

论一个合格的NOC-SLA场景是如何养成的
source link: https://www.51cto.com/article/740873.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

论一个合格的NOC-SLA场景是如何养成的
在所有的互联网企业中,告警经常性的误告,都是让技术人员最头疼的问题之一。试想一下,在凌晨两三点时,你收到了来自告警平台的电话告警,于是你揉了揉惺忪的双眼,短暂的回味了下刚才的美梦,下床打开电脑,开始排查问题,却发现这是一个误告,线上业务都是在有序的运行当中,于是你关上电脑,重新上床睡觉,但此时你已睡意全无,在床上辗转反侧一个小时才睡着,于是乎,第二天同事看到了一脸沧桑的你。这种误告一次两次还能接受,但如果是每隔一天或者是每晚都会触发呢?
因此在互联网行业中,频繁的误告通常会遇见如下几个问题:
单位时间内有效信息获取率变低,技术人员很难从频繁的误告中得到真正有问题的告警;
真正的问题发生时,犹如《狼来了》一样,认为都是误告,大大加长了问题的发现时间;
降低技术人员的工作效率,每天都沉浸在对于各种告警的处理当中,降低人员产出;
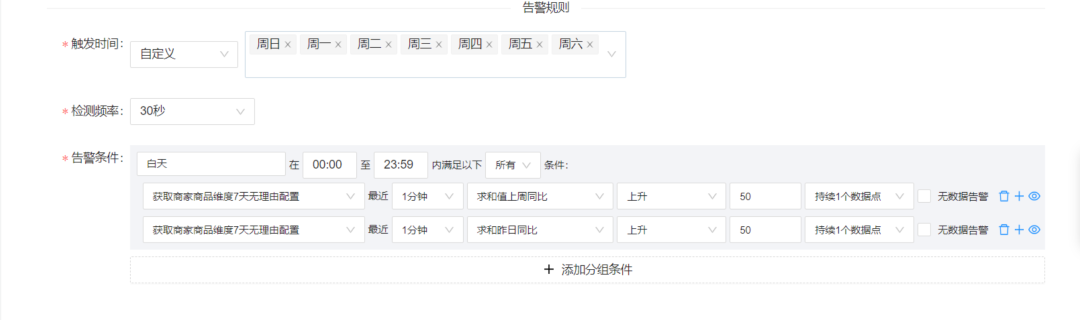
在对于SLA告警的摸索阶段,团队就已经预估到后面可能面临着大量噪音的骚扰,因此组建起一个告警测试群,用于针对性的调优;团队为了测试线上告警误告水位,测试性地将SLA场景告警规则进行接入。果不其然,上个厕所回来,群里已经积攒上百条告警了,根本无法提取出有效的告警,其原因就是我们的告警规则配置都是相对单一的,全天候就一条规则,如:
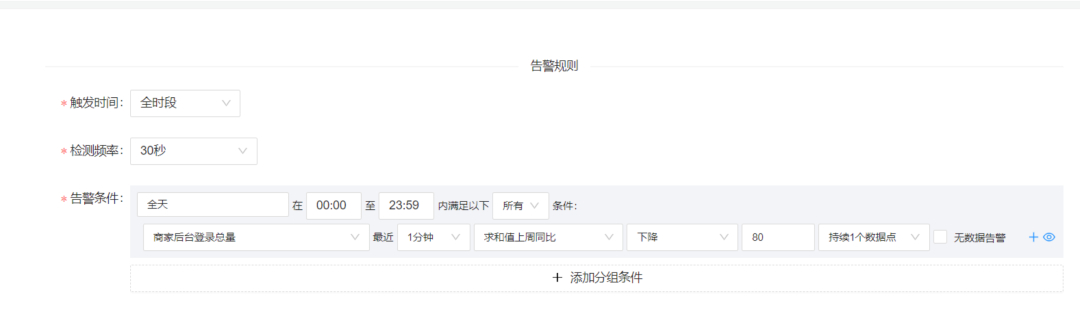
为了在告警正式上线后,大家晚上能有一个如婴儿般的睡眠,我们自然而然的就启动了对于噪音的治理工作。而告警噪音的治理最重要的就是对于利弊的权衡,如果阈值设置过高,可能线上问题无法发现;如果阈值过低,又会导致噪音频发,所以对于阈值的调整里边有很大的学问。
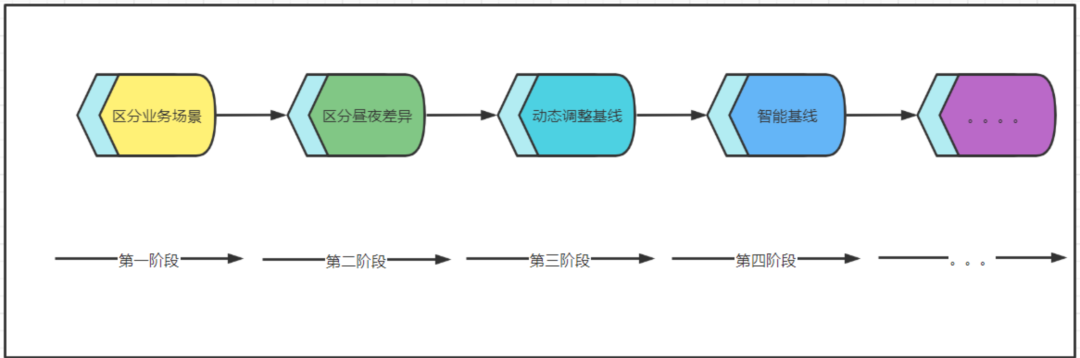
区分业务场景。我们创新性地将场景分为平稳型、波浪型、突发型,它们的定义如下:
平稳型:日常流量波动在30%以内,流量波动小;
波浪型:日常流量波动在30%以外,流量波动较大;
突发型:日常流量波动在30%以内,但在遇见某些突发情况下,如重大活动或者时间,波动会超过30%;
针对不同类型的场景,我们也拥有不同的告警配置方案,比如平稳型,那么就可以评估一下该场景的波动范围,在其正常的波动的范围内,进行设置阈值,比如大部分时间我们的取消订单,相比于前七天的平均值,波动在30%以内,如下:
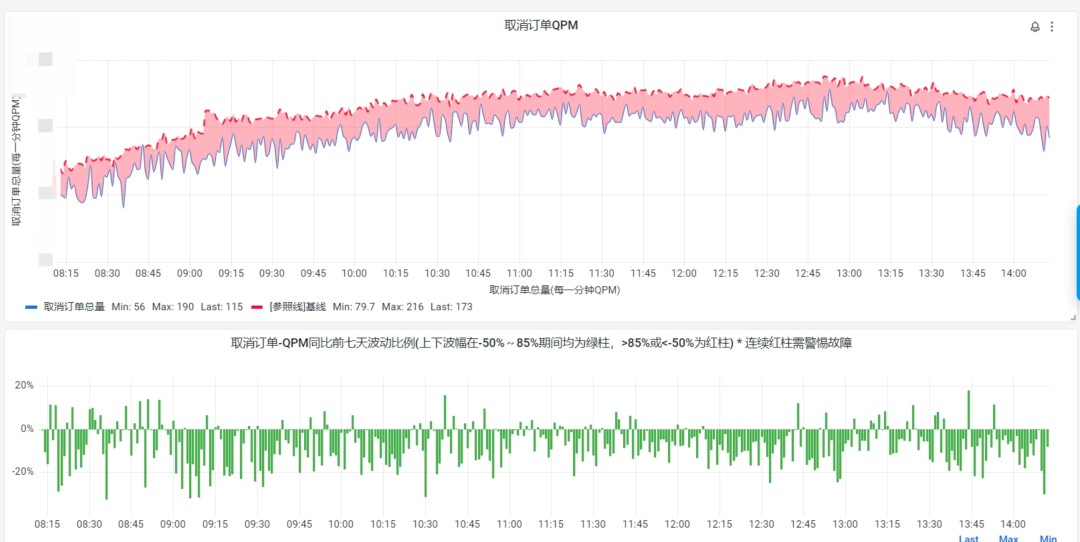
那么我们经过两三天的观测,我们就可以将告警阈值设置在30%,于是告警的设置就会如下:
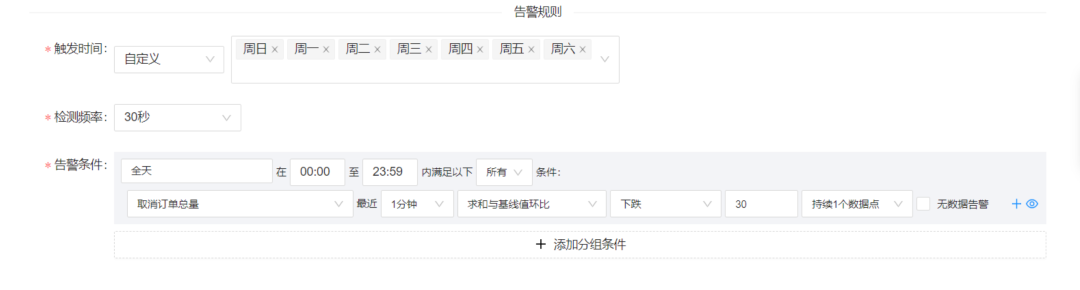
上升告警也是同理,将阈值设置到30%。
那么针对于波浪形告警,我们的阈值范围可能就会设置的大一点,比如到50%,并且设置与昨日同比等多种规则来限制噪音,例如:
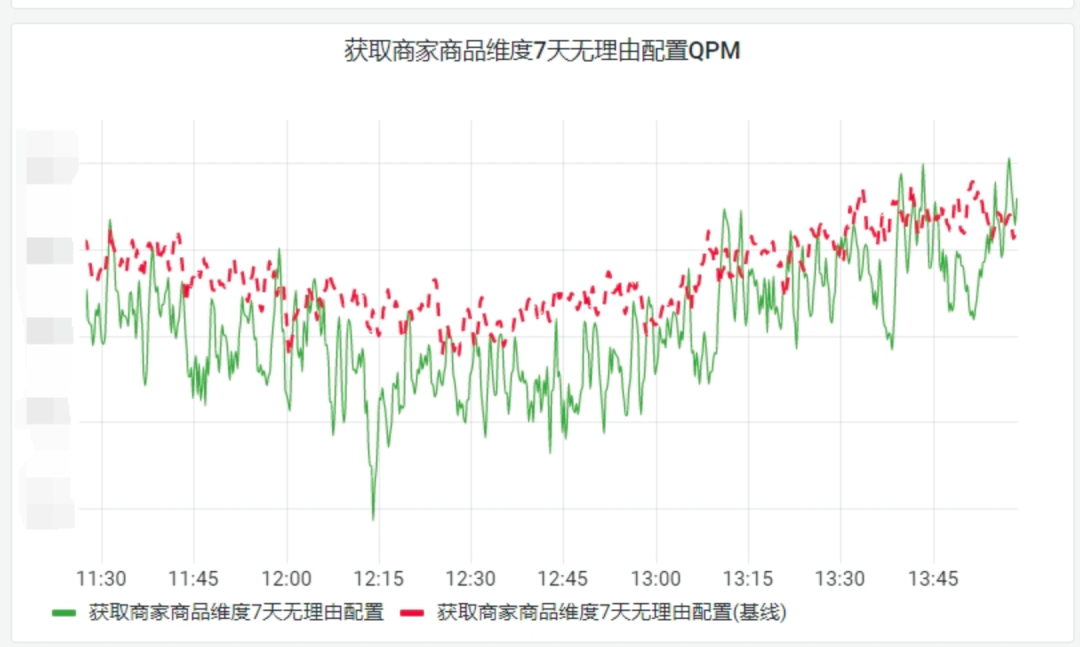
这样我们配置的规则就会相对复杂,利用昨日以及基线的量来进行综合判断。
在我们告警都上了之后,发现白天的噪音相对有了一定的改善,但夜间由于流量波动大,导致经常性流量波动比能大于30%,进而触发告警,如下图所示:
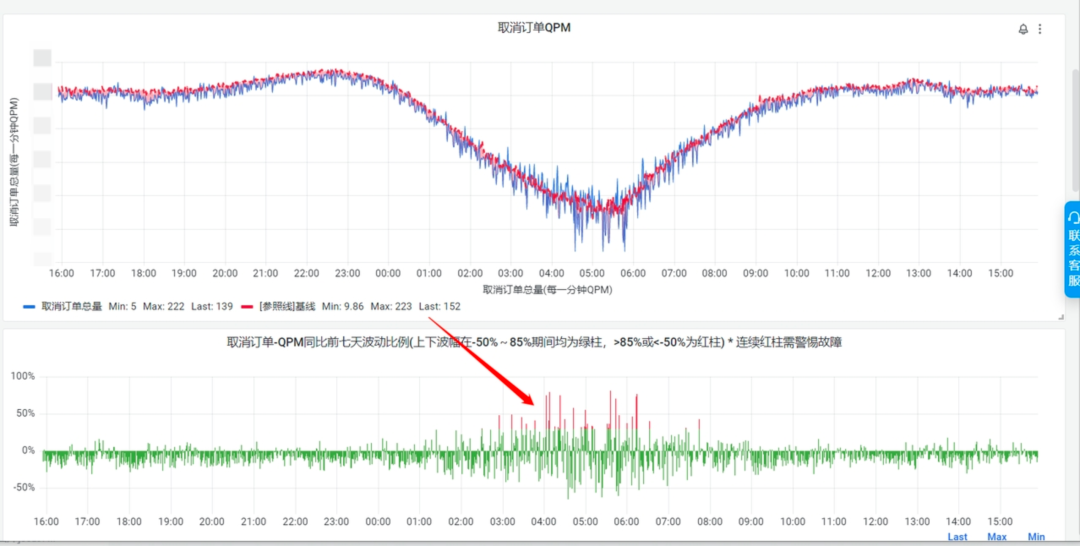
如果在这个时候,我们为了适应夜间的大波动,而将30%的阈值拉长,修改到50%甚至80%,这样的话确实在一定程度上降低了噪音的产生;但在另一方面,我们的告警发现率可能会大大降低。假如出现线上故障的时候,流量波动下小于我们设置的阈值范围,那么整个配置都没有意义。在这个时候,我们就开始构思区分白天和夜间,跑两套规则,保证噪音相对较低的同时,也能反映出线上的问题,于是取消订单的规则就变成了如下所示:
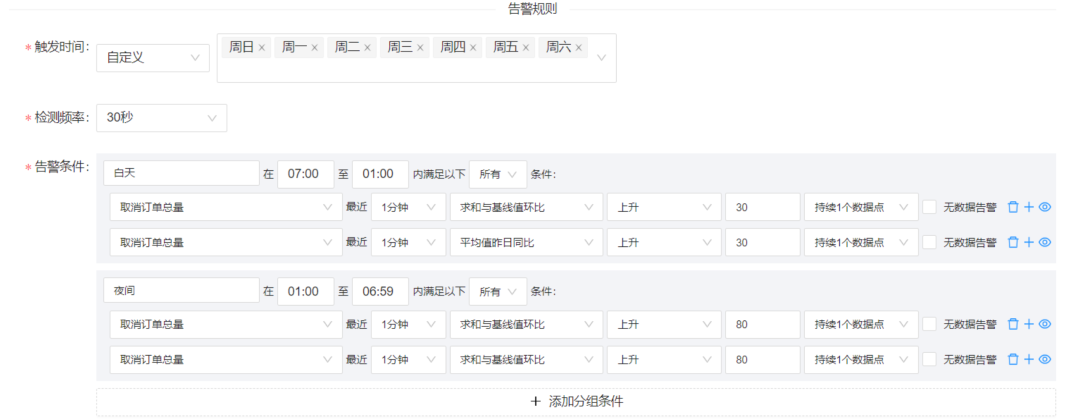
与此同时,我们也发现,线上流量并不稳定,可能这段时间低一点,过段时间来个大促,流量就上升的厉害,导致告警频繁的触发,这个时候技术人员又会面临大量的告警骚扰,而很难从中发现真正有问题的告警。
10月1号大盘数据
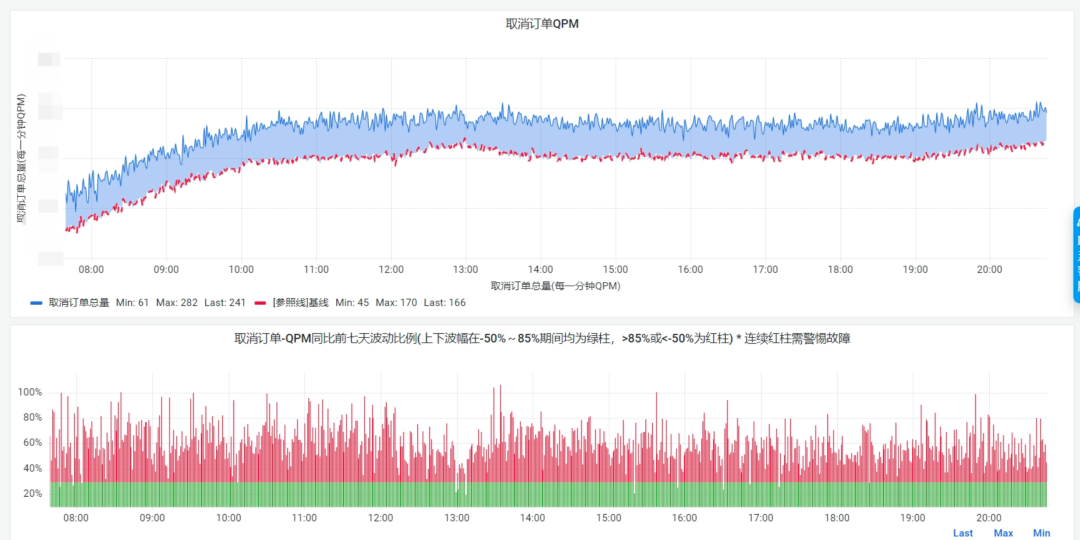
告警触发数据
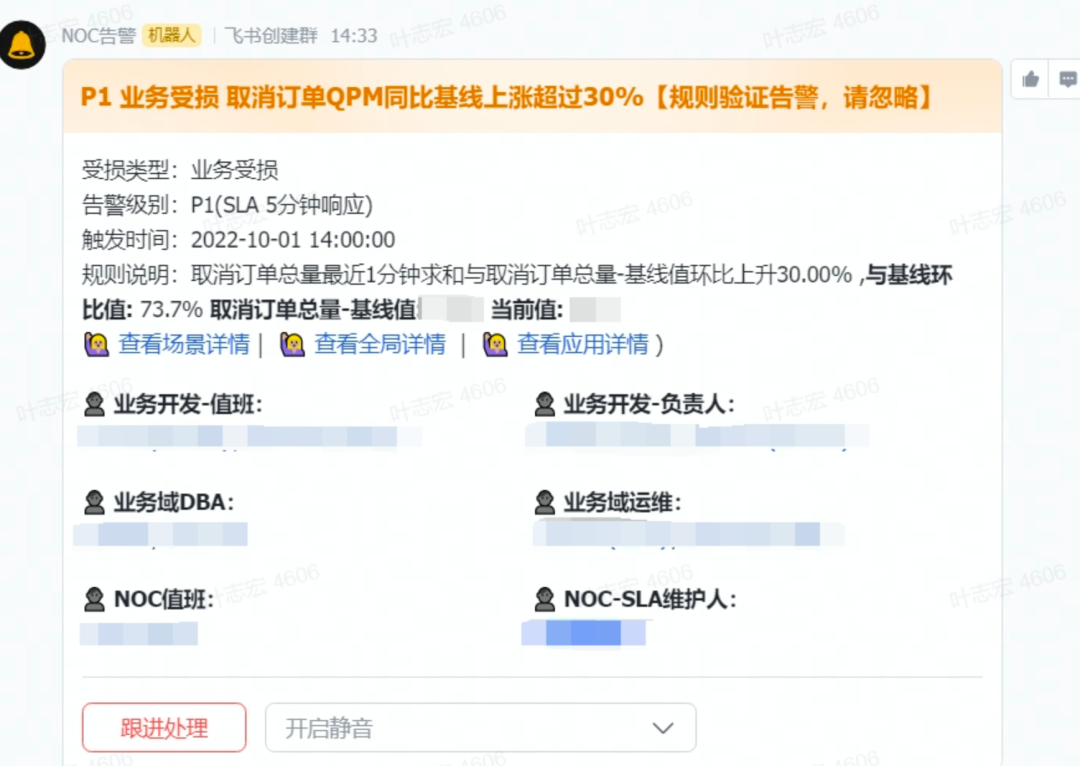
在此基础上,整个团队集思广益,讨论如何破局。因此就有了如下的解决方案,既然线上流量是实时波动的,容易受各种事件影响,那么基线为何一定要简单粗暴的只取前七天的一个平均值呢?为何我们不能在此基础上,让基线也可以动态调整,并且尽可能匹配线上流量呢?
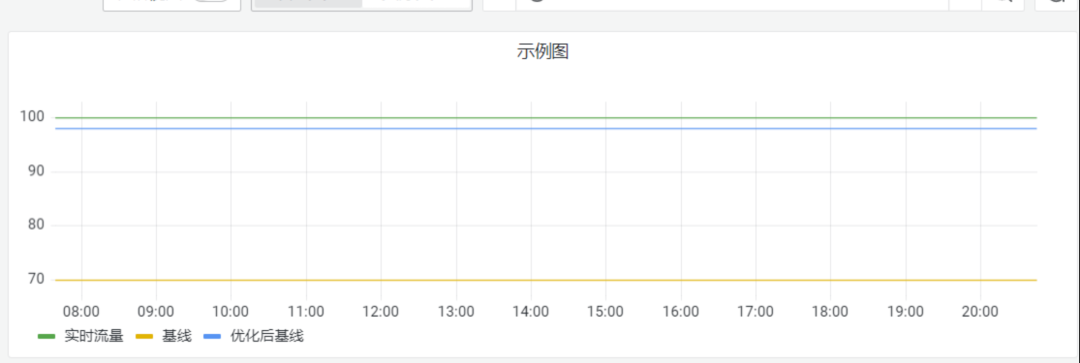
如上图所示,当我们实时流量与线上真实流量偏差较大的时候,我们可能让基线尽可能的靠近线上实时流量,从而更好的评估线上流量水平,不至于让我们的告警失灵,产生过多的噪音;针对取消订单场景,我们也做了如下调整:
调整前(红色部分表示波动超过30%)
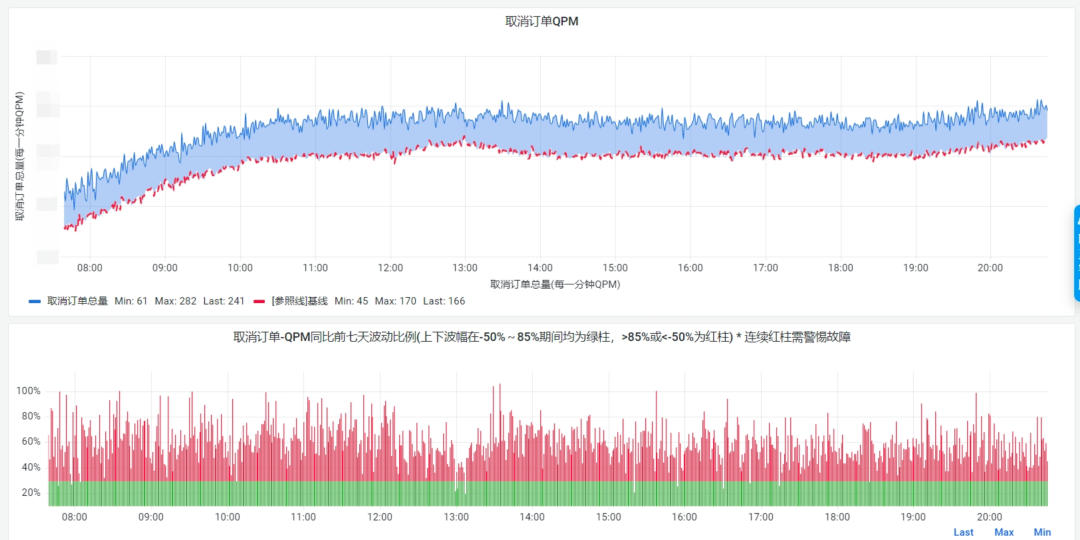
调整后(红色部分表示波动超过30%)
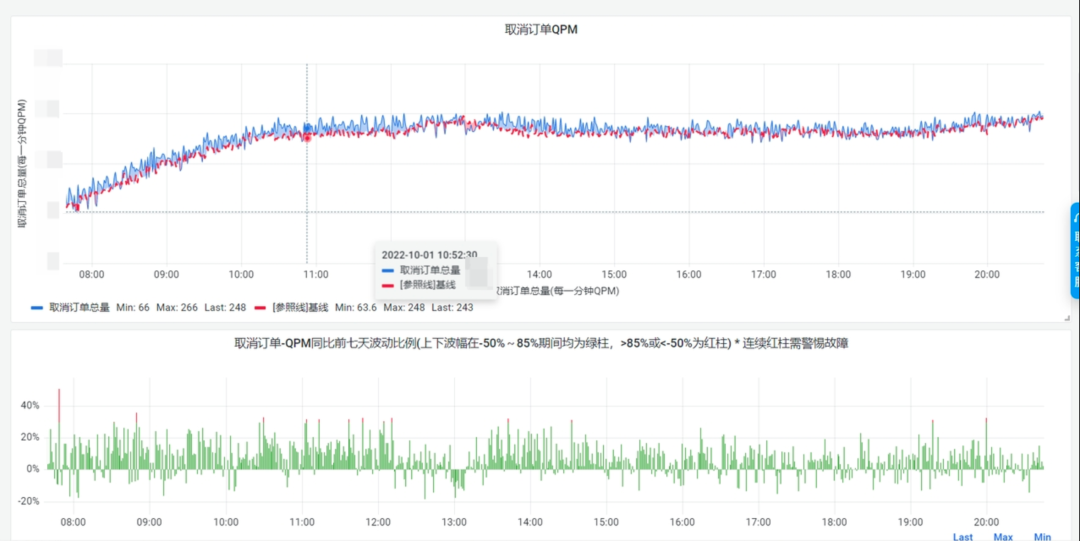
从大盘上可以看到,明显经过调整后,大部分时候的波动能够保持在30%内,大大减少了噪音的产生。
C端告警数据
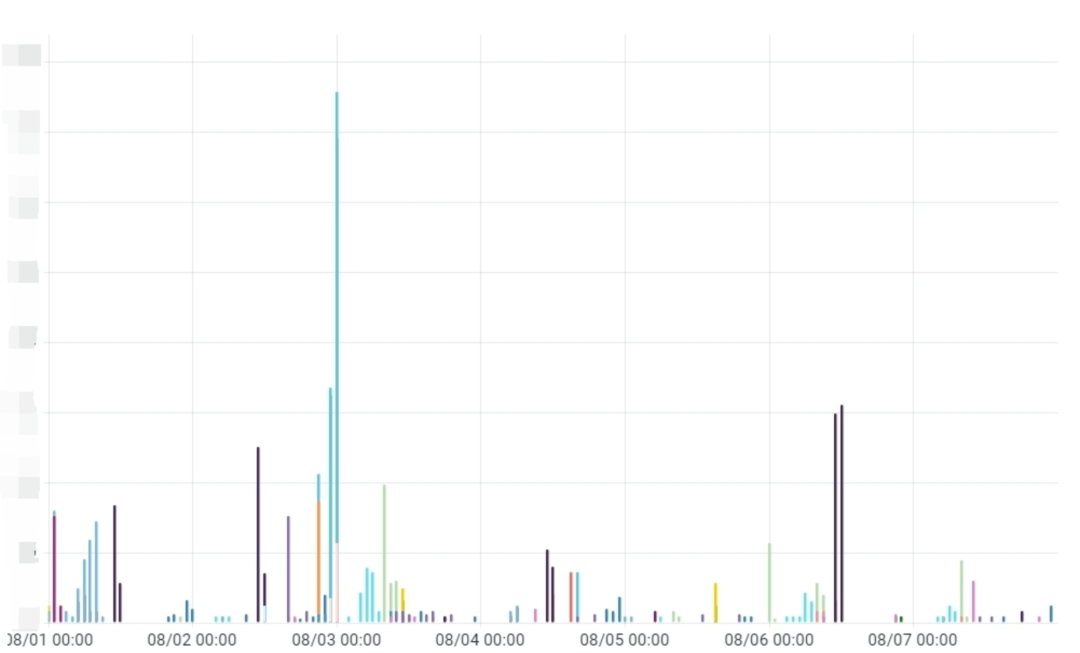
B端告警数据
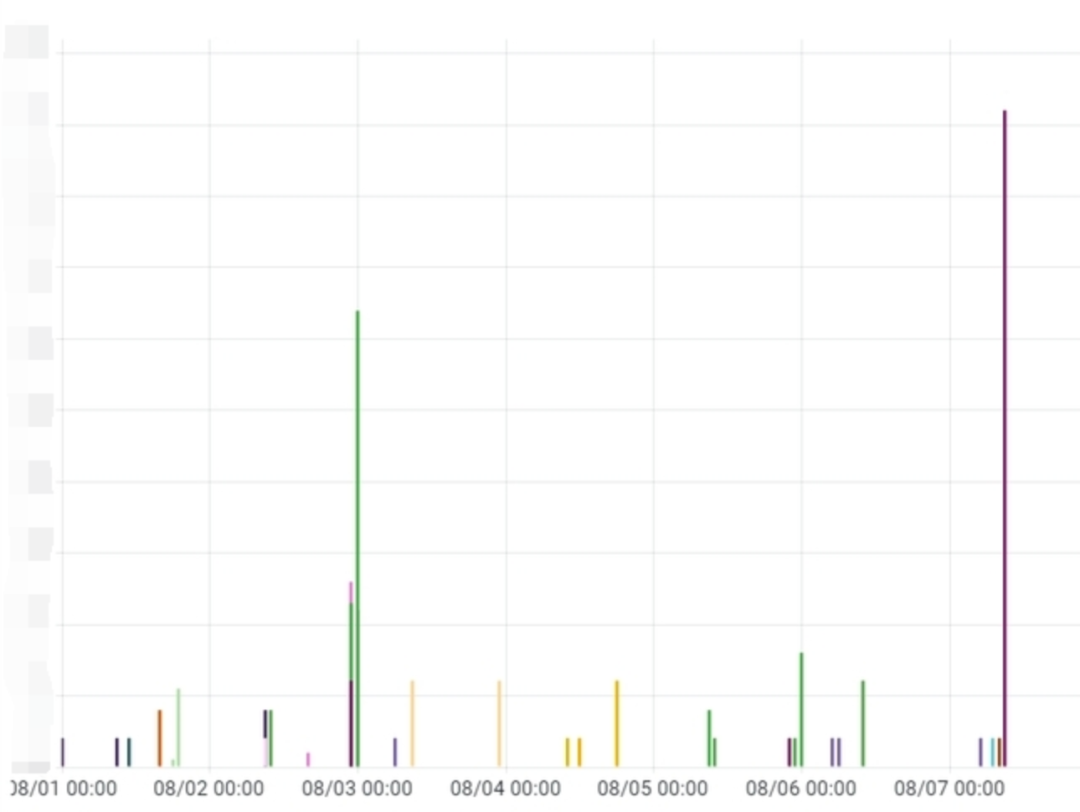
整个团队在现有基础成果上,为了减小人员的投入以及负担,开始探索能否有一种手段,可以让大家不为了应对线上水位变化,而频繁调整SLA场景基线呢?
答案就是智能基线,智能基线它能根据过往的数据,智能的推测出流量的曲线图,并评估出流量的最高水位(上限)以及最低水位(下限),在保证告警噪音相对较小的情况下,帮助我们更便捷以及灵敏的发现线上问题,并且保鲜周期也能进一步拉长,配置规则也进一步简单化,便捷化。
任意条件: XX总量最近30s求和与智能基线值环比下跌XX% XX总量最近30s求和与智能基线值环比上升XX% | 所有条件: XX总量最近30s求和与预测上线比高于XX XX总量最近30s求和与智能基线值环比上升XX% | |||
任意条件: XX总量最近30s求和与智能基线值环比下跌XX%&持续XX个点位 XX总量最近30s求和与智能基线值环比上升XX%&持续XX个点位 | 任意条件: XX总量最近30s求和与预测上线比高于XX&持续XX个点位 XX总量最近30s求和与预测下线比低于XX&持续XX个点位 | 任意条件: XX总量最近30s求和与预测上线比高于XX&持续XX个点位 XX总量最近30s求和与预测下线比低于XX&持续XX个点位 | ||
所有条件: XX总量最近30s求和与预测上线比高于XX&XX总量最近30s求和与智能基线值环比上升XX% XX总量最近30s求和与预测下线比低于XX&XX总量最近30s求和与智能基线值环比下跌XX% | 所有条件: XX总量最近30s求和与预测上线比高于XX XX总量最近30s求和与智能基线值环比上升XX% | |||
所有条件: XX总量最近30s求和与预测上线比高于XX&XX总量最近30s求和与智能基线值环比上升XX% XX总量最近30s求和与预测下线比低于XX&XX总量最近30s求和与智能基线值环比下跌XX% | 任意条件: XX总量最近30s求和与预测上线比高于XX&持续XX个点位 XX总量最近30s求和与预测下线比低于XX&持续XX个点位 | 任意条件: XX总量最近30s求和与预测上线比高于XX&持续XX个点位 XX总量最近30s求和与预测下线比低于XX&持续XX个点位 | ||
一些比较特殊的场景可能会有些差别,但绝大多数场景都可以按此进行配置,还是以取消订单为例,智能基线大盘如下:
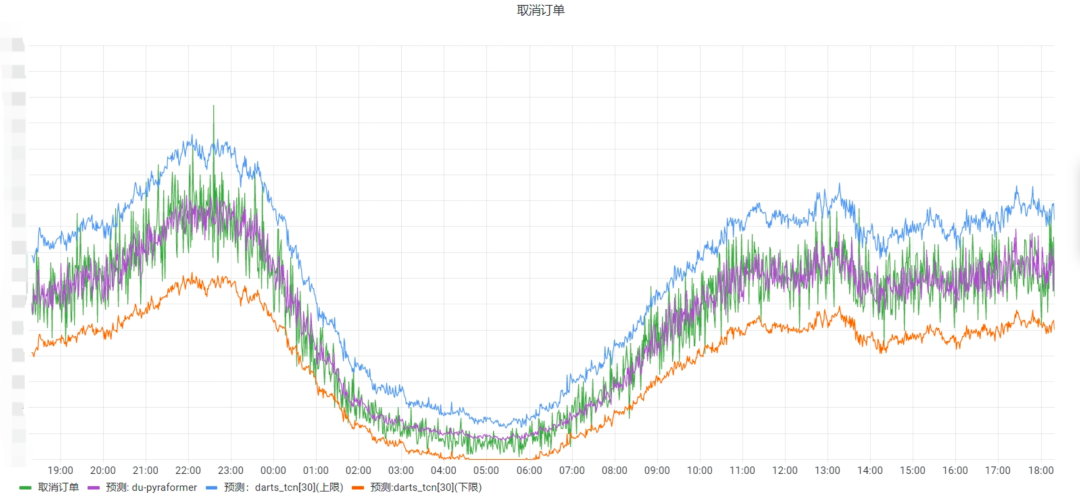
从图上我们可以看出此场景的波动比例基本在上下限控制以内,而对应的一般基线如下:
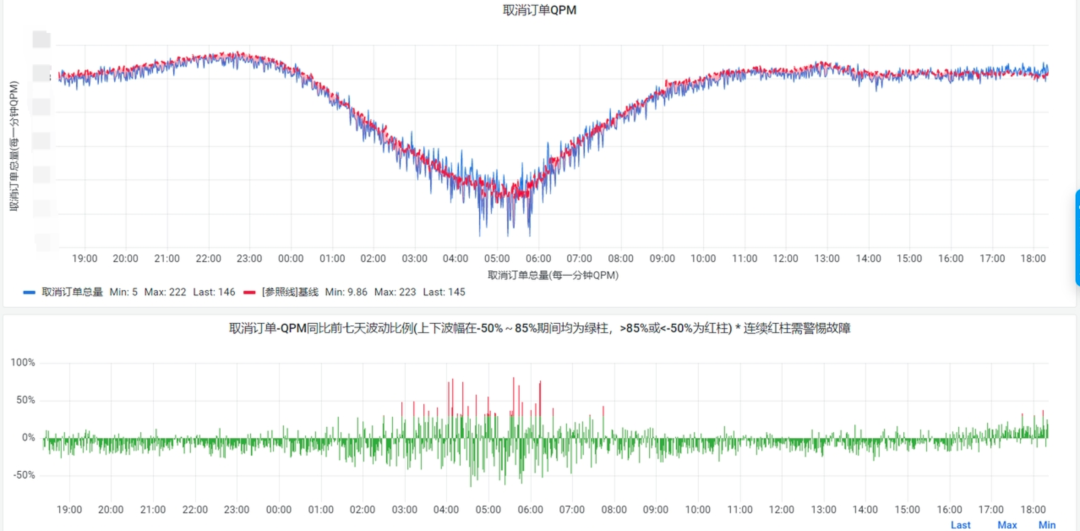
从刚开始的对于噪音治理的探索,到现在极低噪音的治理成果,这是整个团队的努力造就的。从分场景,分时间段,到根据流量动态调整基线,再到现在的智能基线,眼看着它在越变越优秀,这是让我们稳定生产人打心底感到自豪的。也相信也不久的将来,我们的NOC-SLA告警能够报出更多的线上问题的同时,也能产生更少的噪音。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK