

一文搞懂DBMS和数据仓库的区别及联系,你明白了吗?
source link: https://www.51cto.com/article/717093.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

一文搞懂DBMS和数据仓库的区别及联系,你明白了吗?
在数据仓库技术以前,只存在事务处理,DBMS系统为这种处理类型的需要提供支持。但是,在数据仓库中的处理是截然不同的。数据仓库环境中的处理类型可以概括为装载和访问过程。数据从原来操作型数据环境和ODS中集成、转换和装载到数据仓库中去。一旦进入数据仓库,集成的数据就在那里访问和分析。在数据仓库中,数据一旦被装载,通常是不更新的。如果需要对数据仓库更正和调整的话,也是在对数据仓库数据没有分析操作的空闲时间进行。而且,这些改变也是通过加入一个当前的数据快照来完成。
传统的事务处理数据库环境和数据仓库环境的另一个重要的区别在于,数据仓库环境中有很多的数据,比一般的操作型环境中要多得多,以万亿或千万亿计,而一个通用的DBMS通常管理下的传统事务处理数据库中的数据要少得多。数据仓库要管理大量的数据,是因为它们包括如下内容:
- 粒化的原子细节。
- 历史信息。
- 细节和汇总数据。
谈到基本的数据管理功能,数据仓库用与标准的操作型DBMS非常不同的一组参数进行优化。
传统的通用DBMS和数据仓库专用DBMS的第一个也是最重要的区别在于数据更新是如何进行的。传统的通用DBMS必须将记录级的、基于事务的更新作为一个正常的操作部分。由于记录级、基于事务的数据更新是通用DBMS的一般特征,所以它必须提供以下功能:
- 日志磁带处理。
- 逆向恢复。
不仅这些特征确实已成为DBMS一个常规部分,它们的开销也是巨大的。有趣的是,当DBMS不使用时也要耗费这笔开销。换句话说,当通用DBMS仅执行只读操作时,DBMS也至少要提供更新和锁定的开销(取决于DBMS)。根据不同的通用DBMS,更新所需的开销能不同程度地最小化,但不能完全没有。而对于一个数据仓库专用的DBMS来说,不用支付任何更新所需的开销。
通用DBMS和数据仓库专用DBMS之间的第二个主要区别是对基本数据的管理的不同。对于通用的DBMS来说,对数据在块级上的管理要包括一些附加的空间,这些空间是用于以后更新和插入数据时块的扩展。一般情况下,这些空间是自由空间。对于通用DBMS,自由空间可能占到50%。对于数据仓库专用的DBMS,根本就不需要自由空间,因为数据一旦装入到数据仓库后是不需要更新的,也就没有物理块扩展的需要。事实上,给定了数据仓库中要管理的数据量后,留下以后将永远不会用到的大量空间是没有任何意义的。
数据仓库和通用环境之间的另一个相关的区别反映在不同类型的DBMS上,是索引的区别。通用DBMS环境限制在有限数量的索引,这个限制是因为当有数据的更新和插入时,索引本身需要空间和数据管理。然而,在数据仓库环境中没有数据的更新,却有必要对数据的访问进行优化,也有多种索引的必要(和机会)。事实上,数据仓库相对于操作型的、面向更新的数据库来说,能够应用更稳健和更完善的索引结构。
除了索引、更新和物理块级上的基本数据管理以外,在数据管理能力和策略上,通用DBMS和数据仓库专用DBMS之间还存在其他一些基本区别。其中,这两种类型的DBMS最基本的区别可能是在物理上以优化方式组织数据以适应不同类型访问的能力。通用DBMS在物理上组织数据是为了优化事务的访问和处理。以这种方式进行的组织使得许多不同类型的数据可以根据一个公共关键字聚集起来,并能有效地通过1次或2次I/O访问。最适合于信息型访问的数据通常具有一个区别很大的物理描述。最适合于信息型访问的数据是经过组织的,可以使对同一类型数据的许多不同值能够通过1次或2次物理I/O高效地进行访问。
数据能够在物理上得到优化以便于事务访问或DSS访问,但无法同时做到这两点。通用的、基于事务的DBMS只针对事务访问对数据进行优化,而数据仓库专用的DBMS则针对DSS访问和分析在物理上对数据进行优化。
1.改变DBMS技术
信息仓库需要考虑的一个有趣的因素是,在数据仓库数据已经载入以后, DBMS技术发生变化。有以下几个原因说明进行这种改变:
- 当今可用的DBMS技术,在数据仓库首次载入数据时并不一定适合。
- 数据仓库大小已经增长到一定的程度,要求提出新的技术方法。
- 对数据仓库的使用逐步增加,也发生了很多变化,使得当前的数据仓库的DBMS技术不满足要求了。
- 需要不时地对基本的DBMS选择进行审查。
是否应考虑找一种新的DBMS技术?要考虑的因素是什么?以下的几点非常重要:
- 新的DBMS技术是否满足可预知的需求?
- 从旧的DBMS技术向新的DBMS技术的转换应该怎样去做?
- 转换的程序应该怎样改变?
所有的这些考虑因素中,最后一个是最令人头痛的。即使在最好的情况下,试图去改变转换程序也是一项很复杂的工作。
事实上,一旦数据仓库已经采用了一个DBMS,在以后某个时间进行更改是可能的。但这种情况在事务处理的过程中是永远不可能的,因为一旦采用了一个DBMS,只要事务处理系统仍在运行当中,这个DBMS就必须保持不动。
2.多维DBMS和数据仓库
一项在数据仓库中经常讨论的技术是多维数据库管理系统处理(有时称为OLAP处理)。多维数据库管理系统或者数据集市提供了一种信息系统结构,这种结构可以使企业灵活地对数据进行访问,可以用多种方法对数据进行切片、分块,动态地考察汇总数据和细节数据之间的关系。多维DBMS为最终用户提供了灵活性和控制功能。为此,它非常适合于DSS环境。如图1所示,多维DBMS和数据仓库之间存在着非常有趣和互补的关系。
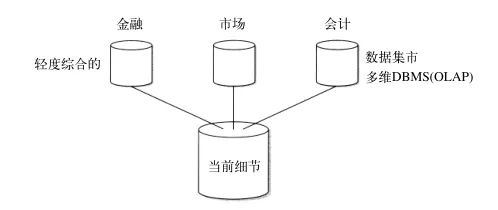
图1 数据仓库的传统结构以及当前细节数据是如何同部门数据(或多维DBMS,数据集市)结合起来的
数据仓库中的细节数据为多维DBMS提供了非常稳健和方便的数据源。因为多维DBMS需要定期地刷新,为此,数据要定期从数据仓库中导入到多维DBMS中。由于历史应用数据在进入数据仓库时被集成,多维DBMS就不再需要从操作型环境中抽取与集成它所需要的数据。另外,数据仓库在最低级别上保存了数据,这样就能为那些使用多维DBMS的用户在需要的时候进行的低级别分析提供“基础”数据。
可能有人会认为多维DBMS技术应该是用于数据仓库的数据库技术,事实上除一些非常特殊的情况外,这种想法是不正确的。那些为了多维DBMS技术的功能而对其进行优化的性质并不是数据仓库的最基本的重要特性。数据仓库中最重要的特性也不是多维DBMS技术的特性。
看一下数据仓库和多维DBMS的区别:
- 数据仓库有大量的数据;多维DBMS中的数据至少要少一个数量级。
- 数据仓库只适于少量的灵活访问;而多维DBMS适合大量的不可预知的数据访问和分析。
- 数据仓库内存储了很长时间范围内的数据(从5年到10年);而多维DBMS中只存储较短时间范围内的数据。
- 数据仓库只允许分析人员以受限的形式访问数据,而多维DBMS允许自由的访问。
- 多维DBMS和数据仓库有着互补的关系,而并不是数据仓库建立在多维DBMS之上的关系。
数据仓库和多维DBMS关系中有趣的一点是,数据仓库可以为非常细节的数据提供基础,而这些数据在多维DBMS中通常是看不到的。数据仓库能容纳非常详细的数据,这些数据在导入多维DBMS时被轻度综合了。而导入到多维DBMS之后,数据会被进一步地汇总。在这种模式下,多维DBMS可以包含除了非常细节以外的所有数据。使用多维DBMS的分析者可以以一种灵活而高效的方法来对多维DBMS中所有不同层次的数据进行钻取。如果需要,分析者还可以向下钻取到数据仓库。通过这种方式将数据仓库和多维DBMS相结合,DSS分析者可以得到这二者的好处,在大部分时间里在多维DBMS中享受操作高效的优点。同时,还可以向下钻取到最低层次的细节数据。
另一个优势是汇总的信息在多维DBMS中计算和聚集后存储在数据仓库中。这样,汇总数据在数据仓库中能比在多维DBMS中存储更长的时间。
数据仓库和多维DBMS还有一个方面也是互补的。多维DBMS存放中等时间长度的数据,根据应用的不同从12个月到15个月。而数据仓库存放数据的时间跨度要大得多—从5年到10年。基于这一点,数据仓库就成为多维DBMS分析者进行研究的数据源。如果需要,多维DBMS分析者可以高兴地知道有大量的可用数据,而不用为在他们的环境中存储所有这些数据而进行花费。
多维DBMS有不同的特色。一些多维DBMS建立在关系模型基础上,而另一些多维DBMS建立在能优化“切片和分块”数据的基础上,在这里数据可以认为存储在多维立方体内。后者的技术基础可以称为立方体基础或OLAP基础。
两种技术基础都支持多维DBMS数据集市。但在这两种技术基础之间存在着一些差异。
多维DBMS数据集市的关系型基础如下:
能支持大量数据。
能支持数据的动态连接。
已被证实是有效的技术。
能够支持通用的数据更新处理。
如果对数据的使用模式不清楚,关系型结构与其他结构一样好。
性能上不是最佳的。
不能够对访问处理进行优化。
多维DBMS数据集市的立方体基础如下:
对DSS处理在性能上是优化的。
能够对数据的非常快的访问进行优化。
如果已知数据访问的模式,则数据的结构可以优化。
能够很轻松地进行切片和分块。
可以用许多途径进行检测。
无法处理像标准关系模式那么多的数据。
不支持通用更新处理。
装载的时间很长。
如果想选取的访问路径不被数据设计所支持,这种结构就显得不灵活。
对数据的动态连接的支持是有问题的。
多维DBMS(OLAP)是一种技术,而数据仓库是一种体系结构基础。这两者之间存在着依存的关系。在通常情况下,数据仓库是作为需要流入多维DBMS的数据的基础,将选出的细节数据的子集转入多维DBMS,在那里对数据进行汇总或聚集。但在某些范围内,有一种观点是多维DBMS并不需要数据仓库作为它的数据的基础。
如果没有数据仓库作为多维DBMS的基础,那么装入多维DBMS中的数据就是直接从旧的、历史应用环境中得到的。图2展示了数据直接从历史环境中装入多维DBMS中的情形。由于它很直接,并且很容易实现,所以这种方法很吸引人。一个程序员能立刻开始工作来建造它。

图2 从没有当前细节数据的应用建立多维DBMS数据集市
不幸的是,图2所示的体系结构中有一些并不是那么明显的主要缺陷。由于各种各样的原因,将数据仓库中的当前细节级的数据装入多维DBMS环境提供数据比将历史应用的操作型环境中的数据装入其中更具意义。
图3展示了将数据仓库的当前细节级的数据装入多维DBMS环境中。在导入数据仓库的过程中,对旧的、历史的操作型数据进行了集成和转换。
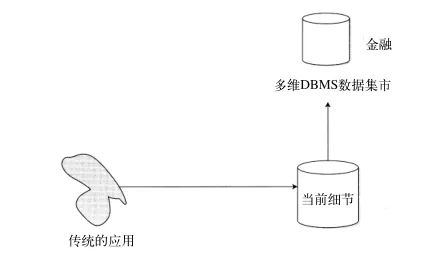
图3 从应用环境流入当前细节级再到多维DBMS数据集市的数据流
一旦到了数据仓库以后,被集成的数据就以当前细节数据的级别存储。多维DBMS就是要载入数据仓库中这一级别的数据。
初看起来,图2和图3所示的两种结构之间似乎并没有本质上的区别。事实上,将数据首先装入到数据仓库中似乎是浪费精力。但是,有一个非常好的理由说明为什么创建多维DBMS的第一步是将数据集成到数据仓库中。
考虑一下在通常情况下,一个公司需要建立多个多维DBMS。金融部门需要自己的多维DBMS,财务部门也需要。市场部、销售部和其他部门也都需要自己的多维DBMS。因为在公司里会有众多的多维DBMS,所以图2所示的情形会变得非常复杂。在图4中,将图2扩展成了一个实际的情形。众多的多维DBMS直接而独立地从历史系统环境中获得数据。
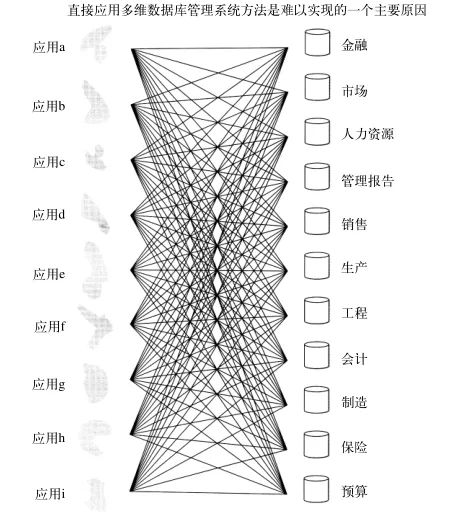
图4 有许多的应用和许多的数据集市,每对之间都需要一个接口。回避细节数据的当前级的后果是产生一个无法管理的“蜘蛛网”
图4表明,众多的多维DBMS直接从相同的历史应用中获得数据。那么,这种结构有什么问题呢?问题如下:
- 抽取数据所需进行的开发量是巨大的。每一个不同的部门多维DBMS都需要定制开发一套适合自己的抽取程序。抽取处理过程有大量的重叠。这样,浪费的开发工作量很大。当多维DBMS是从数据仓库中抽取数据时,它只需要一套集成和转换的程序。
- 当多维DBMS是从历史系统环境中直接抽取数据时,并没有数据的集成基础。每个部门的多维DBMS对于怎样从不同的应用中集成数据都有自己的解释。不幸的是,通常一个部门集成数据的方法和其他部门对相同数据的集成方法是不同的。结果导致最终没有单一集成的、确定的数据源。相反地,在建造数据仓库时,有一个能够作为构造基础的单一的、集成的、确定的数据源。
- 维护所进行的开发工作量是巨大的。在旧的传统应用中,仅仅一个改变就会影响许多抽取程序。有抽取程序的地方由于这个改变而做一些改动,而且这种改动会很多。当有了数据仓库后,由于只需要写很少的程序来处理历史环境和数据仓库的接口,所以应用中的改变所产生的影响也是最小的。
- 需要消耗的硬件资源的数量是很大的。对于每一个部门的每一个抽取处理,同样的历史数据都要顺序地重复传送。而在数据仓库中,历史数据只需要传送一次来刷新数据仓库中的数据。
- 从历史环境中将数据直接导入多维DBMS环境中的复杂性无法对元数据进行有效的管理和控制。在数据仓库中,捕获和管理元数据可以直接进行。
- 缺乏数据的一致性。当不同的部门之间存在意见分歧时,各自都有自己的多维DBMS,很难解决。但用数据仓库后,冲突的解决是很自然并且很容易的。
- 每次必须构建一个新的多维DBMS环境,而且必须根据历史环境建立,所需要的工作量是相当可观的。然而,如果数据基础是在一个数据仓库中,建造一个新的多维DBMS环境将快速而容易。
如果一个企业考虑的是一种短期的方法,那么数据仓库代价的合理性分析将很难进行。如果从长期来看,构建许多多维数据库环境所需的费用是非常高的。而当一个企业从长期的观点出发建立一个数据仓库时,则数据仓库和数据集市所需的长期总费用将会显著降低。
作者简介:William H.Inmon,世界公认的“数据仓库之父”,企业信息工厂创造者之一。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK