

Videogrep Tutorial
source link: https://lav.io/notes/videogrep-tutorial/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
How to Make Automatic Supercuts
I’ve been working on some long-needed updates to Videogrep, my command-line tool that automatically generates supercuts. These updates were motivated in part by a 10 week class I recently developed and taught at the School for Poetic Computation called Scrapism (web-scraping-as-art). The class includes a section on automatically manipulating video, and I’ll also be teaching this material this June, in a 3-hour workshop that is specifically about video and the command line at Sonic Acts.
The most significant improvement I’ve made to the software is migrating Videogrep’s offline transcription tool from Pocketsphinx, which is notoriously inaccurate and seemed to have stopped working on my Mac, to Vosk, which anecdotally works around 1000% better.
I’ve also attempted to simplify the tool a bit, removing some features that I don’t think anyone was really using, like searching by part of speech or word category.
In this tutorial I’ll walk you through how to use the new and improved Videogrep, as well as another tool called yt-dlp that allows you to download videos from almost any website.
Prerequisites
This tutorial requires some familiarity with the command line (although not much). If you’re brand new to this type of thing, you may wish to take a look at this video/write-up I’ve prepared: Intro to the Command Line.
You’ll also need Python installed on your computer. If you’re on a Mac you should already be good to go. If you’re on a PC, download and install the latest stable release of Python here.
Downloading videos with yt-dlp
Before we get into Videogrep, here’s a brief intro to yt-dlp.
yt-dlp allows you to very easily download almost any video from the web. To install it, just run:
pip3 install yt-dlp
There are tons of things you can do with yt-dlp. I’m just going to cover the basics here, focusing on what I find the most useful for making supercuts.
Basic usage
To download a video, just type yt-dlp and the URL of the video you want. This will work for YouTube, Vimeo, Twitter and hundreds of other websites. For example, if we want to download some highlights from the nightmarish Metaverse announcement video (which I’ll be using later to demo Videogrep), it’s as easy as:
yt-dlp "https://www.youtube.com/watch?v=gElfIo6uw4g"
Note: I’ve surrounded the video URL in quotes to avoid problems that can occur if the URL contains special characters. This isn’t always necessary, but I usually do it anyway.
You can also download an entire user, channel, playlist, or search query. For example this will download the entire White House channel (it will take a long time).
yt-dlp "https://www.youtube.com/user/whitehouse/"
And this will download videos matching the search query “capitalism:”
yt-dlp "https://www.youtube.com/results?search_query=capitalism"
You can pretty much give yt-dlp any URL on YouTube, or any other video site.
File formats
Websites like YouTube and Vimeo store videos in multiple file formats and sizes. By default, yt-dlp will download the highest quality video it can find, but frequently I like to work with smaller videos. To get a list of all available video formats simply add the -F option:
yt-dlp "https://www.youtube.com/watch?v=gElfIo6uw4g" -F
You’ll see something like this:
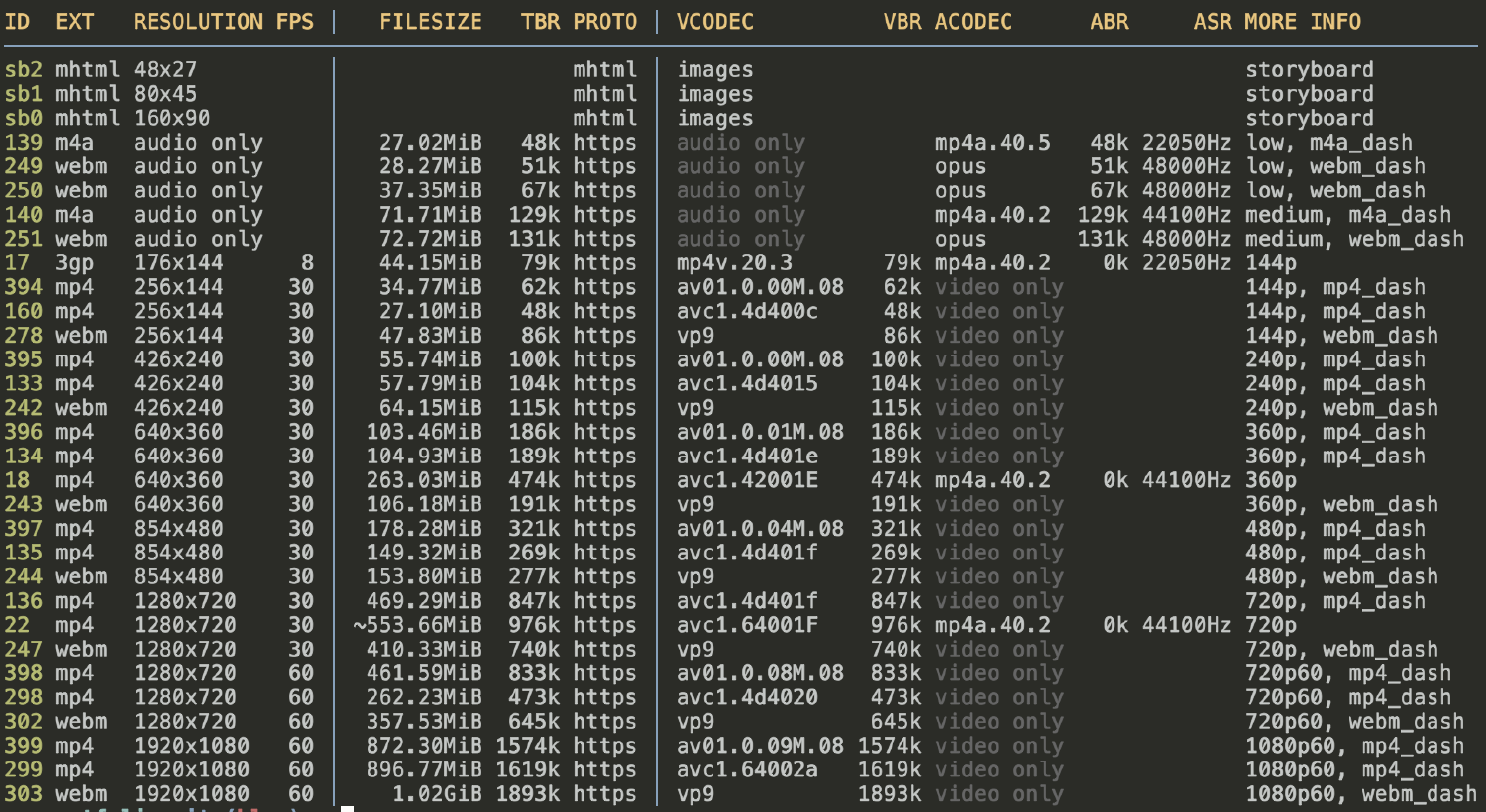
You can then select a file to download by passing the -f option along with an id (the number or characters in the first column). So if I want to download this video as a 1280x720 mp4, I would type:
yt-dlp "https://www.youtube.com/watch?v=gElfIo6uw4g" -f 22
Note: some formats are video or audio only.
Changing the video filename
By default yt-dlp will automatically name the downloaded video for you. This is useful, but sometimes it’s convenient to name the file yourself. To do so, add the -o flag.
yt-dlp "https://www.youtube.com/watch?v=gElfIo6uw4g" -o meta.mp4
Download subtitles
Finally, YouTube usually provides auto-generated subtitles for videos. These are fairly high quality, and are useful for a variety of reasons, including making supercuts!
To download subtitles, just add --write-auto-sub.
yt-dlp "https://www.youtube.com/watch?v=gElfIo6uw4g" --write-auto-sub
You can also combine this with -f, and -o, like so:
yt-dlp "https://www.youtube.com/watch?v=gElfIo6uw4g" --write-auto-sub -f 22 -o meta.mp4
This will download the video as a 1280x720 mp4 with the filename meta.mp4, along with it’s subtitles in .vtt format.
Videogrep
Videogrep uses the timestamps in subtitle files to make supercuts of videos. It will automatically look for a few different types of subtitle files, including .srt files (the most common subtitle format), .vtt files (a common web-based subtitle format), or specially formatted .json files that videogrep can generate itself (more on this later).
Note: the subtitle file must have the same name as the video file. So, if you have a video called meta.mp4 you’d also need a subtitle file, in the same folder, called meta.vtt or meta.srt.
We’ll start using .vtt files that are provided with almost every YouTube video.
If you haven’t already done so, go ahead and download a YouTube video with yt-dlp, and make sure to pass along the --write-auto-sub option to also download the video subtitle file.
Once you have a video to work with, we can use videogrep to make a supercut of it. First, install videogrep with pip:
pip3 install videogrep
Usage
To use videogrep give it input video or video files with the --input argument, and a search term with the --search argument.
videogrep --input VIDEO.mp4 --search "search term"
For our first example, let’s make a supercut of Mark Zuckerberg saying the word “experience” in this video.
videogrep --input meta.mp4 --search 'experience'
This will save a video called supercut.mp4 in the same folder that you ran the script from. The video will be made only of clips containing the word “experience”.
To change the name of the output video, add the --output or -o option:
videogrep --input meta.mp4 --search 'experience' --output experience1.mp4
Notice that the video doesn’t just contain the search word “experience” but also a few words before and after the keyword. By default videogrep will try to match whole sentences or phrases. A “sentence” is determined by the transcript file associated with the video.
If you want to just cut to individual words you can change the --search-type argument from the default (--sentence) to fragment:
videogrep --input meta.mp4 --search 'experience' --search-type fragment --output experience2.mp4
Note: --search-type fragment requires that subtitle files have timestamps for each word. Frequently .vtt files will have these timestamps, but .srt files will not.
You may notice that some of the timing seems a bit off. In this example, videogrep is using timestamps in the .vtt file that YouTube generated and sometimes these aren’t 100% accurate. If you want to you can adjust how videogrep makes cuts with either the --padding argument, or the --resyncsubs argument.
--padding SECS will add some padding time to the start and end of every clip, and --resyncsubs SECS will shift the time of the entire subtitle file.
In this example, pushing everything back by about 1/10th of a second seems to increase the accuracy:
videogrep --input meta.mp4 --search 'experience' --search-type fragment --resyncsubs 0.1 --output experience3.mp4
Frequent words and phrases
If you want to learn what the most common words and phrases inside a video are, you can use the --ngrams N argument. For example, to print out the most common single words in our Meta video:
videogrep --input meta.mp4 --ngrams 1
To print out the most common two word phrases:
videogrep --input meta.mp4 --ngrams 2
The output would be:
to be 15
going to 10
the metaverse 10
in the 9
you can 8
a lot 7
...
Let’s use this to make a video:
videogrep --input meta.mp4 --search 'the metaverse' --search-type fragment --resyncsubs 0.1 --output metaverse1.mp4
Regular Expressions
Videogrep uses Python’s regular expression engine for the searches you specify with the --search argument. Regular expressions are a long and complicated topic that I won’t try to fully cover here, but I will provide a few useful pointers for getting started.
What is a “regular expression engine??”
A regular expression engine takes a set of characters (some of which have special meaning) and uses them to try to find matches in a text. The input you give the engine (in this case, videogrep) is called a “regular expression”. The most simple type of regular expression is just a set of normal characters, like ing.
videogrep --input meta.mp4 --search 'ing' --search-type fragment
This will look for any word that contains the characters ing, regardless of where they appear in the word. For example making, building and things
In addition to just searching for characters chunks, regular expressions can also contain characters that aren’t matched literally but have a special meaning.
For example:
.is a wildcard that will match with any other character. The regular expressionh.twill match “hot”, “hit”, “hat” and so on.$signifies the end of the word or sentence:y$will find anything that ends with the character “y”.^signifies the start of a word or sentence|means “or” - it let’s you search for multiple things.
Here’s an example of matching multiple words with |:
videogrep --input meta.mp4 --search 'physical|world' --search-type fragment --output physical_world.mp4
Very important note
If you want videogrep to match exactly what you enter, surround your search with ^ and $. For example, to match the word “the” you would use:
videogrep --input meta.mp4 --search '^the$' --search-type fragment --output the.mp4
If you’d like to learn a bit more about regular expressions, I recommend Allison Parrish’s Regular Expressions: A Gentle Introduction.
Transcribing
If you don’t have a subtitle file for your video (for instance if you’ve recorded it yourself), you can use videogrep to transcribe the video for you. To do this you’ll also need to install vosk and ffmpeg.
Note: this does not currently work on M1 Macs without some hacking around.
To install vosk:
pip3 install vosk
To install ffmpeg on a Mac, first install brew, and then:
brew install ffmpeg
Then, just pass the --transcribe option to videogrep:
videogrep --input meta.mp4 --transcribe
After some time passes you should see a new file in the same directory as your video with a .json extension. You can now use videogrep on that video. By default the transcription only works in English, but you can download other language models from vosk and use the --model option to indicate which model to use.
Export options
Videogrep can export any file type that moviepy can handle. In addition, it can export edl files compatible with the wonderful command line video player mpv, xml files that can be imported into Final Cut, Premiere, and Resolve, and it can also save individual clips rather than a concatenated supercut.
To save a supercut as individual clips, just pass the --export-clips option.
videogrep --input meta.mp4 --search experience --output experience.mp4 --export-clips
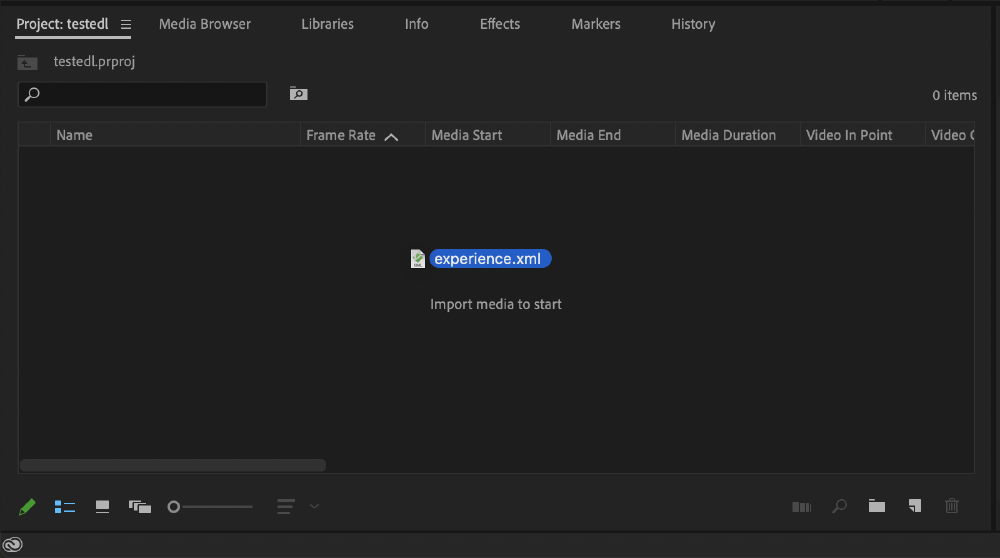
To save a supercut for import into another video editor, give the output file a .xml extension:
videogrep --input meta.mp4 --search experience --output experience.xml
You can now drag the xml file directly into Adobe Premiere, or import it into Davinci Resolve.
Multiple files
Videogrep can take multiple input videos. For example, to run it on every mp4 in your current directly, just pass it *.mp4 as an input:
yt-dlp "https://www.youtube.com/results?search_query=capitalism" --write-auto-sub
videogrep --input *.mp4 --search capitalism
Videogrep as a module
Finally, you can also use videogrep from within Python. I’ve included a few example scripts in the repository that you can explore. These include: a script for extracting silences from a video; downloading and supercutting YouTube searches, and automatically making a supercut based on common words in a video.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK