

总结出这套数据库迁移经验,我花了20年…… - 更多 - dbaplus社群:围绕Data、Blockchai...
source link: https://dbaplus.cn/news-160-4545-1.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

总结出这套数据库迁移经验,我花了20年……
到了后来,面对迁移方案的选择,如果是十分重要的核心系统,一定要选择最为稳妥的方案,以备不测。昨天微信群里有人在问一个数据库想迁移存储,有没有什么好方案,从我脑子里冒出来的都是系统层面的迁移方案,而群里的DBA朋友往往都说的是数据库层面的迁移技术。实际上没有最好的技术和方案,只有最合适的。具体选择哪种数据库迁移方案,最终还是要看具体的系统环境以及迁移实施队伍的技术能力。
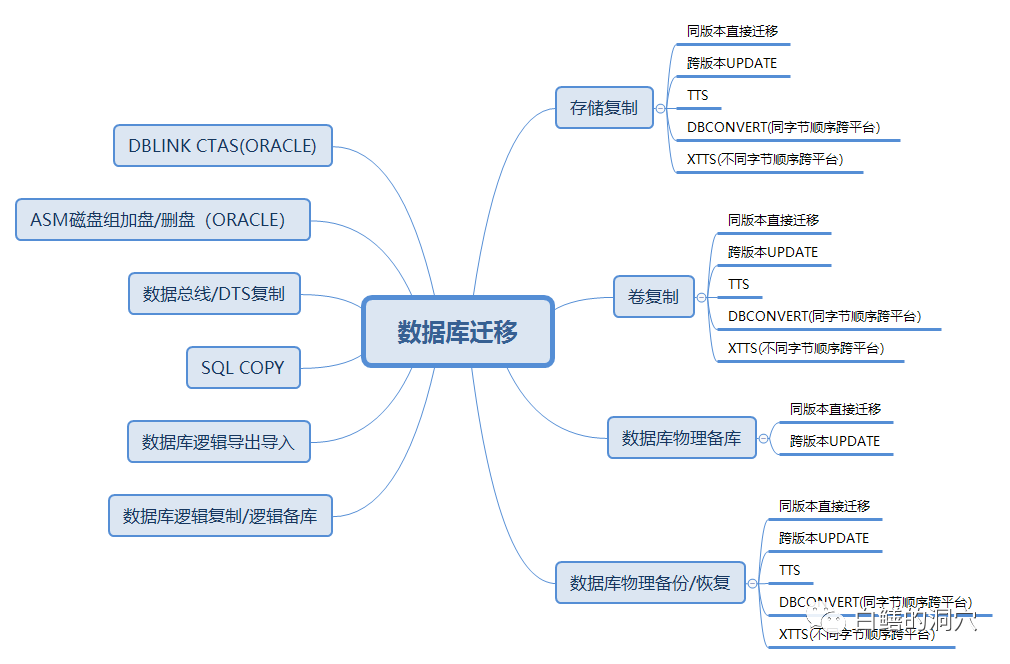
一、存储复制
存储复制是最近我比较喜欢的一种数据库跨存储迁移的方法,可以用于很多迁移需求。特别是一个环境中存在多种数据库/多个数据库的场景,用存储复制的方式一下子可以搞定所有的数据库,十分便捷。存储复制的主要实施工作都由存储厂商完成,对于DBA来说也是最为轻松的,如果出问题,都不需要DBA去甩锅,肯定是存储厂商的问题。DBA要做的就是打开数据库,用rman validate校验一下数据文件是否存在物理/逻辑坏块就可以了。十年前一个金融客户的核心数据库数据库从9i HA升级为10g RAC,存储从IBM 8000系列迁移到HDS高端存储,采用的就是这个方案。使用HDS自带的异构存储虚拟化能力,首先将数据从IBM 8000系列存储复制到HDS上,最后切换的那一晚上停掉生产数据库,作最后一次增量复制后,用10g RAC的环境挂在新的卷,然后UPGRADE数据库,整个数据库迁移升级工作一个多小时就完成了。
很多DBA会把卷复制和存储复制看作一码事,对于DBA来说,存储和卷并无不同,反正看到的是一堆裸设备。实际上二者还是不同的,卷复制采用的是卷管理软件的数据同步功能,比如VERITAS的LVM,卷管理软件天生就是支持异构平台的,因此使用卷复制技术同步数据有更广泛的适用性,而存储复制技术需要存储本身的支持(不过现在大多数高端存储都支持异构存储的存储虚拟化,因此大多数情况下都能支持,如果实在你的环境中的存储不支持异构复制,也可以考虑租借一台支持你所需要复制的存储的虚拟化机头来做实施,费用在几千块钱到几万块钱不等,看你租借的设备和租借的时间)。
大概十年前吧,一个运营商从HP小机上迁移一个数据库到IBM小机,存储也从HP存储更换为EMC存储,当时他们原来的系统使用了VCS,因此使用VERITAS的卷复制做的数据迁移。在IBM端CONVERT数据库的时候(因为HP-UX和AIX都是大端的,所以可以做DATABASE CONVERT,而不需要使用XTTS)遇到了ORACLE 10G的一个BUG, UNDO表空间CONVERT失败,数据库无法打开,当时也是惊出一身冷汗,最后通过强制OFFLINE相关UNDO SEGMENT,重新创建UNDO表空间切换等方式解决了这个问题,不过完成迁移的时候已经接近早上8点,超出了申请的停机窗口,差点影响了第二天营业厅开门。所以说,再简单的迁移方案,都不能保证不出意外。
二、逻辑复制
逻辑复制是一种停机窗口较为紧张时候常用的数据库迁移的方案。两千零几年的时候帮助一个运营商把计费/账务两大核心系统从Oracle 8i迁移到Oracle 10g的时候,为了缩短停机窗口,使用ogg进行逻辑复制。那时候的OGG也是比较垃圾的,功能、性能都存在一定的问题,BUG也比较多。切换当晚发现有几张表总是追不上,最后决定直接通过dblink CTAS重建的方式迁移了。最后还好,在规定的时间窗口内完成了数据库的迁移和数据校验工作。使用OGG做迁移,数据校验的工作量十分大,如果是十分核心的系统,对数据一致性和完整性要求较高,一定要留足时间做数据校验。
逻辑导出导入一直是被认为最为安全的迁移方式,不过天底下没有绝对安全的迁移方案。大概6/7年前,一个银行把核心系统从HDS存储迁移到华为18K上的时候,想把数据库也顺便从10g升级到11g,因为核心应用也要做升级,因此申请了36小时的业务停机窗口,其中核心系统完全停止业务18小时,这18小时中,给了数据库迁移8个小时的时间。通过综合考虑,他们决定采用最为稳妥的数据库逻辑导出导入的方式。
首先在老存储上导出数据,然后把整个卷挂载到新的服务器上,再做导入。按理说够安全了吧,没想到主机工程师挂载这块盘的时候没注意给挂载成只读的了。DBA也没检查就开始导入了,几个小时后报无法写入磁盘数据,impdp异常退出了。这时候8小时的时间窗口已经使用了5个多小时了,如果重新导入一次,时间上肯定是不够的。当时我正好在现场,通过检查发现是impdp输出日志的时候无法写盘导致了错误,而刚开始的时候写入日志的时候是写在缓冲里并没有刷盘,所以没有报错,等刷盘的时候就报错了。通过校验数据表和索引发现所有的索引都已经完成创建了。因此报错时可能已经完成了主要的数据导入过程。最后经过会商决定暂时不回退整个工作,继续进行后续工作。
不过因为这个插曲,原本计划的对所有表和索引做一次重新统计(通过SPA分析后发现11g对统计数据的依赖性更强,因此建议最后做一次表分析)就没有进行了。核心系统启动顺利完成,主要功能测试也顺利完成,大家揪着的心才放了下来。不过前台很快传来更坏的消息,应用开发商在测试性能的时候,认为主要核心交易的延时都慢了几十毫秒,平均核心交易延时从升级前的80毫秒提高到120毫秒以上,因此拒绝新系统上线。大家折腾了这么长时间还要回退,这对IT部门的打击十分严重的。因此CIO希望我们能够尽快找到问题,解决问题。
通过分析存储的性能,数据库的总体性能没有发现什么问题。时间已经接近8小时的窗口了,按道理现在必须做回退了。我当时和CIO说,能不能再给我20分钟我再分析一下,如果找不到原因再回退。当时CIO说,我给你40分钟,如果不行只能我去向行长请罪了。最后在差不多半小时后,我终于定位了引起一部分核心交易延时增加的主要原因是几张表的统计数据过旧,更新了统计数据后,核心交易延时恢复到90毫秒左右,低于开发商要求的不高于120毫秒的要求。从这个案例上看,最简单靠谱的迁移方案,也不是万全的。
三、ASM磁盘组加盘/删盘
ASM磁盘组上加入新存储的磁盘,然后逐步删除老存储的磁盘,利用ASM的REBALANCE功能实现存储迁移也是一种挺不错的方案,只是REBALANCE时间比较长(如果数据量较大,业务负载较大),需要DBA随时关注整个进程,如果系统负载较高,IO吞吐量较大,那么在此期间可能会引起一些IO方面的性能问题。严重时可能导致应用系统总体性能严重下降,而一旦这些问题发生,我们只能暂时降低REBALANCE的优先级,缓解问题,无法彻底解决问题。因此对于特别核心的系统使用这种方式还是要十分注意。我把这个方法教给一家银行后,他们就喜欢上了这种迁移方式,并用这种方式迁移了大量的系统,总体上来说还是比较平稳的。不过在核心交易系统上,他们还是没敢使用。
数据库迁移的方法有很多,今天时间的关系我就不一一举例了。不过无论采用何种方式,都需要实施者不要掉以轻心,对每个环节都做最精心的准备。不过有一定可以提醒大家的是,跳出DBA的思维方式,可能会找到更好的方法。
作者丨白鳝 来源丨公众号:白鳝的洞穴(ID:baishan755) dbaplus社群欢迎广大技术人员投稿,投稿邮箱:[email protected]Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK