

EfficientFormer:轻量化ViT Backbone - ZOMI酱酱
source link: https://www.cnblogs.com/ZOMI/p/16506319.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

EfficientFormer:轻量化ViT Backbone
论文:《EfficientFormer: Vision Transformers at MobileNet Speed 》
Vision Transformers (ViT) 在计算机视觉任务中取得了快速进展,开启了 Vision + Transformer 的先河,之后大量的论文和研究都基于 ViT 之上的。不过呢,Transformer 由于 Attention 的结构设计需要大量的参数,执行的性能也比经过特殊优化的 CNN 要慢一点。
像是之前介绍的 DeiT 利用 ViT + 蒸馏让训练得更快更方便,但是没有解决 ViT 在端侧实时运行的问题。于是后来有了各种 MateFormer、PoolFormer 等各种 XXXFormer 的变种。应该在不久之前呢,Facebook 就提出了 mobilevit,借鉴了端侧 YYDS 永远的神 mobileNet 的优势结构和 Block(CNN) + ViT 结合,让 ViT 开启了端侧可运行的先河。不管是 XXXFormer 还是 mobileNet,主要是试图通过网络架构搜索(AutoML)或与 MobileNet 块的混合设计来降低 ViT 的计算复杂度,但推理速度嘛,还是没办法跟 mobileNet 媲美。
这就引出了一个重要的问题:Transformer 能否在获得高性能的同时跑的跟 MobileNet 一样快?
作者重新审视基于 ViT 的模型中使用的网络架构和具体的算子,找到端侧低效的原因。然后引入了维度一致的 Transformer Block 作为设计范式。最后,通过网络模型搜索获得不同系列的模型 —— EfficientFormer。
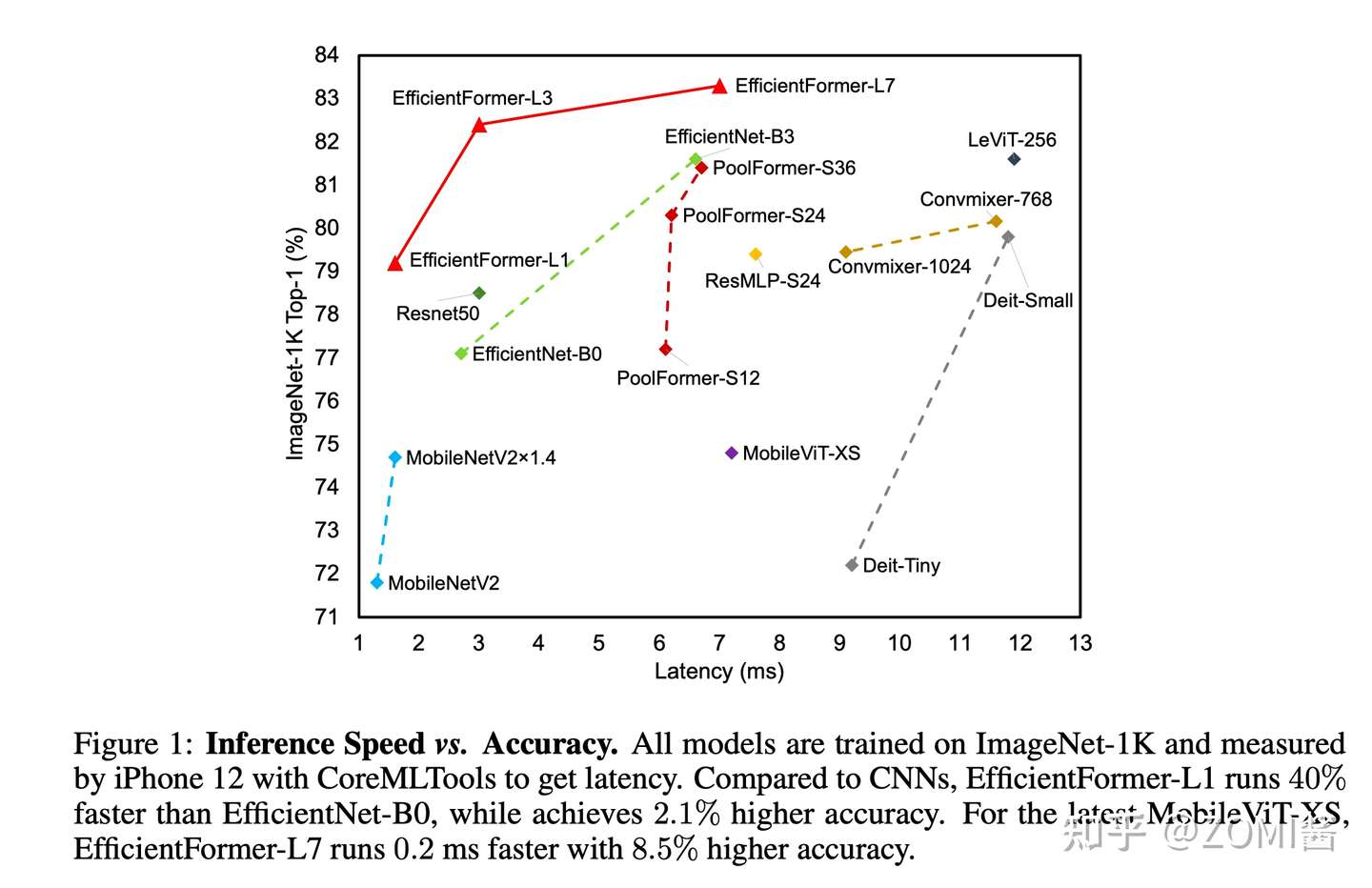
ViT 实时运行分析
图中作者作者对不同模型在端侧运行进行了一些分析,主要是分为 ViT 对图像进行分块的 Patch Embedding、Transformer 中的 Attention 和 MLP,另外还有 LeViT 提出的 Reshape 和一些激活等。基于下面这个表,提出了几个猜想,然后设计出了 EfficientFormer 结构。

- 猜想分析1:大 kernel 和 stride 的Patch embedding是速度瓶颈
Patch embedding 通常使用具有较大kernel-size和stride的非重叠卷积层来实现。大部分AI编译器都不能很好地支持大内核卷积,并且无法通过 Winograd 等现有算法进行加速。
- 猜想分析2:特征维度一致对于 token mixer 的选择很重要
很多翻译这里写得很玄乎,ZOMI酱的理解是特征维度一致比多头注意力机制对延迟的影响更重要啦,也就是 MLP 实际上并没有那么耗时,但是如果 tensor 的shape一会大一会小,就会影响计算时延。所以 EfficientFormer 提出了具有 4D 特征实现和 3D 多头注意力的维度一致网络,并且消除了低效且频繁 Reshape 操作(主要指 LeViT 中的 Reshape 操作)。
- 猜想分析3:CONV + BN 比 MLP + LN 效率更高
在 CNN 结构中最经典的就是使用3x3卷积 Conv + Batch Normalization(BN)的组合方式(获取局部特征),而在 Transformer 中最典型的方式是使用 linear projection(MLP)+ layer normalization(LN)(获取全局特征)的组合。不过作者对比测试中发现呀,CONV + BN 比 MLP + LN 效率更高。
- 猜想分析4:激活函数取决于编译器
最后这个就比较简单,激活函数包括 GeLU、ReLU 和 HardSwish 的性能在 TensorRT 或者 CoreML 中都不一样,所以激活的优化主要是看用什么端侧编译器。
EfficientFormer 架构
第4个点不太重要,主要是关注1,2,3点。于是引出了 EfficientFormer 的总结架构啦。 EfficientFormer 由 patch embedding (PatchEmbed) 和 meta transformer blocks 组成,表示为 MB:
X_0 是输入图像,Batch Size 为 B,featur map 大小为 [H,W],Y 是输出,m 是Block的数量。MB 由未指定的 TokenMixer 和 MLP Block 组成,可以表示如下:
X_i 是第 i 个 MB 的featur map。进一步将 Stage 定义为处理具有相同空间大小的特征的几个 MetaBlock 的堆栈,图 N_1x 表示 S1 具有 N_1 个 MetaBlock。
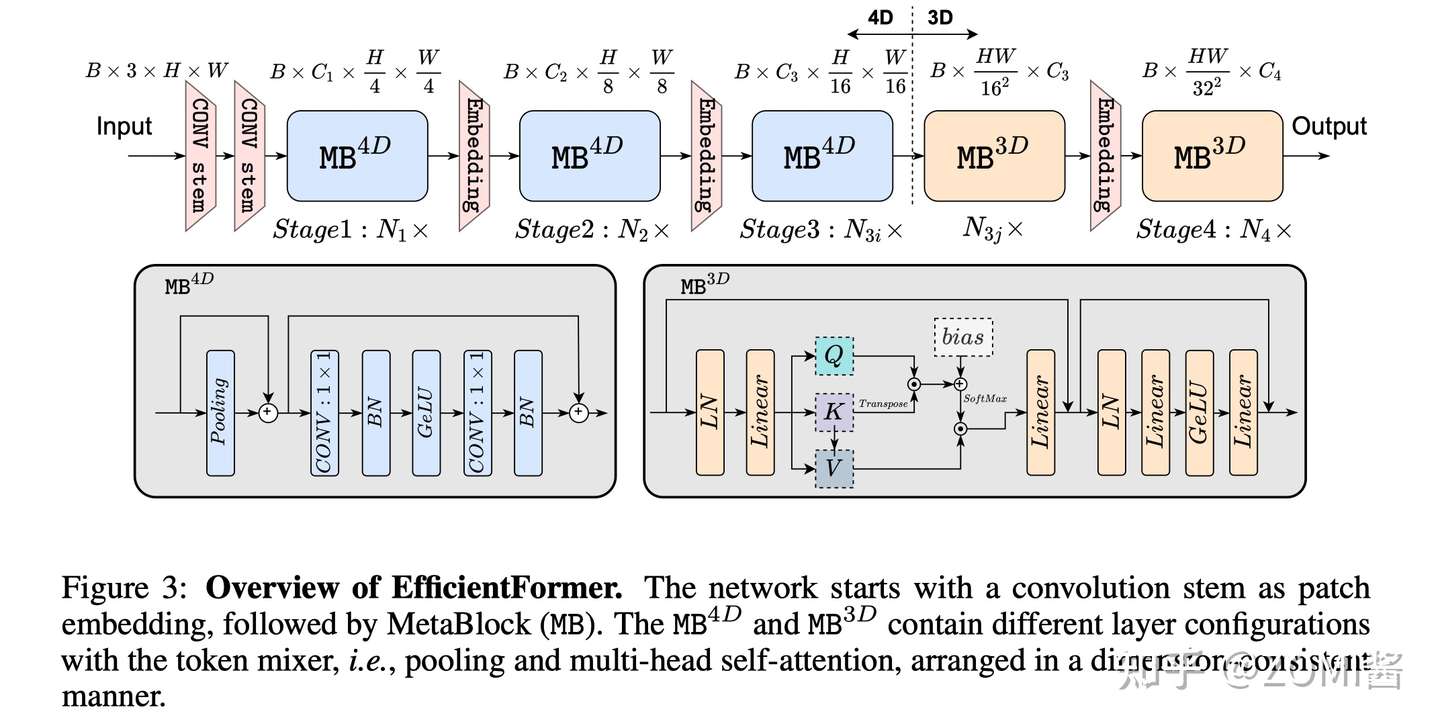
可以看到 EfficientFormer 一共有4个阶段。每个阶段都有一个 Embeding(两个3x3的Conv组成一个Embeding) 来投影 Token 长度(可以理解为CNN中的feature map)。可以看到啦,EfficientFormer 是一个完全基于Transformer设计的模型,没有集成 MobileNet 相关内容啦。
最后通过 AUTOML 来搜索 MB_3D 和 MB_4D block 相关参数。
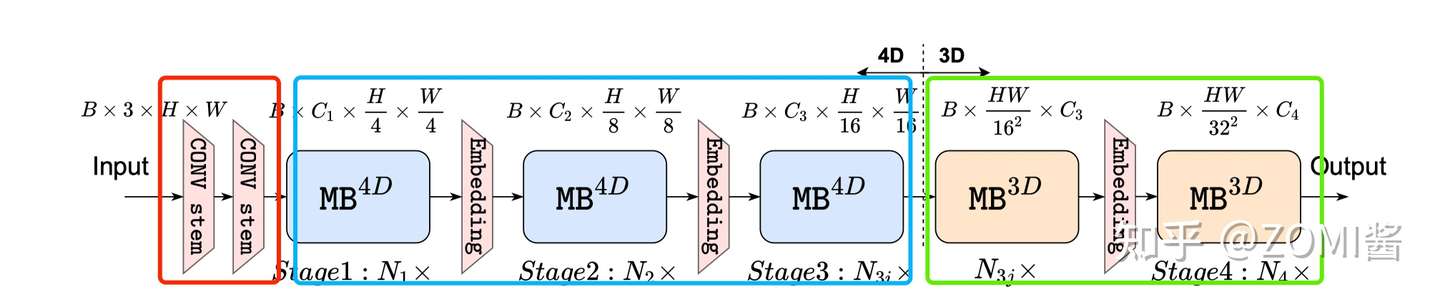
维度一致性 dimension-consistent
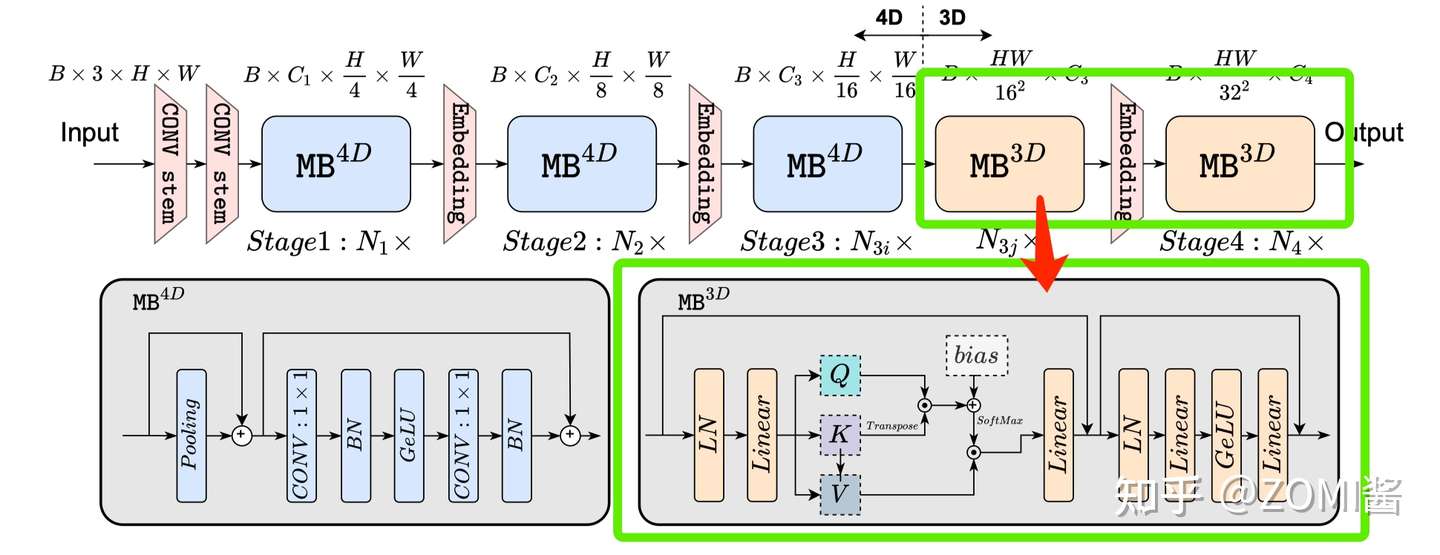
根据 猜想分析2:特征维度一致对于 token mixer 的选择很重要 EfficientFormer 提出了一种维度一致的设计,将网络分成一个 MB_4D,以 CNN 结构为主 (MB4D) 实现;以及一个 MB_3D ,MLP 线性投影和 Attention 注意力在 3D tensor 上运行。网络从 patch embedding 开始,然后就到了 4D 分区,3D 分区在最后阶段应用。最后 4D 和 3D 分区的实际长度是稍后通过架构搜索指定的。
这里面的 4D 主要是指 CNN 结构中 tensor 的维度 [B, C, W, H],而 3D 主要是指 Tran 结构中 tensor 的维度 [B, W, H]。
网络从使用由具有2个 kernel-size为 3×3, Stride=2 的卷积组成的 Conv stem 处理后的图像作为 patch embedding:
其中 C_j 是第 j 个阶段的通道数(宽度)。然后网络从 MB_4D 开始,使用简单的 Pool ing 来提取 low level特征:
其中 Conv_B,G 是指卷积后是否分加上BN和GeLU。
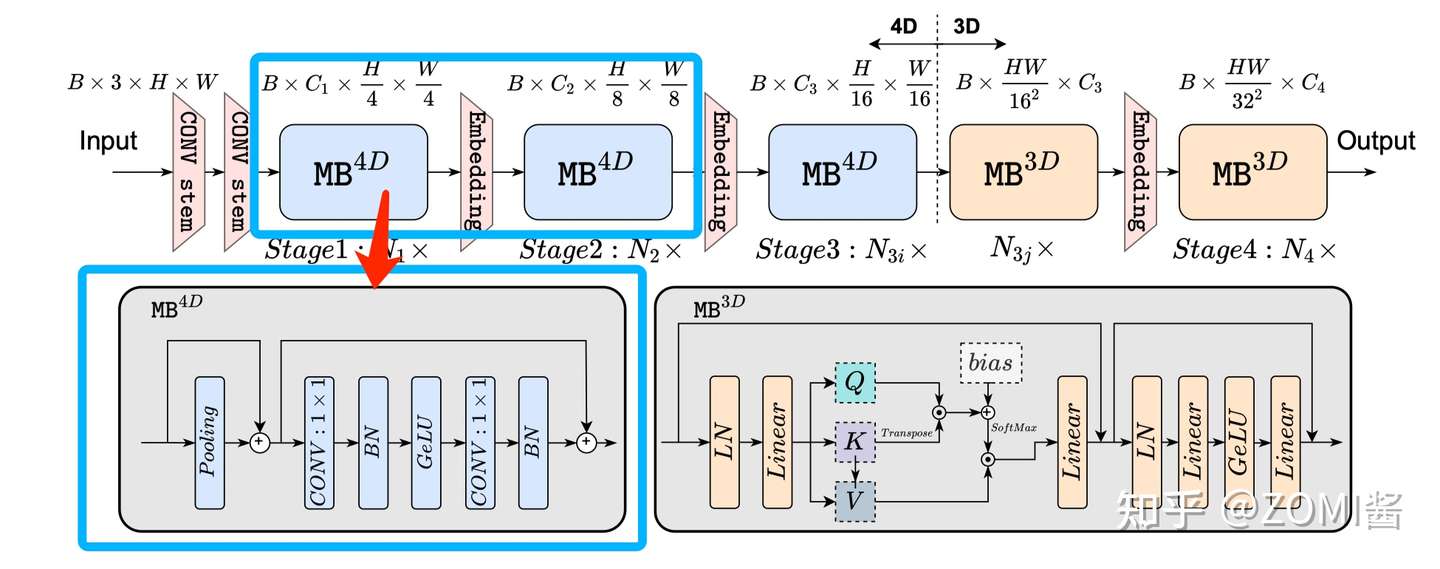
在处理完所有 MB4D 块后,执行一次Reshape以变换 freature map 并进入 3D 分区。MB3D 遵循传统的 ViT,不过作者把 ReLU 换成了 GeLU 哦。
实时运行模型瘦身 Latency Driven Slimming
基于 dimension-consistent,EfficientFormer 构建了一个 Supernet,用于搜索 EfficientFormer 架构的高效模型。下面定义一个 MetaPath (MP):
I 呢表示 identity path,j 表示第 j 个阶段,i 表示第 i 个块。搜索网络Supernet 中通过用 MP 代替 EfficientFormer 的 MB。
在 Supernet 的第1阶段和第2阶段中,每个 Block 可以选择 MB4D 或 I,而在第3阶段和第4阶段中,Block可以是 MB3D、MB4D 或 I。
EfficientFormer 只在最后两个阶段启用 MB3D,原因有2个:1)多头注意力的计算相对于Token长度呈二次增长,因此在模型早期集成会大大增加计算成本。2)将全局多头注意力应用于最后阶段符合直觉,即网络的早期阶段捕获低级特征,而后期层则学习长期依赖关系。
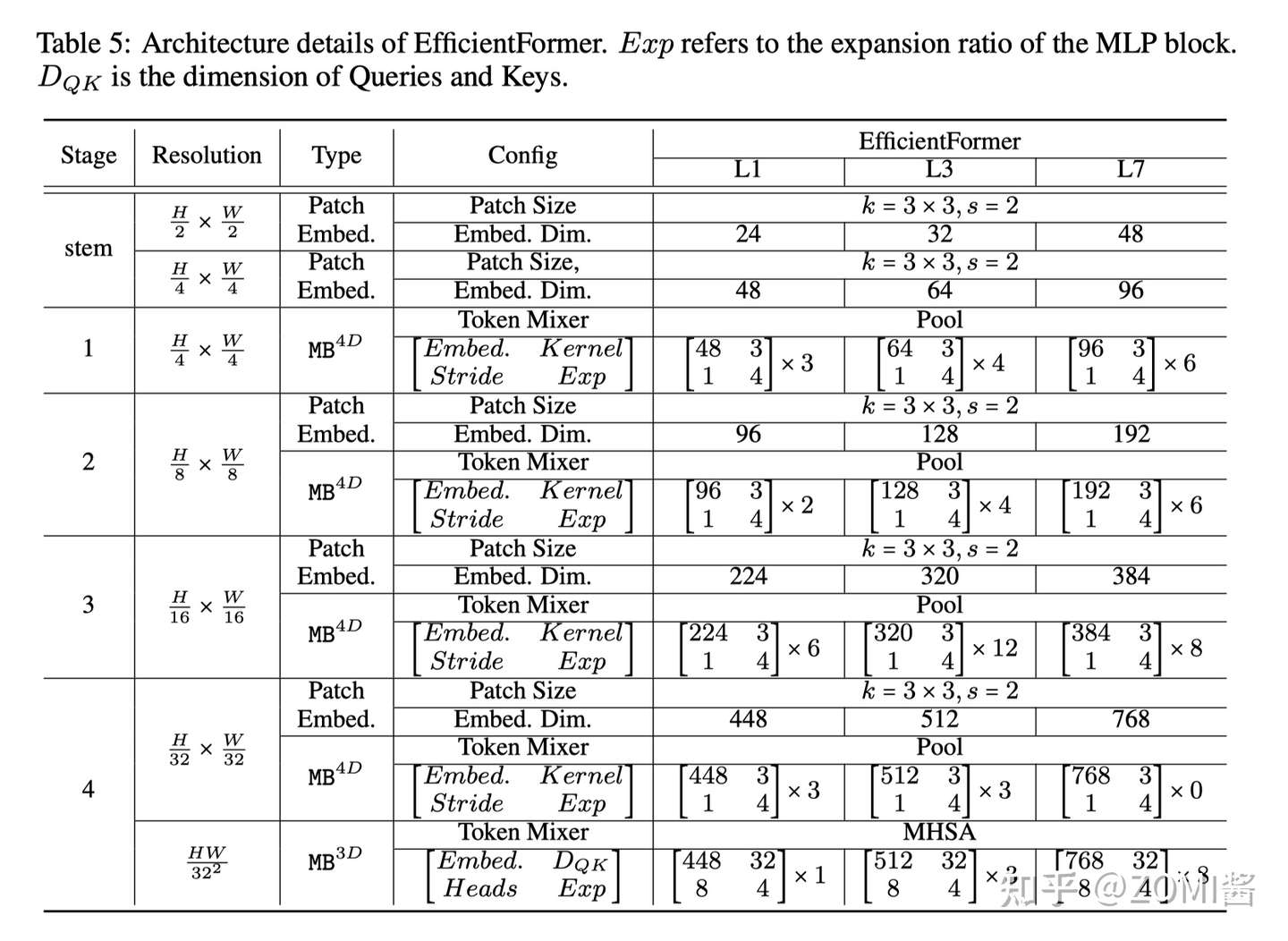
搜索空间包括 C_j(每个 Stage 的宽度)、N_j(每个 Stage 中的块数,即深度)和最后 N 个 MB3D 的块。
传统的硬件感知网络搜索方法,通常依赖于每个候选模型在搜索空间中的硬件部署来获得延迟,这是非常耗时的。EfficientFormer提出了基于梯度的搜索算法,以获得只需要训练一次Supernet的候选网络。
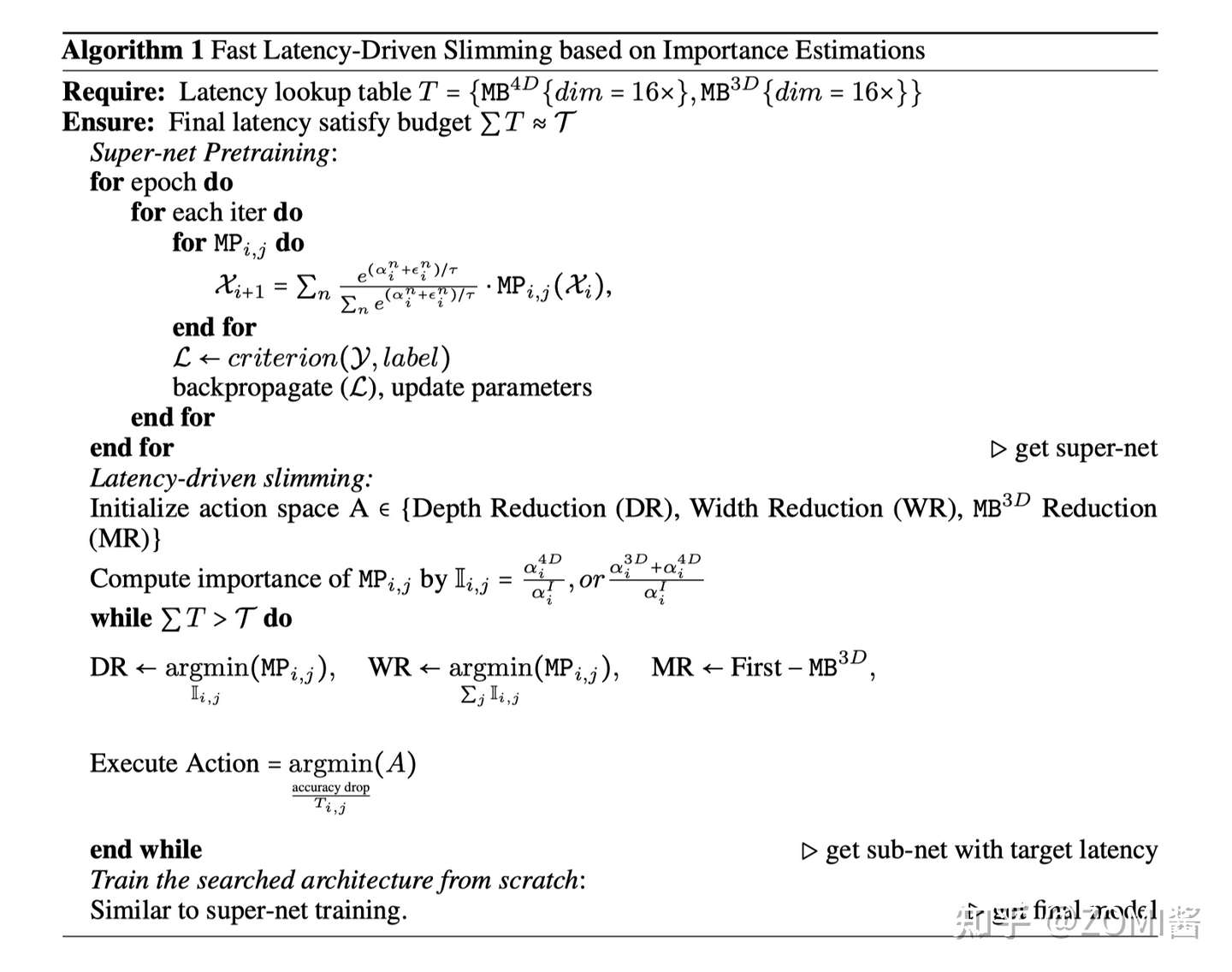
(后续可以针对 NASA 搜索进行详细补充这个内容。)
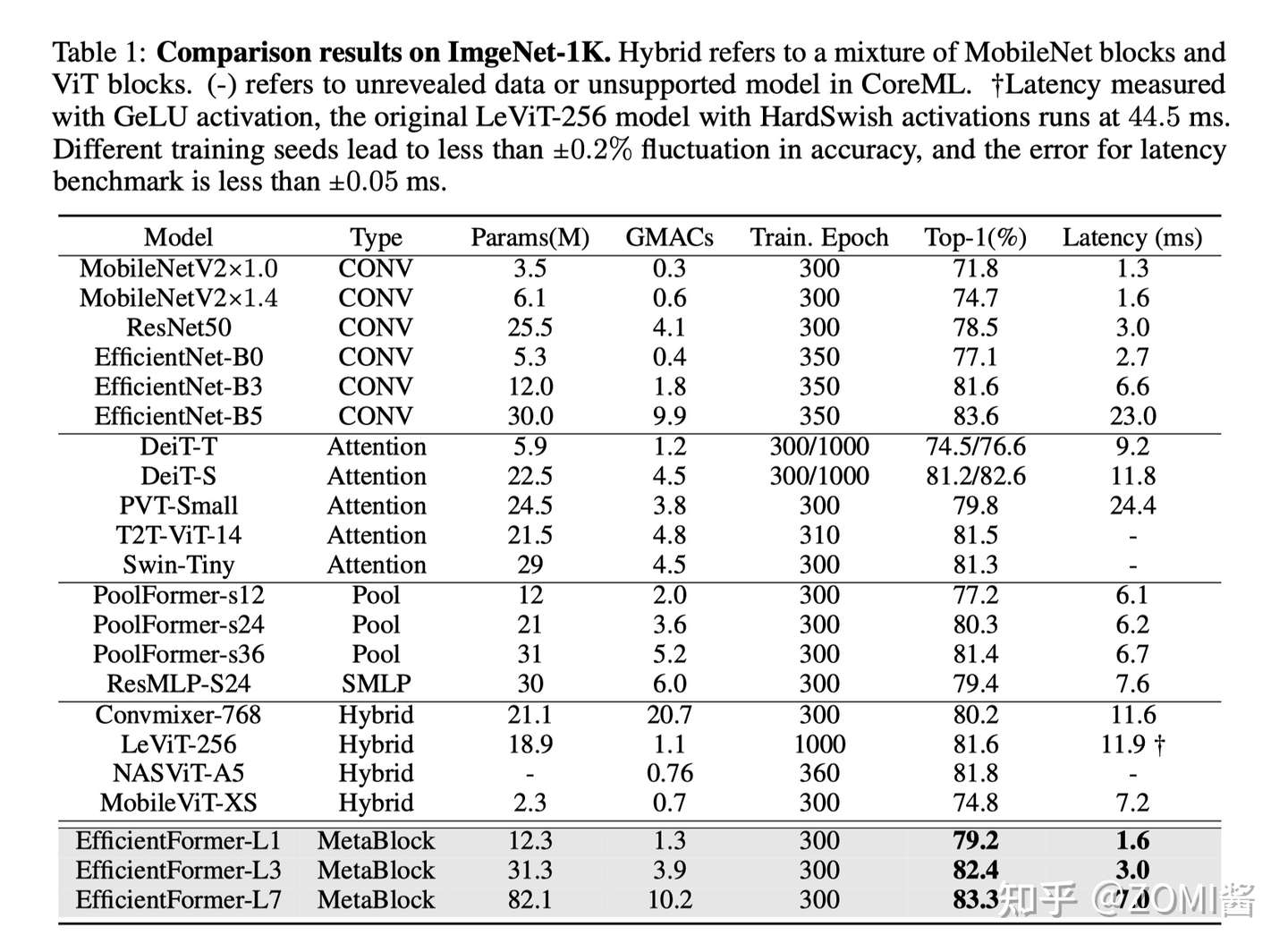
总的来说呢,EfficientFormer-L1 在 ImageNet-1K 分类任务上实现了 79.2% 的 top-1 准确率,推理时间仅为 1.6 ms,与 MobileNetV2 相比,延迟降低了 6%,top-1 准确率提高了 7.4%。延迟不是 ViT 在端侧部署的障碍。
另外,EfficientFormer-L7 实现了 83.3% 的准确率,延迟仅为 7.0 ms,大大优于 ViT×MobileNet 混合设计(MobileViT-XS,74.8%,7.2ms)。

最后通过使用 EfficientFormer 作为图像检测和分割基准的 Backbone,性能也是非常赞的。ViTs 确实可以实现超快的推理速度和强大的性能。
MobileViT 结构上基本基于 MobileNet V2 而改进增加了 MobileViT block,但是同样能够实现一个不错的精度表现,文章实验部分大量的对比了 MobileViT 跟 CNN 和 ViT 模型的参数量和模型大小,不过值得一提的是在端侧除了模型大小以外,更加重视模型的性能,只能说这篇文章经典之处是开创了 CNN 融合 ViT 在端侧的研究。
[1] Li, Yanyu, et al. "EfficientFormer: Vision Transformers at MobileNet Speed." arXiv preprint arXiv:2206.01191 (2022).
[2] EfficientFormer | 苹果手机实时推理的Transformer模型,登顶轻量化Backbone之巅
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK