

谈谈数据湖和数据仓库
source link: https://www.51cto.com/article/740947.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

谈谈数据湖和数据仓库
数据湖是近十年来出现的一个术语,用于描述大数据世界中数据分析管道的重要组成部分 。这个想法是为组织中的任何人可能需要分析的所有原始数据建立一个单一的存储区。人们通常使用 Hadoop 来处理湖中的数据,但这个概念比 Hadoop 更广泛。
当提到一个单一的点可以将一个组织想要分析的所有数据集中在一起时,我立即想到了数据仓库和数据集市的概念。但是数据湖和数据仓库之间有一个重要的区别。数据湖以数据源提供的任何形式存储原始数据。没有关于数据模式的假设,每个数据源都可以使用它喜欢的任何模式。数据的使用者需要根据自己的目的来理解这些数据。
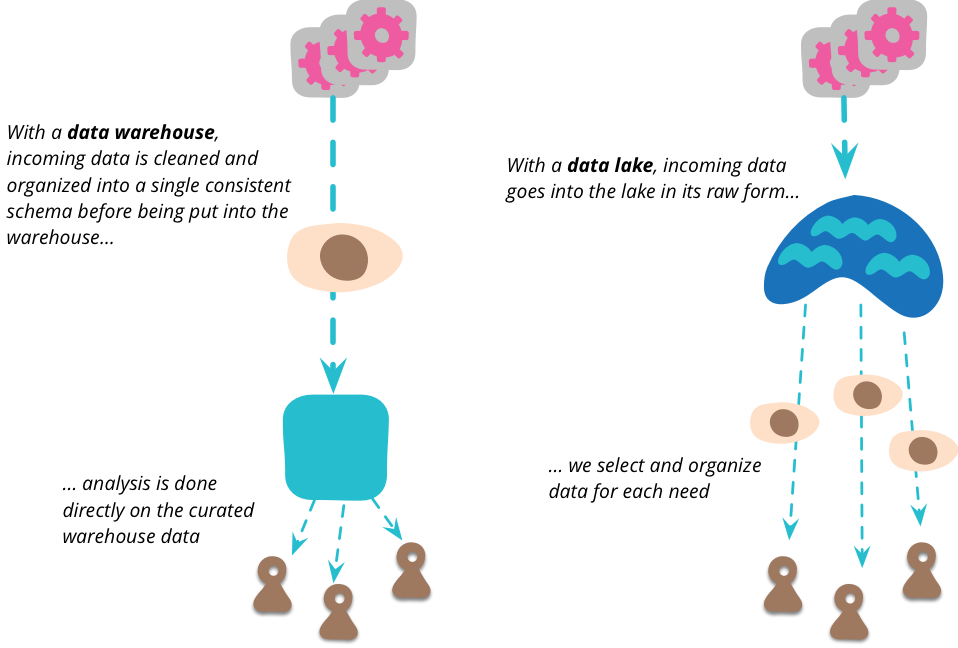
许多数据仓库由于模式问题而没有取得太大进展。数据仓库倾向于采用单一模式的概念来满足所有分析需求,但单一的统一数据模型对于除最小组织之外的任何组织都是不切实际的。即使要为稍微复杂的域建模,也需要多个有界上下文,每个都有自己的数据模型。在分析方面,需要每个分析用户使用对他们正在进行的分析有意义的模型。通过转向仅存储原始数据,这将责任推给了数据分析师。
数据仓库的另一个问题是确保数据质量。试图获得权威的单一数据源需要对不同系统如何获取和使用数据进行大量分析。系统 A 可能适用于某些数据,而系统 B 可能适用于其他数据。这便会遇到一些规则,系统 A 更适合最近的订单,而系统 B 更适合一个月或更早以前的订单,除非涉及退货。最重要的是,数据质量往往是一个主观问题,不同的分析对数据质量问题的容忍度不同,甚至对什么是好质量的概念也不同。
这导致了对数据湖的批判——它只是质量参差不齐的数据的垃圾场,更确切地说是数据沼泽。批评既有道理又无关紧要。新分析的热门标题是“数据科学家”。尽管这是一个经常被滥用的头衔,但这些人中的许多人确实拥有扎实的科学背景。任何严肃的科学家都知道数据质量问题。试想一下随时间分析温度读数的简单问题,必须考虑到某些气象站的重新定位可能会微妙地影响读数、设备问题导致的异常、传感器不工作时的缺失时段数据。许多复杂的统计技术都是为了解决数据质量问题而创建的。科学家总是对数据质量持怀疑态度,习惯于处理有问题的数据。所以对他们来说,湖泊很重要,因为他们可以使用原始数据,并且可以慎重地应用技术来理解它,而不是一些可能弊大于利的不透明数据清理机制。
数据仓库通常不仅会清理数据,还会将数据聚合成一种更易于分析的形式。但科学家们也倾向于反对这一点,因为聚合意味着丢弃数据。数据湖应该包含所有数据,因为不知道人们会发现什么有价值,无论是今天还是几年后。
它们正在被一些月末处理报告修改。所以简而言之,数据仓库中的这些值是无用的;科学家担心无法进行这种比较。经过更多挖掘,发现这些报告已被存储,因此可以提取当时所做的真实预测。这种原始数据的复杂性意味着有空间将数据整理成更易于管理的结构以及减少相当大的数据量。不应该直接访问数据湖。因为数据是原始数据,所以需要很多技巧才能理解它。在数据湖中工作的人相对较少,因为他们发现了湖中通常有用的数据视图,他们可以创建许多数据集市,每个数据集市都有一个针对单个有界上下文的特定模型。然后,更多的下游用户可以将这些集市视为该上下文的权威来源。
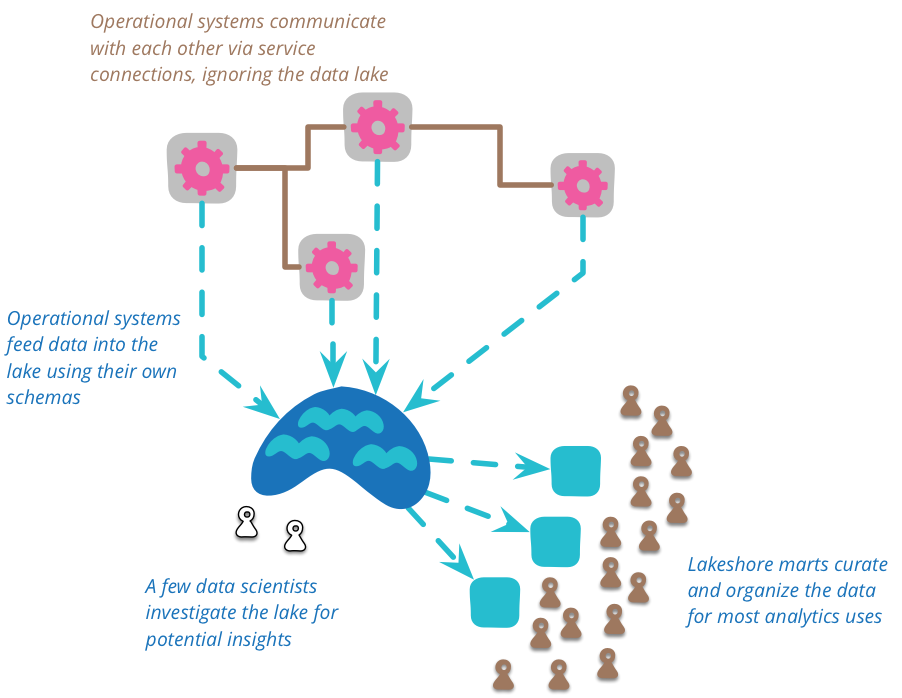
现在,很多时候我们已经将数据湖视为跨企业集成数据的单一点,但应该指出,这并不是它最初的意图。这个词是 James Dixon 在 2010 年创造的,当时他打算将数据湖用于单个数据源,多个数据源将形成一个“水上花园”。尽管有最初的表述,但现在普遍的用法是将数据湖视为整合了许多来源。
我们应该将数据湖用于分析目的,而不是用于业务系统之间的协作。当业务系统协作时,它们应该通过为此目的设计的服务来实现,例如 RESTful HTTP 调用或异步消息传递。
重要的是,所有放入湖中的数据都应该有明确的时间和地点来源。每个数据项都应该清楚地跟踪它来自哪个系统以及何时生成数据。因此,数据湖包含历史记录。这可能来自将业务系统事件馈送到湖中,也可能来自定期将当前状态转储到湖中的系统——当源系统没有任何时间能力但想要对其数据进行时间分析时,这种方法很有价值。
数据湖是无模式的,由源系统决定使用什么模式,并由消费者决定如何处理由此产生的混乱。此外,源系统可以随意更改其流入数据模式,而消费者也必须应对。显然,我们更希望此类更改的破坏性尽可能小,但科学家更喜欢全面的数据而不是缺失数据。
数据湖将变得非常大,并且大部分存储都围绕着大型无模式结构的概念——这就是为什么 Hadoop 和 HDFS 通常是人们用于数据湖的技术。数据湖中集市的一项重要任务是减少需要处理的数据量,这样大数据分析就不必处理大量数据。
数据湖对大量原始数据的存储引发了有关隐私和安全的尴尬问题。数据湖对黑客来说是一个诱人的目标,他们可能喜欢把选择的数据块吸进公共海洋。限制小型数据科学组织直接访问数据湖可能会减少这种威胁,但无法避免该组织如何对其获取的数据的隐私负责的问题。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK