

DRY vs DAMP in Unit Tests
source link: https://enterprisecraftsmanship.com/posts/dry-damp-unit-tests/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

DRY vs. DAMP: the dichotomy
You can often hear that people put these two principles in opposition to each other. DRY and DAMP are usually represented as two ends of the spectrum that covers all of your code:
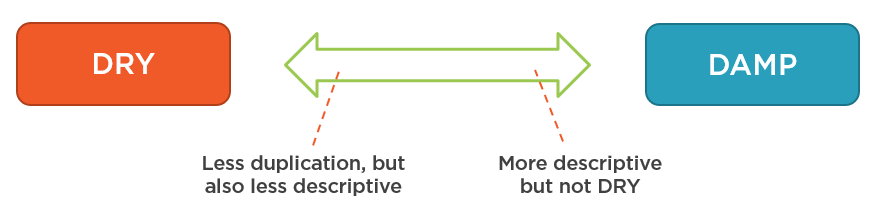
You can choose to make your code more descriptive at the expense of the DRY principle (and thus lean towards the DAMP end of the spectrum) or you can choose to remove duplication, but at the cost of the code becoming less expressive. In other words, you can’t adhere to both principles with the same piece of code.
You may also hear the guideline saying that:
-
For your production code, you should err on the side of the DRY principle
-
For the test code, you should favor DAMP over DRY
I strongly disagree with this opposition.
But let’s first take an example, to understand where this guideline comes from. I’ll then describe why this guideline misses the point.
Let’s say we have a UserController with two methods:
public class UserController
{
public string Register(string userName, string email)
{
User userByName = _dbContext.Users
.SingleOrDefault(x => x.UserName == userName);
if (userByName != null)
return "User with such username already exists";
User userByEmail = _dbContext.Users
.SingleOrDefault(x => x.Email == email);
if (userByEmail != null)
return "User with such email already exists";
// Register the user
return "OK";
}
public string EditPersonalInfo(string userName, string email)
{
User currentUser = GetCurrentUser();
User userByName = _dbContext.Users
.SingleOrDefault(x => x.UserName == userName && x.UserName != currentUser.UserName);
if (userByName != null)
return "User with such username already exists";
User userByEmail = _dbContext.Users
.SingleOrDefault(x => x.Email == email && x.Email != currentUser.Email);
if (userByEmail != null)
return "User with such email already exists";
// Update personal info
return "OK";
}
}
Both of the methods check for user name and email uniqueness before making the changes. These checks aren’t exactly the same (EditPersonalInfo takes into account the current user’s name and email), but close enough to be worth extracting into one place.
Here’s how we can do that:
public class UserController
{
public string Register(string userName, string email)
{
if (UserNameAlreadyExists(userName, null))
return "User with such username already exists";
if (UserEmailAlreadyExists(email, null))
return "User with such email already exists";
// Register the user
return "OK";
}
public string EditPersonalInfo(string userName, string email)
{
User currentUser = GetCurrentUser();
if (UserNameAlreadyExists(userName, currentUser.UserName))
return "User with such username already exists";
if (UserEmailAlreadyExists(email, currentUser.Email))
return "User with such email already exists";
// Update personal info
return "OK";
}
private bool UserNameAlreadyExists(string name, string currentUserName)
{
IQueryable<User> query = _dbContext.Users
.Where(x => x.UserName == name);
if (currentUserName != null)
{
query = query.Where(x => x.UserName != currentUserName);
}
User user = query.SingleOrDefault();
return user != null;
}
private bool UserEmailAlreadyExists(string email, string currentUserEmail)
{
/* Same for email */
}
}
This version is much cleaner. It also adheres to the DRY principle — the common bits get reused across the two methods. (Notice that I moved the checks for uniqueness to private methods, but they could also be repository methods, depending on your project’s specifics.)
So, that’s the example of the first part of the guideline — favoring DRY in the production code. The benefits are pretty self-evident: the code in the two controller methods gets simpler and, more importantly, the knowledge of how to do the uniqueness checks now resides in one place.
Let’s now look at the second part of the guideline — preferring DAMP in the test code. Let’s say we’ve got a CalculatorController and two tests that check its functionality:
[Fact]
public void Division_by_zero()
{
// Arrange
int dividend = 10;
int divisor = 0;
var calculator = new CalculatorController();
// Act
Envelope<int> response = calculator.Divide(dividend, divisor);
// Assert
response.IsError.Should().BeTrue();
response.ErrorCode.Should().Be("division.by.zero");
}
[Fact]
public void Division_of_two_numbers()
{
// Arrange
int dividend = 10;
int divisor = 2;
var calculator = new CalculatorController();
// Act
Envelope<int> response = calculator.Divide(dividend, divisor);
// Assert
response.IsError.Should().BeFalse();
response.Result.Should().Be(5);
}
These tests also have common bits, that could be extracted like this:
/* The initialization code that is common for both tests */
int _dividend = 10;
CalculatorController _calculator = new CalculatorController();
[Fact]
public void Division_by_zero()
{
// Arrange
int divisor = 0;
// Act
Envelope<int> response = _calculator.Divide(_dividend, divisor);
// Assert
response.IsError.Should().BeTrue();
response.ErrorCode.Should().Be("division.by.zero");
}
[Fact]
public void Division_of_two_values()
{
// Arrange
int divisor = 2;
// Act
Envelope<int> response = _calculator.Divide(_dividend, divisor);
// Assert
response.IsError.Should().BeFalse();
response.Result.Should().Be(5);
}
This time the refactoring doesn’t feel as good as in the previous example, does it?
Indeed, such a refactoring is an anti-pattern:
-
It introduces high coupling between tests — If you need to modify the calculator setup in one test, it will affect the other test too.
Such coupling becomes hard to trace really quickly. Changes in one test may ripple through the remaining tests and may introduce unexpected bugs in them.
Try to always follow this rule of thumb: a modification of one test should not affect other tests. For that, you need to avoid sharing state between tests. The two private fields (
_dividendand_calculator) are an example of such a shared state. -
It diminishes test readability — After extracting the two lines, you no longer see the full picture just by looking at individual tests. You have to examine the whole class in order to understand what the test does.
Even if there’s not much of arrangement logic, for example, only instantiation of the calculator, like in the example above, you are still better off moving that logic directly to the test method. Otherwise, you’ll wonder if it’s really just instantiation or maybe there’s something else is being configured here as well. A self-contained test doesn’t leave you with such uncertainties.
That’s where the guideline of preferring DAMP over DRY in tests comes from. The initial version of the two tests is better — it’s more expressive, even if at the expense of code repetition.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK