

博客翻译:神经辐射场模型爆炸式增长
source link: https://whuhenry.github.io/posts/a575e88f/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

博客翻译:神经辐射场模型爆炸式增长
发表于
2021-12-26 分类于 深度学习
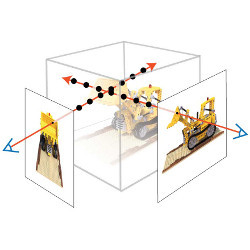
假设你可以捕获一个3D场景的信息,而且能够从不同的视角重复浏览这个场景,甚至可以看到场景捕获时展开的动作。传统情况下,我们习惯于获取2D的图像或者视频,他们能够完整的保存在我们的手机上或者云端服务器上,这个过程十分简单。与之对应的是,捕获一个场景的3D信息则是十分繁琐的。一般来说,这个过程包括获取场景的大量图像,使用摄影测量技术来重建一个密集表面模型,然后人工清理场景中的噪声和错误。最终的结果可以是十分震撼的,可以表达出仅使用2D图像无法传递的场景感受,例如纽约时报最新上线的交互功能就是一个典型的例子。
最新,许多研究人员开始探索深度神经网络革命能否使得每个人都有捕获这样3D场景的能力,使其变得像拍摄照片一样轻松。一项在2020年由论文“Newral Radiance Fields(NeRF)”引发的创新型的技术——神经体渲染(Neural Volume Rendering),抢占了人们的注意力。这项全新的技术接受多张图像作为输入,生成一个使用深度全连接网络进行存储的3D场景紧凑表示方法,该神经网络的全局可以存储在一个不比一般压缩图像大多少的文件中。通过这种表示和记录方法,该模型可以令人惊讶的精度和细节渲染出场景任意视角的图像。
神经体渲染指的是一种深度图像或者视频生成方法,这种方法追踪场景的光线信息,按照一定长度对光线进行积分来生成最终的图像。一般来说,一个全连接神经网络能够在三维坐标系统中对光线的强度、颜色等信息进行编码生成一个函数,随后对该函数进行积分即可生成渲染图像。一篇早期研究是,Lombardi et al.1在视景合成论文中提出了神经体渲染方法,该论文中虽然还是基于体素的表达方法,但是使用神经网络表示三维体的亮度和颜色信息。
与NeRF直接相关前置工作是使用神经网络定义了一个3D隐表面表示方法。许多利用3D信息的图像生成方法使用体素、三维模型、点云或其他传统表示方法。但是在CVPR 2019会议上,至少有3篇文章提出使用神经网络作为一个方程的近似,来定义空间的占用(occupancy)或者符号距离函数(signed distance function),这3篇论文是:occupancy networks2, IM-Net3以及DeepSDF4。直到今天,依然有许多论文基于隐函数思想来实现。
但是,NeRF是最受大家关注的一篇论文。本质上来说,Mildenhall et al. 使用DeepSDF网络结构,但是直接回归出亮度和颜色信息。然后,他们使用一个简单的可微的数值积分方法来近似模拟一个真正的体渲染步骤。一个NeRF模型使用MLP的权重来表达和存储三维场景,这个网络使用已知位姿的图像训练获得。新视角的图像则是通过每条视线上的亮度和颜色的等间隔积分来渲染生成。
NeRF文章最早是2020年3月被放到Arxiv上的,并立刻引起了广泛的关注,不仅是因为该方法能够渲染出高质量的场景图像,而且在深度图上也显示出了惊人的细节。这篇文章的成功可能主要是取决于他的简约性:使用一个多层感知机MLP,接受5D坐标作为输入,输出亮度和颜色。当然还有一些小的改进点,包括位置编码以及分层采样方案。许多研究人员都对如此一个简单的结构能够实现这么好的效果感到惊讶。另一个原因是,“vanilla(翻译:平常的,普通的) NeRF”文章提供了很多可以改进的点。包括这个网络十分慢,包括训练和渲染都很慢;此外这个网络只能表示静态场景;这个网络将场景“烘焙”(bakes in)成光线;以及这个网络是基于场景的,而不是通用的。
在快速发展的计算机视觉社区中,这些机会几乎立刻就被利用和改进了。有几篇文章和数个项目重点提高训练和渲染效率;还有许多工作着眼于将该方法应用于动态场景,使用许多不同的方法,使得从不同视角渲染视频成为可能。另一个NeRF类方法的增强方向是如何处理光线。传统是使用潜在代码(latent code)来重新渲染场景。然而很多研究这提出使用latent codes生成形状,从而可以减少训练使用的图像数量。最后,一个最新的研究方向是如和支持压缩,从而能够存储更加复杂和动态的场景。
总结起来,神经体渲染收到了计算机视觉社区的广泛关注,可以期待在不久将来,研究成果可以使得其真正可以部署到每个人的智能手机上。
Lombardi, S. et al. Neural volumes: Learning dynamic renderable volumes from images. ACM Trans. Graph. (2019).↩︎
Mescheder, L. et al. A. Occupancy Networks: Learning 3D reconstruction in function space. In Proceedings of the IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2019.↩︎
Chen, Z. and Zhang, H. Learning implicit fields for generative shape modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, 5939–5948.↩︎
Park, J.J. et al. DeepSDF: Learning continuous signed distance functions for shape representation. In Proceedings of the IEEE/CVF Conf. Computer Vision and Pattern Recognition, 2019, 165–174.↩︎
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK