

被一位读者赶超,手摸手 Docker 部署 ELK Stack - 悟空聊架构
source link: https://www.cnblogs.com/jackson0714/p/docker_elk.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

被一位读者赶超,容器化部署 ELK Stack
你好,我是悟空。
被奇幻“催更”
最近有个读者,他叫“老王“,外号“茴香豆泡酒”,找我崔更 ELK 的文章。
因之前我用的是软件安装 Logstash + Filebeat 的方式:
7000 字 | 20 图 | 一文带你搭建一套 ELK Stack 日志平台
他想知道如何用容器化部署 ELK,于是我先写了一半,因为要写其他文章所以耽搁了。没想到过了几天后,老王说他已经部署好了,还写了篇文章,恐怖如斯啊!
那可不行,我不能输给他,必须自己安排一篇。那么我写的这篇有哪些特色内容呢?
- 支持离线环境部署 ELK。
- 支持离线安装 Logstash 多行插件。
- 生产级别 Logstash 配置。
- 生产级别 Filebeat 配置。
- Filebeat 如何做到重新同步导入。
- 一步一图,手摸手教程了。
本文主要内容如下:

这次我们演示在单机上用 Docker 部署 ELK Stack,大家可以参照这个教程部署在集群环境中。
ELK Stack 整体的工作流程如下:

流程如下:
- 1、微服务写入日志到本地文件中。
- 2、Filebeat 组件监控日志文件变化,将日志收集起来。
- 3、Filebeat 把数据传给 Logstash 组件。
- 4、Logstash 具有强大的数据清洗和过滤功能,然后写入到 Elasticsearch 中。
- 5、Kibana 可视化工具从 Elasticsearch 中查询数据并展示出来。
演示环境:
- Ubuntu 18.04 虚拟机一台
- Elasticsearch、Logstash、Kibana、Filebeat、容器的版本为 7.6.2
最后启动了 5 个容器:

一、Docker 方式部署 Elasticsearch 数据库
1.1 安装 Elasticsearch
方案一:从互联网下载 Elasticsearch 镜像
docker pull elasticsearch:7.6.2
方案二:离线安装加载 Elasticsearch 镜像
# 从有互联网的机器上下载 Elasticsearch 镜像
sudo docker pull elasticsearch:7.6.2
# 从有互联网的机器上保存 logstash 镜像
sudo docker save -o es.tar es
# 设置 logstash 镜像的权限,保证能有权限拷贝到其他机器
sudo chmod 777 es.tar
# 在离线的机器上加载 logstash 镜像
sudo docker load -i es.tar

1.2 配置 ES
创建挂载目录
mkdir -p /data/elk/es/{config,data,logs,plugins}
sudo chown -R 1000:1000 /data/elk/es
创建配置文件
cd /data/elk/es/config
sudo touch elasticsearch.yml
-----------------------配置内容----------------------------------
cluster.name: "my-es"
network.host: 0.0.0.0
http.port: 9200
http.cors.enabled: true
http.cors.allow-origin: "*"
1.3 启动 elasticsearch 容器
docker run -it -d \
-p 9200:9200 \
-p 9300:9300 \
--name es01 \
-e ES_JAVA_OPTS="-Xms1g -Xmx1g" \
-e "discovery.type=single-node" \
--restart=always \
-v /data/elk/es/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /data/elk/es/data:/usr/share/elasticsearch/data \
-v /data/elk/es/logs:/usr/share/elasticsearch/logs \
-v /data/elk/es/plugins:/usr/share/elasticsearch/plugins \
elasticsearch:7.6.2

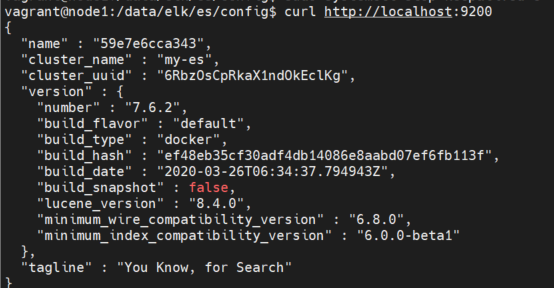
1.4 验证 elasticsearch 是否启动成功
curl http://localhost:9200
1.5 安装 ES 辅助工具
这个工具安装好了后,相当于启动了一个服务,这个服务是一个站点,通过在站点里面访问 ES 的 API,就可以获取到 ES 的当前信息了。
安装步骤如下:
- 下载 elasticsearch-head 镜像
sudo docker pull mobz/elasticsearch-head:5
- 运行 elasticsearch-head 容器
docker run -d -p 9100 9100 mobz/elasticsearch-head:5
- 用浏览器访问 elasticsearch-head 网址
http://192.168.56.11:9100/
- 修改网站中的 ES 的连接地址
http://192.168.56.11:9200/

就可以看到 ES 的集群和索引信息了,这个要比在 Kibana 中用 DevTools 查看更方便。
1.6 IK 分词器
https://github.com/medcl/elasticsearch-analysis-ik/releases
选择 ES 对应版本的 IK 分词器,我的 ES 版本为 7.6.2。

解压后,拷贝到 /data/elk/es/plugins/ik/ 目录

二、Docker 方式部署 Kibana 可视化工具
2.1 安装 Kibana
获取 kibana 镜像
docker pull kibana:7.7.1
获取elasticsearch容器 ip
docker inspect --format '{{ .NetworkSettings.IPAddress }}' es01
结果:172.17.0.2
创建 kibana 配置文件
mkdir -p /data/elk/kibana/
vim /data/elk/kibana/kibana.yml
配置内容:
#Default Kibana configuration for docker target
server.name: kibana
server.host: "0"
elasticsearch.hosts: ["http://172.17.0.2:9200"]
xpack.monitoring.ui.container.elasticsearch.enabled: true
2.2 运行 kibana
docker run -it -d --restart=always \
--name kibana -p 5601:5601 -v /data/elk/kibana/kibana.yml:/usr/share/kibana/config/kibana.yml kibana:7.6.2
访问 http://192.168.56.10:5601 。这个 IP 是服务器或虚拟机的 IP。Kibana 控制台的界面如下所示,打开 kibana 时,首页会提示让你选择加入一些测试数据,点击 try our sample data 按钮就可以了。

Kibana 界面上会提示你是否导入样例数据,选一个后,Kibana 会帮你自动导入,然后就可以进入到 Discover 窗口搜索日志了。
离线方式安装 Kibana 方式
sudo docker save -o kibana.tar kibana
sudo chmod 777 kibana.tar
sudo docker load -i kibana.tar

三、Docker 方式安装 Logstash
3.1 拉取 Logstash 镜像
方案一:从互联网下载镜像
sudo docker pull logstash:7.6.2
方案二:离线安装镜像
# 从有互联网的机器上下载 logstash 镜像
sudo docker save -o logstash.tar logstash
# 设置 logstash 镜像的权限,保证能有权限拷贝到其他机器
sudo chmod 777 logstash.tar
# 在离线的机器上加载 logstash 镜像
sudo docker load -i logstash.tar
临时方式启动,主要是为了映射整个 Logstash 目录,后面方便安装 logstash 插件
docker run -d --name=logstash logstash:7.6.2
将容器内的文件夹拷贝到宿主机磁盘上
sudo docker cp logstash:/usr/share/logstash /data/elk

添加 logstash 文件夹的权限
cd /data/elk/
sudo chmod 777 logstash -R
3.2 创建采集配置文件
创建 logstash.conf 采集配置文件
sudo mkdir -p /data/elk/logstash/conf.d
cd /data/elk/logstash/conf.d
sudo vim logstash.conf
配置内容如下:
input {
beats {
port => 5044
}
}
filter {
grok {
match => [ "message", "(?<logTime>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3})\s+\[(?<thread>.*)\]\s+(?<level>\w*)\s{1,2}+(?<class>\S*)\s+-\s+(?<content>.*)\s*"]
match => [ "message", "(?<logTime>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3})\s{1,2}+(?<level>\w*)\s{1,2}+.\s---+\s\[(?<thread>.*)\]+\s(?<class>\S*)\s*:+\s(?<content>.*)\s*"]
match => [
"source", "/home/passjava/logs/(?<logName>\w+)/.*.log"
]
overwrite => [ "source"]
break_on_match => false
}
mutate {
convert => {
"bytes" => "integer"
}
remove_field => ["agent","message","@version", "tags", "ecs", "_score", "input", "[log][offset]"]
}
useragent {
source => "user_agent"
target => "useragent"
}
date {
match => ["logTime", "MMM d HH:mm:ss", "MMM dd HH:mm:ss", "ISO8601"]
timezone => "Asia/Shanghai"
}
}
output {
stdout { }
elasticsearch {
hosts => ["192.168.56.11:9200"]
index => "passjava_log"
}
}
3.3 创建 logstash 配置文件
创建 logstash.yml 配置文件
cd /data/elk/logstash/config
sudo vim logstash.yml
配置内容如下:
# 指定管道配置的目录,在此目录下的所有管道配置文件都将被 logstash 读取,除管道配置外,不要放任何文件
path.config: /usr/share/logstash/conf.d/*.conf
# logstash 日志目录位置,默认为 logstash 路径下的 logs
path.logs: /var/log/logstash
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://192.168.56.11:9200" ]
3.4 启动 logstash 容器
# 删除 logstash 容器
docker rm -f logstash
# 启动 logstash 容器
docker run -it -d \
-p 5044:5044 \
--name logstash \
--restart=always \
-v /data/elk/logstash:/usr/share/logstash \
logstash:7.6.2


3.5 安装 multiline 插件
还有一个坑的地方是错误日志一般都是很多行的,会把堆栈信息打印出来,当经过 logstash 解析后,每一行都会当做一条记录存放到 ES,那这种情况肯定是需要处理的。这里就需要使用 multiline 插件,对属于同一个条日志的记录进行拼接。
3.5.1 安装 multiline 插件
multiline 不是 logstash 自带的,需要单独进行安装。我们的环境是没有外网的,所以需要进行离线安装。
介绍在线和离线安装 multiline 的方式:
- 在线安装插件。
在 logstash 根目录执行以下命令进行安装。
bin/logstash-plugin install logstash-filter-multiline

- 离线安装插件。
在有网的机器上在线安装插件,然后打包。
bin/logstash-plugin install logstash-filter-multiline
bin/logstash-plugin prepare-offline-pack logstash-filter-multiline
拷贝到服务器,/data/elk/logstash/mutiline
进入到容器中
docker exec -it logstash /bin/bash
执行安装命令
cd /usr/share/logstash
bin/logstash-plugin install file:///usr/share/logstash/mutiline/logstash-offline-plugins-7.6.2.zip
安装插件需要等待 2 分钟左右的时间,控制台界面会被 hang 住,当出现 Install successful 表示安装成功。

检查下插件是否安装成功,可以执行以下命令查看插件列表。当出现 multiline 插件时则表示安装成功。
bin/logstash-plugin list

3.5.2 添加 mutiline 配置
编辑 logstash.conf 配置文件
cd /data/elk/logstash/conf.d/
sudo vim logstash.conf
filter 节点下添加 mutiline 配置。
input {
beats {
port => 5044
}
}
filter {
multiline {
pattern => "^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}.\d{3}"
negate => true
what => "previous"
}
grok {
match => [ "message", "(?<logTime>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3})\s+\[(?<thread>.*)\]\s+(?<level>\w*)\s{1,2}+(?<class>\S*)\s+-\s+(?<content>.*)\s*"]
match => [ "message", "(?<logTime>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3})\s{1,2}+(?<level>\w*)\s{1,2}+.\s---+\s\[(?<thread>.*)\]+\s(?<class>\S*)\s*:+\s(?<content>.*)\s*"]
match => [
"source", "/home/passjava/logs/(?<logName>\w+)/.*.log"
]
overwrite => [ "source"]
break_on_match => false
}
mutate {
convert => {
"bytes" => "integer"
}
remove_field => ["agent","message","@version", "tags", "ecs", "_score", "input", "[log][offset]"]
}
useragent {
source => "user_agent"
target => "useragent"
}
date {
match => ["logTime", "MMM d HH:mm:ss", "MMM dd HH:mm:ss", "ISO8601"]
timezone => "Asia/Shanghai"
}
}
output {
stdout { }
elasticsearch {
hosts => ["192.168.56.11:9200"]
index => "passjava_log"
}
}
关于 Logstash 如何配置的内容,请查看这篇:
深入理解 ELK 中 Logstash 的底层原理 + 填坑指南
3.5.4 重新启动 logstash 容器
docker restart logstash
四、Docker 方式安装 Filebeat
4.1 拉取 filebeat 镜像
docker pull elastic/filebeat:7.6.2

临时方式启动,主要是为了映射整个 filebeat 目录,后面可以修改同步进度以及查看日志文件。
docker run -d --name=filebeat elastic/filebeat:7.6.2
将容器内的文件夹拷贝到宿主机磁盘上
docker cp filebeat:/usr/share/filebeat /data/elk

创建日志目录作为测试
sudo mkdir -p /data/passjava/logs
4.2 配置 filebeat
创建日志目录作为测试
sudo mkdir -p /data/passjava/logs
创建 filebeat 配置文件
vim /data/elk/filebeat/filebeat.yml
配置内容如下:
filebeat.inputs:
- type: log
enabled: true
paths:
- /usr/share/filebeat/passjava/logs/*/info*.log
- /usr/share/filebeat/passjava/logs/*/warn*.log
- /usr/share/filebeat/passjava/logs/*/error*.log
fields:
log_catagory: service
fields_under_root: true
multiline.type: pattern
multiline.pattern: '^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}.\d{3}'
multiline.negate: true
multiline.match: after
multiline.max_lines: 52
output.logstash:
hosts: ["192.168.56.11:5044"]
这里配置的 paths 日志文件路径用来映射宿主机上的日志文件。
paths:
- /usr/share/filebeat/logbeat/*.log
sudo chmod 777 -R /data/elk/filebeat
sudo chmod go-w /data/elk/filebeat/filebeat.yml

启动 filebeat
# 删除 filebeat 容器
docker rm -f filebeat
# 启动 filebeat 容器
docker run -d \
--name=filebeat \
--restart=always \
-v /data/passjava/logs:/usr/share/filebeat/passjava/logs/ \
-v /data/elk/filebeat:/usr/share/filebeat \
elastic/filebeat:7.6.2
查看启动日志
docker logs -f filebeat

4.3 Filebeat 重新同步日志文件
当我们想要完全重新同步日志文件时,可以将 Filebeat 这个文件夹删掉:
/data/elk/filebeat/data/registry/filebeat
这个目录下的 data.json 文件会记录同步的进度,删掉后,重启 Filebeat 后就会重新开始同步。
五、测试日志文件写入 ES
5.1 创建日志文件
sudo vim /data/passjava/logs/wukong/error.log
模拟后端输出的日志:

5.2 观察 logstash 容器中的日志
docker logs logstash
可以看到 logstash 收集到了 filebeat 传输的日志。

5.3 观察 Filebeat 容器中的日志
docker logs filebat
可以看到 Filebeat 采集日志文件,并同步到 Logstash 的日志。

5.4 创建 ES 索引
当 Logstash 将日志同步到 Elasticsearch 中后,就会自动在 Elasticsearch 中创建索引。然后我们需要在 Kibana 可视化控制台中创建一个对应的索引来查看日志。步骤如下所示:
- 打开 Kibana 控制台

- 创建 passjava_log 索引
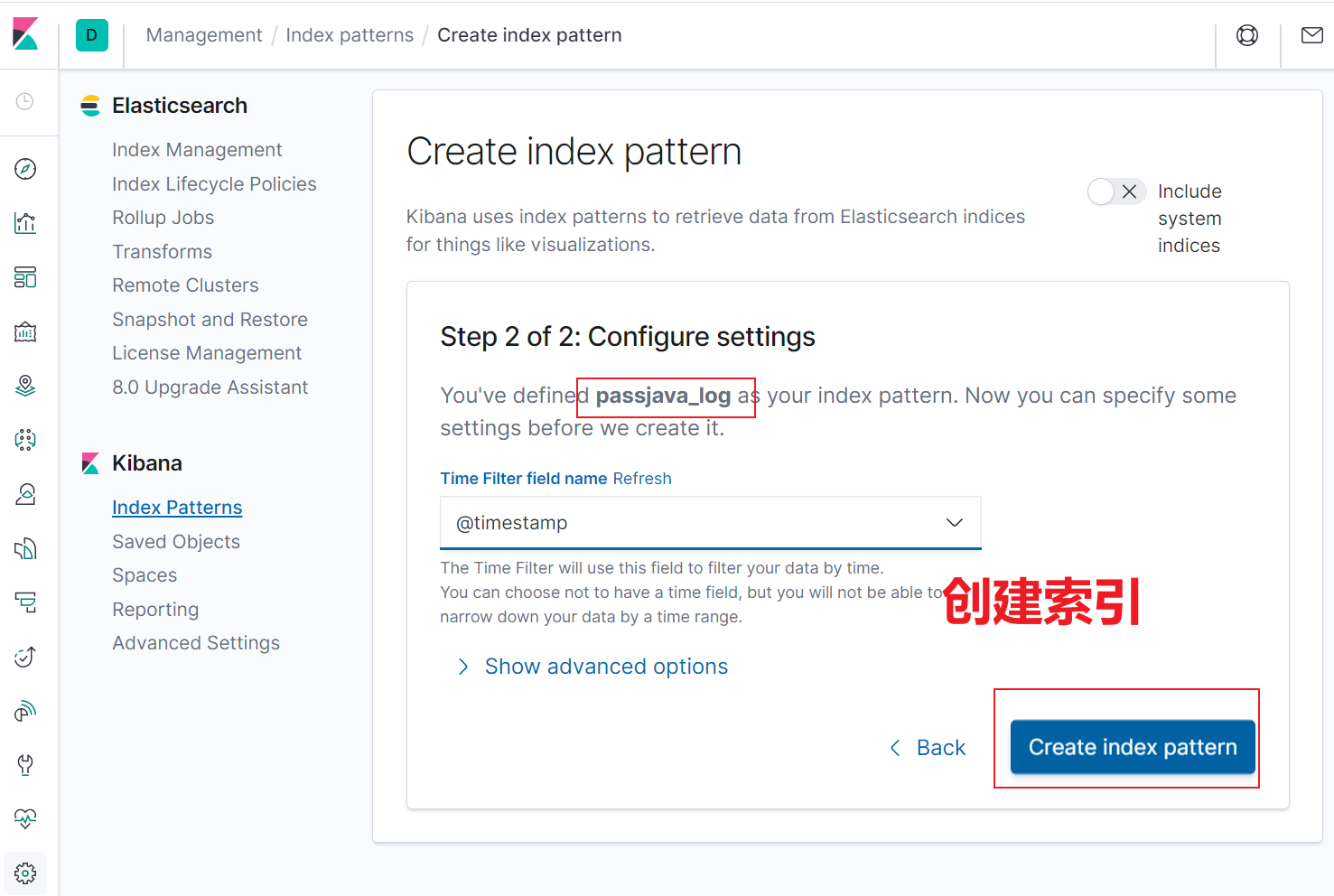
5.5 查询日志
在 Kibana 搜索大楼 关键字,可以查到日志输出。需要注意的是,要选择对应的过滤时间段。

六、报错问题排查
Filebeat 出现报错,但是过一会 Filebeat 和 Logstash 又成功建立了连接,而且日志也输出到了 Logstash 了。暂时未找到原因。
Failed to publish events caused by: EOF

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK