

有序查找及顺序查找_wx619474981d7fe的技术博客_51CTO博客
source link: https://blog.51cto.com/Laccoliths/5694738
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

1 有序查找
查找就是根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素。
查找表按照操作方式分成两大种:
- 静态查找表(Static Search Table):只作查找操作的查找表
- 查询某个“特定的”数据元素是否在查找表中。
- 检索某个“特定的”数据元素和各种属性。
- 动态查找(Dynamic Search Table):在查找过程中同时插入查找表中不存在的数据元素,或者从查找表中删除已经存在的某个数据元素。
- 查找时插入数据元素。
- 查找时删除数据元素。
顺序查找又叫做线性查找,是最基本的查找技术,它的查找过程是:从表中第一个(或最后一个)记录开始,逐个进行记录的关键字和给定值比较,若某个记录的关键字和给定值相等,则查找成功,找到所查的记录;如果直到最后一个(或第一个)记录,其关键字和给定值比较都不等时,则表中没有所查的记录,查找不成功。
顺序查找的算法实现如下:
/* 无哨兵顺序查找,a为数组,n为要查找的数组个数,key为要查找的关键字 */
int Sequential_Search(int *a,int n,int key)
{
int i;
for(i=1;i<=n;i++)
{
if (a[i]==key)
return i;
}
return 0;
}
这种算法在每次循环时都需要对i是否越界,即是否小于等于n作判断。优化此算法可以设置一个哨兵,可以解决不需要每次让i与n作比较。
/* 有哨兵顺序查找 */
int Sequential_Search2(int *a,int n,int key)
{
int i;
a[0]=key;
i=n;
while(a[i]!=key)
{
i--;
}
return i;
}
此时代码是从尾部开始查找, 由于a[0]=key,也就是说,如果在a[j]中有key则返回值,查找成功。否则—定在最终的a[0]处等于key,此时返回的是0,即说明a[1]-a[n]中没有关键字key,查找失败。
2 有序表查找
2.1 折半查找
折半查找(Binary Search)技术,又称为二分查找。
它的前提是线性表中的记录必须是关键码有序(通常从小到大有序),线性表必须采用顺序存储。
折半查找的基本思想是:在有序表中,取中间记录作为比较对象,若给定值与中间记录的关键字相等,则查找成功;若给定值小于中间记录的关键字,则在中间记录的左半区继续童找;若给定值大于中间记录的关键字,则在中间记录的右半区继续查找。不断重复上述过程,直到查找成功,或所有查找区域无记录,查找失败为止。
折半查找算法代码如下:
/* 折半查找 */
int Binary_Search(int *a,int n,int key)
{
int low,high,mid;
low=1; /* 定义最低下标为记录首位 */
high=n; /* 定义最高下标为记录末位 */
while(low<=high)
{
mid=(low+high)/2; /* 折半 */
if (key<a[mid]) /* 若查找值比中值小 */
high=mid-1; /* 最高下标调整到中位下标小一位 */
else if (key>a[mid])/* 若查找值比中值大 */
low=mid+1; /* 最低下标调整到中位下标大一位 */
else
{
return mid; /* 若相等则说明mid即为查找到的位置 */
}
}
return 0;
}
算法执行流程如下:
-
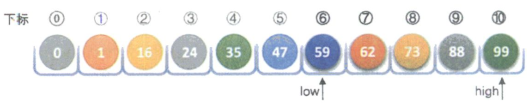
假设我们传入的参数a={0,1,16,24,35,47,59,62,73,88,99}a=\{0,1,16,24,35,47,59,62,73,88,99\}a={0,1,16,24,35,47,59,62,73,88,99},我们要查找的数值为62,初始化n=10,key=62,第3-5行,此时low=1,high=10,如图所示。

-
第6-15行循环,进行查找。
-
第8行,mid计算出得5,由于a[5]=47<key,所以执行第12行,low=5+1=6,如图所示。
-
再次循环,mid=(6+10)/2=8,此时a[8]=73>key,所以执行第10行,high=8-1=7,如图所示。

-
再次循环,mid=(6+7)/2=6,此时a[6]=59<key,所以执行第12行,low=6+1=7,如图所示。

-
再次循环,mid=(7+7)/2=7,a[7]=62=key,查找成功,返回7。
折半查找时间复杂度:O(log2n)O(log_2n)O(log2n)
3 线性索引查找
索引就是把一个关键字与它对应的记录相关联的过程。线性索引就是将索引项集合组织为线性结构,也称为索引表。
3.1 分块索引
分块查找是把数据集的记录分成若干块,并且这些块需要满足以下两个条件:
- 块内无序,即每一块内的记录不要求有序。当然,如果能够让块内有序对查找来说更理想,不过这就要付出大量时间和空间的代价,因此通常不要求块内有序。
- 块间有序,例如,要求第二块所有记录的关键字均要大于第—块中所有记录的关键字,第三块所有记录的关键字均要大于第二块所有记录的关键字。因为只有块间有序,才有可能在查找时提高效率。

对于分块有序的数据集,将每块对应一个索引项,这种索引方法叫做分块索引,如右图所示,我们定义的分块索引的索引项结构分三个数据项:
- 最大关键码,它存储每一块中的最大关键字,这样的好处就是可以使得在它之后的下—块中的最小关键字也能比这一块最大的关键字要大。
- 存储了块中的记录个数,以便于循环时使用。
- 用于指向块首数据元素的指针,便于开始对这一块中的记录进行遍历。
在分块索引表中查找,就是分以下两步进行:
- 在分块索引表中查找要查关键字所在的块。由于分块索引表是块间有序的,因此很容易利用折半算法得到结果。例如,在上图的数据集中查找62,我们可以很快从左上角的索引表中由57<62<96得到62在第三个块中。
- 根据块首指针找到相应的块,并在块中顺序查找关键码。因为块中可以是无序的,因此只能顺序查找。
设nnn个记录的数据集被平均分成mmm块,每个块中有ttt条记录,显然n=m×tn=m \times tn=m×t。再假设LbL_bLb为查找索引表的平均查找长度,因最好与最差的筹概率原则,所以LbL_bLb的平均长度为m+12\frac{m+1}{2}2m+1。LbL_bLb为块中查找记录的平均查找长度,同理可知它的平均查找长度为t+12\frac{t+1}{2}2t+1。
这样分块索引查找的平均查找长度为
ASLw=Lb+Lw=m+12+t+12=12(m+t)+1=12(nt+t)+1ASL_w=L_b+L_w=\frac{m+1}{2}+\frac{t+1}{2}=\frac{1}{2}(m+t)+1=\frac{1}{2}(\frac{n}{t}+t)+1 ASLw=Lb+Lw=2m+1+2t+1=21(m+t)+1=21(tn+t)+1
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK