

Redis 哈希Hash底层数据结构 - 废物大师兄
source link: https://www.cnblogs.com/cjsblog/p/16526256.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Redis 哈希Hash底层数据结构
1. Redis 底层数据结构
Redis数据库就像是一个哈希表,首先对key进行哈希运算得到哈希值再取模得到一个下标,每个元素是一个节点,节点之间形成链表。这感觉有点像Java中的HashMap。
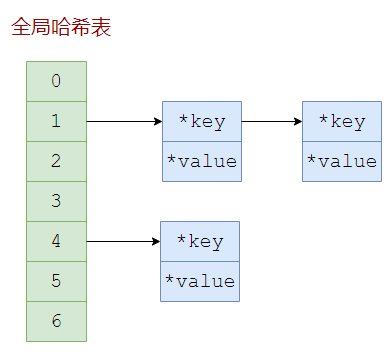
不同的数据类型的实现方式是不一样的,可以通过object encoding命令查看底层真正的数据存储结构

同一种类型在不同的条件下所采用的数据结构也不一样,例如:
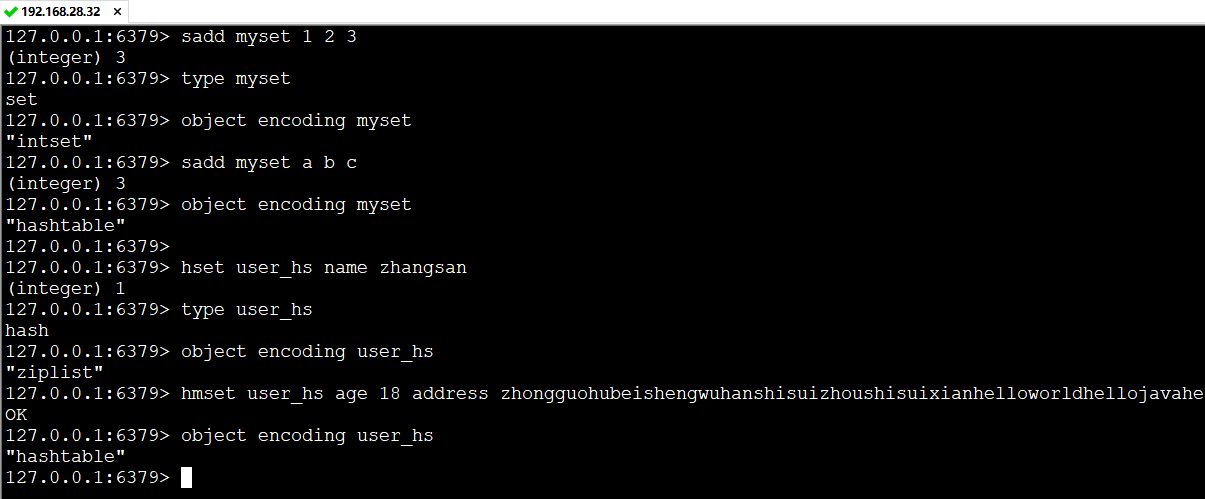
Redis是键值对形式的数据库,key可以是任意值(PS:最终都会转成string),value有多种数据类型
详见:https://redis.io/docs/manual/data-types/data-types-tutorial/
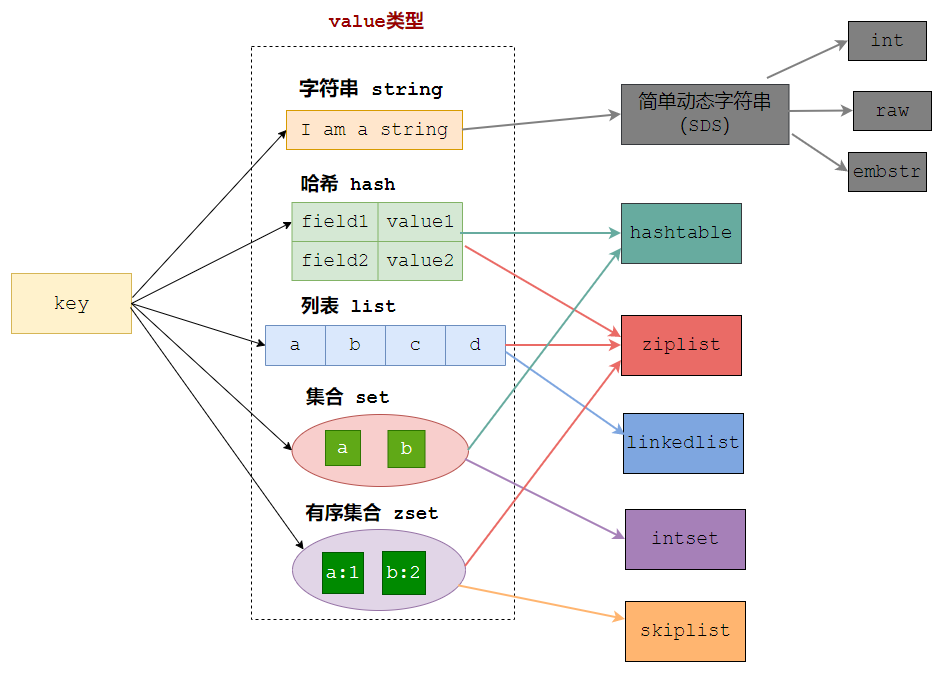
至此,已经很清楚,hash底层的结构是 ziplist 和 hashtable
那么,什么时候会从ziplist转成hashtable呢?这个在redis.conf中有相关的配置,如下:

默认情况下:
- 当ziplist中entry的数量超过512的时候,会转成hashtable
- 单个元素的值超过64字节的时候,会转成hashtable
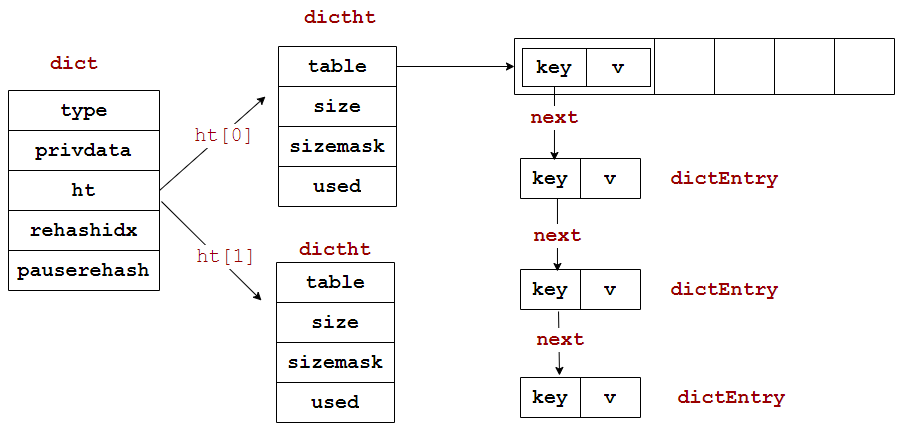
2. hashtable
在Redis中hashtable就是字典dict
通过源码,可以看到dict是这样定义的:

3. redisDb 与 redisObject
通过源码得知,redisDb代表redis数据库,redisObject代表存到数据库中的数据
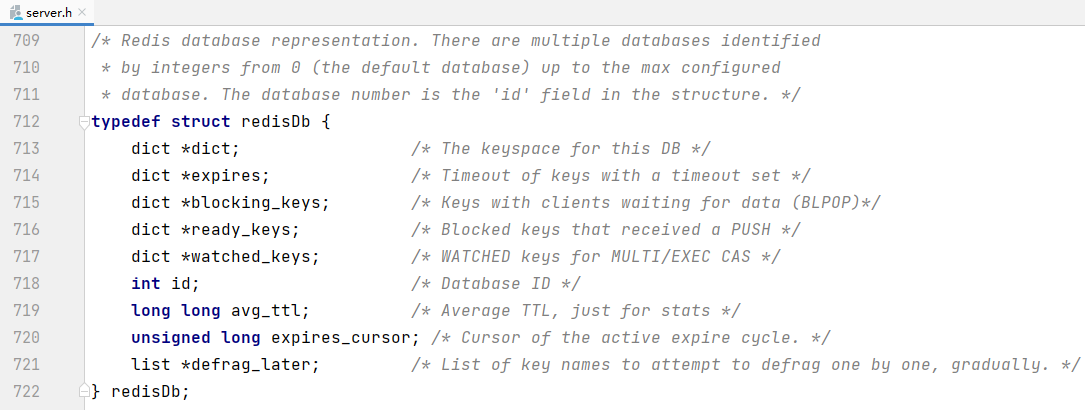
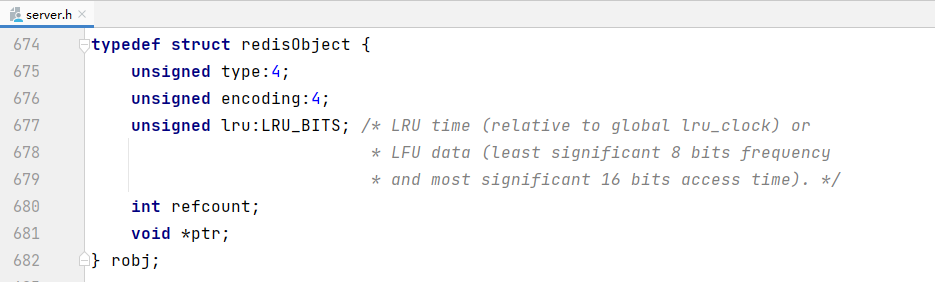
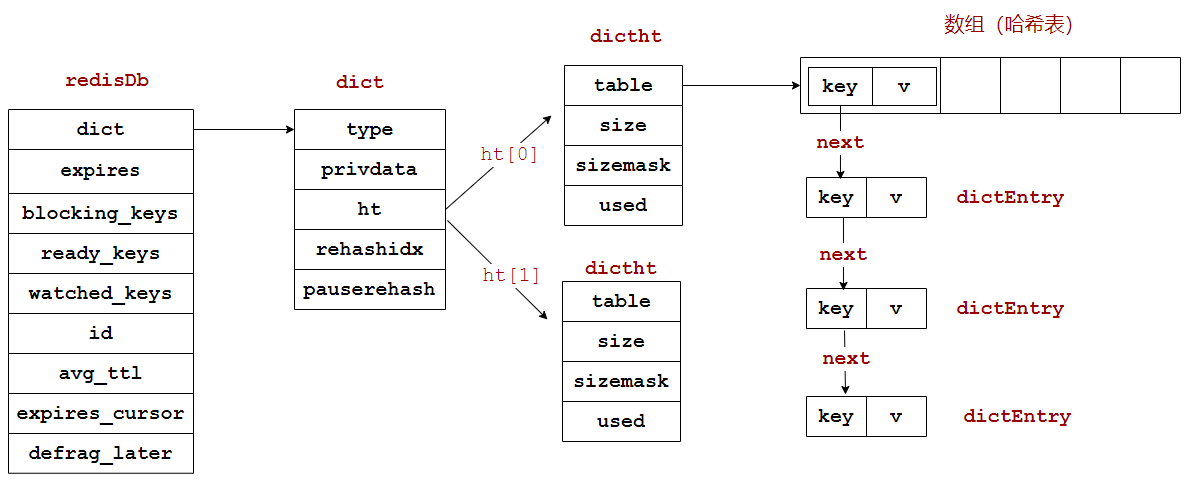
字典dict的结构前面已经看过了,于是整个数据库的结构大概就是下面这个样子:
4. ziplist
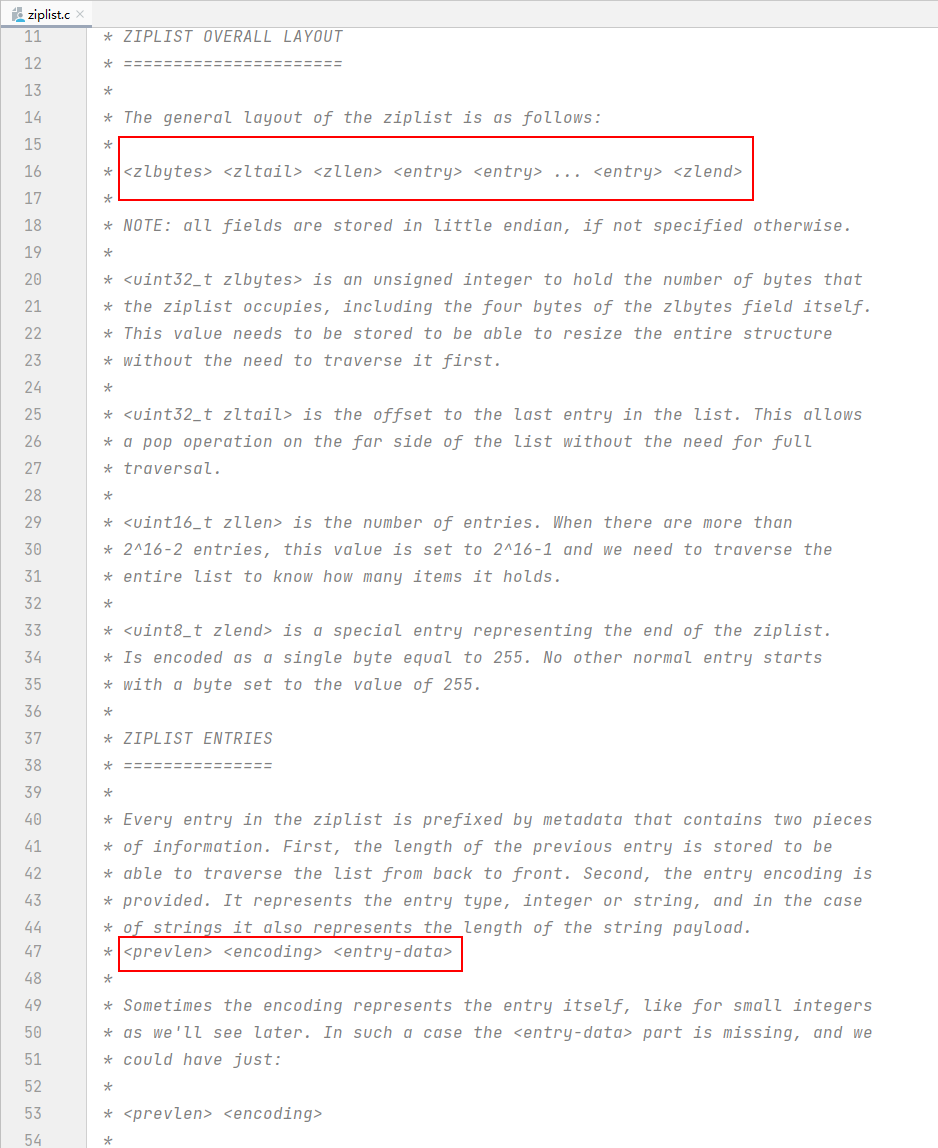
ziplist是一种特殊编码的双链表,被设计成非常节省内存。它存储字符串和整型值,其中整数被编码为实际整数,而不是一系列字符。它允许在O(1)时间内在列表的任意一边进行push和pop操作。但是,由于每个操作都需要重新分配ziplist所使用的内存,因此实际的复杂性与ziplist所使用的内存量有关。
ziplist的大体布局如下:
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
<uint32_t zlbytes>: 一个无符号整数,用于保存ziplist占用的字节数,包括zlbytes字段本身的四个字节。需要存储这个值,以便能够调整整个结构的大小,而不需要首先遍历它。
<uint32_t zltail> : 列表中最后一个条目的偏移量。
<uint16_t zllen> : 条目的数量。当有超过2^16-2个条目时,这个值被设置为2^16-1,我们需要遍历整个列表来知道它包含多少项。
<uint8_t zlend> : 一个特殊的条目,表示 ziplist 的结尾

5. linkedlist

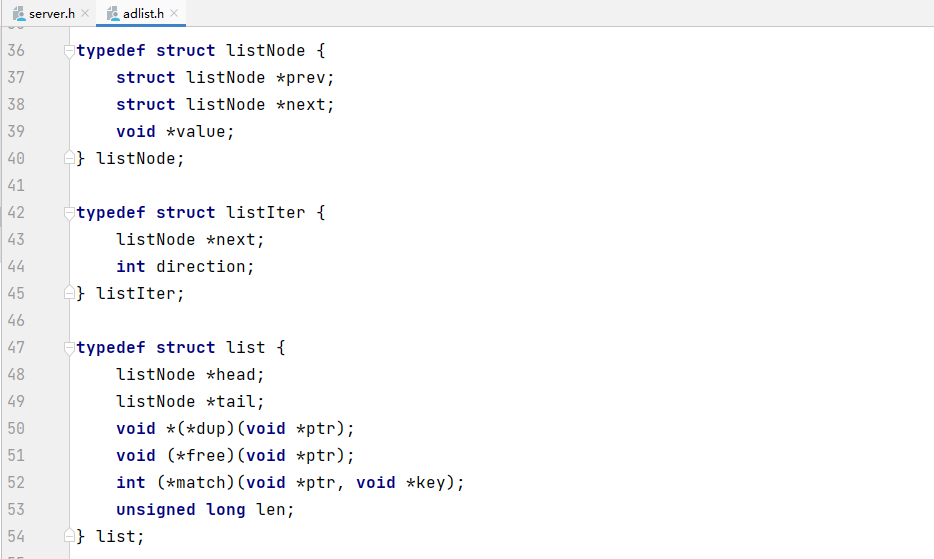
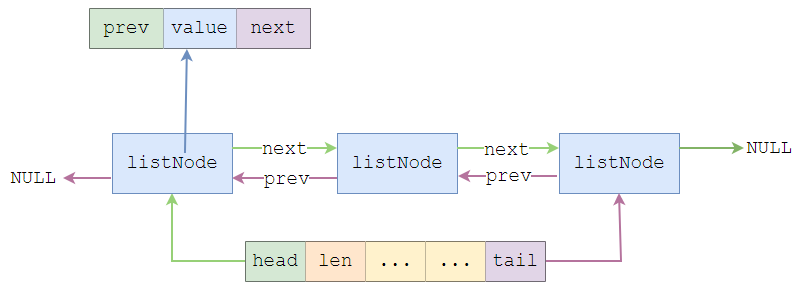
linkedlist是一个双向链表
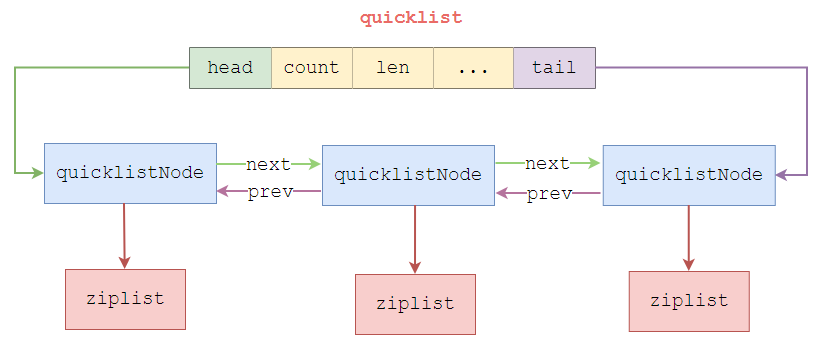
6. quicklist

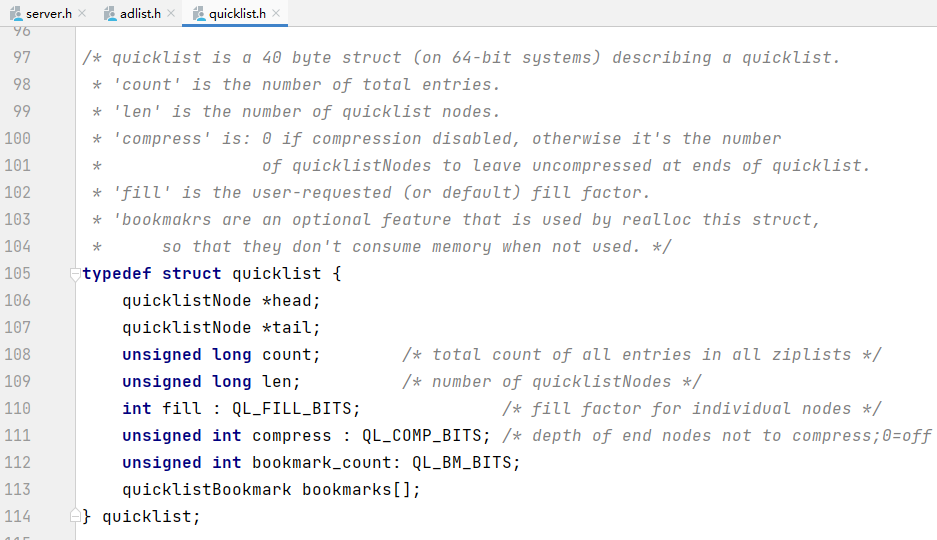
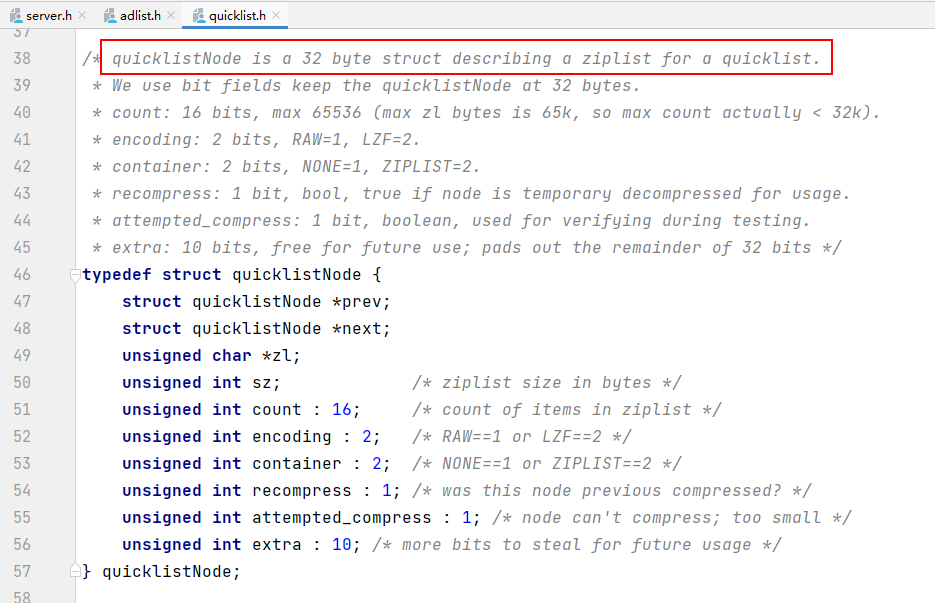
quicklistNode是一个32字节的结构体,描述快表的ziplist。
quicklist = linkedlist + ziplist
http://redisbook.com/index.html
http://blog.itpub.net/70000430/viewspace-2787985/
https://www.cnblogs.com/reecelin/p/13358432.html
https://juejin.cn/post/6844904008591605767
欢迎各位转载,但必须在文章页面中给出作者和原文链接!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK