

一文盘点NeurIPS'22杰出论文亮点!英伟达AI大佬一句话总结每篇重点,一并看透今年技术...
source link: https://www.qbitai.com/2022/11/39907.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

一文盘点NeurIPS’22杰出论文亮点!英伟达AI大佬一句话总结每篇重点,一并看透今年技术趋势

快来抄笔记
Pine 明敏 发自 凹非寺
量子位 | 公众号 QbitAI
15篇NeurIPS’22杰出论文重磅出炉,具体亮点都是啥?
来来来,大佬已经帮你总结好了!

师从李飞飞,现在在英伟达工作的大佬,用49条推文,带你回顾过去一年AI圈的重要研究。
虽然到不了NeurIPS’22的现场,但也能提前在推特上体验下大会的盛况。
总结推文发出之后,立刻在网上掀起一阵热度,众多AI大佬都在转发。
还有人从中看出了今年的技术趋势。

每篇亮点都是啥?
总结这一线程的老哥名叫Linxi“Jim”Fan(以下简称Jim)。
对于每篇论文,他都给出了一句话提炼亮点,并简要解释了自己的看法,还将论文地址和相关拓展链接一并附上。
具体都讲了啥,我们一篇篇来看~
1、训练计算最优的大语言模型
一句话总结:提出一个700亿规模的新语言模型“Chinchilla”,效果比千亿级别GPT-3、Gopher更强。
Jim表示,通过这个模型,研究人员证明了想要实现“计算最优”,模型大小和训练数据规模必须同等缩放。
这意味着,目前大多数大语言模型的训练数据是不够的。
再考虑到新的缩放定律,即使将模型参数扩大到千万亿级,效果恐怕也不及将训练token提升4倍。

2、谷歌Imagen的强,在于文本编码器
一句话总结:Imagen是一个大型从文本到图像的超分辨率扩散模型,可以生成逼真图像,并且在评级中击败了Dall·E 2。
Jim指出,和Dall·E 2相比,Imagen使用了更为强大的文本编码器T5-XXL,这直接影响了它的语言理解能力。
比如同题对比中,左边是谷歌Imagen选手眼中的“猫猫绊倒人类雕像”,右边DALL·E 2选手的创作则是酱婶儿的:

3、ProcTHOR:房间模型模拟器

一句话总结:ProcTHOR是一个可以生成大量定制化、可实际应用房间模型的AI。
和Chinchilla一样,ProcTHOR也需要大量数据来训练,然后从中摸索出自己的生成方案。
该成果由艾伦人工智能实验室提出,在此之前他们还为家用机器人提出了一些模型,如AI2THOR 和 ManipulaTHOR,可以让他们感知房间环境。
4、MineDojo:看70000小时《我的世界》视频学会人类高级技巧
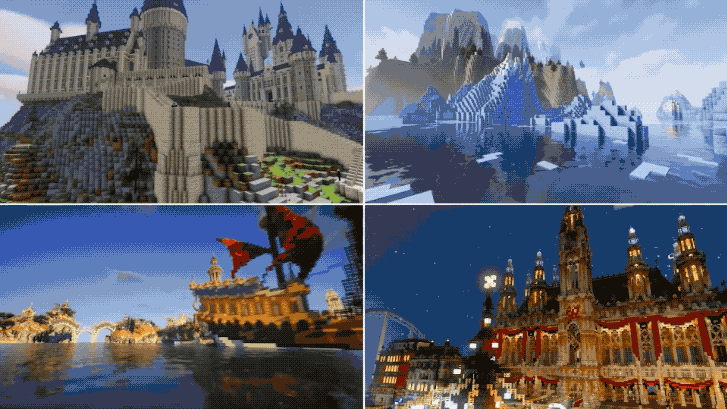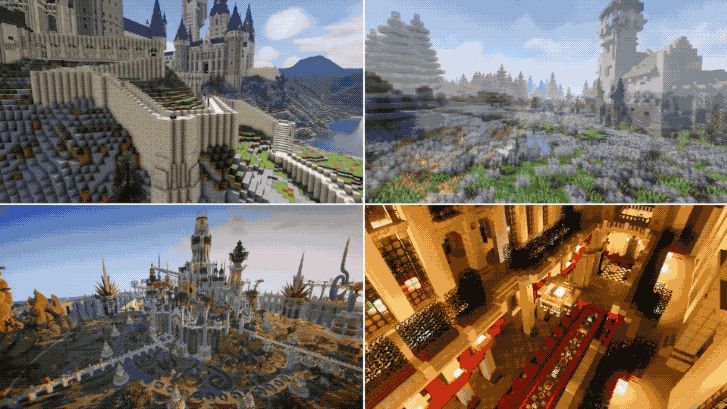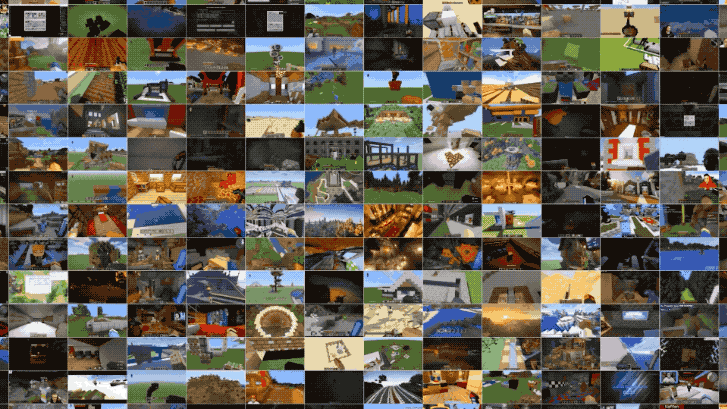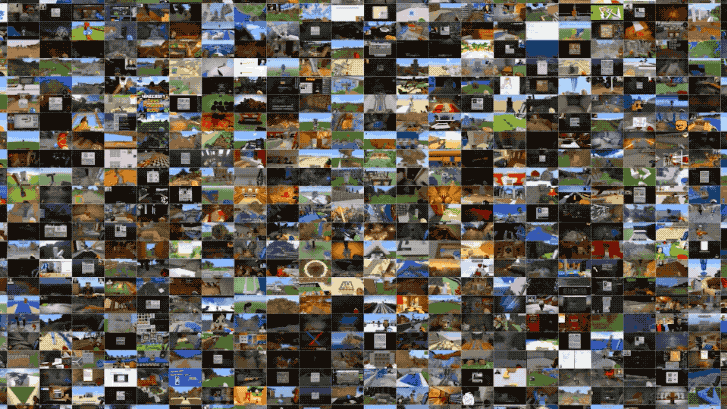
一句话总结:该研究提出一个由3个智能体(agent)组成的“具身GPT-3”,可以感知无限世界并在其中行动。
研究团队认为,想要训练出通才agent需要具备3方面因素:
第一、一个开放的环境,可以包含无限不同种类的任务(比如地球就是个开放环境);
第二、一个大规模知识库,可以教会AI做什么事、该做哪些事;
第三、足够灵活的代理框架,能将知识转化为实际操作。
综上,《我的世界》是一个绝佳的训练场地。研究团队让AI看了油管上70000小时《我的世界》视频后,它学会了使用钻石镐、打造“简易避难所”等人类玩家的高级操作。
值得一提的是,该成果的模拟套件、数据库、算法代码、预训练模型,甚至注释工具,全部对外开源!
AI看了70000小时《我的世界》视频学会人类高级技巧,网友:它好痛苦

5、LAION-5B:史上最大规模公共开放的多模态图文数据集

一句话总结:一个包含58.5亿个CLIP过滤的图像-文本对数据集。
LAION-5B不用过多介绍了,Stable Diffusion使用正是它。
该数据集获得了今年NeurIPS最杰出数据集论文奖。

目前Stable Diffusion 2也已经上线了。
6、超越神经网络缩放定律:通过数据集修剪击败幂律

一句话总结:通过仔细筛选训练示例、而不是盲目收集更多数据,有可能大大超越神经网络的缩放定律。
该研究中,Meta和斯坦福的学者们通过数据蒸馏,缩小数据集规模,但是保持模型性能不下降。
实验验证,在剪掉ImageNet 20%的数据量后,ResNets表现和使用原本数据时的正确率相差不大。
研究人员表示,这也为AGI实现找出了一条新路子。
剪掉ImageNet 20%数据量,模型性能不下降!Meta斯坦福等提出新方法,用知识蒸馏给数据集瘦身
7、让AI自己调超参数

一句话总结:使用超级随机梯度下降法,实现自动调超参数。
谷歌大脑设计了一个基于AI的优化器VeLO,整体由LSTM(长短期记忆网络)和超网络MLP(多层感知机)构成。
其中每个LSTM负责设置多个MLP的参数,各个LSTM之间则通过全局上下文信息进行相互协作。
采用元训练的方式,VeLO以参数值和梯度作为输入,输出需要更新的参数。
结果表明,VeLO在83个任务上的加速效果超过了一系列当前已有的优化器。
让AI自己调整超参数,谷歌大脑新优化器火了,自适应不同任务,83个任务训练加速比经典Adam更快

8、利用自然语言和程序抽象让机器学会人类归纳性偏好

一句话总结:利用自然语言描述和引导程序,让智能体的行为更像人类。
论文表明,语言和程序中存储了大量人类抽象先验知识,智能体可以在元强化学习设置中学到这些归纳性偏好。
如下是是否使用人类抽象先验知识的对比:

9、新方法提高扩散模型生成结果
一句话总结:英伟达通过对扩散模型的训练流程进行分析,得到新的方法来提高最后生成的结果。

此次研究提出了很多实用的方法改进了模型的生成效果:
- 一个新的采样过程,大大减少了合成过程中的采样步数;
- 改进了训练过程中噪声水平的分布;
- 其他一些改进方法,如non-leaking增强,即不会将生成分布暴露给生成器。
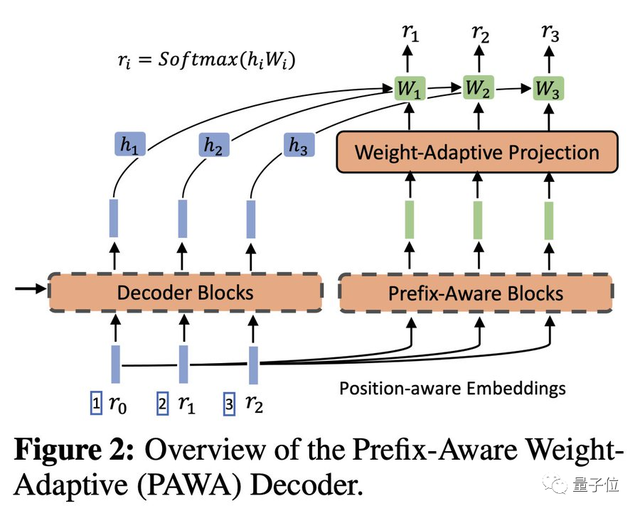
10、神经语料库索引器(NCI)
一句话总结:NCI可以直接为特定的查询生成相关的文档标识符,并显著提高信息检索性能。

传统的检索系统是基于文档向量嵌入和最近邻搜索。
而NCI则使用了一个端到端的可微模型,极大地简化了搜索管道,并且有可能在单个框架中统一检索、排序和Q&A。
11、一种新的采样方法
一句话总结:加州大学设计出一个最有效的算法从多个分布中进行采样,按需采样。

研究利用随机零和博弈的方法研究了多重分布学习问题。
多重分布学习在机器学习公平性、联邦学习以及多主题协作中都有着重要的应用。
在这其中,分布可能是不平衡或重叠的,所以最佳的算法应该按需采样。
12、分布外样本(OOD)检测是可学习的吗?
一句话总结:OOD检测在某些条件下是不可学习的,但是这些条件不适用于一些实际情况。
Jim表示,具体来讲,我们所熟悉的监督式学习的测试数据是内部分发的,但现实世界却是混乱的。
而这个研究运用PAC学习理论,提出了3个具体的不可能性定理,推断应用于实际环境中确定OOD检测的可行性。
更重要的是,此项工作还为现有的OOD检测方法提供了理论基础。
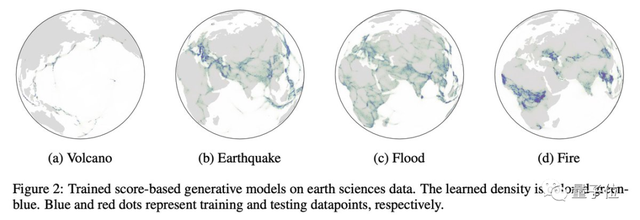
13、基于黎曼得分的生成模型(RSGMs)

一句话总结:这是一类将模型扩展到黎曼流形的生成模型(与欧几里德空间中的数据相反)。
扩散模型目前已经在人工智能领域取得了很大的进展,不过大多数模型都被假设是一个扁平的流形。
但在机器人学、地球科学或蛋白质折叠等领域,数据也能很好地在黎曼流形上描述。
这项研究使得Stable Diffusion有望应用在气候科学上。
14、SGD的高维极限定理
一句话总结:研究用一个统一的方法,了解在高维情况下具有恒定步长的随机梯度下降的缩放极限。

其核心贡献是发展一个统一的方法,在连续步长之下,使我们了解SGD在高维的比例限制。
研究团队还在目前正流行的模型中证明了这个方法,示例也展示了很好的效果:
包括收敛的多模态时间尺度以及收敛到次优解决方案,概率从随机初始化开始有界地远离零。
15、RODEO:减小估计梯度方法REINFORCE的方差。
一句话总结:利用Stein算子控制变量来增强REINFORCE的性能。

离散变量使神经网络不可微,所以估计梯度的一种常见方法是REINFORCE,但这种方法又存在很大的方差。
本文提出了一种利用Stein算子控制变量增强REINFORCE的高性能方法:“ RODEO”。
并且,这种控制变量可以在线调整以最小化方差,并且不需要对目标函数进行额外的评估。
在基准生成建模任务中,例如训练二进制变分自动编码器,在具有相同数量的函数估计的情况下,研究的梯度估计器实现了有史以来最低的方差。
大佬来自英伟达,师从李飞飞
总结这一超强线程的大佬Jim,现就职于英伟达。

他的研究方向是开发具有通用能力的自主智能体,如上让AI学会《我的世界》人类玩家技巧的论文,正是他的成果。
他博士就读于斯坦福大学视觉实验室,师从李飞飞。
曾在谷歌云、OpenAI、百度硅谷AI实验室等实习。
参考链接:
[1]https://twitter.com/DrJimFan/status/1596911064251187201
[2]https://jimfan.me/
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK