

微信小程序,Python爬虫抓包采集实战,采集某成考题库小程序
source link: https://blog.51cto.com/cnca/5606953
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Table of Contents
⛳️ 实战场景
从本篇博客开始,我们会针对微信小程序编写一系列的爬虫,这些爬虫依旧通过案例进行串联,保证对大家的学习有所帮助。
正式开始前先准备工具,一个可以解析 https 协议请求的软件 fiddler,电脑版微信。
由于在 2022 年 5 月份,微信调整了其小程序架构,所以在正式开始前需要对环境进行一下基础配置,便于抓取到网络包。
如果你的 fiddler 启动之后,可以成功抓取数据包,无需该步操作。
找到下述路径的文件夹,然后清空该文件夹,接下来重新启动微信,此时就可以获取小程序中的 https 请求了,效果图如下所示。
C:\Users\Administrator\AppData\Roaming\Tencent\WeChat\XPlugin\Plugins\WMPFRuntime
由于 Python 有侵权问题,所以关键站点信息进行打码处理。

抓取请求之后,首先对请求地址进行分析,本次采集的目标站点呈现如下规则(实践初期可以多获取一下不同地址):
weixin.不能展示的作品地址.com/app/index.php?i=1063&t=0&v=1.0.0&from=wxapp&c=entry&a=wxapp&do=gettopic&m=huitong_shuati&sign=指纹地址&topic_class_id=30702&ordinal=1
weixin.不能展示的作品地址.com/app/index.php?i=1063&t=0&v=1.0.0&from=wxapp&c=entry&a=wxapp&do=gettopic&m=huitong_shuati&sign=指纹地址&topic_class_id=30702&ordinal=2
在对参数进行猜测的时候,我发现了 sign 加密参数,此时就比较麻烦了,因为我们没有办法进行调试,如果该参数需要解析,那还面临小程序解包这一问题,不过后续的实际分析,让我松了一口气,该参数并未参加运算。
其核心参数如下所示:
c:控制器;a:动作,也可以叫做函数m:猜测是 modeltopic_class_id:试卷 ID;ordinal:题目序号。
如果仅有这些参数,此时可以在一空白谷歌浏览器中进行迭代,即判断是否可以直接通过题号切换,获取所有试题。
随着不断增大题号,结果当试题不存在时,得到下述响应信息。
{"errno":0,"message":"\u9898\u7684\u6570\u636e\u83b7\u53d6\u5931\u8d25","data":{"status":0}}
将 unicode 转码之后,得到题目不存在的提示,此时表示该试卷所有试题已经解析完毕。
题目获取成功,得到题干,选项,解析,包括试卷题目总数等信息,有这些数据之后,就可以进入编码实战环节。

以下代码主要通过 Python requests 模块实现。
⛳️ 实战编码
在实战中可以先将数据存储到 MySQL 中(直接存储 JSON 文件也可以),然后在进行后续的读取操作。
下面在梳理一下需求实现步骤:
1. 获取分类页面试题类型
该页面获取地址如下所示:
weixin.不能展示的作品地址.com/app/index.php?i=1063&t=0&v=1.0.0&from=wxapp&c=entry&a=wxapp&do=fenlei_data&state=指纹地址&m=huitong_shuati&sign=指纹地址&up_class_id=3464&openid=om76m4sMOiBzooHFFKbqcZJFysq0
2. 获取试卷科目数据
获取地址如下所示:
weixin.不能展示的作品地址.com/app/index.php?i=1063&t=0&v=1.0.0&from=wxapp&c=entry&a=wxapp&do=fenlei_data&state=指纹地址&m=huitong_shuati&sign=指纹地址&up_class_id=24321&openid=om76m4sMOiBzooHFFKbqcZJFysq0
3. 获取试卷分组数据
https://weixin.不能展示的作品地址.com/app/index.php?i=1063&t=0&v=1.0.0&from=wxapp&c=entry&a=wxapp&do=fenlei_data&state=指纹地址&m=huitong_shuati&sign=指纹地址&up_class_id=24377&openid=om76m4sMOiBzooHFFKbqcZJFysq0
4.获取分组下的试卷
https://weixin.不能展示的作品地址.com/app/index.php?i=1063&t=0&v=1.0.0&from=wxapp&c=entry&a=wxapp&do=fenlei_data&state=指纹地址&m=huitong_shuati&sign=指纹地址&up_class_id=30658&openid=om76m4sMOiBzooHFFKbqcZJFysq0
5.获取试题
https://weixin.不能展示的作品地址.com/app/index.php?i=1063&t=0&v=1.0.0&from=wxapp&c=entry&a=wxapp&do=gettopic&state=指纹地址&m=huitong_shuati&sign=指纹地址&topic_class_id=30659&ordinal=1
获取到这五个地址之后,还需要进一步的进行整理分析,看中间是否存在步骤跳过的可能。
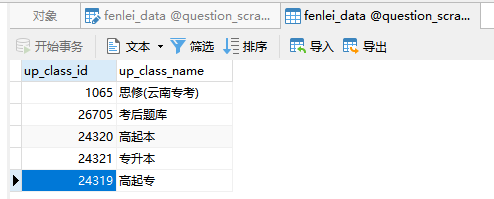
经过筛选,得到下图内容,其中 up_class_id 作为核心参数脱颖而出。

所以后续的内容就围绕 up_class_id 进行编写即可,二级分类数据获取代码如下:
import requests
import pymysql
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
}
def get_conn():
conn = pymysql.connect(
host='127.0.0.1',
user='你的账号',
db='question_scrapy',
port=3306,
cursorclass=pymysql.cursors.DictCursor
)
return conn
def run():
res = requests.get(
'https://weixin.不能展示的作品地址.com/app/index.php?i=1063&from=wxapp&c=entry&a=wxapp&do=fenlei_data&m=huitong_shuati&up_class_id=3464',
headers=headers, timeout=5, verify=False)
json_data = res.json()
if json_data["errno"] == 0:
fenlei_data = json_data["data"]['0']["fenlei_data"]
insert_fenlei(fenlei_data)
def insert_fenlei(fenlei_data):
conn = get_conn()
cursor = conn.cursor()
for item in fenlei_data:
up_class_id = item["id"]
topic_class_name = item["topic_class_name"]
cursor.execute(
f'insert into fenlei_data values({up_class_id},"{topic_class_name}")')
try:
conn.commit()
except Exception as e:
conn.rollback()
cursor.close()
conn.close()
if __name__ == '__main__':
run()
输入插入结果如下所示:
四层页面全部采集完毕,得到的数据如下所示:
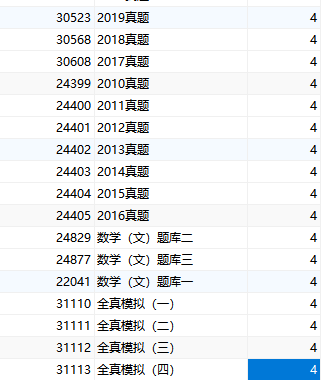
拿到本列表之后,就可以批量采集试题了,直接通过最后一个链接地址获取。
def get_question(topic_class_id, ordinal=1):
url = f'https://weixin.不能展示的作品地址.com/app/index.php?i=1063&from=wxapp&c=entry&a=wxapp&do=gettopic&m=huitong_shuati&topic_class_id={topic_class_id}&ordinal={ordinal}'
res = requests.get(url, headers=headers)
data = res.json()["data"]
if data["status"] == 1:
questions_count = data["count"]
for num in range(1,int(questions_count)+1):
url = f'https://weixin.不能展示的作品地址.com/app/index.php?i=1063&from=wxapp&c=entry&a=wxapp&do=gettopic&m=huitong_shuati&topic_class_id={topic_class_id}&ordinal={num}'
res = requests.get(url, headers=headers)
print(res.json()["data"]["topic_data"][0])
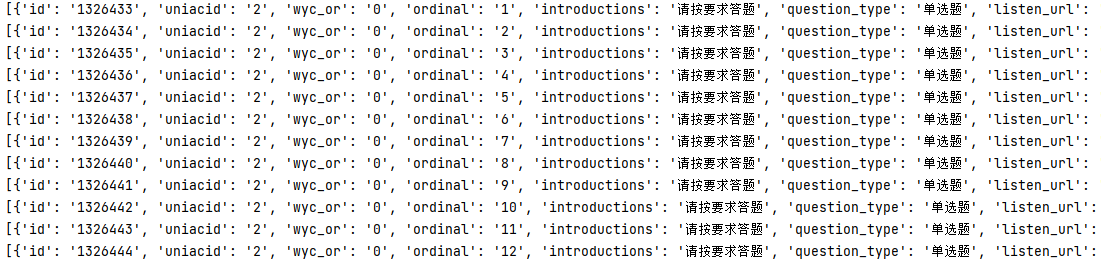
此时再次运行代码,就可以将试题全部采集到本地数据库中了,为了后续操作便捷,试题全部采用 JSON 字符串格式入库。
📢📢📢📢📢📢
💗 你正在阅读 【梦想橡皮擦】 的博客
👍 阅读完毕,可以点点小手赞一下
🌻 发现错误,直接评论区中指正吧
📆 橡皮擦的第 <font color=red>710</font> 篇原创博客
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK