣的读者可以自己查询下相关资料。
数据库规范化就是使用一系列范式设计数据库(通常是关系型数据库)的过程,其目的是减少数据冗余,增强数据的一致性,必须要注意的一点是范式存在前置依赖,如要使用第三范式,设计数据库时必须依赖于使用前两个范式的之后,才可以按照第三范式的继续设计数据库表。具体设计时要根据业务实际流程,一般遵循第三范式即可。
第一范式:强调列的原子性,要求每列属性不可分割。

上图数据列中商品这一列的数据不是原子数据,它可以继续分割成商品数量和商品名称,按照第一范式进行调整后,如下图所示:

第二范式:在1范式的基础上,要求属性必须依赖于主键,不能存在部分函数依赖。
函数依赖:某个属性集x决定另一个属性集y时,称另一属性集y依赖于该属性集x。如学号和姓名,通过学号可以找到姓名,那么就说姓名依赖于学号。
完全函数依赖:通过xy能得到z,但是单独通过x或者通过y得不到z,那么就称z完全依赖于xy。如:学号,课程和成绩。可以通过学号和课程得到成绩,但是单独通过课程和学号得不到课程,就说成绩完全依赖于课程和学号。
部分函数依赖:通过xy能得到z,通过x得到z或者通过y也可以得到z,那么就说z部分依赖于xy,如学号、姓名和性别,通过学号和姓名可以找到性别,也可以通过学号单独找到性别,就说性别部分依赖于学号和姓名。
传递函数依赖:通过x能得到y,通过y得到z,那么就说z传递依赖于x,如通过学号得到班级名称,在通过班级名称找到班主任,就可以说班主任传递依赖于学号。
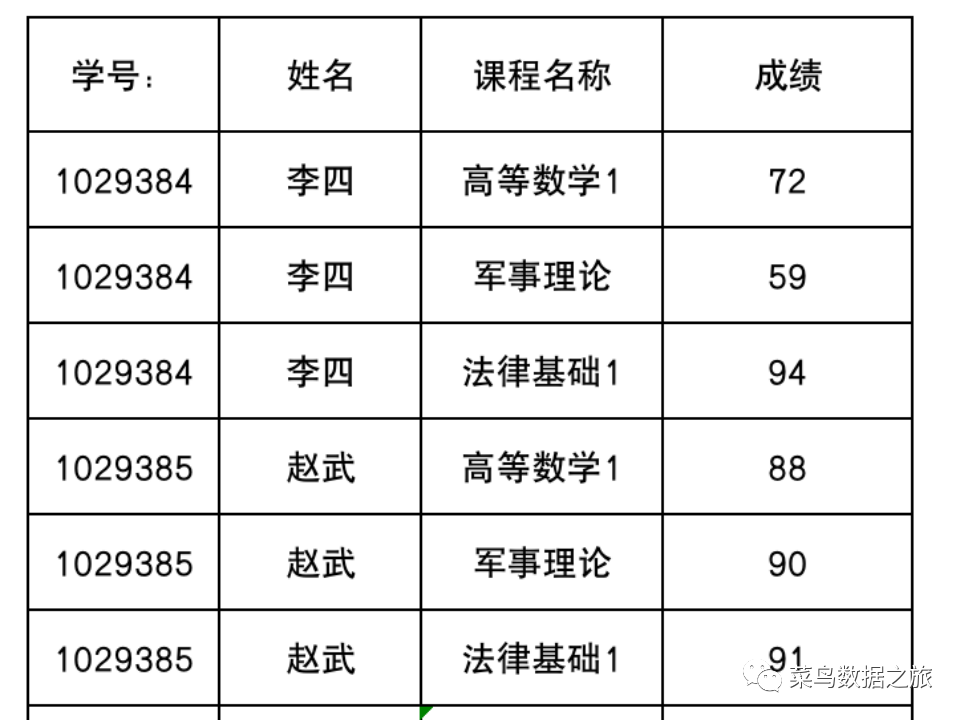
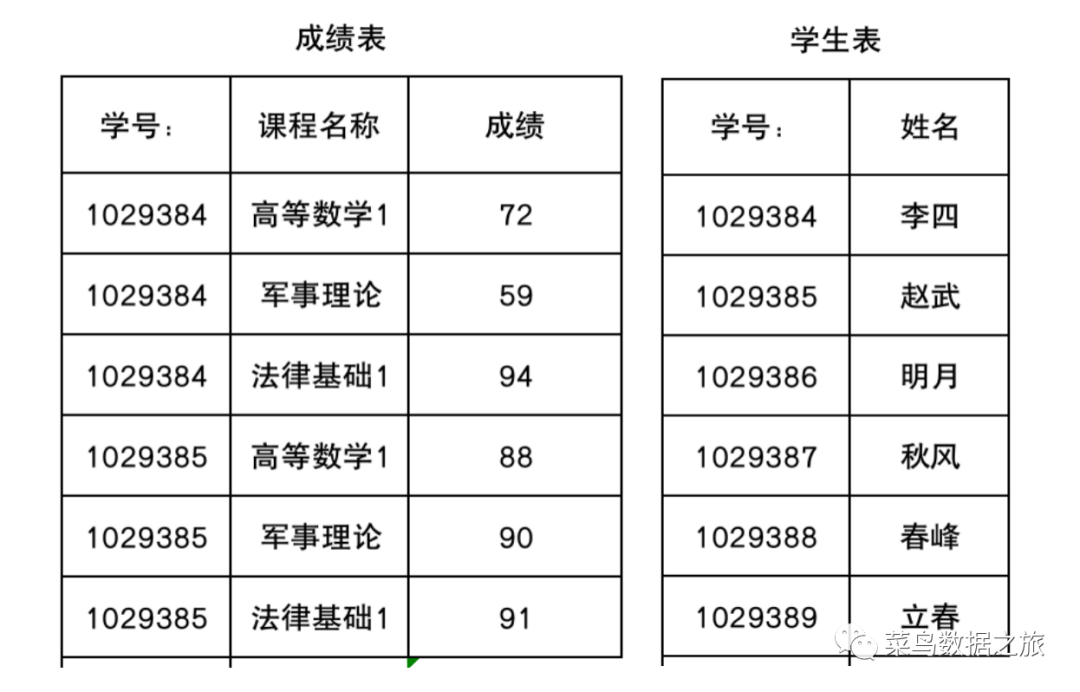
如上图所示:表中的主键如果是(学号、课程)的话,通过(学号、课程)可以找到成绩,分数是完全依赖于(学号、课程)但是姓名可以单独通过学号找到,姓名不完全依赖于找到(学号、课程),故不符合第二范式。调整后如下所示:
第三范式:消除依赖传递,任何非主属性不依赖与其他非主属性。
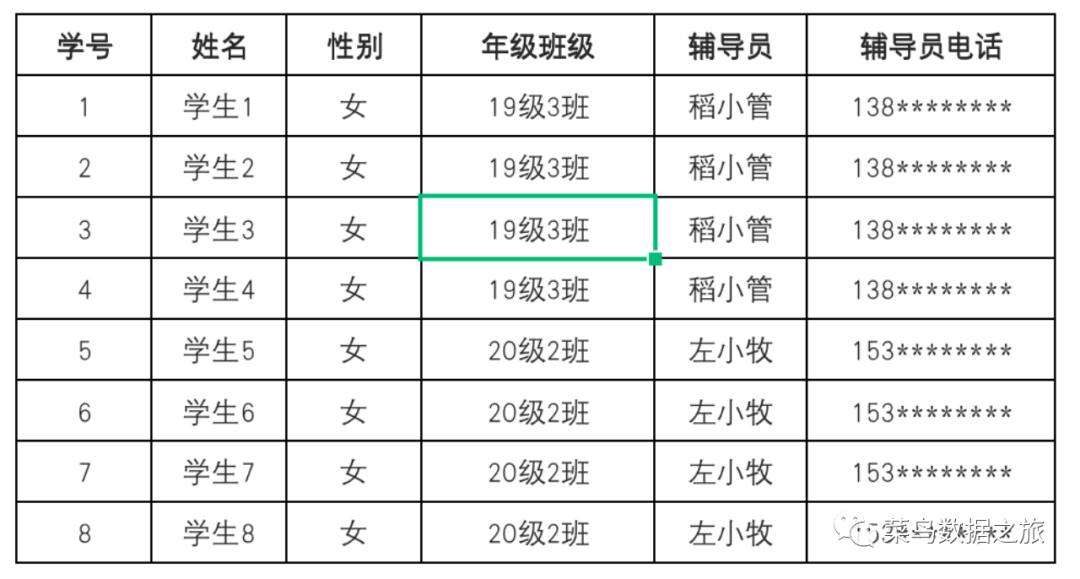
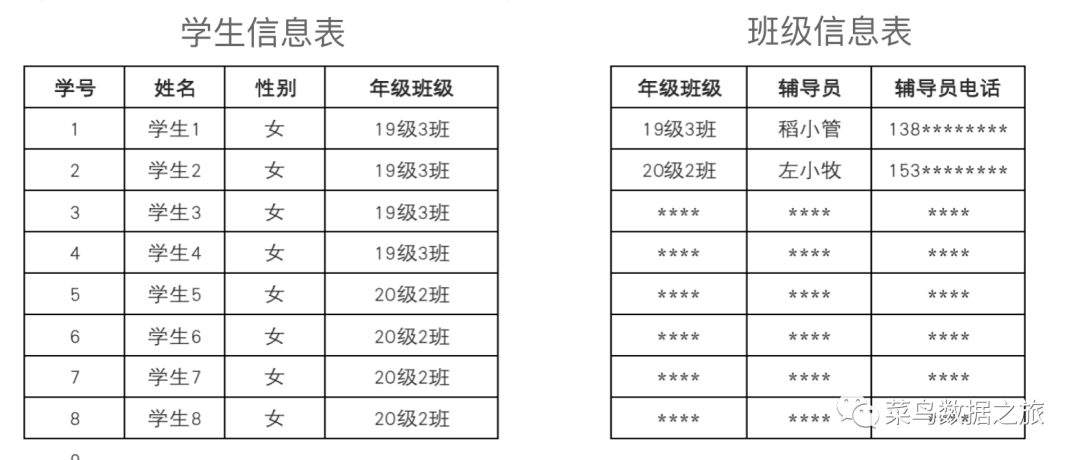
如图所示:上边这张表中,如果想要找到辅导,通过学号找到班级,通过班级找到辅导员,存在很明显的函数依赖,故不符合第三范式要求,调整后如图所示:
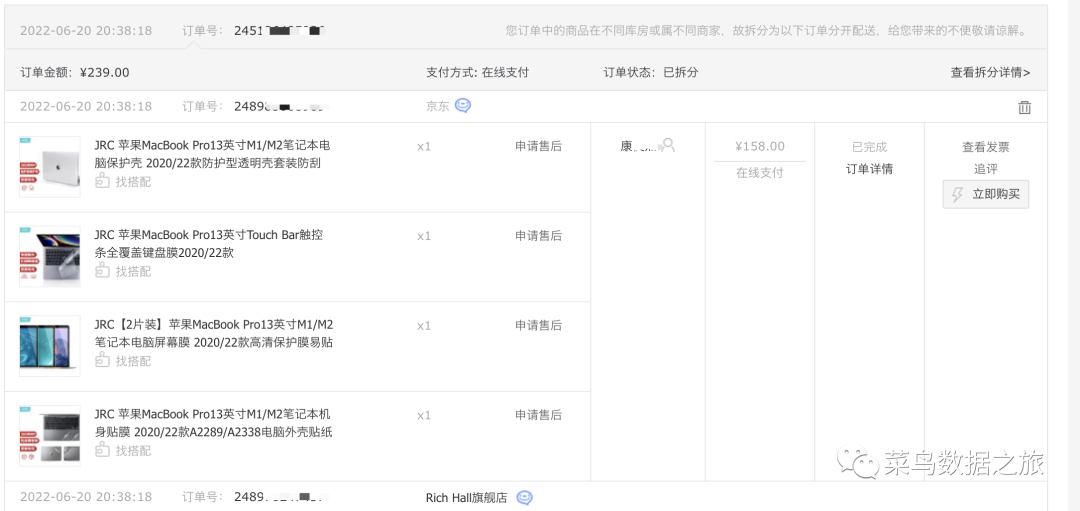
以上就是关于三范式的相关讲解,那么按照Bill Inmon提出的数仓建模思想,用ER模型进行建模,首先以京东商城订单流程为例子,整个交易环节中包含下单,取消订单、支付,拆单、退款,发货、收货、退换货、评价等,下图为京东商城订单截图。
那么我们以订单业务为例,采用ER模型遵循3范式建模,按照这种方式将数据进行规范化处理,则可以构建出下图所示的数仓模型,值得注意的是下图只是将一部分交易流程进行了绘制,订单风控、订单退货退款、订单评价等还没有绘制到模型中。
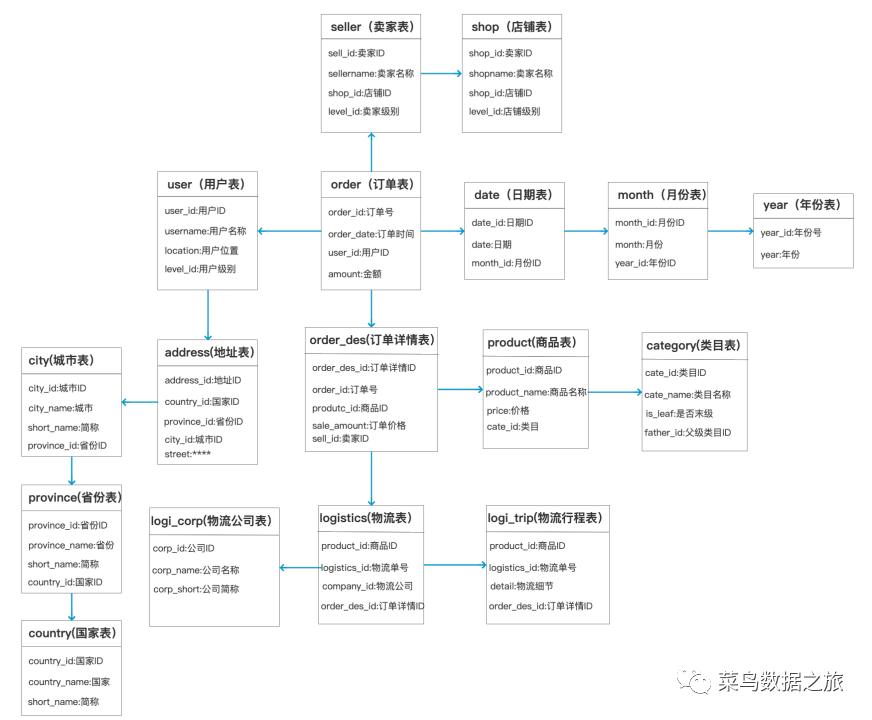
从图中我们可以看出按照这样的方式进行数据建模,虽然减少了数据冗余性,保证了数据的一致性,但是如果要查询一个相关的指标或者事实可能需要关联十几张表,在数据量小,有索引的情况下可能还好些,如果数据量十分惊人,数以亿计,那查询的速度可能十分缓慢,甚至可能会造成宕机,显而易见这种模型不太适合直接应用于业务分析和计算场景。
2. 维度模型
维度模型是Ralph Kimball 在90年代提出的数仓建模理论,并在于1996年发布的《The Data Warehouse Toolkit》一书中详细介绍了维度建模理论知识。
维度建模之所以能受到广泛的关注和认可,一方面是因为它从企业决策分析作为出发点,为数据分析服务,它的初衷是旨在,使用户更快的完成数据分析,以及更好地实现大规模复杂的查询操作。另外一方面,得益于技术的发展,基础存储硬件的成本逐年降低,同时硬件的计算性能也大幅度提升,才使得维度建模能够走上历史舞台,得到海内外企业和用户的认同。
维度模型将企业的业务通过两个方面进行数据建模,即事实表和维度表。事实通常指企业具体的业务过程,如登录、注册、加购、下单等等,需要注意的是建模时通常会选择最细粒度的业务过程数据作为事实表,如订单事实表会选订单明细表作为基础事实表,而上边简述的ER模型则选订单主表作为基础,维度通常指业务过程发生时所处的环境,如何人、何地、何时、何种东西,何种方法做了哪些事情。
具体细节应该联系业务过程,通过5W2H的方法进行分析,绘制出具体的总线矩阵。按照维度建模理论,我们将上述订单过程进行了一个初步建模,中间的为事实表,周边的为维度表,需要注意的是,本次建模的内容和上边ER模型讲解保持了一致,所以也没有涵盖所有的维度,如图所示:
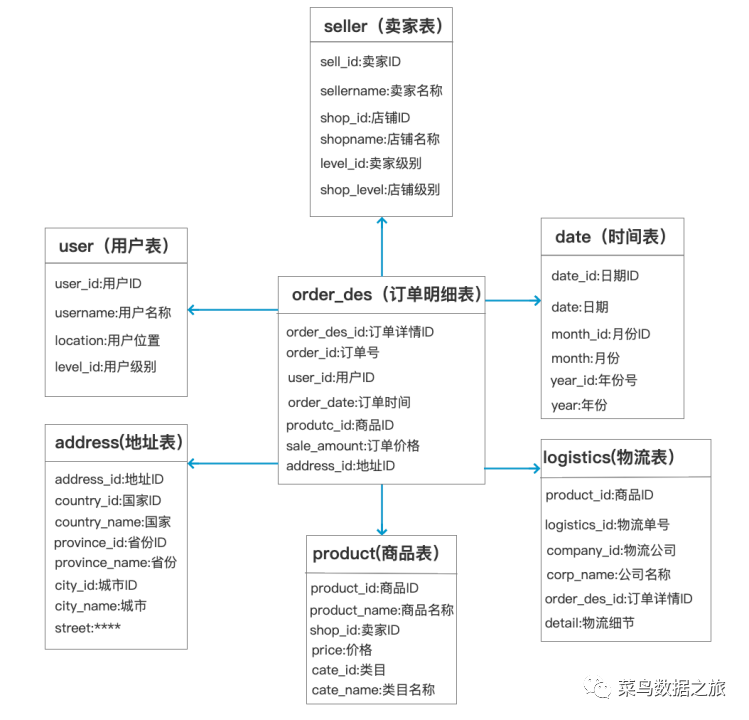
从上图中可以看出,维度建模数据结构相对ER模型来说,更为清晰简洁,查询时连表操作相对较少,可以及时响应大量且复杂的查询操作,提升业务分析速度,快速支持业务决策。但是数据存在大量冗余,需要消耗大量存储空间。
本文由 @菜鸟数据之旅 原创发布于人人都是产品经理,未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK