

10分钟搞懂CAP理论笔记
source link: https://jasonkayzk.github.io/2022/10/23/10%E5%88%86%E9%92%9F%E6%90%9E%E6%87%82CAP%E7%90%86%E8%AE%BA%E7%AC%94%E8%AE%B0/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

本文为CAP理论学习的开篇,主要是走马观花地总结了分布式领域的CAP理论相关的内容;
视频地址:
10分钟搞懂CAP理论笔记
CAP理论基本概念
维基百科中的内容:
在理论计算机科学中,CAP定理(CAP theorem),又被称作布鲁尔定理(Brewer’s theorem),它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency) :等同于所有节点访问同一份最新的数据副本;
- 可用性(Availability):每次请求都能获取到非错的响应——但是不保证获取的数据为最新数据;
- 分区容错性(Partition tolerance):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择;(简单解释:分区容错性是尽管任意数量的消息被节点间的网络丢失或者延迟,系统仍然是正确运行的!)
根据定理,分布式系统只能满足三项中的两项而不可能满足全部三项;

对于一致性
有两个关键字:同一份、最新;
同一份意味着所有数据节点中的数据都要是一致的,最新意味着这些数据不能都是错误的;
对于可用性
意味着每次请求都能够获取到非错的响应,但是获取到的数据不一定是最新的,只要是成功的响应即可;
对于分区容错性
从实际效果而言,分区相当于对通信时限的要求;即:
系统如果不能在某个时间内达成一致性,就意味着发生了分区的情况,必须就当前操作,在C和A中做出选择!
更具体的说:
分区容错性就是指,尽管任意数量的消息被节点之间的网络问题造成丢失或者延迟(网络丢包,网络中断),
但是仍然要保证系统不能崩溃(系统能够容忍这些问题);
在一个上千台设备组成的大集群中,网络、硬件设备几乎是无时不刻都在发生的!
CAP理论理解
首先要注意:CAP 理论中的 C 和数据库事务ACID 中的 C 完全不是一个意思!
ACID 中 C 的一致性指的是事物的一致性状态,即:
数据库任何数据库事务修改数据必须满足定义好的规则,包括数据完整性(约束)、级联回滚、触发器等!
例如:
a 向 b 转账 100 块钱,事物一致性(C) 要求在事务前、中、后都要保证
a+b的和相同!
而CAP中的C可以理解为:
副本一致性:所有集群中的所有副本的值都是一样的!
为什么CAP三者无法共存
在没有网络分区和网络波动的情况下,我们无需为了P而舍弃C或者A;
但是一个大集群中的网络几乎无时不刻都存在问题(网络分区或者网络波动时刻发生),因此:
为了保证P(即,整个分布式系统还是可用的),就要舍弃C和A中的一个;
例如:存在三个副本,则对于这三个副本的写入有两种可能的方案:
- W=1(一写):向三个副本写入,只要一个副本返回写入成功即认为成功;
- W=3(三写):向三个副本写入,必须三个副本都写入成功才认为成功;
在不考虑副本投票选举(Quorum Replication)和共识(Consensus)算法的情况下:
在一写的情况下(W=1):
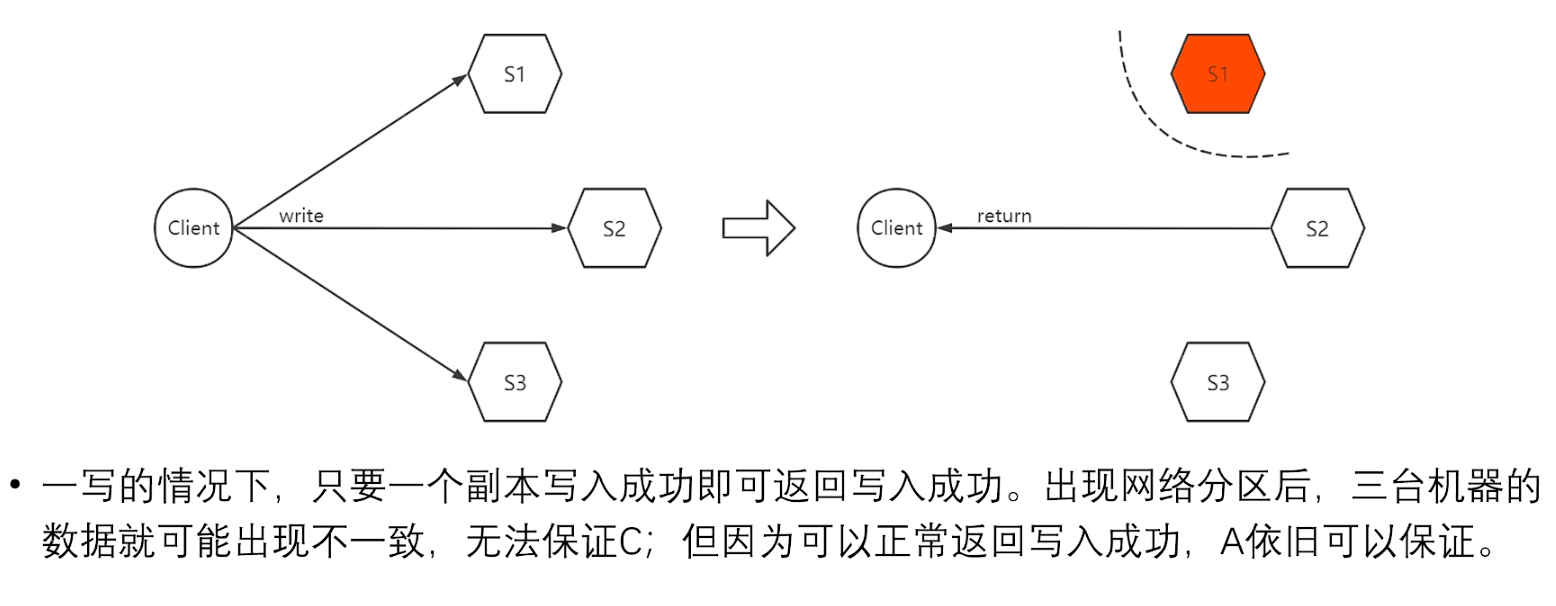
由于只要有一个副本写入成功即可返回成功;
当存在网络分区后(如上图S1的网络和其他节点中断),三台机器的数据就可能出现不一致的情况,因此无法保证C;
但是由于可以正常的返回写入成功,所以A可以保证!
在三写的情况下(W=3):

此方案要求三个副本都要写入成功才可以返回成功;
当出现网络分区后,由于无法保证三个节点都写入成功,因此最终会返回错误;
所以此时失去了A,但是由于数据没有被成功写入,因此保证了C!
CAP理论在分布式数据库下的场景
前文提到了,在现实生活中由于集群网络的复杂性 P 是一定存在的!
因此一旦出现了网络分区,那么一致性和可用性就要抛弃一个!
通常情况下:
- 对于 NoSQL 数据库,由于更加注重可用性(例如:缓存等场景),因此会是一个AP系统;
- 对于分布式关系型数据库,必须要保证一致性,因此就是一个 CP 系统;
需要注意的是:
虽然分布式关系型数据库是一个 CP 系统,但是仍然是具有高可用性需求的,虽然达不到理论上 100% 的可用性,但是一般都具备5个9(99.999%)以上的高可用!
我们可以将关系型数据库看作是 CP + HA(Hign Availability) 的系统,因此产生了两个重要且广泛使用的指标:
- RPO(Recovery Point Objective,恢复点目标):指数据库在灾难发生后会丢失多长时间的数据,对于分布式数据库基本上 RPO=0;
- RTO(Recovery Time Objective,恢复点时间):指数据库在灾难发生后到整个系统恢复正常所需要的时间,对于分布式数据库通常情况下 RTO<几分钟;
可以认为:
- RPO对应了CAP中的C,因此一般情况下 RPO 都是0,因为数据一致性是保证的,没有副本丢失数据;
- RTO对应 HA,虽然不能完全保证A,但是可以达到高可用;
辩证看待CAP理论
CAP 理论是一个证明在现实场景下你无法达到什么的理论(即:追求CAP都保证),这个理论限制了分布式系统设计者的行为;
类似于能量守恒理论限制了你无法设计出永动机;
但是由于其 C 和 A 的条件都太过极端,就导致有些理解不深入的设计者认为选取了一个,就一定抛弃了另一个;
实际上在现实生活中,我们是根据实际场景,在保证一个指标的同时,对另一个指标进行 降级 处理,尽量的去保证这一指标;
CAP理论下目前成熟的分布式方案
前面提到了副本投票选举(Quorum Replication)和共识(Consensus)算法,这里来简单看一下;
Quorum Replication
Quorum Replication 主要包括三个部分:
- N:副本数;
- W:写入成功副本数;
- R:读取成功副本数;
简单可知,当 W+R>N 时,在系统中永远都存在至少一个副本是最新且正确的!
因此,对于系统中的多个节点,只需要保证
W+R>N即可(大多数成功即成功)!
当 N=3 时有两种设计:
- W=1,R=3:写可用AP,读一致CP,如:记录流水系统,需要快速写入但是可以暂时无法读取,并且不可以读到老旧的错误流水;
- W=3,R=1:写一致CP,读可用AP,如:电子商务系统,商家修改商品金额,可以容许暂时失败,但是会有大量客户去查看商品,需要保证读可用;
Consensus
在共识算法中,各个副本之间存在交互;
通常情况下,整个集群中会选举出一个 leader(例如:raft、paxos算法),所有操作由leader提供(读写操作);
- 当 leader 没有出现故障的情况下,整个集群的 CA 都可以得到保障!
- 当 leader 由于部分原因宕机,集群选举新的 leader,而此时系统在选举的短暂过程中不可用;
因此,共识算法通常都是一个 CP + HA 的系统;
附录
视频地址:
顺带说一句,最近在学习分布式存储相关的知识,戌米的论文笔记 绝对是一个宝藏 UP 主,他的所有视频基本上我都刷过了,讲的非常好,非常推荐!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK