

Using IO objects in python to read data
source link: https://andrewpwheeler.com/2022/11/02/using-io-objects-in-python-to-read-data/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Using IO objects in python to read data
Just a quick post on a technique I’ve used a few times recently, in particular when reading web data.
First for a very quick example, in python when reading data with pandas, it often expects a filename on disk. For pandas, e.g. pd.read_csv('my_file.csv'). But if you happen to already have the contents of the csv in a text object in memory, you can use io.StringIO to just read that object.
import pandas as pd
from io import StringIO
# Example csv file inline
examp_csv = """a,b
1,x
2,z"""
pd.read_csv(StringIO(examp_csv))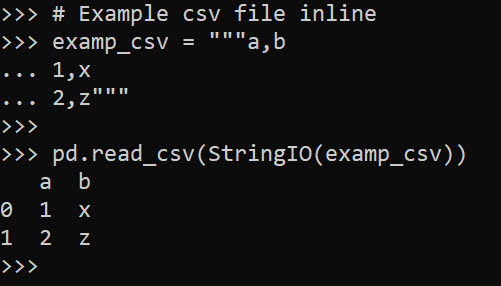
Where this has come up for me recently is reading in different data from web servers. For example, here is Cary’s API for crime data, you can batch download the whole thing at the below url, but via this approach I currently get an SSL error:
# Town of Cary CSV for crimes
cary_url = 'https://data.townofcary.org/explore/dataset/cpd-incidents/download/?format=csv&timezone=America/New_York&lang=en&use_labels_for_header=true&csv_separator=%2C'
# Returns SSL Error for me
cary_df = pd.read_csv(cary_url)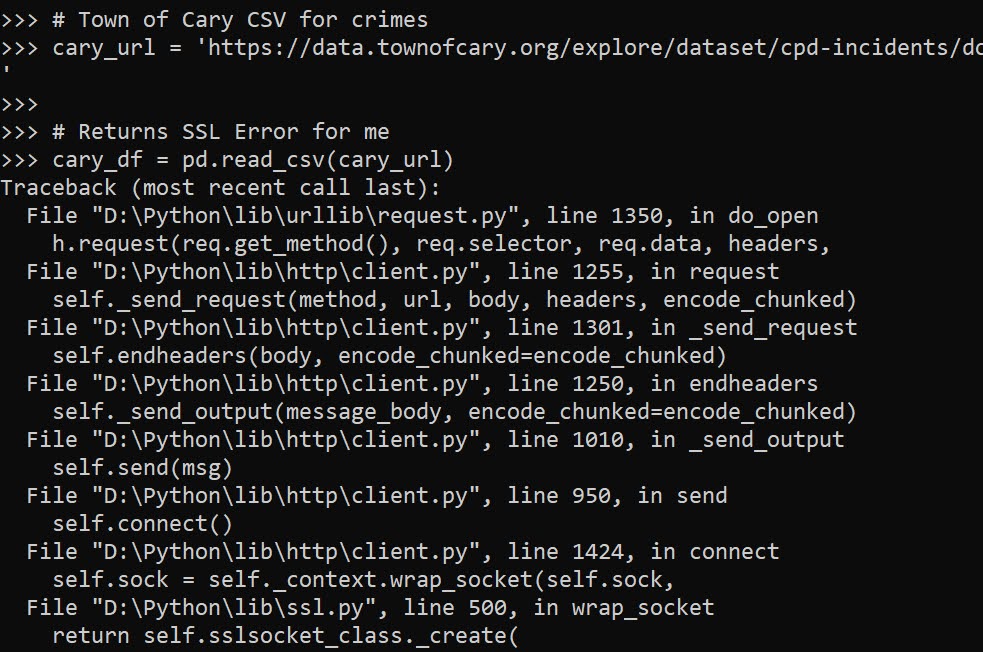
Note I don’t know the distinction in web server tech that causes this (as sometimes you can just grab a CSV via url, here is an example I have grabbing PPP loan data or with the NIJ recidivism data).
But we can grab the data via requests, and use the same StringIO trick I just showed to get this data:
# Using string IO for reading text
import requests
res_cary = requests.get(cary_url)
cary_df = pd.read_csv(StringIO(res_cary.text))
cary_df
Again I don’t know why some servers you need to go through this approach, but this works for me for Socrata and CartoDB api’s for different cities open data. I also used in recently for converting geojson in ESRI’s api.
The second example I want to show is downloading zipfiles. For this, we will use io.BytesIO instead of StringIO. The census stores various data in zipfiles on their FTP server:
# Example 2, grabbing zipped contents
import zipfile
from io import BytesIO
census_url = 'https://www2.census.gov/programs-surveys/acs/summary_file/2019/data/2019_5yr_Summary_FileTemplates.zip'
req = requests.get(census_url)
# Can use BytesIO for this content
zf = zipfile.ZipFile(BytesIO(req.content))The zipfile library would be equivalent to reading/extracting a zipfile already on disk. But when downloading there is no need to save to disk, then deal with that file. BytesIO here cuts out the middleman.
Then we gan either grab a specific file inside of our zf object, or extract all the contents one-by-one:
# Now can loop through the list
# or grab specific file
zf.filelist[0]
temp_geo = pd.read_excel(zf.open('2019_SFGeoFileTemplate.xlsx'))
temp_geo.T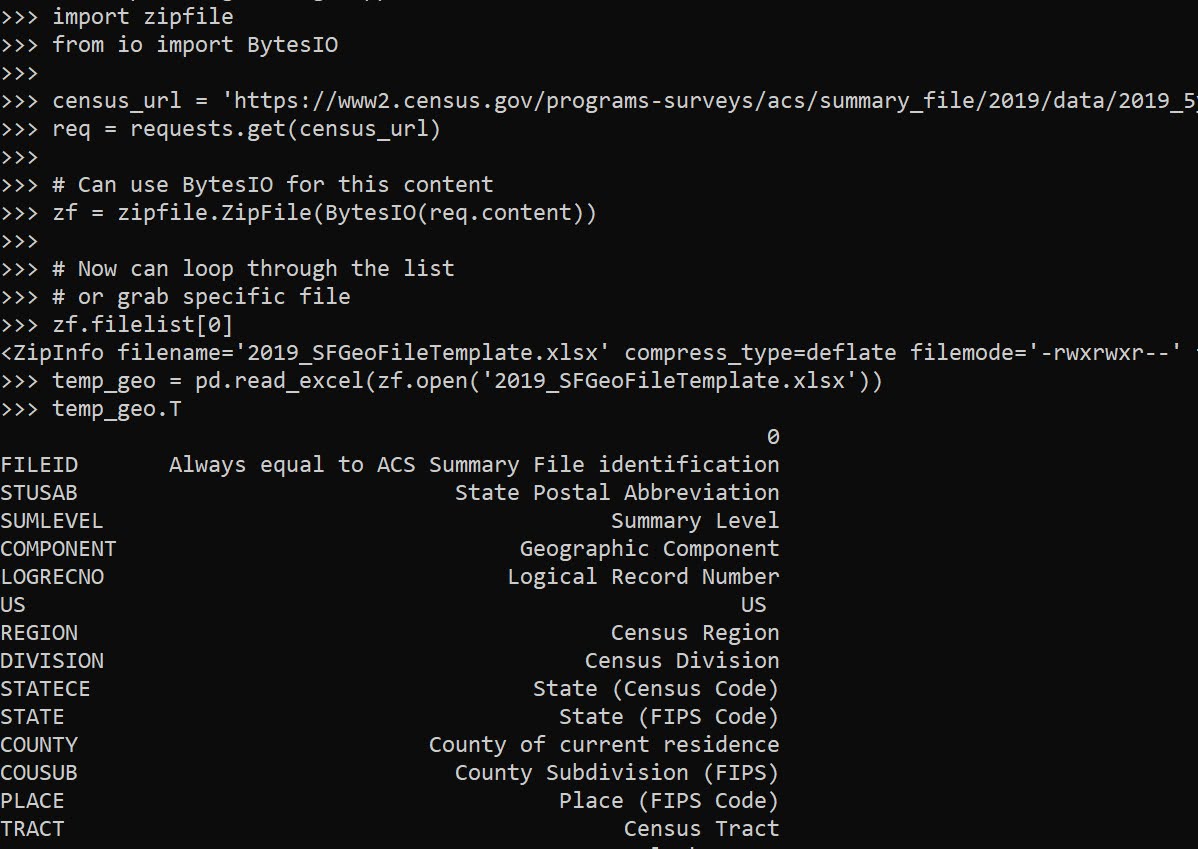
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK