

深入浅出 http 的缓存机制
source link: https://www.xiabingbao.com/post/http/http-cache-rblrrn.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

通过复用以前获取的资源,可以显著提高网站和应用程序的性能。Web 缓存减少了等待时间和网络流量,因此减少了显示资源表示形式所需的时间。通过使用 HTTP 缓存,变得更加响应性。
通常 http 缓存分为强缓存和协商缓存。
1. 强缓存
在约定的固定时间内,直接使用浏览器本地缓存。这种方式适用于不常更新的资源中,如 js,css,image 等静态资源;同样这也是一个缺点,若缓存时间设置的过长,更新内容不及时;若缓存时间设置的过短,又造成内容没更新,但缓存时间到了的问题。
设置强缓存一般有两种方式:
通过 Expires 设置当前资源的过期时间点;
通过 cache-control 设置缓存的时间,从第 1 次请求开始算起;
1.1 Expires
在服务端设置这个字段,表示该资源的过期时间。
Expires: Wed, 21 Oct 2017 07:28:00 GMT浏览器就会拿其本地时间来跟这个字段中的时间进行对比,若还没到过期时间,则继续使用缓存,否则产生新的请求。
这就会存在一个问题,该资源缓存的长短,与其本地时间有关系,比如设置本地电脑时间在 2039 年,目前所有下发的资源,都无法缓存。
1.2 cache-control
Expires 是 HTTP1.0 时就存在字段,为了解决上面 Expires 存在的问题,在 HTTP1.1 中,引入了cache-control字段。该字段不是用统一的过期时间来控制,而是告诉浏览器要缓存多长时间,从第一次收到这个请求开始算起。
若我们用 nodejs 搭建一个简单的 http 服务的话,设置该字段也很简单。
const http = require('http');
http
.createServer((req, res) => {
console.log('get static request:', req.url);
res.writeHead(200, {
'cache-control': 'public, max-age=31536000',
});
res.end('console.log(Date.now())');
})
.listen(3031);若使用express的话,可以这样设置:
const express = require('express');
const app = express();
app.get('*', (req, res) => {
console.log('get static request:', req.url);
// 下面的3种方式都可以
res.setHeader('cache-control', 'public, max-age=600');
// res.header('cache-control', 'public, max-age=600');
// res.set({ 'cache-control': 'public, max-age=600' });
res.end('console.log(Date.now())');
});
app.listen(3031);当缓存起作用时,会提示该资源from memory cache或from disk cache,服务端也不再接收该请求。
在 Chrome 浏览器中,刷新页面时,会发现 cache-control 或者 Expires 失效了,这是因为:
如果在同一标签中对同一 URI 的另一个请求后立即发出请求(通过单击刷新按钮,或 F5 之类的),Google Chrome 会忽略该标头 Cache-Control 或 Expires 标头。它可能有一个算法来猜测用户真正想做什么。 测试 Cache-Control 标题的一种方法是返回带有自身链接的 HTML 文档。点击该链接后,Chrome 会从缓存中投放文档。
那怎么才能看到效果呢?新开启一个窗口,打开控制台,然后再请求链接,会发现走缓存了,Is Chrome ignoring Cache-Control: max-age?。
1.3 cache-control 的其他用法
1.3.1 cache-control 的组成部分
cache-control 的值主要由 3 部分组成,可以单独或组合使用任何部分,(具体可参考该文档Cache-Control):
可缓存性:即对该资源如何进行缓存
public: 表明响应可以被任何对象(包括:发送请求的客户端,代理服务器,等等)缓存,即使是通常不可缓存的内容。(例如:1.该响应没有 max-age 指令或 Expires 消息头;2. 该响应对应的请求方法是 POST 。);
private: 表明响应只能被单个用户缓存,不能作为共享缓存(即代理服务器不能缓存它)。私有缓存可以缓存响应内容,比如:对应用户的本地浏览器。
no-cache: 在发布缓存副本之前,强制要求缓存把请求提交给原始服务器进行验证(协商缓存验证)。
no-store: 缓存不应存储有关客户端请求或服务器响应的任何内容,即不使用任何缓存。该
no-store比no-cache更加严格,no-cache 是不走强缓存,但协商缓存还可以使用,但 no-store 是不缓存任何内容。
max-page=<seconds>: 设置缓存存储的最大周期,超过这个时间缓存被认为过期(单位秒)。与 Expires 相反,时间是相对于请求的时间;
s-maxage=<seconds>: 覆盖 max-age 或者 Expires 头,但是仅适用于共享缓存(比如各个代理),私有缓存会忽略它;
重新验证和重新加载
must-revalidate: 一旦资源过期(比如已经超过 max-age),在成功向原始服务器验证之前,缓存不能用该资源响应后续请求。
proxy-revalidate: 与 must-revalidate 作用相同,但它仅适用于共享缓存(例如代理),并被私有缓存忽略。
immutable Experimental: 表示响应正文不会随时间而改变。资源(如果未过期)在服务器上不发生改变,因此客户端不应发送重新验证请求头(例如 If-None-Match 或 If-Modified-Since)来检查更新,即使用户显式地刷新页面。在 Firefox 中,immutable 只能被用在
https://transactions。
1.3.2 使用示例
这几个值可以任意的组合,比如:
一般不太改变的文件,各个环节都可以缓存,缓存时间为 600s(↓):
cache-control: public, max-age=600;关闭缓存,任何地方都不存储(↓):
cache-control: no-store;客户端可以缓存资源,但每次都必须重新验证其是否有效(↓),如指定no-cache或max-age=0, must-revalidate等:
Cache-Control: no-cache;Cache-Control: max-age=0, must-revalidate;1.4 cache-control 与 Expires 的优先级
这两个字段都决定了资源的过期时间,那如果两个同时出现,浏览器要看哪一个呢?
根据RFC2616的定义:
If a response includes both an Expires header and a max-age directive, the max-age directive overrides the Expires header, even if the Expires header is more restrictive. This rule allows an origin server to provide, for a given response, a longer expiration time to an HTTP/1.1 (or later) cache than to an HTTP/1.0 cache. This might be useful if certain HTTP/1.0 caches improperly calculate ages or expiration times, perhaps due to desynchronized clocks.
当两者同时存在时,max-age 的优先级更高。
1.5 memory cache 和 disk cache 的区别
Memory Cache 也就是内存中的缓存,主要包含的是当前中页面中已经抓取到的资源,例如页面上已经下载的样式、脚本、图片等。读取内存中的数据肯定比磁盘快,内存缓存虽然读取高效,可是缓存持续性很短,会随着进程的释放而释放。 一旦我们关闭 Tab 页面,内存中的缓存也就被释放了。
那么既然内存缓存这么高效,我们是不是能让数据都存放在内存中呢?
这是不可能的。计算机中的内存一定比硬盘容量小得多,操作系统需要精打细算内存的使用,所以能让我们使用的内存必然不多。
当我们访问过页面以后,再次刷新页面,可以发现很多数据都来自于内存缓存。
内存缓存中有一块重要的缓存资源是 preloader 相关指令(例如)下载的资源。总所周知 preloader 的相关指令已经是页面优化的常见手段之一,它可以一边解析 js/css 文件,一边网络请求下一个资源。
需要注意的事情是,内存缓存在缓存资源时并不关心返回资源的 HTTP 缓存头 Cache-Control 是什么值,同时资源的匹配也并非仅仅是对 URL 做匹配,还可能会对 Content-Type,CORS 等其他特征做校验。
Disk Cache 也就是存储在硬盘中的缓存,读取速度慢点,但是什么都能存储到磁盘中,比之 Memory Cache 胜在容量和存储时效性上。
在所有浏览器缓存中,Disk Cache 覆盖面基本是最大的。它会根据 HTTP Herder 中的字段判断哪些资源需要缓存,哪些资源可以不请求直接使用,哪些资源已经过期需要重新请求。并且即使在跨站点的情况下,相同地址的资源一旦被硬盘缓存下来,就不会再次去请求数据。绝大部分的缓存都来自 Disk Cache,关于 HTTP 的协议头中的缓存字段,我们会在下文进行详细介绍。
浏览器会把哪些文件丢进内存中?哪些丢进硬盘中?
关于这点,网上说法不一,不过以下观点比较靠得住:
对于大文件来说,大概率是不存储在内存中的,反之优先;
当前系统内存使用率高的话,文件优先存储进硬盘;
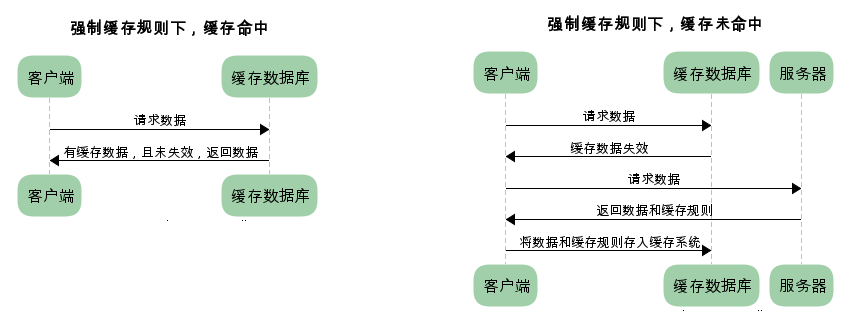
强缓存下请求数据的流程:
2. 协商缓存
根据内容最后的修改时间(Last-Modified),或者标识(ETag),来判断内容是否发生了变化,若没有变化,则告诉浏览器直接使用缓存即可,否则返回最新的内容。
协商缓存是每次都要请求服务器的,然后服务器校验是走缓存,还是下发新的内容。当可以使用客户端的缓存时,只需要返回304状态码即可。
2.1 last-modified
last-modified是一个响应首部,表示资源最后一次修改的时间,用来判断接收到的或者存储的资源是否彼此一致。
2.1.1 使用 last-modified 实现缓存
若上次响应带有last-modified字段,则后面请求资源时,会自动在头部带上If-Modified-Since字段,值就是上次 last-modified 返回的值。我们服务器就可以通过这个If-Modified-Since字段与资源的修改时间进行对比,若没有变化,直接返回304即可,若产生变化,则下发新的内容和新的last-modified字段。
我们以 express 框架为例,来实现下这个缓存逻辑。
const express = require('express');
const fs = require('fs');
const app = express();
let lastModifiedTime = 0;
app.get('*', (req, res) => {
console.log('get static request:', req.url);
// 获取请求头中的 if-modified-since ,若有该字段,且能与上次的修改时间相同
// 则直接返回304
const ifModifiedSince = req.headers['if-modified-since'];
if (ifModifiedSince && new Date(ifModifiedSince).valueOf() === lastModifiedTime) {
res.status(304).end();
return;
}
const file = './app/static/hunger.js';
// 读取文件时,实际上应当使用 createReadStream ,我们使用readFile仅是为了方便演示,
// 因为使用readFile在高并发时,会产生内存积压的问题
// readFile会将所有的内容都读取到内存中,
// 而 createReadStream 则是分片读取,只要读取了内容就会传向下一个管道
fs.readFile(file, { encoding: 'utf8' }, (err, data) => {
if (err) {
return res.status(500).end('read file error');
}
const { mtimeMs } = fs.statSync(file);
// 存储该文件最后的修改时间,并将其设置为响应头进行返回
lastModifiedTime = Math.floor(mtimeMs);
res.setHeader('last-modified', new Date(lastModifiedTime).toGMTString());
res.end(data);
});
});
app.listen(3031);这样就能通过资源的修改时间,来决定是否使用缓存。
2.1.2 last-modified 的缺陷
但用这个字段判断一致性时不太准确,原因如下:
last-modified 最多只能精确到秒级,若 1 秒内产生多次修改时,会被认为成没有改动;
若文件存在重复上传,或打开文档然后又保存,都可能会造成时间的修改,但内容实际上并没有变化;
针对这些问题,http 协议中又出现了一个etag的响应字段。
2.2 etag
etag 是对资源内容的标识符,如 hash 值。这可以让缓存更高效,并节省带宽,因为如果内容没有改变,Web 服务器不需要发送完整的响应。而如果内容发生了变化,使用 ETag 有助于防止资源的同时更新相互覆盖(“空中碰撞”)。
如果给定 URL 中的资源内容更改,则一定要生成新的 Etag 值。 因此 Etags 类似于指纹,也可能被某些服务器用于跟踪。 比较 etags 能快速确定此资源是否变化,但也可能被跟踪服务器永久存留。
2.2.1 使用 etag 实现缓存
若上次响应带有etag字段,则后面请求资源时,会自动在头部带上If-None-Match字段,值就是上次 etag 返回的值。我们服务器就可以通过这个If-None-Match字段与资源的 tag 进行对比,若没有变化,直接返回304即可,若产生变化,则下发新的内容和新的etag字段。
我们以 express 框架为例,来实现下这个缓存逻辑。
const express = require('express');
const fs = require('fs');
const crypto = require('crypto');
const md5 = (str) => crypto.createHash('md5').update(str).digest('hex');
const app = express();
let etag = '';
app.get('*', (req, res) => {
console.log('get static request:', req.url);
// 获取请求头中的 if-none-match ,若有该字段,且能与上次的etag相同
// 则直接返回304
const ifNoneMatch = req.headers['if-none-match'];
if (ifNoneMatch && ifNoneMatch === etag) {
res.status(304).end();
return;
}
const file = './app/static/hunger.js';
// 同理这里实际上我们最好使用 createReadStream
fs.readFile(file, { encoding: 'utf8' }, (err, data) => {
if (err) {
return res.status(500).end('read file error');
}
// 这里我们使用md5来生成etag标识
etag = md5(data);
res.setHeader('etag', etag);
res.end(data);
});
});
app.listen(3031);2.2.2 etag 与 last-modified
当 etag 与 last-modified 两者同时出现时,etag 的优先级更高;同理,if-none-match 比 if-modified-since 的优先级更高。
同时,etag 对资源更新的控制粒度比 last-modified 也更好,无论源文件怎样修改,只要内容不变,etag 就不会变,则缓存就可以一直使用。
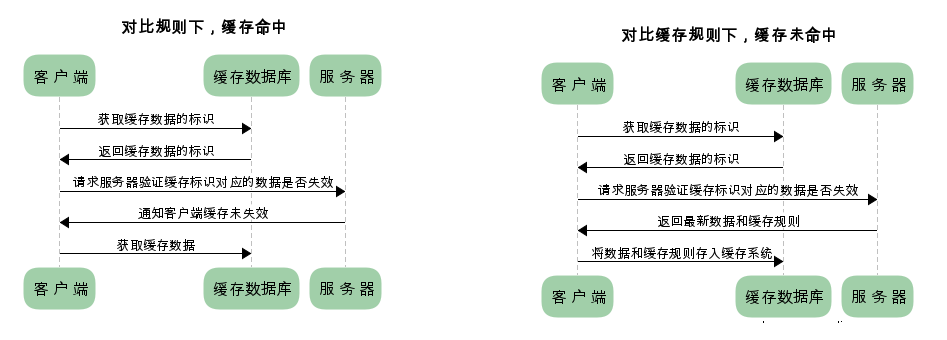
协商缓存下的请求流程:
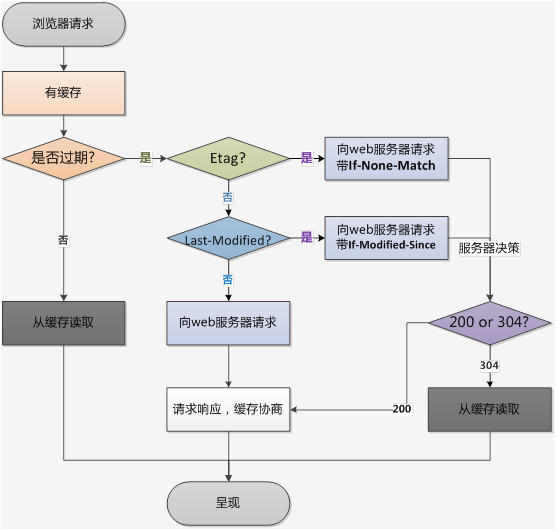
上面我们讲解了强制缓存与协商缓存的实现机制与实现方式,各位可根据自己资源的缓存特性,来决定使用哪种缓存方式和要缓存的时间。
一般地,强制缓存的优先级比协商缓存的优先级更高,优先判断是否存在强制缓存;
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK