

#导入Word文档图片# linux三剑客
source link: https://blog.51cto.com/u_11822586/5449259
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

#导入Word文档图片# linux三剑客
推荐 原创linux三剑客
Linux中的三个命令awk、sed、grep在业界被称为“三剑客”,grep擅长查找,sed擅长取行和替换,awk擅长运算。
我们知道Linux下一切皆文件,对Linux的操作就是对文件的处理,那么怎么能更好的处理文件呢?这就要用到三剑客命令。
三剑客与正则表达式息息相关,正则表达式是为了处理大量的文本|字符串而定义的一套规则和模版,这个模版是由一些普通 字符和一些 元字符组成。普通字符包括大小写的字母和数字,而元字符则具有特殊的含义。正则表达式详情可参看资料《linux正则表达式》。
三剑客与正则表达式是什么关系呢?
三剑客就是普通的命令,有的把他们叫做工具。而正则表达式就好比一个模版,而linux下一般只有三剑客能读懂这个模版.
grep
grep(global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
Unix的grep家族包括grep、egrep和fgrep。egrep和fgrep的命令只跟grep有很小不同。egrep是grep的扩展,支持更多的re元字符, fgrep就是fixed grep或fast grep,它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊。linux使用GNU版本的grep。它功能更强,可以通过-G、-E、-F命令行选项来使用egrep和fgrep的功能。
查找内容可以用双引号括起来,也可以不用,建议使用双引号,双引号中一些特殊符号要注意使用转义字符。
grep [OPTIONS] PATTERN [FILE...] |
- grep默认不支持扩展正则,因此扩展正则表达式的符号对于grep来说就等同于普通字符含义,因此,想让grep直接处理正则符号必须通过转义字符\{\}来处理。
- grep -E 强制让grep直接认识正则符号,不需要再进行转义
- egrep 等效grep -E 天生就能认识正则符号
- 我们平时备份可以通过cp 文件名{,.bak}的形式进行,避免再打一次文件名
选项参数
-a 不要忽略二进制数据。 -A<显示行数> 除了显示符合范本样式的行之外,并显示该行之后的指定几行内容。 -B<显示行数> 除了显示符合范本样式的行之外,并显示该行之前的指定几行内容。 -C<显示行数> 除了显示符合范本样式的那一行之外,并显示该行前后指定几行的内容。 -b 在显示符合范本样式的那一行之外,并显示字节偏移量。 -c 只计算显示符合范本样式的行数,不显示详细内容 -d<进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。 -e<范本样式> 指定字符串作为查找文件内容的范本样式。 -E 将范本样式为延伸的普通表示法来使用,意味着能使用扩展正则表达式。 -f<范本文件> 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。 -F 将范本样式视为固定字符串的列表。 -G 将范本样式视为普通的表示法来使用。 -h 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。 -H 在显示符合范本样式的那一列之前,标示该列的文件名称。 -i 忽略字符大小写的差别。 -l 列出文件内容符合指定的范本样式的文件名称。 -L 列出文件内容不符合指定的范本样式的文件名称。 -n 在显示符合范本样式的那一列,标示出该列的编号。 -q 不显示任何信息。 -R/-r 此参数的效果和指定“-d recurse”参数相同,表明查找路径为目录 -s 不显示错误信息。 -v 反转查找,显示不符合模式的所有信息 -w 只显示全字符合的列。 -x 只显示全列符合的列。 -y 此参数效果跟“-i”相同。 -o 只输出文件中匹配到的部分。 --color=auto 把匹配部分标记出来,要想当前终端后续使用都要标记匹配部分,可用alias命令重新封装grep :#alias grep=’grep --color=auto’ |
常用示例
在文件中查找内容
成功会输出所有包含查找内容的行,否则输出为空。
$ grep bash file_read.sh #在file_read.sh内查找bash $ grep "bash" file_read.sh --color=auto #两者效果相同,并且标记颜色 $ grep "bash" file_read.sh demo.sh #在file_read.sh demo.sh 内查找bash |
在目录下查找内容
成功会输出文件名:所有包含内容的行,否则输出为空
需运用-r/-R/-d recurse 选项参数,指明查找路径为目录
$ grep "bash" -r ./ #在当前目录下查找文件内容bash $ grep "bash" -R ./ $ grep "bash" -d recurse ./ |
显示查找内容所在行的行号
需运用-n参数,显示行号,可单独也可与其他选项参数写在一起。
$ grep "bash" -n file_read.sh #在file_read.sh内查找bash $ grep "bash" -Rn ./ $ grep "bash" -r -n ./ |
反转显示,显示与查找内容不符合的所有内容
需运用-v参数。
$ grep "bash" -vn demo.sh #显示demo.sh内不包含bash的行,并显示行号 |
查找以某内容开头的行
需运用正则表达式^...。
$ grep "^#" demo.sh #查找demo.sh内以#开头的行,注意前面不能有空白字符,必须是最开头 |
查找空白行
需运用正则表达式^...。
需运用正则表达式...$。
$ grep "^$" 123.txt |
查找非指定字符开头的行
$ grep "^[^#]" demo.sh #在demo.sh中查找不以#开头的行 |
查找以某内容结尾的行
需运用正则表达式...$。
$ grep "name$" demo.sh #查找demo.sh内以name结尾的行,注意必须是最后且后面不能有空白字符 |
获取查找内容行数
需运用-c参数,不显示详细内容,只显示行数
$ grep "name" demo.sh -c # 在demo.sh中查找name出现的行数 |
显示查找内容及其前后行内容
$ grep "name" demo.sh -A 2 #显示查找内容及其后两行内容 $ grep "name" demo.sh -B 2 #显示查找内容及其前两行内容 $ grep "name" demo.sh -C 2 #显示查找内容及其前后两行内容 |
查找阿拉伯数字
需要用到正则表达式[m]与{n},选项参数-E(指定使用正则表达式)
[]正则表达式:[m]表明查找匹配m字符的内容。
[^m]表明匹配不是m字符的内容。
[m-f]表示匹配m到f的内容,m可以是数字,可以是字符。
{}正则表达式:{m}表示匹配之前的项m次
{m,}表示匹配之前的项至少m次
{m,f}表示匹配之前的项m次到f次。m是可以为0的正整数。
$ grep "[1-3]\{2\}" 123.txt #在123.txt中查找1-3之间数字出现两次的内容,注意{}前后一定要加转义字符 $ grep -E "[1-3]{2}" 123.txt #或者直接使用-E参数指定使用正则表达式,则可不加转义 $ grep "[1-3][1-3]" 123.txt #与上面相同效果,也表示在123.txt中查找1-3之间数字出现两次的内容 $ifconfig | grep "[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}" |
grep用于常规的查询操作固然方便,但是最大的弊端就是查出来不能增删改,导致如果是写一些脚本就会很不方便,这个时候就需要sed和awk这样的工具来实现。
sed
sed是一种流编辑器,它是文本处理中非常中的工具,能够完美的配合正则表达式使用,功能不同凡响。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
命令格式:
sed [options] 'command' file(s) sed [options] -f scriptfile file(s) |
注意:查找的内容前后一定要用/包含起来,示例/sh/。替换的时候可用@与#替换/。
命令与查找内容可连在一起也可分开,但是中间必须有/作为间隔。
sed的工作流程:
1:sed默认不编辑原文件,而是逐行操作,复制一份到指定内存(pattern space,模式空间)
2:pattern space内进行模式匹配,即和指定条件做匹配
不满足模式:输出到标准输出STDOUT
满足模式:进行指定的模式操作,再输出到STDOUT
3:第二个特殊的内存空间 :保持空间(hold space),临时保存操作在另一处内存
4:当执行pattern space和 hold space相关选项时候会进行之间的数据流编辑操作
5:最后根据操作执行hold space空间操作,选择性显示到STDOUT
选项参数
-c/--copy 用拷贝代替重命名 -e<script>/--expression=<script> 以选项中的指定的脚本来处理输入的文本文件; -f<script文件>/--file=<script文件> 以选项中指定的脚本文件来处理输入的文本文件; --follow-symlinks 处理输入的文本文件时,追踪软链接,断开硬链接 -h/--help 显示帮助; -i[SUFFIX]/ --in-place[=SUFFIX] 就地编辑文件,提供了后缀名(.bak)则备份文件 -l N/ --line-length=N 为l命令指定换行的长度n -n/--quiet/——silent 不自动打印模式空间内容,仅显示脚本处理后的结果,sed默认打印全部内容 --posix 禁用所有GNU扩展 -u/ --unbuffered 从输入文件中加载最小的数据并频繁刷新输出缓冲区 -V/--version 显示版本信息。 -r/--regexp-extended 支持使用扩展正则表达式 -s/--separate 把文件作为单独的个体而不是作为单个连续的长流 |
命令
命令建议用单引号’’或双引号括起来方便区分,多个命令用;隔开。
a\ 在当前行下面插入文本。 i\ 在当前行上面插入文本。 c\ 把选定的行改为新的文本。 d 删除,删除选择的行。 D 删除模板块的第一行。 s 替换指定字符,字符间可用/或@或#隔开 h 拷贝模板块的内容到内存中的缓冲区。 H 追加模板块的内容到内存中的缓冲区。 g 获得内存缓冲区的内容,并替代当前模板块中的文本。 G 获得内存缓冲区的内容,并追加到当前模板块文本的后面。 l 列表不能打印字符的清单。 n 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。 N 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。 p 打印模板块的行。前面可加数字,指定打印第几行 P(大写) 打印模板块的第一行。 q 退出Sed。 b lable 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾。 r file 从file中读行。 t label if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。 T label 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。 w file 写并追加模板块到file末尾。 W file 写并追加模板块的第一行到file末尾。 ! 表示后面的命令对所有没有被选定的行发生作用。 示例:1!表明对文中所有行起作用,3!表示对文中第三行及以下行起作用 = 打印当前行号码。 # 把注释扩展到下一个换行符以前。 |
替换标记
g 表示行内全面替换。 p 表示打印行。 w 表示把行写入一个文件。 x 表示互换模板块中的文本和缓冲区中的文本。 y 表示把一个字符翻译为另外的字符(但是不用于正则表达式) \1 子串匹配标记 & 已匹配字符串标记 |
元字符集
^ 匹配行开始,如:/^sed/匹配所有以sed开头的行。 $ 匹配行结束,如:/sed$/匹配所有以sed结尾的行。 . 匹配一个非换行符的任意字符,如:/s.d/匹配s后接一个任意字符,最后是d。 * 匹配0个或多个字符,如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行。 [] 匹配一个指定范围内的字符,如/[sS]ed/匹配sed和Sed。 [^] 匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行。 \(..\) 匹配子串,保存匹配的字符,如s/\(love\)able/\1rs,loveable被替换成lovers。 & 保存搜索字符用来替换其他字符,如s/love/**&**/,love这成**love**。 \< 匹配单词的开始,如:/\<love/匹配包含以love开头的单词的行。 \> 匹配单词的结束,如/love\>/匹配包含以love结尾的单词的行。 x\{m\} 重复字符x,m次,如:/0\{5\}/匹配包含5个0的行。 x\{m,\} 重复字符x,至少m次,如:/0\{5,\}/匹配至少有5个0的行。 x\{m,n\} 重复字符x,至少m次,不多于n次,如:/0\{5,10\}/匹配5~10个0的行。 |
脚本地址定界
/ 在sed中作为定界符使用,也可以使用任意的定界符:| / 定界符出现在样式内部时,需要进行转义,示例:sed 's/\/bin/\/usr\/local\/bin/g' 不给地址:对全文进行处理 $:表示最后一行 地址范围: 选定行的范围:,(逗号) /pattern/:被此处模式所能够匹配到的每一行 /pattern/,m:被模式匹配到的第一行起到m行 n,m 表示从n行到第m行 n,+m 表示从n行起往后增加m行 n~m:步进:以n行为基准值,每次增加m行 |
组合多个表达式
sed '表达式' | sed '表达式' 等价于: sed '表达式; 表达式' |
常用示例
显示输入文件的行号
需用到命令:=:打印当前行号码(包括空白行)
需用到元字符集:. :匹配一个非换行符的任意字符
需用到命令:!: 表示后面的命令对所有没有被选定的行发生作用。
$ sed '=' 123.txt #显示文本的每一行行号 $ sed '3=' 123.txt #显示文本的第三行行号 $ sed "/./=" 123.txt #只显示非空白行的行号 $ sed -n "/./!=" 123.txt #只显示空白行行号 |
显示文件总行数
需用到元字符集:$:匹配到行结束
$ sed '$=' 123.txt #可显示123.txt内总共有多少行,也就是最后一行的行号 |
打印输入文件的指定行内容
需用到-n参数:不自动打印,
需用到p命令:打印模块的行
$ sed -n '2p' 123.txt #注意一定要加-n,否则会默认自动打印所有内容 $ sed -n '2 p' 123.txt #注意一定要加-n,否则会默认自动打印所有内容 |
打印输入文件的指定几行内容
$sed -n '2,7 p' 123.txt #注意一定要加-n,否则会默认自动打印所有内容 $ sed -n '2,7p' 123.txt $ sed -n '2,7 {p}' 123.txt #命令也可单独用{}括起来 |
替换输入文件中内容
需用到-i参数:就地编辑文件,会对源文件作更改
需用到s命令:替换指定字符,注意字符之间可用/@#隔开,注意如果没有其他命令或者替换标记作为结尾,最后也必须得由它们作为尾字符,
需用到g替换标记:替换行内的所有匹配内容,前面可加数字,表明第几个匹配位置
$ sed -i 's/bck/sh/' 123.txt 666.txt #替换123.txt、666.txt内的bck为sh,每行只替换一个 $ sed -i 's/bck/sh/g' 123.txt #替换123.txt内的bck为sh,每行都进行全面替换 $ sed -i 's/bck/sh/3g' 123.txt #替换123.txt内的bck为sh,从第3个匹配位置开始替换 $ sed -i 's@bck@sh@g' 123.txt #替换123.txt内的bck为sh,每行都进行全面替换 $ sed -i 's#bck#sh#g' 123.txt #替换123.txt内的bck为sh,每行都进行全面替换 |
替换输入文件中指定行的内容
$ sed -i '1,5 s/bck/sh/g' 123.txt 666.txt #替换123.txt、666.txt内的第一行到第五行的bck为sh,每行全面替换 $ sed -i '2,+2 {s/bck/sh/g}' 123.txt 666.txt #替换123.txt、666.txt内的第二行往后两行的bck为sh,每行全面替换,命令也可以单独用{}括起来,表示边界 $ sed -i '2~2 s/bck/sh/g' 123.txt 666.txt #替换123.txt、666.txt内的第二行往后每次增加两行的bck为sh,每行全面替换 |
给文件名\单词前统一替换加前缀或后缀或前后缀
需用到元字符集:^ 匹配行开始,如:/^sed/匹配所有以sed开头的行。
需用到元字符集:$ 匹配行结束,如:/sed$/匹配所有以sed结尾的行。
需用到替换标记:& 已匹配字符串标记,代替之前已匹配内容
需用到正则表达式:\w\+:匹配每一个单词
$ ls | sed 's/^/666_&/g' #表示给当前文件下的文件名统一添加前缀 $ ls | sed 's/$/666_&/g' #表示给当前文件下的文件名统一添加后缀 $ ls | sed 's/\w\+/666_&/g' #表明给所有的单词添加前缀 $ ls | sed 's/\w\+/[&]/' #表明给每个匹配到的单词用[]括起来 |
显示指定区间以指定内容开头或结尾的行
需用到元字符集^:匹配行开始
如果/前面有地址定界,则在/外面必须加上{}
$ sed -n '1,10 {/^10/p}' 123.txt #显示123.txt内第1到第10行中以10开头的行 $ sed -n '/^10/p' 123.txt # /前没有地址定界则可以不加{},如果有则必须加上 $ sed -n '1,10 {/sh$/p}' 123.txt #显示123.txt内第1到第10行中以结尾的行 |
显示查找内容的所有行、显示找到的第一行及以下指定行
需用到脚本地址定界:/pattern/:被此处模式所能够匹配到的每一行
需用到脚本地址定界:/pattern/,m:被模式匹配到的第一行起到m行
需用到脚本地址定界:$ 匹配到末尾行
$ sed -n '/sh/p' 123.txt #显示123.txt内的所有包含sh的所有行 $ sed -n '/sh/ ,$ p' 123.txt #显示123.txt里第一条包含sh的行及以下到末尾的所有行 $ sed -n '/sh/ ,$p' 123.txt |
逆序输出文本内容
需用到命令:!:!前跟非零数字,表示后面的命令对所有没有被选定的行发生作用
需用到命令:G:获得内存缓冲区的内容,并追加到当前模板块文本的后面
需用到命令:h: 拷贝模板块的内容到内存中的缓冲区
需用到命令:d :删除,删除选择的行。
多个命令之前用分号;隔开。
$ sed '1!G;h;$!d' 123.txt |
逆序输出每行内容
$ sed '/\n/!G;s/\(.\)\(.*\n\)/&\2\1/;//D;s/.//' 123.txt |
删除指定行
需用到命令:d 删除,删除选择的行。
$ grep -n "sh" 123.txt | sed '4,5d' #删除grep查找到的内容的第4到5行 $ grep -n "sh" 123.txt | sed '1,2d' #删除grep查找到的内容的第1行后每次隔两行删一行 $ sed '/^$/d' 123.txt #删除空白行 |
在指定行前后插入内容
需用到命令:a\ 在当前行下面插入文本。默认当前行为最末行
需用到命令:i\ 在当前行上面插入文本。默认当前行为最末行
需用到命令:c\ 把选定的行改为新的文本。默认当前行为所有行
$ sed 'a\hello\' 123.txt #在123.txt的末行后增加一行hello $ sed 'i\hello\' 123.txt #在123.txt的末行前增加一行hello $ sed 'c\hello\' 123.txt #替换123.txt的所有行为hello $ sed '8a\hello\' 123.txt #在123.txt的第8行后增加一行hello $ sed '8,10a\hello\' 123.txt #在123.txt的第8行到10行每一行后增加一行hello $ sed '8,10c\hello\' 123.txt #在123.txt的第8行到10行替换为一行hello |
一行内执行多条命令
需用到选项参数-e<script>/--expression=<script> 以选项中的指定的脚本来处理输入的文本文件;
$ sed -e '1,5d' -e 's/sh/bck/' 123.txt #先删除1到5行再替换sh为bck $ sed '1,5d;s/sh/bck/' 123.txt #三者效果相同 $ sed --expression='1,5d' --expression='s/sh/bck/' 123.txt #三者效果相同 |
awk
awk是它的三个作者姓氏的首字母合写,他们是:Aho(阿尔佛雷德·艾侯)、Winberger(彼得·温伯格)和Kernighan(布莱恩·柯林汉),他们三人合著《AWK程式设计》。
awk是一种文本处理工具,同时它也是一门微型编程语言,它的目的是编写小巧 但充满表达力的程序,把文本的输入变换为文本的输出。用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入(stdin)、一个或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是linux/unix下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。awk有很多内建的功能,比如数组、函数等,这是它和C语言的相同之处,灵活性是awk最大的优势。
现今的Linux发行版所附带的awk实际上很新,是GNU的重写版本,也叫GNU awk,程序名是gawk。
awk命令格式和选项
语法形式
awk [options] 'script' var=value file(s) awk [options] -f scriptfile var=value file(s) |
常用选项
-F fs fs指定输入分隔符,fs可以是字符串或正则表达式,如-F: -v var=value 赋值一个用户定义变量,将外部变量传递给awk -f scripfile 从脚本文件中读取awk命令 -m[fr] val 对val值设置内在限制,-mf选项限制分配给val的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用 |
awk的核心思想是模式和行为操作,也叫模式驱动编程。模式一般是关系或正则表达式,用于与输入的每条记录进行匹配;而行为操作则是对模式匹配到的记录的处理方法,采用与C类似的语法,并由一对大括号“{}”括起来。
模式
/正则表达式/:使用通配符的扩展集。 关系表达式:使用运算符进行操作,可以是字符串或数字的比较测试。 模式匹配表达式:用运算符~(匹配)和~!(不匹配)。 BEGIN语句块、pattern语句块、END语句块 |
行为操作
awk脚本基本结构
awk脚本基本结构
awk 'BEGIN{ commands } pattern{ commands } END{ commands }' file |
一个awk脚本通常由:BEGIN语句块、能够使用模式匹配的通用语句块、END语句块3部分组成,这三个部分是可选的。任意一个部分都可以不出现在脚本中,脚本通常是被单引号或双引号中。
awk 'BEGIN{ i=0 } { i++ } END{ print i }' filename awk "BEGIN{ i=0 } { i++ } END{ print i }" filename |
awk的工作原理
第一步:执行BEGIN{ commands }语句块中的语句;
第二步:从文件或标准输入(stdin)读取一行,然后执行pattern{ commands }语句块,它逐行扫描文件,从第一行到最后一行重复这个过程,直到文件全部被读取完毕。
第三步:当读至输入流末尾时,执行END{ commands }语句块。
BEGIN语句块在awk开始从输入流中读取行之前被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中。
END语句块在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块。
pattern语句块中的通用命令是最重要的部分,它也是可选的。如果省略模式,则行为将被应用到每条输入记录;如果省略行为,则默认操作是在标准输出上打印匹配到的记录,执行{ print }。
awk程序的pattern语句块有以下三种情况:
awk 'pattern {commands }' #如果模式匹配,则执行行为 awk 'pattern ' #如果模式匹配,则在标准输出上打印记录执行{ print } awk ' {commands }' # 针对每条记录,执行行为。 |
$ echo -e "hello \n my baymax " | awk 'BEGIN{ print "Start" } { print } END{ print "End" }' #完整的结构 #-e参数表示echo内可使用转义字符 $ echo -e "hello \n my baymax " | awk 'BEGIN{ print "Start" } { print } ' #省略end结构 $ echo -e "hello \n my baymax " | awk ' { print } ' #省略前后结构 $ echo -e "hello \n my baymax " | awk ' { print } END{ print "End" }' #省略begin结构 |
当使用不带参数的print时,它就打印当前行,当print的参数是以逗号进行分隔时,打印时则以空格作为定界符。例如:
$echo | awk '{ var1="v1"; var2="v2"; var3="v3"; print var1,var2,var3; }' v1 v2 v3 |
在awk的print语句块中双引号是被当作拼接符使用:
echo | awk '{ var1="v1"; var2="v2"; var3="v3"; print var1"="var2"="var3; }' |
v1=v2=v3
{ }类似一个循环体,会对文件中的每一行进行迭代,通常变量初始化语句(如:i=0)以及打印文件头部的语句放入BEGIN语句块中,将打印的结果等语句放在END语句块中。
awk内置变量(预定义变量)
说明:[A][N][P][G]表示第一个支持变量的工具,[A]=awk、[N]=nawk、[P]=POSIXawk、[G]=gawk
$n 当前记录的第n个字段,比如n为1表示第一个字段,n为2表示第二个字段。 字段是用空格隔开的单词段。 $0 这个变量包含执行过程中当前行的文本内容。 [A] NF 表示字段数,在执行过程中对应于当前的字段数。而$NF则表示一行中的最后一个字段。$(NF-n)则表示一行中的倒数第n个字段,n为正整数。 [A] NR 表示记录数,在执行过程中对应于当前的行号。 [A] OFMT 数字的输出格式(默认值是%.6g)。 [A] OFS 输出字段分隔符(默认值是一个空格)。 [A] ORS 输出记录分隔符(默认值是一个换行符)。 [A] RS 记录分隔符(默认是一个换行符)。 [A] FILENAME 当前输入文件的名。 [A] FS 字段分隔符(默认是任何空格)。 [G] ARGIND 命令行中当前文件的位置(从0开始算)。 [G] CONVFMT 数字转换格式(默认值为%.6g)。 [G] FIELDWIDTHS 字段宽度列表(用空格键分隔)。 [G] IGNORECASE 如果为真,则进行忽略大小写的匹配。 [N] RSTART 由match函数所匹配的字符串的第一个位置。 [N] RLENGTH 由match函数所匹配的字符串的长度。 [N] SUBSEP 数组下标分隔符(默认值是34)。 [N] ARGV 包含命令行参数的数组。 [N] ARGC 命令行参数的数目。 [N] ERRNO 最后一个系统错误的描述。 [P] ENVIRON 环境变量关联数组。 [P] FNR 同NR,但相对于当前文件。 |
需用到内置变量:NR 表示记录数,在执行过程中对应于当前的行号。
需用到内置变量:NF 表示字段数,在执行过程中对应于当前的字段数。而$NF则表示一行中的最后一个字段。
需用到内置变量:$n 当前记录的第n个字段,比如n为1表示第一个字段,n为2表示第二个字段。
$ echo -e "line1 f2 f3\n line2 f4 f5" | awk '{print "Line No:"NR", No of fields:"NF, "$0="$0, "$1="$1, "$2="$2, "$3="$3}' |
将外部变量值传递给awk
需用到-v选项,可以将外部值(并非来自stdin)传递给awk,有三种方式。
第一种:写在脚本内(脚本后缀名随意,编辑好直接运行即可)
var1="aaa" var2="bbb" echo | awk '{ print v1,v2 }' v1=$var1 v2=$var2 |
第二种:传递外部变量方法:
Va=100 echo | awk -v VARIABLE=$Va '{ print VARIABLE }' |
第三种:当输入来自于文件时使用??
awk '{ print v1,v2 }' v1=$var1 v2=$var2 filename |
以上方法中,变量之间用空格分隔作为awk的命令行参数跟随在BEGIN、{}和END语句块之后。
awk运算符
awk支持多种运算,这些运算与C语言提供的基本相同。awk还提供了一系列内置的运算函数(如log、sqr、cos、sin等)和一些用于对字符串进行操作(运算)的函数(如length、substr等等)。这些函数的引用大大的提高了awk的运算功能。作为对条件转移指令的一部分,关系判断是每种程序设计语言都具备的功能,awk也不例外,awk中允许进行多种测试,作为样式匹配,还提供了模式匹配表达式~(匹配)和~!(不匹配)。作为对测试的一种扩充,awk也支持用逻辑运算符。
算术运算符
注意:所有用作算术运算符进行操作,操作数自动转为数值,所有非数值都变为0
运算符 | 描述 |
乘,除与求余 | |
一元加,减和逻辑非(一元表示只有一个操作数) | |
++ -- | 增加或减少,作为前缀或后缀 |
$ awk 'BEGIN{a="b"; print a++,++a}' #注意这里a="b"后面一定要加;,表明这是一条语句。 |
赋值运算符
运算符 | 描述 |
= += -= *= /= %= ^= **= | 赋值语句 |
关系运算符
注意:> < 可以作为字符串比较,也可以用作数值比较,关键看操作数如果是字符串就会转换为字符串比较。两个都为数字才转为数值比较。字符串比较:按照ASCII码顺序比较。
运算符 | 描述 |
< <= > >= != == | 关系运算符 |
逻辑运算符
运算符 | 描述 |
$ awk 'BEGIN{a=1;b=2;print (a>5 && b<=2),(a>5 || b<=2);}' |
正则运算符
运算符 | 描述 |
匹配正则表达式 | |
不匹配正则表达式 |
需用到正则表达式/^.../,表示以什么内容开头的
$ awk 'BEGIN{a="100testa";if(a ~ /^100*/) {print "ok";}}' $ awk 'BEGIN{a="100testa";if(a !~ /^100*/){print "ok";}else {print "error"}}' error |
其他运算符
运算符 | 描述 |
字段引用 | |
字符串连接符 | |
C条件表达式 | |
数组中是否存在某键值(下标) |
$ awk 'BEGIN{a="b";arr[0]="b";arr[1]="c";print (b in arr);}' #b in arr问arr是否有b这个下标 $ awk 'BEGIN{b=0;arr[0]="b";arr[1]="c";print (b in arr);}' #b最初赋值为1,而数组arr下标为1是存在的 |
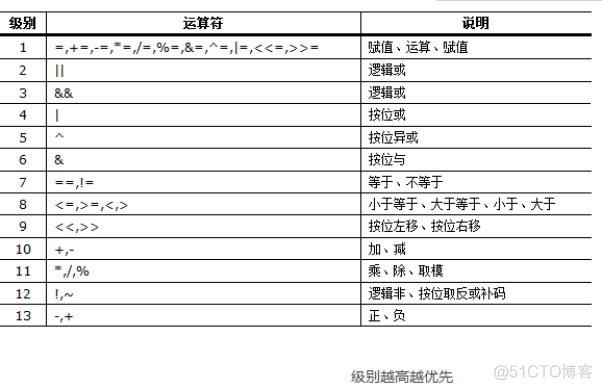
运算符优先级表
控制语句
在linux awk的while、do-while和for语句中允许使用break,continue语句来控制流程走向,也允许使用 exit这样的语句来退出。break中断当前正在执行的循环并跳到循环外执行下一条语句。if 是流程选择用法。每条命令语句后面可以用;分号结尾。
if条件判断语句
语法:表达式为真执行语句1,为假执行语句2
if(表达式) else |
格式中语句1可以是多个语句,为了方便判断和阅读,最好将多个语句用{}括起来。awk分枝结构允许嵌套,其格式为:
if(表达式) {语句1} else if(表达式) {语句2} else {语句3} |
编写在脚本内
$ cat ass.sh awk 'BEGIN{ test=100; if(test>90){ print "very good"; else if(test>60){ print "good"; else{ print "no pass"; 输出结果:very good |
while循环语句
语法:表达式为真,循环执行语句,直到条件为假
while(表达式) {语句} |
do...while循环语句
语法:先执行语句再判断条件真假,为真则循环执行,为假停止执行。
{语句} while(条件) |
for循环语句
语法一:执行变量初始化,再判断条件,条件为真,执行语句,再执行表达式,再判断条件,条件为真,再执行语句,如此循环直至条件为假。
for(变量初始化;条件;表达式) {语句} |
语法二:每次从数组中取一个值赋给变量,再执行语句,循环直到数组内部的数据取完,变量为空。
for(变量 in 数组) {语句} |
需用内置变量ENVIRON :当前系统环境变量关联数组
[DSYU@DSYU shell]$ cat ass.sh awk 'BEGIN{ for(k in ENVIRON){ print k"="ENVIRON[k]; #每次从环境变量数组中取一个数据赋值给k,然后再打印出来。 |
next语句
next 能够导致读入下一个输入行,并返回到脚本的顶部。这可以避免对当前输入行执行其他的操作过程。
awk中next语句使用:在循环逐行匹配,如果遇到next,就会跳过当前行,直接忽略下面语句。而进行下一行匹配。next语句一般用于多行合并:
需用到内置变量NR:表示记录数,在执行过程中对应于当前的行号
$ awk 'NR%2==1{next}{print NR,$0;}' 123.txt #表示当行号取余2为1也就是奇数行时跳过当前行 |
其他语句
- break 当
- continue 当
- exit 语句使主输入循环退出并将控制转移到END,如果END存在的话。如果没有定义END规则,或在END中应用exit语句,则终止脚本的执行。
数组应用
数组是awk的灵魂,处理文本中最不能少的就是它的数组处理。因为数组索引(下标)可以是数字和字符串,在awk中数组叫做关联数组(associative arrays)。awk 中的数组不必提前声明,也不必声明大小。数组元素用0或空字符串来初始化,这根据上下文而定。因为数组是关联数组,默认是无序的。所以通过for…in得到是无序的数组。如果需要得到有序数组,需要通过指定下标获得。
数组的定义
awk的数组不必提前声明,也不必声明大小。
数字做数组索引(下标或键值)。
注意:数组下标是从1开始,与C数组不一样。
Array[1]="sun" Array[2]=1970 |
字符串做数组索引(下标):
Array["first"]="year" Array["birth"]="1970" |
使用中print Array[1]会打印出sun;使用print Array[2]会打印出1970;使用print["first"]会得到year。
$ awk 'BEGIN {Array["first"]="year"; Array[2]=1970; {print Array["first"]"="Array[2]}}' year=1970 $ awk 'BEGIN {Array["first"]="year"; Array[2]=1970; { for(item in Array) {print Array[item],item}; }}' year first 1970 2 #注意此处是取的数组的下标值赋给item,而不是数组元素值 |
数组函数
length函数
使用形式:length(array)
length函数返回array数组长度,array可是数组名也可使字符串。
$ awk 'BEGIN { print length("hello")}' |
split函数
使用形式:split(src,dst,accrod);
split函数以accrod为依据分割src字符串为数组存储到dst内,也会返回分割得到数组长度。
$ awk 'BEGIN{info="it is a test 56 78";lens=split(info,tA,"is");print lens,tA[1],tA[2],tA[3]}' #此示例以is为依据分隔info,分隔为为两个字符串,所以lens为2。 $ awk 'BEGIN{info="it is a test 56 78";lens=split(info,tA,"");print lens,tA[1],tA[2],tA[3]}' #此示例是把info字符串内的所有字符拆分为独立的单个字符存储到tA数组中。 |
asort函数
使用形式:asort(array);不能对字符串操作。
对array数组进行排序,返回数组长度(下标的个数而不是字符的个数)。
$ awk 'BEGIN{info[1]="it";info[2]="aa";{print asort(info),info[1],info[2]}}' #此示例对info数组排序,返回数组元素个数。 |
delete
使用形式:delete array[key],可以删除对应数组array key的序列值。
if(key in array)通过这种方法判断数组中是否包含key键值。
$ awk 'BEGIN{tB["a"]="a1";tB["b"]="b1";delete tB["b"];for(k in tB){print k,tB[k];}}' |
二维、多维数组使用
awk的多维数组在本质上是一维数组,更确切一点,awk在存储上并不支持多维数组。awk提供了逻辑上模拟二维数组的访问方式。例如,array[2,4]=1这样的访问是允许的。
类似一维数组的成员测试,多维数组可以使用if ( (i,j) in array)这样的语法,但是下标必须放置在圆括号中。类似一维数组的循环访问,多维数组使用for ( item in array )这样的语法遍历数组。与一维数组不同的是,多维数组必须使用split()函数来访问单独的下标,awk使用一个特殊的字符串SUBSEP作为分割字段。
可以通过array[k,k2]引用获得数组内容。
awk 'BEGIN{ for(i=1;i<=9;i++){ for(j=1;j<=9;j++){ tarr[i,j]=i*j; print i,"*",j,"=",tarr[i,j]; |
另一种方式:
awk 'BEGIN{ for(i=1;i<=9;i++){ for(j=1;j<=9;j++){ tarr[i,j]=i*j; for(m in tarr){ split(m,tarr2,SUBSEP); print tarr2[1],"*",tarr2[2],"=",tarr[m]; # split(m,tarr2,SUBSEP); 运用了SUBSEP特殊字符串,把二维数组的键值m分割存放在tarr2数组中。 |
内置函数
awk内置函数,主要分以下:算数函数、字符串函数、其它一般函数、时间函数。
算术函数
格式 | 描述 |
atan2( y, x ) | 返回 y/x 的反正切。 |
cos( x ) | 返回 x 的余弦;x 是弧度。 |
sin( x ) | 返回 x 的正弦;x 是弧度。 |
exp( x ) | 返回 x 幂函数。 |
log( x ) | 返回 x 的自然对数。 |
sqrt( x ) | 返回 x 平方根。 |
int( x ) | 返回 x 的截断至整数的值。 |
rand( ) | 返回任意数字 n,其中 0 <= n < 1。 |
srand( [ expr] ) | 将 rand 函数的种子值设置为 Expr 参数的值, 或如果省略 Expr 参数则使用某天的时间。返回先前的种子值。 |
字符串函数
注:Ere都可以是正则表达式。
请参考常用示例。
格式 | 描述 |
gsub( Ere, Repl, [ In ] ) | 用 Repl 参数指定的字符串全部替换 In 参数指定的字符串中的能与由 Ere 参数指定的扩展正则表达式匹配的具体值,其他的与sub函数完全一样执行。 |
sub( Ere, Repl, [ In ] ) | 用 Repl 参数指定的字符串替换 In 参数指定的字符串中的由 Ere 参数指定的扩展正则表达式的第一个具体值。sub 函数返回替换的数量。出现在 Repl 参数指定的字符串中的 &(和符号)由 In 参数指定的与 Ere 参数的指定的扩展正则表达式匹配的字符串替换。如果未指定 In 参数,缺省值是整个记录($0 记录变量)。 |
index( String1, String2 ) | 在由 String1 参数指定的字符串查找String2 指定的参数,存在即返回位置,从1开始编号。不在则返回 0(零)。 |
length [(String)] | 返回 String 参数指定的字符串的长度(字符形式)。如果未给出 String 参数,则返回整个记录的长度($0 记录变量)。如果是数组,则返回数组的元素个数 |
blength [(String)] | 返回 String 参数指定的字符串的长度(以字节为单位)。如果未给出 String 参数,则返回整个记录的长度($0 记录变量)。 |
substr( String, M, [ N ] ) | 返回从string指定字符串第M个位置(编号从1开始)截取的N个字符组成的字符串。如果未指定 N 参数,则子串的长度将是 M 参数指定的位置到 String 参数的末尾的长度。 |
match( String, Ere ) | 在 String 参数指定的字符串(Ere 参数指定的扩展正则表达式出现在其中)中返回位置(字符形式),从 1 开始编号,或如果 Ere 参数不出现,则返回 0(零)。RSTART 特殊变量设置为返回值。RLENGTH 特殊变量设置为匹配的字符串的长度,或如果未找到任何匹配,则设置为 -1(负一)。 |
split( String, A, [Ere] ) | 将 String 参数指定的参数以ERe指定的依据为准分割为数组元素 A[1], A[2], . . ., A[n],并返回 n 变量的值。此分隔可以通过 Ere 参数指定的扩展正则表达式进行,或用当前字段分隔符(FS 特殊变量)来进行(如果没有给出 Ere 参数)。除非上下文指明特定的元素还应具有一个数字值,否则 A 数组中的元素用字符串值来创建。 |
tolower( String ) | 返回 String 参数指定的字符串,字符串中每个大写字符将更改为小写。大写和小写的映射由当前语言环境的 LC_CTYPE 范畴定义。 |
toupper( String ) | 返回 String 参数指定的字符串,字符串中每个小写字符将更改为大写。大写和小写的映射由当前语言环境的 LC_CTYPE 范畴定义。 |
sprintf(Format, Expr, Expr, . . . ) | 根据 Format 参数指定的 printf 子例程格式字符串来格式化 Expr 参数指定的表达式并返回最后生成的字符串。 |
这里注意sprintf格式化字符串输出
其中格式化字符串包括两部分内容:一部分是正常字符,这些字符将按原样输出; 另一部分是格式化规定字符,以"%"开始,后跟一个或几个规定字符,用来确定输出内容格式。
格式符列表
格式 | 描述 |
十进制有符号整数 | |
十进制无符号整数 | |
单个字符 | |
指针的值 | |
指数形式的浮点数 | |
%X 无符号以十六进制表示的整数 | |
无符号以八进制表示的整数 | |
自动选择合适的表示法 |
$ awk 'BEGIN{n1=124.113;n2=1.224;n3=1.2345; printf("%.2f,%2u,%2g,%X,%o\n",n1,n2,n3,n1,n1);}' 124.11, 1,1.2345,7C,174 |
一般函数
格式 | 描述 |
close( Expression ) | 用同一个带字符串值的 Expression 参数来关闭由 print 或 printf 语句打开的或调用 getline 函数打开的文件或管道。如果文件或管道成功关闭,则返回 0;其它情况下返回非零值。如果打算写一个文件,并稍后在同一个程序中读取文件,则 close 语句是必需的。 |
system( command) | 执行 Command 参数指定的命令,并返回退出状态。等同于 system 子例程。 |
Expression | getline [ Variable ] | 从来自 Expression 参数指定的命令的输出中通过管道传送的流中读取一个输入记录,并将该记录的值指定给 Variable 参数指定的变量。如果当前未打开将 Expression 参数的值作为其命令名称的流,则创建流。创建的流等同于调用 popen 子例程,此时 Command 参数取 Expression 参数的值且 Mode 参数设置为一个是 r 的值。只要流保留打开且 Expression 参数求得同一个字符串,则对 getline 函数的每次后续调用读取另一个记录。如果未指定 Variable 参数,则 $0 记录变量和 NF 特殊变量设置为从流读取的记录。 |
getline [ Variable ] < Expression | 从 Expression 参数指定的文件读取输入的下一个记录,并将 Variable 参数指定的变量设置为该记录的值。只要流保留打开且 Expression 参数对同一个字符串求值,则对 getline 函数的每次后续调用读取另一个记录。如果未指定 Variable 参数,则 $0 记录变量和 NF 特殊变量设置为从流读取的记录。 |
getline [ Variable ] [file] | 从file内读取一行将存储到Variable 参数指定的变量内。如果未指定 Variable 参数,则 $0 记录变量设置为该记录的值,还将设置 NF、NR 和 FNR 特殊变量。如果未指定file,默认从标准输入中读取文件。 |
getline函数
awk getline用法:输出重定向需用到getline函数。getline从标准输入、管道或者当前正在处理的文件之外的其他输入文件获得输入。它负责从输入获得下一行的内容,并给NF,NR和FNR等内建变量赋值。
如果得到一条记录,getline函数返回1,如果到达文件的末尾就返回0,如果出现错误,例如打开文件失败,就返回-1。
getline语法:getline var,变量var包含了特定行的内容。
awk getline从整体上来说,用法说明:
- 当其左右无重定向符|或<时:getline作用于当前文件,读入当前文件的第一行给其后跟的变量var或$0(无变量),应该注意到,由于awk在处理getline之前已经读入了一行,所以getline得到的返回结果是隔行的。
- 当其左右有重定向符|或<时:getline则作用于定向输入文件,由于该文件是刚打开,并没有被awk读入一行,只是getline读入,那么getline返回的是该文件的第一行,而不是隔行。
执行linux的 date命令,并通过管道输出给getline,然后再把输出赋值给自定义变量out,并打印它:
awk 'BEGIN{ "date" | getline out; print out }' test |
执行shell的date命令,并通过管道输出给getline,然后getline从管道中读取并将输入赋值给out, split函数把变量out转化成数组mon,然后打印数组mon的第二个元素:
awk 'BEGIN{ "date" | getline out; split(out,mon); print mon[2] }' test |
命令 ls的输出传递给geline作为输入,循环使getline从ls的输出中读取一行,并把它打印到屏幕。这里没有输入文件,因为BEGIN块在打开输入文件前执行,所以可以忽略输入文件。
awk 'BEGIN{ while( "ls" | getline) print }' |
文件操作
关闭文件
awk中允许在程序中关闭一个输入或输出文件,方法是使用awk的close。
close("filename") |
filename可以是getline打开的文件,也可以是stdin,包含文件名的变量或者getline使用的确切命令。或一个输出文件,可以是stdout,包含文件名的变量或使用管道的确切命令。
输出到一个文件
awk中允许用如下方式将结果输出到一个文件:
echo | awk '{ printf("hello word!n") > "datafile"}' echo | awk '{printf("hello word!n") >> "datafile"}' |
时间函数
格式 | 描述 |
生成时间格式,返回从1970年1月1日开始到指定时间的的整秒数 | |
strftime([format [, timestamp]]) | 格式化时间输出,将时间戳转为时间字符串 |
systime() | 得到时间戳,返回从1970年1月1日开始到当前时间的整秒数 |
strftime日期和时间格式说明符
格式 | 描述 |
星期几的缩写(Sun) | |
星期几的完整写法(Sunday) | |
月名的缩写(Oct) | |
月名的完整写法(October) | |
本地日期和时间 | |
十进制日期 | |
日期 08/20/99 | |
日期,如果只有一位会补上一个空格 | |
用十进制表示24小时格式的小时 | |
用十进制表示12小时格式的小时 | |
从1月1日起一年中的第几天 | |
十进制表示的月份 | |
十进制表示的分钟 | |
12小时表示法(AM/PM) | |
十进制表示的秒 | |
十进制表示的一年中的第几个星期(星期天作为一个星期的开始) | |
% w | 十进制表示的星期几(星期天是0) |
十进制表示的一年中的第几个星期(星期一作为一个星期的开始) | |
重新设置本地日期(08/20/99) | |
重新设置本地时间(12:00:00) | |
两位数字表示的年(99) | |
当前月份 | |
时区(PDT) | |
百分号(%) |
设置字段定界符
默认的字段定界符是空格,可以使用-F "定界符" 明确指定一个定界符:
awk -F: '{ print $NF }' /etc/ passwd
awk 'BEGIN{ FS=":" } { print $NF }' /etc/passwd
在BEGIN语句块中则可以用OFS=“定界符”设置输出字段的定界符。
常用示例
打印每一行内容
需用到内置变量:$0 这个变量包含执行过程中当前行的文本内容。
$ awk '{print $0}' 123.txt $ awk '{print }' 123.txt |
打印每一行的前面字段
需用到内置变量:$n 当前记录的第n个字段,比如n为1表示第一个字段,n为2表示第二个字段。
$ awk '{print $1,$2}' 123.txt |
打印每一行的最后字段
需用到内置变量:$NF表示一行的最后一个字段,
需用到内置变量:$(NF-n)表示一行中的倒数第几个字段,
$ awk '{print $NF}' 123.txt $ awk '{print $(NF-1)}' 123.txt |
打印文本总行数
需用到内置变量:
$ awk END'{print NR}' 123.txt #注意此处要用END语句块,如果用通用,则会打印每一行的行号,而END只会打印最后一次的行号,也就是总的行数 |
算术运算求冥
需用到算术运算符**与^,都表示求冥
$ awk ' BEGIN{print 3**3}' #只有BEGIN语句块,不用输入文件 $ echo | awk ' END{print 3**3}' #有END语句块,必须有输入文件,这里用echo输入一个空字符串 $ echo | awk '{print 3^3} ' #有通用语句块,必须有输入文件 |
跳过某行
需运用到next语句,表示跳过当前行
需用到正则表达式/...$/,$表明以某内容结尾的
$ awk '/sh$/{next}{print $0}' 123.txt #直接跳过以sh结尾的行 |
判断关联数组中是否存在某键值
$ awk 'BEGIN{tB["a"]="a1";tB["b"]="b1";if( "c" in tB){print "ok";}else {print "no"};}' |
循环打印数组元素
$ awk 'BEGIN{tB["a"]="a1";tB["b"]="b1";for(k in tB){print k,tB[k];}}' |
替换指定字符串
需用到字符串函数:gsub( Ere, Repl, [ In ] ),替换所有与正则表达式相匹配的具体值
需用到字符串函数:sub( Ere, Repl, [ In ] ),替换第一个与正则表达式相匹配的具体值
需用到正则表达式:[-],表明匹配范围内的任意字符,[0-9]表明匹配0-9的任意数字
需用到正则表达式:+,表明匹配之前的项一次或多次
注意正则表达式需用//括起来。
$ awk 'BEGIN{info="this is a test2010test!2008";gsub(/[0-9]+/,"!",info);print info}' this is a test!test!! [DSYU@DSYU shell]$ awk 'BEGIN{info="this is a test2010test!2008";sub(/[0-9]+/,"!",info);print info}' this is a test!test!2008 |
指定字符串查找
需用到字符串函数:index( Str1, Str2 ),在str1中寻找str2,有即返回位置(从1开始),没有返回0.
需用到其他运算符:?: ;a?b:c; a为真则b为整个表达式结果,否则c为整个表达式结果。
$ awk 'BEGIN{info="this is a test2010test!";print index(info,"tast")?"ok":"not found";}' not found $ awk 'BEGIN{info="this is a test2010test!";print index(info,"test")?"ok":"no found";}' $ awk 'BEGIN{info="this is a test2010test!";print len=index(info,"test");}' |
指定正则表达式匹配查找
需用到字符串函数:match( Str, Ere );成功返回在str中能匹配ERe正则表达式的位置,没有返回0.
需用到正则表达式:[-],表明匹配范围内的任意字符,[0-9]表明匹配0-9的任意数字
需用到正则表达式:+,表明匹配之前的项一次或多次
注意正则表达式需用//括起来。
$ $ awk 'BEGIN{info="this is a test2010test!";len=match(info,/[0-9]+/);print len}' $ awk 'BEGIN{info="this is a test2010test!";len=match(info,/[5-9]+/);print len}' |
截取字符串
需用到字符串函数:substr( String, M, [ N ] ),返回从string指定字符串第M个位置(编号从1开始)截取的N个字符组成的字符串。未指定N,则返回M位置到最末尾。
$ awk 'BEGIN{info="this is a test2010test!";print substr(info,4,10)}' s is a tes [DSYU@DSYU shell]$ awk 'BEGIN{info="this is a test2010test!";print substr(info,4)}' s is a test2010test! |
字符串分割
需用到字符串函数:split( String, A, [Ere] ),将 String 参数指定的参数以ERe指定的依据为准分割为数组元素 A[1], A[2], . . ., A[n],并返回 n 变量的值。
$ awk 'BEGIN{info="this is a test";split(info,tA," ");print length(tA);for(k in tA){print k,tA[k];}}' 4 test 1 this |
打开外部文件
需用到一般函数:Expression | getline [ Variable ],从来自 Expression 参数指定的命令的输出中通过管道传送的流中读取一个输入记录,并将该记录的值指定给 Variable 参数指定的变量。
需用到一般函数:close( Expression ),用同一个带字符串值的 Expression 参数来关闭由 print 或 printf 语句打开的或调用 getline 函数打开的文件或管道。
$ awk 'BEGIN{while("cat /etc/passwd"|getline){print $0;};close("/etc/passwd");}' |
获取输入信息
需用到一般函数:getline [ Variable ] file ,读取file内的一行信息存储到Variable 内。如果未指定file,默认从标准输入文件中读取。
$ awk 'BEGIN{print "Enter your name:";getline name;print name;}' Enter your name: yu #此行是用户输入的 $ awk 'BEGIN{print "Enter your name:";getline name;print name;}' 123.txt Enter your name: 8.sh 9.sh 10.bck |
创建指定时间
需用到时间函数:mktime( YYYY MM dd HH MM ss[ DST]),生成时间格式,返回从1970年1月1日开始到指定时间的的整秒数
需用到时间函数:strftime([format [, timestamp]]),格式化时间输出,将时间戳转为时间字符串
具体格式。
$ awk 'BEGIN{tmp=mktime("2006 06 06 6 6 6");print strftime("%c",tmp);}' 2006年06月06日 星期二 06时06分06秒 |
- 赞
- 收藏
- 评论
- 分享
- 举报
</div
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK