

Jenkins结合MySql Database插件的平台化实践思路
source link: https://wiki.eryajf.net/pages/ef36d8/#%E6%80%9D%E8%B7%AF%E6%89%A9%E5%B1%95
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Jenkins结合MySql Database插件的平台化实践思路
# 前言
以往 Jenkins 实践当中,配置了共享库的流水线方案,通过将核心公共逻辑抽离成膜版,项目个性化配置信息放到引导文件中的方式进行推进。
这种方案没有什么毛病,对于运维的维护工作也是比较友好的,只是后来我们打算再在 Jenkins 上层做一下平台化封装的时候,发现还是存在一些问题,并且有一些难度的。
最近我了解学习到了一个与 MySQL Database 插件结合的思路,能够比较好解决这种问题,那么接下来话不多说,直接进入正题,让我们来认识一下这个插件。
# 安装插件
安装如下两个插件:
因为 MySQL 的插件会需要依赖一个 database 的驱动,因此也要安装这个插件。
# 配置插件
插件成功安装之后,我们来到 系统管理 --->系统设置,然后搜索 database,可以看到数据库的配置项。
配置信息都比较常规,也就不一一介绍了,只需要在数据库当中创建一个 jenkins 库,然后按如下截图配置即可:
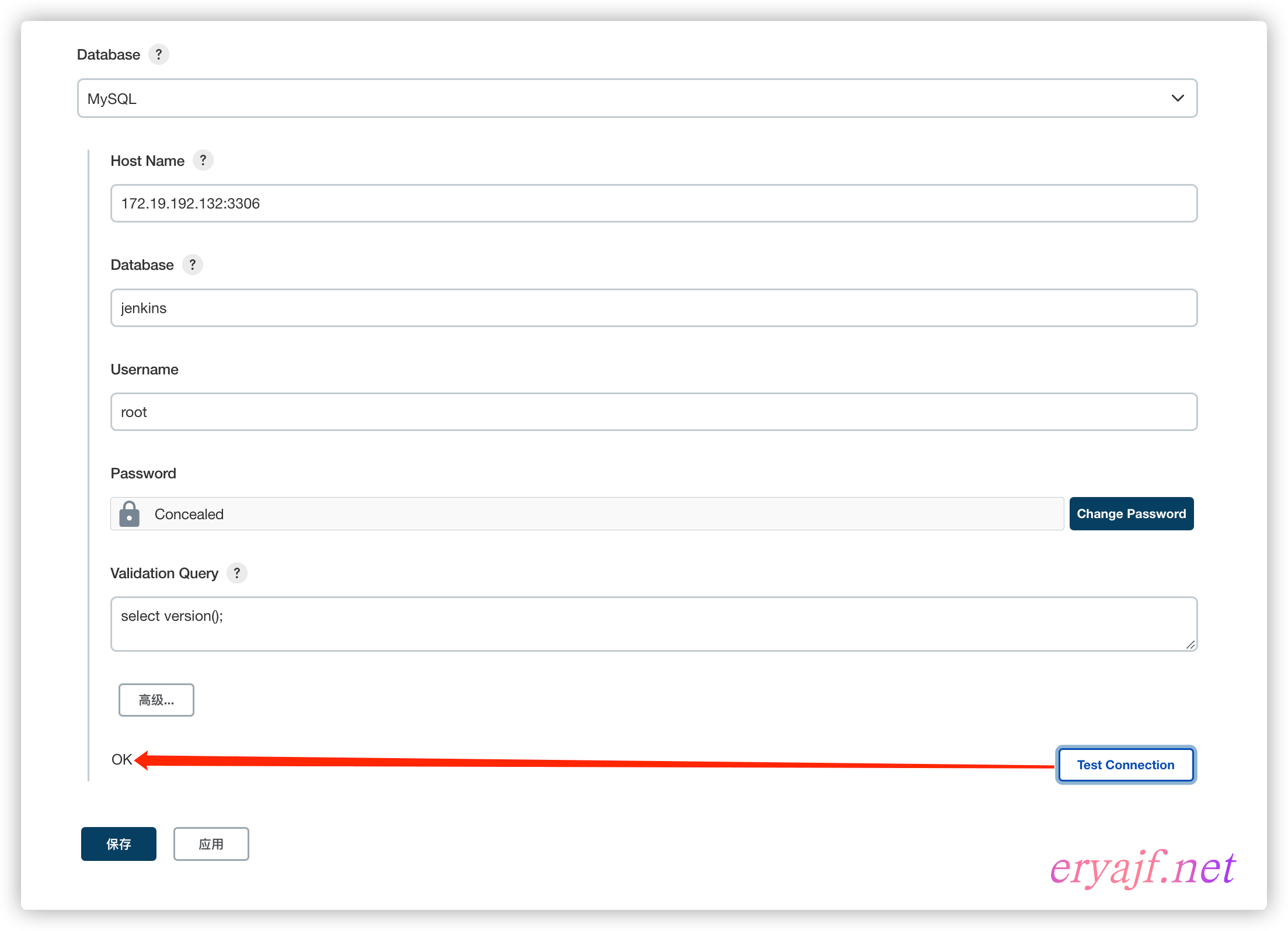
其中的测试语句为:select version();
如果点击 Test Connection 之后报如下错误:
javax.net.ssl.SSLHandshakeException: No appropriate protocol (protocol is disabled or cipher suites are inappropriate)
则需要对 JDK 进行一点配置的调整:
$ vim /opt/java/openjdk/conf/security/java.security
# 将这行内容 jdk.tls.disabledAlgorithms=SSLv3, TLSv1, TLSv1.1, RC4, DES, MD5withRSA, \ 中的 SSL 部分删去,改后的效果如下
jdk.tls.disabledAlgorithms=RC4, DES, MD5withRSA, \
然后重启 Jenkins,再次进行配置测试,应该就能通过了。
# 使用
配置完毕之后,我们就可以通过一个固定语句,在流水线当中,与数据库进行交互了。
比如我的项目需要的配置信息有如下内容:
那么就创建一个项目信息的表:
CREATE TABLE `job_msg` (
`run_node` varchar(255) DEFAULT NULL,
`service_name` varchar(255) DEFAULT NULL,
`webroot_dir` varchar(255) DEFAULT NULL,
`default_branch` varchar(255) DEFAULT NULL,
`git_url` varchar(255) DEFAULT NULL,
`hosts` varchar(255) DEFAULT NULL,
`build_command` varchar(255) DEFAULT NULL,
`free_command` varchar(255) DEFAULT NULL,
`exclude_file` varchar(255) DEFAULT NULL,
`build_base_image` varchar(255) DEFAULT NULL,
`project_file_path` varchar(255) DEFAULT NULL,
`robot_key` varchar(255) DEFAULT NULL,
`job_name` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
然后存进去一条数据:
INSERT INTO `job_msg` (`run_node`, `service_name`, `webroot_dir`, `default_branch`, `git_url`, `hosts`, `build_command`, `free_command`, `exclude_file`, `build_base_image`, `project_file_path`, `robot_key`, `job_name`) VALUES ('master', 't-eryajf-blog.eryajf.net', '/data/www/${SERVICE_NAME}', 'main', 'https://jihulab.com/eryajf-jenkins/eryajf-blog.git', 'ALL\\n172.19.192.132', 'echo test', 'chown -R www.www /data/www/${SERVICE_NAME}/', 'ansible_tmp\\nansible_tmp@tmp\\n.git\\nnode_modules', 'eryajf/node:10.6', '.', '6a781aaf-0cda-41ab-9bd2-ed81ee7fc7d2', 'test-eryajf-blog');
此时我们把 job_name 字段作为该表的唯一标识,那么创建一个项目,就可以通过如下配置拿到对应的数据:
// 获取 job 信息
res = get_mysql_msg("${JOB_BASE_NAME}")
if ( res == []) { throw new Exception(" ${JOB_NAME}没有找到对应的项目信息 ") }
job_msg = get_job_msg(res)
// 判断是否已经具有 service_name 如果没有则通过jobname 赋值
if ( !job_msg.service_name ) {
service_name = "${JOB_NAME}"
}
// 各个参数落位
env.RUN_NODE = "${job_msg.run_node}"
env.SERVICE_NAME = "${job_msg.service_name}"
env.WEBROOT_DIR = "${job_msg.webroot_dir}"
env.DEFAULT_BRANCH = "${job_msg.default_branch}"
env.GIT_URL = "${job_msg.git_url}"
env.HOSTS = "${job_msg.hosts}"
env.BUILD_COMMAND = "${job_msg.build_command}"
env.FREE_COMMAND = "${job_msg.free_command}"
env.EXCLUDE_FILE = "${job_msg.exclude_file}"
env.BUILD_BASE_IMAGE = "${job_msg.build_base_image}"
env.PROJECT_FILE_PATH = "${job_msg.project_file_path}"
env.ROBOT_KEY = "${job_msg.robot_key}"
pipeline {
agent any
stages {
stage('# 构建开始') {
steps {
script{
sh "printenv"
}
}
}
}
}
// 拉取job在数据库中的信息
def get_mysql_msg(jobName) {
println "===========获取${jobName}信息============"
getDatabaseConnection(type: 'GLOBAL') {
def result = sql("SELECT * FROM job_msg WHERE job_name=\"${jobName}\"")
return result
}
}
// 格式化数据信息,返回的是map信息
def get_job_msg (res) {
message = ""
for (i in res) {
if (i != "[" && i != "]") {
message += i
}
}
job_map = message.split(', ').collectEntries{it.replaceFirst(/:/, '000000').minus("]").minus("[").split('000000') as List}
return job_map
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
其中的 get_mysql_msg() 方法就是通过项目名作为唯一标识,然后去数据库里拿到这个项目对应的其他匹配信息,再填充到整个构建流程当中。
同理,构建过程中,如果有需要往库里写数据的时候,比如要将当次构建的一些信息存库的话,仍然可以调用如下方式进行:
// 向数据库中插入本次构建记录
def set_job_history (buildId,platForm,jobName,branch,buildImage,messAge,build_user) {
getDatabaseConnection(type: 'GLOBAL') {
def result = sql("INSERT INTO `job_histoy` SET build_id='" + buildId + "',platform= '" + platForm + "',job_name= '" + jobName + "',branch= '" + branch + "',build_image= '" + buildImage + "',build_user='" + build_user + "',message= '" + messAge + "';")
}
}
2
3
4
5
6
# 思路扩展
当我们已经捋顺了上边的思路之后,就可以把思路再打开一下。
一个项目的元数据信息,通过工单平台,由研发人员提交上来,经过审核之后,这份数据就会存在 MySQL 当中,然后 Jenkins 平台只需要创建一个 job_name 对应的项目,直接套入到这个模板即可,而不再需要关心维护其他数据了。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK