

深入挖掘Elastic Search的原理
source link: https://www.51cto.com/article/721100.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

深入挖掘Elastic Search的原理
elastic search分布式工作原理
- Elasticsearch 是分布式的,但是对于我们开发者来说并未过多的参与其中,我们只需启动对应数量的节点,并给它们分配相同的 cluster.name 让它们归属于同⼀个集群,创建索引的时候只需指定索引主分⽚数和 副分⽚数 即可,其他的都交给了 ES 内部⾃⼰去实现。
- 这和数据库的分布式和 同源的 solr 实现分布式都是有区别的,数据库要做集群分布式,⽐如分库分表需要我们指定路由规则和数据同步策略等,包括读写分离,主从同步等,solr的分布式也需依赖 zookeeper,但是 Elasticsearch 完全屏蔽了这些。
- 虽然Elasticsearch 天⽣就是分布式的,并且在设计时屏蔽了分布式的复杂性,但是我们还得知道它内部的原理。
节点交互原理
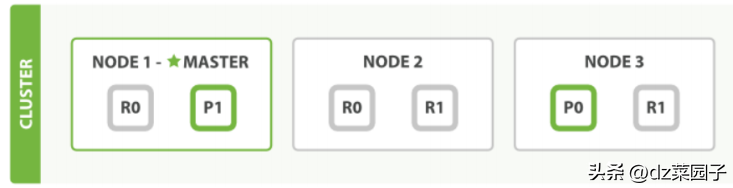
- es和其他中间件⼀样,⽐如mysql,redis有master-slave模式。es集群也会选举⼀个节点做为master节点
- master节点它的职责是维护全局集群状态,在节点加⼊或离开集群的时候重新分配分⽚。
- 所有⽂档级别的写操作不会与master节点通信,master节点并不需要涉及到⽂档级别的变更和搜索等操作,es分布式不太像mysql的master-slave模式,mysql是写在主库,然后再同步数据到从库。⽽es⽂档写操作是分⽚上⽽不是节点上,先写在主分⽚,主分⽚再同步给副分⽚,因为主分⽚可以分布在不同的节点上,所以当集群只有⼀个master节点的情况下,即使流量的增加它也不会成为瓶颈,就算它挂了,任何节点都有机会成为主节点。
- 读写可以请求任意节点,节点再通过转发请求到⽬的节点,⽐如⼀个⽂档的新增,⽂档通过路由算法分配到某个主分⽚,然后找到对应的节点,将数据写⼊到主分⽚上,然后再同步到副分⽚上。
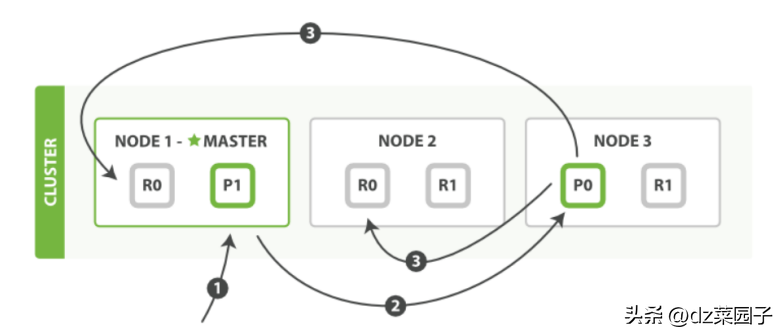
- 客户端向node-1发送新增⽂档请求。
- 节点通过⽂档的路由算法确定该⽂档属于主分⽚-P0。因为主分⽚-P0在node-3,所以请求会转发到node-3。
- ⽂档在node-3的主分⽚-P0上新增,新增成功后,将请求转发到node-1和node-2对应的副分⽚-R0上。⼀旦所有的副分⽚都报告成功,node-3向node-1报告成功,node-1向客户端报告成功。
- 客户端向node-1发送读取⽂档请求。
- 在处理读取请求时,node-1在每次请求的时候都会通过轮询所有的副本分⽚来达到负载均衡。
elastic search文档的路由原理
- 当新增⼀个⽂档的时候,⽂档会被存储到⼀个主分⽚中。 Elasticsearch 如何知道⼀个⽂档应该存放到哪个分⽚中呢?当我们创建⽂档时,它如何决定这个⽂档应当被存储在分⽚ 1 还是分⽚ 2 中呢?
- ⾸先这肯定不会是随机的,否则将来要获取⽂档的时候我们就不知道从何处寻找了。实际上,这个过程是根据下⾯这个公式决定的:
shard- routing 是⼀个可变值,默认是⽂档的 _id ,也可以设置成⼀个⾃定义的值。 routing通过 hash 函数⽣成⼀个数字,然后这个数字再除以 number_of_primary_shards (主分⽚的数量)后得到 余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的⽂档所在分⽚的位置。
- 这就解释了为什么我们要在创建索引的时候就确定好主分⽚的数量 并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会⽆效,⽂档也再也找不到了。
- 新增⼀个⽂档(指定id)
PUT /nba/_doc/1
{
"name": "哈登",
"team_name": "⽕箭",
"position": "得分后卫",
"play_year": "10",
"jerse_no": "13"
}- 查看⽂档在哪个分⽚上
GET /nba/_search_shards?routing=1"nodes":{
"V1JO7QXLSX-yeVI82WkgtA":{
"name":"node-1",
"ephemeral_id":"_d96PgOSTnKo6nrJVqIYpw",
"transport_address":"192.168.1.101:9300",
"attributes":{
"ml.machine_memory":"8589934592",
"xpack.installed":"true",
"ml.max_open_jobs":"20"
}
},
"z65Hwe_RR_efA4yj3n8sHQ":{
"name":"node-3",
"ephemeral_id":"MOE_Ne7ZRyaKRHFSWJZWpA",
"transport_address":"192.168.1.101:9500",
"attributes":{
"ml.machine_memory":"8589934592",
"ml.max_open_jobs":"20",
"xpack.installed":"true"
}
}
},
"indices":{
"nba":{
}
},
"shards":[
[
{
"state":"STARTED",
"primary":true,
"node":"V1JO7QXLSX-yeVI82WkgtA",
"relocating_node":null,
"shard":2,
"index":"nba",
"allocation_id":{
"id":"leX_k6McShyMoM1eNQJXOA"
}
},
{
"state":"STARTED",
"primary":false,
"node":"z65Hwe_RR_efA4yj3n8sHQ",
"relocating_node":null,
"shard":2,
"index":"nba",
"allocation_id":{
"id":"6sUSANMuSGKLgcIpBa4yYg"
}
}
]
]
}剖析elastic search的乐观锁
锁的简单分类
顾名思义,就是很悲观,每次去拿数据的时候都认为别⼈会修改,所以每次在拿数据的时候都会上锁,这样别⼈想拿这个数据就会阻塞,直到它拿到锁。传统的关系型数据库⾥边就⽤到了很多这种锁机制,⽐如⾏锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
顾名思义,就是很乐观,每次去拿数据的时候都认为别⼈不会修改,所以不会上锁,但是在更新的时候会判断⼀下在此期间别⼈有没有去更新这个数据,⽐如可以使⽤版本号等机制。乐观锁适⽤于多读的应⽤类型,这样可以提⾼吞吐量,因为我们elasticsearch⼀般业务场景都是写少读多,所以通过乐观锁可以在控制并发的情况下⼜能有效的提⾼系统吞吐量。
版本号乐观锁
- Elasticsearch 中对⽂档的 index , GET 和 delete 请求时,都会返回⼀个 _version,当⽂档被修改时版本号递增。
- 所有⽂档的更新或删除 API,都可以接受 version 参数,这允许你在代码中使⽤乐观的并发控制,这⾥要注意的是版本号要⼤于旧的版本号,并且加上version_type=external。
GET /nba/_doc/1{
"_index" : "nba",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 4,
"_primary_term" : 7,
"found" : true,
"_source" : {
"name" : "哈登",
"team_name" : "⽕箭",
"position" : "得分后卫",
"play_year" : "10",
"jerse_no" : "13"
}
}- 通过版本号新增⽂档(version要⼤于旧的version)
POST /nba/_doc/1?versinotallow=2&version_type=external
{
"name": "哈登",
"team_name": "⽕箭",
"position": "得分后卫",
"play_year": "10",
"jerse_no": "13"
}浅谈elastic search的分词原理
- 我们创建⼀个⽂档
PUT test/_doc/1
{
"msg":"乔丹是篮球之神"
}- 我们通过'乔丹'这个关键词来搜索这个⽂档
POST /test/_search
{
"query": {
"match": {
"msg": "乔丹"
}
}
}- 我们发现能匹配⽂档出来,那整⼀个过程的原理是怎样的呢?
- 我们来试下使⽤中⽂分词器
PUT test/_mapping
{
"properties": {
"msg_chinese":{
"type":"text",
"analyzer": "ik_max_word"
}
}
}POST test/_doc/1
{
"msg":"乔丹是篮球之神",
"msg_chinese":"乔丹是篮球之神"
}POST /test/_search
{
"query": {
"match": {
"msg_chinese": "乔"
}
}
}POST /test/_search
{
"query": {
"match": {
"msg": "乔"
}
}
}为什么同样是输⼊'乔',为什么msg能匹配出⽂档,⽽msg_chinese不能呢?
- 我们使⽤来分析这个msg这个字段是怎样分词的
POST test/_analyze
{
"field": "msg",
"text": "乔丹是篮球之神"
}乔,丹,是,篮,球,之,神- 再来分析这个msg_chinese这个字段是怎样分词的
POST test/_analyze
{
"field": "msg_chinese",
"text": "乔丹是篮球之神"
}乔丹, 是, 篮球, 之神- ⽂档写⼊的时候会根据字段设置的分词器类型进⾏分词,如果不指定就是默认的standard分词器。
- 写时分词器需要在mapping中指定,⽽且⼀旦指定就不能再修改,若要修改必须重建索引。
- 由于读时分词器默认与写时分词器默认保持⼀致,拿上⾯的例⼦,你搜索 msg 字段,那么读时分词器为 Standard ,搜索 msg_chinese 时分词器则为 ik_max_word。这种默认设定也是⾮常容易理解的,读写采⽤⼀致的分词器,才能尽最⼤可能保证分词的结果是可以匹配的。
- 允许读时分词器单独设置
POST test/_search
{
"query": {
"match": {
"msg_chinese": {
"query": "乔丹",
"analyzer": "standard"
}
}
}
}- ⼀般来讲不需要特别指定读时分词器,如果读的时候不单独设置分词器,那么读时分词器的验证⽅法与写时⼀致。
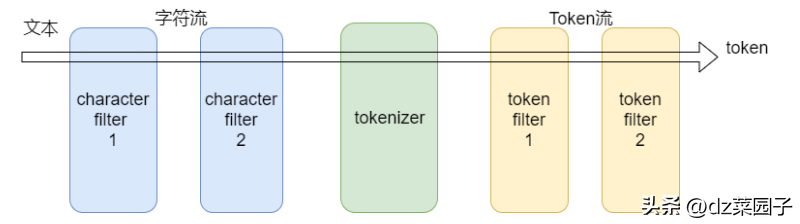
- 分析器(analyzer)有三部分组成
char filter : 字符过滤器
tokenizer : 分词器
token filter :token过滤器
- char filter(字符过滤器)
字符过滤器以字符流的形式接收原始⽂本,并可以通过添加、删除或更改字符来转换该流。⼀个分析器可能有0个或多个字符过滤器。
tokenizer (分词器)
⼀个分词器接收⼀个字符流,并将其拆分成单个token (通常是单个单词),并输出⼀个token流。⽐如使⽤whitespace分词器当遇到空格的时候会将⽂本拆分成token。"eating anapple" >> [eating, and, apple]。⼀个分析器必须只能有⼀个分词器
POST _analyze
{
"text": "eating an apple",
"analyzer": "whitespace"
}token filter (token过滤器)
token过滤器接收token流,并且可能会添加、删除或更改tokens。⽐如⼀个lowercase token fifilter可以将所有的token转成⼩写。⼀个分析器可能有0个或多个token过滤器,它们按顺序应⽤。
standard分析器
- tokenizer
Stanard tokenizer
- token fifilters
Standard Token Filter
Lower Case Token Filter
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK