

基于全局场景背景图和关系优化的全景3D场景理解(ICCV 2021)
source link: https://zhuanlan.zhihu.com/p/469651790
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

基于全局场景背景图和关系优化的全景3D场景理解(ICCV 2021)
DeepPanoContext: 基于全局场景背景图和关系优化的全景3D场景理解(ICCV 2021)
论文标题:DeepPanoContext: Panoramic 3D Scene Understanding with Holistic Scene Context Graph and Relation-based Optimization
摘要
全景图像具有更大的视场,因此与标准透视图像相比,全景图像自然编码了丰富的场景上下文信息,但在以往的场景理解方法中并没有很好地利用这一点。本文提出了一种新的全景三维场景理解方法,该方法可以从单一的全景图像中恢复三维房间布局以及每个对象的形状、姿态、位置和语义类别。为了充分利用丰富的环境信息,设计了一种基于图神经网络的环境模型来预测对象与房间布局之间的关系,并设计了一种基于可微关系的优化模块,利用精心设计的目标函数实时优化对象布局。研究人员考虑到现有的数据要么是不完整的真实场景,要么是过于简化的场景,因此提出了一种新的综合数据集,该数据集在房间布局和家具摆放方面具有良好的多样性,具有真实的图像质量,可用于全面的全景3D场景理解。实验表明,该方法在几何精度和物体排列方面都优于现有的全景场景理解方法。
作者:夏初 首发:公众号【3D视觉工坊】
文章末尾附有【点云处理】交流群加入方式!
精品课程推荐:
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现
11.自动驾驶中的深度学习模型部署实战
12.相机模型与标定(单目+双目+鱼眼)
13.重磅!四旋翼飞行器:算法与实战
14.ROS2从入门到精通:理论与实战
研究内容
在本文中,研究人员赋予全景场景理解任务更强的3D感知能力,以单幅彩色全景图像作为输入,旨在预测物体的形状、三维姿态、语义类别和房间布局。为了实现这一目标,研究人员提出了一种新的基于深度学习的框架,利用局部图像信息和全局背景来全景3D场景理解。具体地说,研究人员首先使用为全景图像定制的算法从局部图像区域提取房间布局和目标假设,并依赖上下文模型细化初始估计。该方法在三维全景场景理解的几何精度和场景布局等方面都取得了显著的性能。
研究贡献
研究人员提出了第一个用于全面理解3D场景的基于深度学习的框架,用以从单一的颜色全视图全景图像中恢复3D房间布局和详细的形状,姿势和位置。为了充分利用环境,研究人员设计了一个新的环境模型来预测对象和房间布局之间的关系,然后设计了一个新的基于可微关系的优化模块来细化初始结果。为了学习和评估研究人员的模型,研究人员创建了一个新的数据集,用于全面的全景三维场景理解。研究人员的模型在几何精度和3D对象安排方面都达到了最先进的性能。
研究方法
如上图所示,研究人员首先提取Manhattan World假设下的整个房间布局,以及初始对象估计,包括位置、大小、姿态、语义类别和潜在形状代码。提取的特征被送入基于关系的图卷积网络(Relation-based Graph Convolutional Network,RGCN)进行细化,并同时估计对象和布局之间的关系。在此基础上,提出了一种可微关系优化算法来解决碰撞问题和调整姿态。最后,通过将潜在形状代码输入局部隐式深度函数中恢复三维形状,并结合物体姿态和房间布局实现对场景的整体理解。
1 Bottom-up Initialization
研究人员首先根据局部图像的外观估计出全景场景的空间布局、初始对象的姿态和形状。研究人员采用Mask R-CNN检测2D对象,对象检测网络(Object Detection Network, ODN)生成初始姿态,一个局部隐式嵌入网络(Local Implicit Embedding Network, LIEN)嵌入每个对象的隐式3D表示。所有的网络都是重新训练或自定义的等矩形全景图像。
2 Relation-based Graph Convolutional Network
在得到初始估计后,研究人员用一个图对整个场景建模,然后通过Graph R-CNN对结果进行细化,使用GCN对房间中的所有对象建模,该模型不仅细化了对象的姿态,还预测了对象与房间布局之间的关系。因此将模型称为基于关系的图卷积网络(RGCN)。
3 Relation Optimization
虽然RGCN对物体姿态进行了细化,但一些数值上的微小误差可能会破坏场景建模,如物理碰撞、飞行物体或与墙壁的小间隙。为了解决这些问题,研究人员提出了一种可微的优化方法来更新优化后的位姿,即使用梯度下降来最小化损失函数,包括测量物理碰撞、关系一致性和自底向上观察的一致性三个主要成分。
4全景数据集
由于目前还没有能够完整反映房间布局、物体姿态和物体形状的全景数据集,研究人员提出利用最新的仿真环境iGibson合成一个全景数据集,该全景数据集能够提供详细的三维形状、姿态、位置、物体的语义以及房间布局。iGibson包含了57个类别的500多个对象,15个完全交互式的场景,总共100多个房间,平均75个对象。在渲染之前,研究人员运行一个物理模拟来解决错误的放置(例如,浮动对象),并从相同的语义类别为每个场景随机替换对象与模型。然后研究人员设置高度为1.6米的摄像机,在水平面上随机观察方向。最后,研究人员使用语义/实例分割、深度图像、房间布局和来自物理模拟器的定向三维物体渲染1500幅全景图像。在提供的15个场景中,研究人员使用10个用于训练,5个用于测试,每个场景生成100张图像。
实验
图:3D目标检测对比实验结果图:语义分割IoU指标
研究人员是在场景级重建的全景图像上实现全3D场景理解的。因此,为了与使用透视相机的SoTA方法Total3D和Im3D进行比较,研究人员将全景相机划分为一组水平视场为的相机。然后,研究人员从2D检测器检索全景上的检测结果,并通过摄像机分割对它们进行分组,然后将它们输入到Total3D和Im3D中。物体的姿态和形状的结果从相机坐标转换到世界坐标,以获得最终的结果(Total3D-Pers和Im3D-Pers)。除了透视图版本,研究人员还扩展了Total3D和Im3D,以直接工作在全景图像。具体来说,研究人员将二维包围框的表示形式改为BFoV,并将目标检测结果作为一个整体输入,以提供更丰富的场景上下文信息。由于Total3D和Im3D的设计是做长方体布局估计的,为了便于比较,研究人员用HorizonNet代替了他们的布局估计网络,并且只在3D目标检测和场景重建方面与他们进行比较。所有的模型都按照相同的流程在研究人员建议的数据集上进行了微调。实验结果表面该研究在防止物理碰撞、目标姿态估计和形状重建等方面均表现出最佳性能。
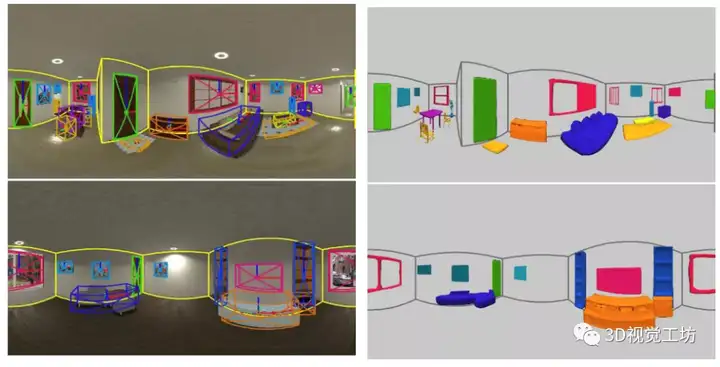
图:三维目标检测与场景重建的定性比较
总结
本文提出了一种从单个全景图像中获取三维场景的方法,该方法恢复了三维房间的布局以及场景中每个物体的形状、姿态、位置和语义类别。利用丰富的上下文信息的全景图像,研究人员采用图神经网络和一种上下文模型来预测对象之间的关系和房间布局,并针对现有数据集在整体三维场景理解方面的局限性,提出了一种新的合成数据集,验证了该方法各模块的有效性,并表明该方法达到了最优性能。
更多干货
欢迎加入【3D视觉工坊】交流群,方向涉及3D视觉、计算机视觉、深度学习、vSLAM、激光SLAM、立体视觉、自动驾驶、点云处理、三维重建、多视图几何、结构光、多传感器融合、VR/AR、学术交流、求职交流等。工坊致力于干货输出,为3D领域贡献自己的力量!欢迎大家一起交流成长~
添加小助手微信:dddvision,备注学校/公司+姓名+研究方向即可加入工坊一起学习进步。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK