

编辑器在编译Shader时的报错疑问 - UWA问答 | 博客 | 游戏及VR应用性能优化记录分享 |...
source link: https://blog.uwa4d.com/archives/TechSharing_312.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
1)编辑器在编译Shader时的报错疑问
2)关于图片大小和包体大小的疑问
3)关于合图和合批是否会降低带宽的疑问
4)URP下,如何优化多相机渲染时的Cull耗时
这是第312篇UWA技术知识分享的推送。今天我们继续为大家精选了若干和开发、优化相关的问题,建议阅读时间10分钟,认真读完必有收获。
UWA 问答社区:answer.uwa4d.com
UWA QQ群2:793972859(原群已满员)
Shader
Q:有时在Shader编写过程中,我们可能会用到非常多纹理,如果每个纹理都采用类似uniform sampler2D _Mask;的方式进行声明,编辑器在编译Shader的时候就会报错:
Shader error in ‘CloudShaow/MaskBlend’: maximum ps_4_0 sampler register index (16) exceeded at line 69 (on d3d11)
A1:OpenGL ES2.0中,单个Shader最多支持8个贴图;OpenGL ES3.0中,单个Shader最多支持16个贴图。没办法,这是硬件限制,你只能减少贴图数量。
比如,把几个2D Texture合成2D Array Texture。或者,根据不同的Keyword,访问不同的贴图,但是要保证,贴图使用量最多的变体,符合上面的要求。
感谢王烁@UWA问答社区提供了回答
A2:以前的写法,参考这个:
https://blog.csdn.net/weixin_32521765/article/details/113056248现在的写法,只定义一个Sampler,传参数的时候共用这一个就行:


感谢仇磊@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/5eb901a14d93790618e0ed24
Resource
Q:关于图片大小和包体大小的疑问。
例如 ,一张图片,实际大小是1KB,放到Unity里是10KB(根据不同的压缩格式不一样),打包后查看Editor Log说图片占用了包体10KB。查了很多文章都说Unity打包的时候,会把图片按设定的压缩格式转成Unity的图片格式,但实际打出的包不是增长10KB,而是图片实际大小1KB,这个10KB是内存大小。
究竟这个包体大小与图片大小的关系是怎样的?如何查看实际的包体资源构成?
A1:jpg和png拥有良好的压缩率,也就是你所看到的1KB的图片。但是这2种格式不支持随机读取,所以引擎会帮你转换成支持随机读取的格式,会比原来的图片大一点,存储也是按照新格式来存储的。包体构成如果是AssetBundle或者全都放在Resource目录下,就可以通过AssetStudio进行解包查看。
感谢萧小俊@UWA问答社区提供了回答
A2:你要理解内存大小和所占硬盘的容量大小,10KB是实际加载这张图内存会占用的大小,1KB是这个文件在你的操作系统中的文件所占的硬盘大小,但是不完全等同于实际进包内的大小,毕竟Resource里或者打成AssetBundle之后会有一定的压缩,可以在打下的AssetBundle中查看。
也就是说,要看下这个文件更改格式之后打出来的AssetBundle大小是否产生了实质的变化,因为AssetBundle的大小进到包内一般不会被压缩。
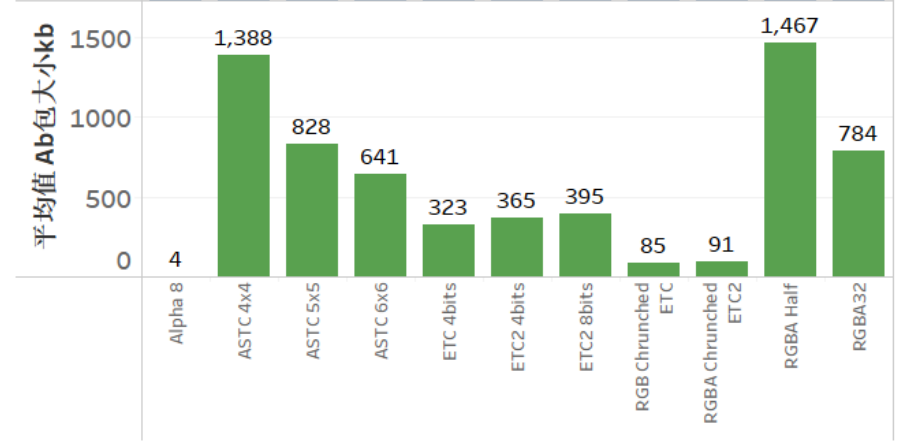
感谢Knight-132872@UWA问答社区提供了回答
A3:最终看打出来的AssetBundle包的大小即可,通常AssetBundle是不会2次压缩的,否则加载耗时会变高。纹理的压缩格式也会导致AssetBundle大小不一样,下图中是1024x1024的纹理测试得到的结果,仅供参考:
感谢Xuan@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/635a9baaf0920d3f810aac84
Rendering
Q:关于合图和合批是否会降低带宽疑问。
有一张合图1024x1024,200个物体共用其中一张100x100纹理,总共DrawCall只有1,请问下现在带宽是:
200物体 x (1024 x 1024) or
200物体 x (100 x 100) or
1 x (1024 x 1024) or
1 x (100 x 100)?
如题目所说,合图的应该是被合成一个Batch,那是200物体 x (1024 x 1024)吗?
另外NxN的像素块有多大?比如想要渲染一张1024x1024背景图,一般会被读取几次?
若开启Mipmap,我的理解是相当于弄了一个合图,合图里包含了更低级别的信息。如果是这个思路,那合图传的带宽应该是100x100,而不是传整张合图1024x1024?
A1:首先一点,Sprite不是你想的100X100尺寸,传到GPU就是这块区域,最终传输到GPU还是纹理本身,GUI只是通过Sprite信息设置了顶点UV,才能正确渲染纹理的目标区域。Sprite它不是任何显示资源或者物理资源,而就是一个纯数据结构,为了方便管理一个纹理的不同区域。
感谢1 9 7 3-311135@UWA问答社区提供了回答
A2:纹理带宽主要指读纹理带宽:当GPU的OnChip Memory上没有,则会从System Memory里面读取,一般是会读取一个NxN的像素块的内容进OnChip Memory。所以,当采样次数和采样点更多的时候,越容易Cache Miss,这样就增多了到System Memory里面读取纹理到OnChip的次数,带宽就相应增大了。
因此,为了降低带宽,我们常说纹理要开Mipmap,要减少采样次数(避免开启各项异性和三线性差值),从而尽量减少Cache Miss次数;也可以进一步压缩纹理格式,来减少传输的数据量。
对于本问题,本质还是在OnChip上读取里面NxN的内容的,但是会受到采样次数的影响。其中如果有200个DrawCall但被合成一个了Batch,仍然会采样200次;但如果确实合成了一个DrawCall,那就会只采一次。
之所以说Mipmap降低带宽,是因为传到GPU的是合适层级的纹理,当画下一个像素时很大概率就落在OnChip里的NxN个像素内,就不需要重新采从而增加Cache Miss概率;但如果没有开Mipmap而导致用了分辨率过大的层级,则画两个相邻的点也可能要跨纹理中的好几个像素,从而得重新采从而增加Cache Miss概率。
感谢Faust@UWA问答社区提供了回答
A3:对于带宽来说,是100x100还是1024x1024,区别不大,小图和大图的区别在于从CPU传到GPU的时候的操作,是一次性传图集到GPU里面还是分很多次传小图到GPU,到带宽层面,都是读取采样点周围的像素到OnChip上,应该没有太大区别。至于采样点读取的NxN有多大,这个应该是和硬件相关。
感谢Xuan@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/6358ad790bdffa5c03f4316d
Rendering
Q:根据Profiler来看,CPU端相机的耗时有很大一部分在Cull阶段。有什么办法能够优化这部分的耗时吗?或者说跳过这部分?有尝试过通过CommandBuffer去绘制,但是CommandBuffer绘制的物体,SRPBatcher似乎没法生效。
请问在URP下,多相机渲染时的Cull耗时有办法优化吗?
A:Frustum Culling已经在JobSytem的子线程中。你相机可能重复渲染了,或者你场景的对象太多了,建议先用些其他手段,比如LOD、HLOD或逻辑剔除等。
跳过不可能。如果跳过,全地图的顶点都会进入这一帧的VBO(一样会卡),EBO长度也大大增加 ,接着由驱动发送到GPU,后来来到Vertex Shader阶段参与计算(压力),其次除法前裁剪[-w,w]之外的顶点(最后也裁剪了,但是浪费了最大的计算过程资源)。
感谢龙跃@UWA问答社区提供了回答,欢迎大家转至社区交流:
https://answer.uwa4d.com/question/633690a7e73cb53fa4e28c74
封面图来源于网络
今天的分享就到这里。当然,生有涯而知无涯。在漫漫的开发周期中,您看到的这些问题也许都只是冰山一角,我们早已在UWA问答网站上准备了更多的技术话题等你一起来探索和分享。欢迎热爱进步的你加入,也许你的方法恰能解别人的燃眉之急;而他山之“石”,也能攻你之“玉”。
官网:www.uwa4d.com
官方技术博客:blog.uwa4d.com
官方问答社区:answer.uwa4d.com
UWA学堂:edu.uwa4d.com
官方技术QQ群:793972859(原群已满员)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK